Este artigo foi publicado como parte do Data Science Blogathon
1. objetivo
El objetivo de este artículo es predecir los precios de los vuelos dados los distintos parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto..... Os dados usados neste artigo estão disponíveis publicamente no Kaggle. Este será un problema de regresión ya que la variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... objetivo o dependiente es el precio (valor numérico continuo).
2. Introdução
As companhias aéreas usam algoritmos complexos para calcular os preços dos voos, dadas as várias condições presentes naquele momento específico.. Esses métodos levam em consideração fatores financeiros, marketing e social para prever preços de voos.
Hoje em dia, o número de pessoas que usam voos aumentou significativamente. É difícil para as companhias aéreas manter os preços, uma vez que os preços mudam dinamicamente devido a diferentes condições. É por isso que tentaremos usar o aprendizado de máquina para resolver esse problema.. Isso pode ajudar as companhias aéreas, prevendo quais preços eles podem manter. Ele também pode ajudar os clientes a prever os preços de voos futuros e planejar sua viagem de acordo..
3. Dados usados
Dados Kaggle foram usados, que é uma plataforma de acesso gratuito para cientistas de dados e entusiastas do aprendizado de máquina.
Fonte: https://www.kaggle.com/nikhilmittal/flight-fare-prediction-mh
Estamos usando o jupyter-notebook para executar a tarefa de previsão de preços de voos.
4. Analise de dados
O procedimento de extração de informações de dados brutos fornecidos é chamado de análise de dados. Aqui vamos usar eda módulo preparação de dados biblioteca para fazer este passo.
from dataprep.eda import create_report
import pandas as pd
dataframe = pd.read_excel("../saída/Data_Train.xlsx")
create_report(quadro de dados)
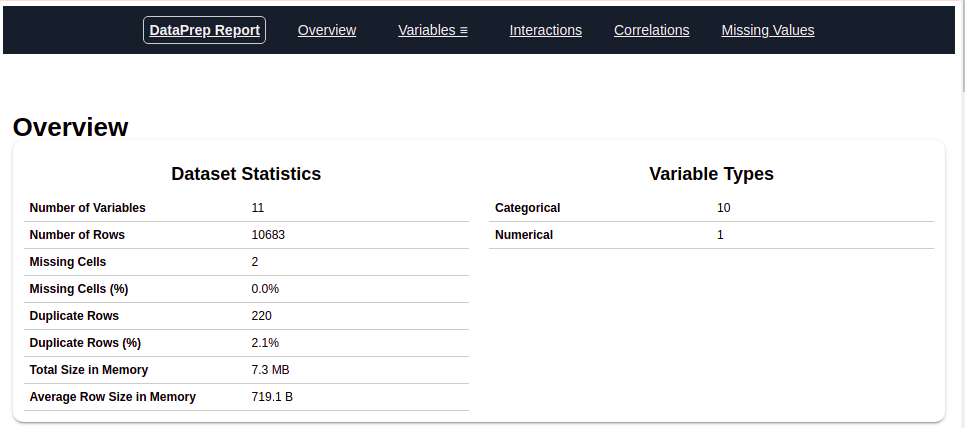
Depois de executar o código acima, obtendrá un informe como se muestra en la figura"Figura" é um termo usado em vários contextos, Da arte à anatomia. No campo artístico, refere-se à representação de formas humanas ou animais em esculturas e pinturas. Em anatomia, designa a forma e a estrutura do corpo. O que mais, em matemática, "figura" está relacionado a formas geométricas. Sua versatilidade o torna um conceito fundamental em várias disciplinas.... anterior. Este relatório contém várias seções ou guias. A seção 'Visão geral'’ deste relatório nos fornece todas as informações básicas dos dados que estamos usando. Para os dados atuais que estamos usando, obtivemos as seguintes informações:
Número de variáveis = 11
Número de linhas = 10683
Número de tipo categórico de característica = 10
Número do tipo numérico característico = 1
Linhas nubladas = 220, etc.
Vamos explorar outras seções do relatório um por um.
4.1 Variáveis
Depois de selecionar a seção de variáveis, você obterá informações conforme mostrado nas figuras a seguir.
