Antes de continuar, vamos analisar brevemente Raspado e logo AutoScraper:
O que está raspando?
Web scraping é uma técnica fundamental usada para extrair informações úteis, como contatos, E-mails, imagens, URL, etc ... dos sites. A outra forma de web scraping é o rastreamento. Usado quando precisamos de uma grande quantidade de dados estruturados e rotulados para fundamentos industriais. O software de web scraping pode acessar diretamente a rede mundial de computadores usando protocolos HTML.
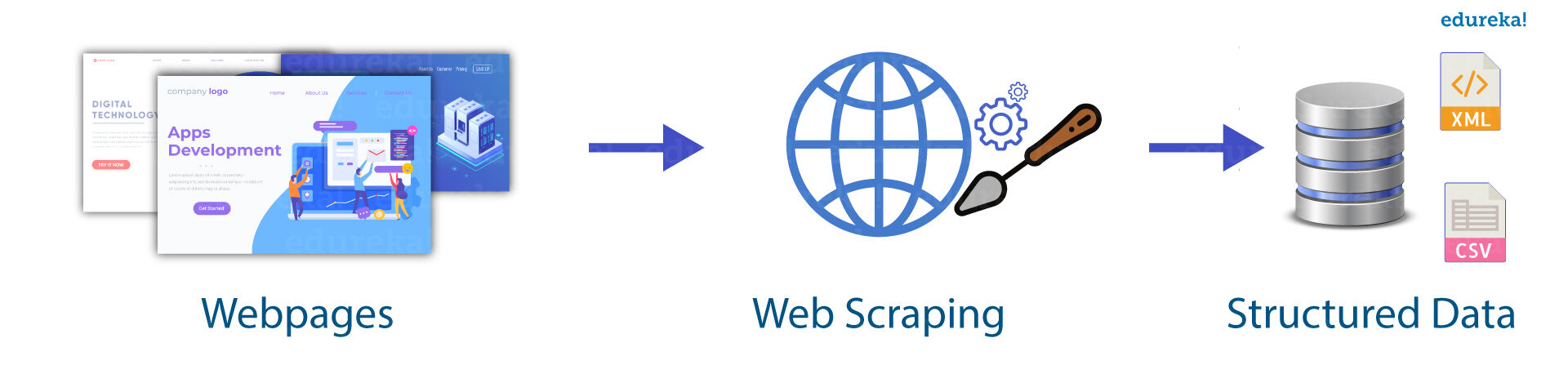
Você sabe que novas formas de web scraping envolvem observar o feed de dados em servidores web, por exemplo, un archivo JSONJSON, o Notação de objeto JavaScript, É um formato leve de troca de dados que é fácil para os humanos lerem e escreverem, e fácil para as máquinas analisarem e gerarem. É comumente usado em aplicativos da web para enviar e receber informações entre um servidor e um cliente. Sua estrutura é baseada em pares de valores-chave, tornando-o versátil e amplamente adotado no desenvolvimento de software.. que se utiliza como transportador entre el cliente y el servidor web.
Existem muitos sites grandes que Google, Facebook, Amazonas, etc. fornecem APIs que permitem que você acesse seus dados em um formato estruturado ou com tags.
Agora, analisamos brevemente a biblioteca AutoScraper:
O que é AutoScraper?
Quando falamos sobre raspagem, há muitas coisas no site que queremos remover, mas os scripts graváveis levam muito tempo para remover os dados e é um processo muito longo, para superar este problema, um grupo de desenvolvedores Python desenvolve uma biblioteca. que extrairá todos os dados de um site de uma maneira fácil. Então AutoScraper é uma biblioteca python de web scraping usada para extrair dados de um site de uma maneira simples, fácil e rápido. Possui um ambiente amigável por este raspador você pode interagir facilmente com esta biblioteca.

Usa URLs de sites e conteúdo HTML para extrair informações e dados confiáveis.
Ponto a considerar: aprenda as regras de raspagem e devolva itens semelhantes em bom formato.
É fácil remover o conteúdo do site que era fácil de revisar como um título, preço, Nome, avaliações, etc. Espere um minuto! O que faremos com as imagens? É uma grande questão que se coloca, podemos dar a imagem durante a execução do programa😅. Estou encontrando uma maneira de remover imagens de sites. Vamos analisar a seguir:

Primeiro, vamos para a instalação desta biblioteca:
Instale AutoScraper
Existem duas maneiras de instalar o AutoScraper:
Usando pip: –
Digite o seguinte código no prompt de comando,
pip instalar autoscraper
ou com o repositório git,
clon de git https://github.com/brandonrobertz/autoscrape-py
cd autoscrape-py /
pip install.[tudo]
Agora importamos módulos importantes:
Importação de módulo
# Importando AutoScraper de autoscraper import AutoScraper
Aqui, importamos a classe AutoScraper da biblioteca.