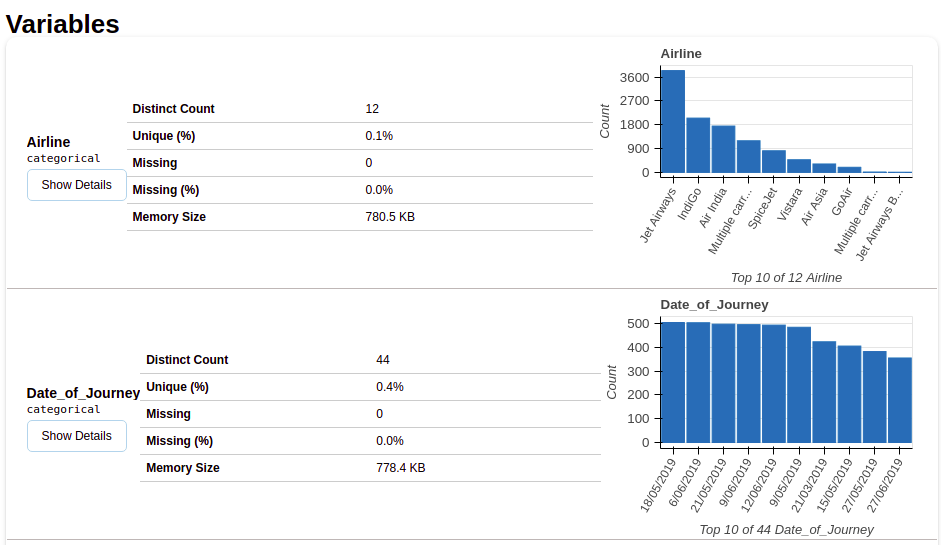
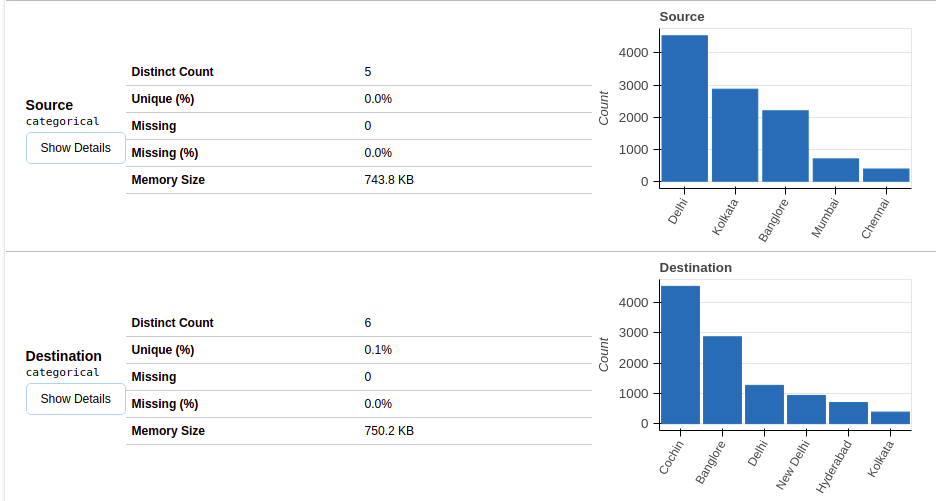
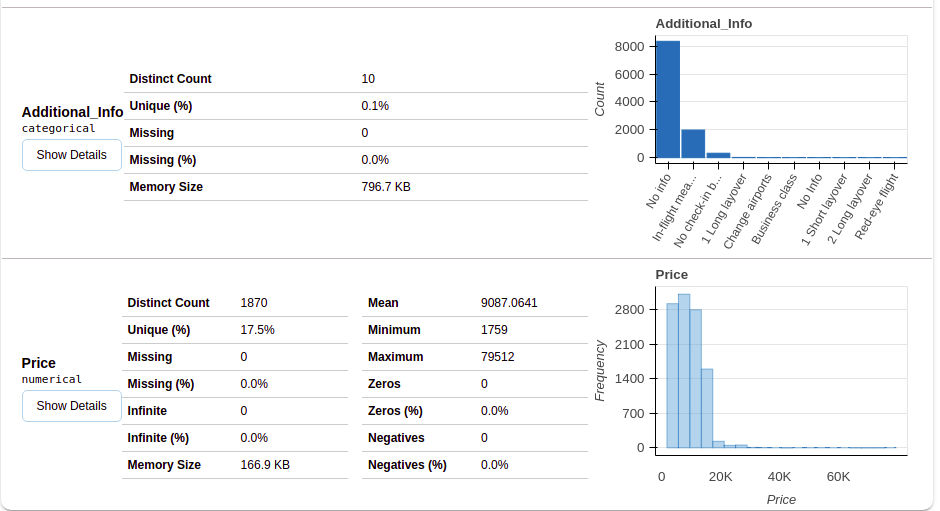
Esta seção fornece o tipo de cada variável junto com uma descrição detalhada da variável..
4.2 Valores ausentes
Esta seção tem várias maneiras de analisar os valores ausentes nas variáveis. Vamos discutir três métodos mais usados, gráfico de barrasO gráfico de barras é uma representação visual de dados que usa barras retangulares para mostrar comparações entre diferentes categorias. Cada barra representa um valor e seu comprimento é proporcional a ele. Esse tipo de gráfico é útil para visualizar e analisar tendências, facilitar a interpretação de informações quantitativas. É amplamente utilizado em várias disciplinas, como estatísticas, Marketing e pesquisa, devido à sua simplicidade e eficácia...., espectro y mapa de caloruma "mapa de calor" é uma representação gráfica que usa cores para mostrar a densidade de dados em uma área específica. Comumente usado em análise de dados, Estudos de marketing e comportamentais, Esse tipo de visualização permite identificar padrões e tendências rapidamente. Através de variações cromáticas, Os mapas de calor facilitam a interpretação de grandes volumes de informações, ajudando a tomar decisões informadas..... Vamos explorar um por um.
4.2.1 Gráfico de barras
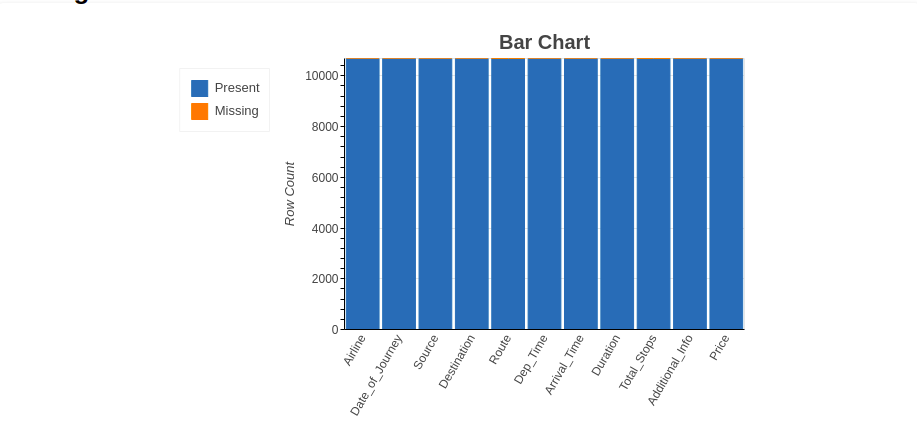
O método do gráfico de barras mostra o 'número de valores ausentes e presentes’ em cada variável em uma cor diferente.
4.2.2 Espectro
O método do espectro mostra a porcentagem de valores ausentes em cada variável.
4.2.3 Mapa de calor
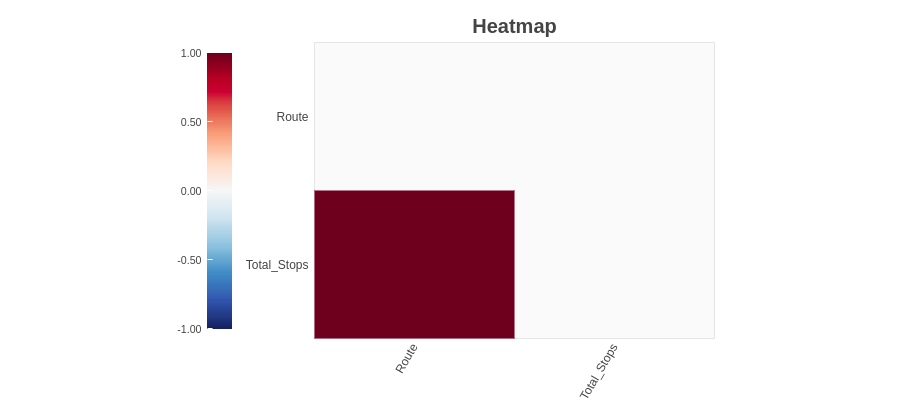
O método do mapa de calor mostra as variáveis que têm valores ausentes em termos de correlação. Desde ‘Route’ e ‘Total_Paradas’ são altamente correlacionados, ambos têm valores ausentes.