Agora, alimentamos o URL para a função AutoScraper para continuar a raspagem:
URL: – https://www.bookswagon.com/
Aqui, alimentamos o URL do site de comércio eletrônico para a classe AutoScraper para extrair ou riscar as imagens do livro.
Agora, antes de seguir em frente, primeiro vemos a demonstração raspando títulos de livros e preços para obter uma compreensão melhor e básica do código de raspagem:
Demonstração de raspagem
Agora, vamos alimentar a lista de itens para riscar, então primeiro temos que inicializar a classe AutoScraper com seu objeto:
Lista de Procurados:
crie uma lista de itens
# crie uma lista de elementos itens = ['Rs.349' , 'O Segredo dos Nagas']

Criação de objeto:
# criar objeto scrape = AutoScraper() # alimentação para raspar final_result = scrape.build(URL,Itens) # resultado de exibição imprimir(resultado final)

É hora de deletar a imagem
Agora, ter uma ideia sobre o código de web scraping que discutimos anteriormente, então usamos esse mesmo método para raspar imagens de sites com algumas alterações. Portanto, vamos discutir o método ou técnica para extrair as imagens dos dados. vamos ver a seguir:
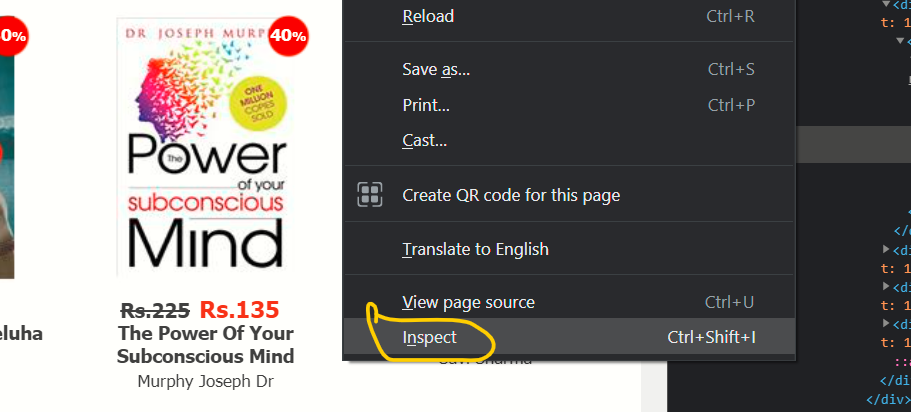
Paso 1:
Na primeira etapa, temos que clicar com o botão direito do mouse e selecionar a opção inspecionar na lista do menu:
Paso 2:
Depois de selecionar a opção inspecionar, uma página de conteúdo HTML abre ao lado da tela, então ele irá pairar sobre a imagem do livro; nesse momento, observe na página de conteúdo HTML que você encontrará o Imagem URL.
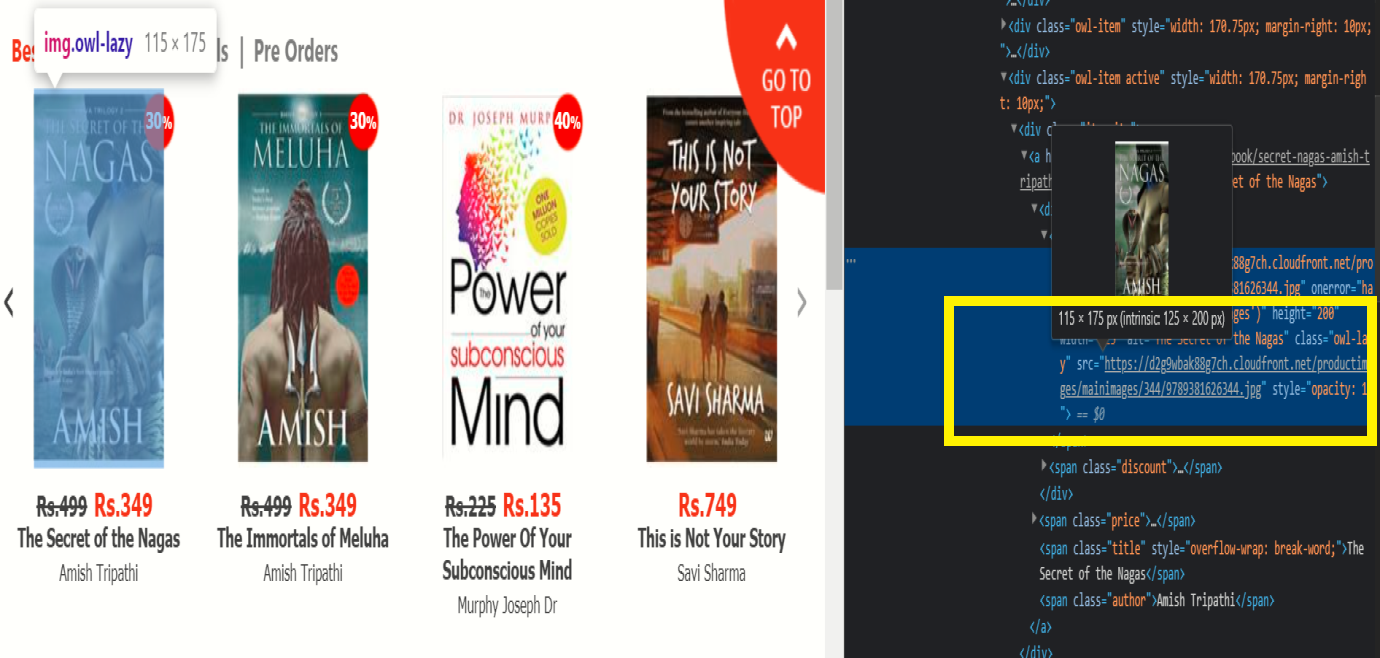
Quando você encontrar o URL da imagem específica, copie e vamos usar na lista de desejos. Esta é apenas a mudança necessária para raspar as imagens do site.
Paso 3:
Agora, vamos configurar esse URL de imagem junto com os livros que entraram em nossa lista de procurados,
item = ['https://d2g9wbak88g7ch.cloudfront.net/productimages/mainimages/344/9789381626344.jpg ','Esta não é a sua história']
Depois de criar uma lista, nós fazemos o mesmo processo que fizemos acima:
# criando objeto
scrape = AutoScraper()
# building result
final_result = scrap.build( URL, item )
# resultado de exibição
imprimir(resultado final)
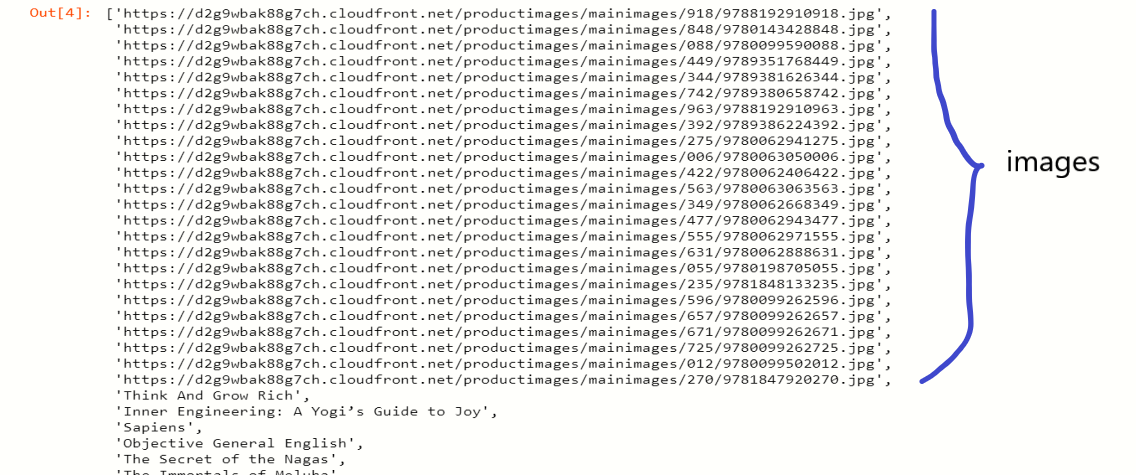
Observação: use o url das imagens para extraí-las do site
Então, este é o processo de raspar imagens de qualquer site.
Nota final
Então, aqui, discutiremos a coleta de imagens do site, se você deseja remover imagens do site, use esta técnica. Estou muito surpreso de usar esta biblioteca AutoViz. Espero que tenha gostado deste artigo e obrigado por ler este artigo.
Você pode se conectar comigo no Linkedin: URL do perfil
Leia também meus outros artigos: https://www.analyticsvidhya.com/blog/author/mayurbadole2407/
Obrigado.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