Como podemos observar, as 'Variáveis de caminho’ e ‘Total_Paradas’ tem valores ausentes. Uma vez que não encontramos nenhuma informação de valor ausente no método do gráfico de barras do espectro, mas encontramos variáveis de valor ausente usando o método de mapa de calor. Combinando essas informações, podemos dizer que a rota das variáveis’ e ‘Total_Paradas’ têm valores ausentes, mas são muito baixos.
5. Preparação de dados
Antes de iniciar a preparação de dados, vamos dar uma olhada nos dados primeiro.
dataframe.head()

Como vimos na Análise de Dados, existem 11 variáveis nos dados fornecidos. Abaixo está a descrição de cada variável.
CIA aérea: Nome da companhia aérea usada para viajar
Date_of_Journey: Data em que uma pessoa viajou
Fonte: Local de início do voo
Destino: Localização final do voo
Rota: Contém informações sobre o local de início e término da viagem no formato padrão usado pelas companhias aéreas.
Dept_Time: Horário de partida do voo a partir do ponto de partida
Hora da chegada: Horário de chegada do vôo no destino
Duração: Duração do voo em horas / minutos
Total_Stops: Número total de escalas feitas pelo voo antes de pousar no destino.
Informação adicional: Mostre qualquer informação adicional sobre um voo
Preço: Preço do voo
Poucas observações sobre algumas das variáveis:
1. ‘Preço‘Será nossa variável dependente e todas as variáveis restantes podem ser usadas como variáveis independentes.
2. ‘Total_Stops'Pode ser usado para determinar se o vôo foi direto ou em conexão.
5.1 Tratamento de valores ausentes
Como descobrimos, as 'Variáveis de caminho’ e ‘Total_Paradas’ têm valores ausentes muito baixos nos dados. Vamos agora ver a porcentagem de valores ausentes nos dados.
(dataframe.isnull().soma()/dataframe.shape[0])*100
Produção :
CIA aérea 0.000000 Date_of_Journey 0.000000 Fonte 0.000000 Destino 0.000000 Rota 0.009361 Dept_Time 0.000000 Tempo de chegada 0.000000 Duração 0.000000 Total_Stops 0.009361 Informação adicional 0.000000 Preço 0.000000 tipo d: float64
Como podemos observar, 'Rota’ y ‘Total_Stops’ eles têm ambos 0.0094% de valores perdidos. Neste caso, é melhor remover os valores ausentes.
dataframe.dropna(inplace = True) dataframe.isnull().soma()
Produção :
CIA aérea 0 Date_of_Journey 0 Fonte 0 Destino 0 Rota 0 Dept_Time 0 Tempo de chegada 0 Duração 0 Total_Stops 0 Informação adicional 0 Preço 0 tipo d: int64
Agora não perdemos valor.
5.2 Manipulação de variáveis de data e hora
Tenemos ‘Date_of_Journey’, uma 'variável de tipo de data e’ Dept_Time ',’ Arrival_Time 'que captura informações de tempo.
Podemos extrair ‘Journey_day’ y ‘Journey_Month’ de la variable ‘Date_of_Journey’. “Dia de viagem” mostra o dia do mês em que a viagem começou.
quadro de dados["Journey_day"] = pd.to_datetime(dataframe.Date_of_Journey, format ="%d /% m /% Y").dt.dia quadro de dados["Journey_month"] = pd.to_datetime(quadro de dados["Date_of_Journey"], format = "%d /% m /% Y").dt.month quadro de dados.derrubar(["Date_of_Journey"], eixo = 1, inplace = True)
de forma similar, podemos extrair "hora de partida’ e ‘hora de partida’ bem como 'hora de chegada e minuto de chegada’ das variáveis ‘Time_dep.’ E 'hora de chegada’ respectivamente.
quadro de dados["Dep_hour"] = pd.to_datetime(quadro de dados["Dept_Time"]).dt.hour quadro de dados["Dep_min"] = pd.to_datetime(quadro de dados["Dept_Time"]).dt.minute quadro de dados.derrubar(["Dept_Time"], eixo = 1, inplace = True)
quadro de dados["Hora_de_chegada"] = pd.to_datetime(dataframe.Arrival_Time).dt.hour quadro de dados["Arrival_min"] = pd.to_datetime(dataframe.Arrival_Time).dt.minute quadro de dados.derrubar(["Tempo de chegada"], eixo = 1, inplace = True)
Também temos informações sobre a duração da variável 'Duração'. Esta variável contém informações combinadas de horas e minutos de duração.
Podemos extrair ‘Duração_horas’ e ‘Duração_minutos’ separadamente da variável 'Duração'.
def get_duration(x):
x=x.split('')
hours=0
mins=0
if len(x)== 1:
x=x[0]
se x[-1]=='h':
horas=int(x[:-1])
outro:
mins=int(x[:-1])
outro:
horas=int(x[0][:-1])
mins=int(x[1][:-1])
horas de retorno,mins
dataframe['Duration_hours']=dataframe. Duração.aplicar(lambda x:get_duration(x)[0])
quadro de dados['Duration_mins']=dataframe. Duração.aplicar(lambda x:get_duration(x)[1])
dataframe.drop(["Duração"], eixo = 1, inplace = True)
5.3 Gerenciamento categórico de dados
CIA aérea, Origem, Destino, Rota, Total_Stops, Informações adicionais são as variáveis categóricas que temos em nossos dados. Vamos cuidar de cada um por um..
Variável aérea
Vamos ver como a variável Airline se relaciona com a variável Preço.
import seaborn as sns
sns.set()
sns.catplot(y = "Preço", x = "CIA aérea", dados = train_data.sort_values("Preço", ascendente = Falso), kind ="Box", altura = 6, aspecto = 3)
plt.show()
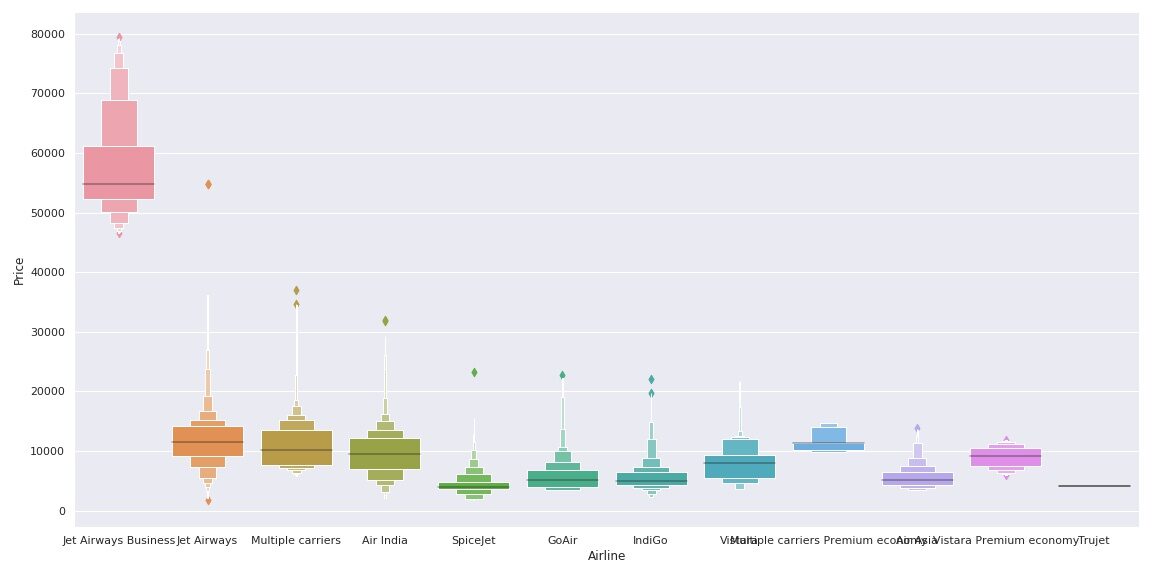
Como podemos ver, nome da companhia aérea importa. 'JetAirways Business’ tem a faixa de preço mais alta. O preço de outras companhias aéreas também varia.
os usuários que não responderam ao acompanhamento e os seguidores que você não segue CIA aérea variável é Dados categóricos nominais (Não há ordem de nenhum tipo nos nomes das companhias aéreas) usaremos codificação one-hot para lidar com esta variável.
Airline = dataframe[["CIA aérea"]] Airline = pd.get_dummies(CIA aérea, drop_first = True)
Os dados de ‘Airline’ codificados em One-Hot são armazenados na variável Airline conforme mostrado no código acima.
Variável de origem e destino
Novamente, as 'Variáveis de origem’ e ‘Destino’ são dados categóricos nominais. Usaremos a codificação One-Hot novamente para lidar com essas duas variáveis.
Fonte = dataframe[["Fonte"]] Source = pd.get_dummies(Fonte, drop_first = True) Destination = train_data[["Destino"]] Destino = pd.get_dummies(Destino, drop_first = True)
Variável de caminho
A variável path representa o caminho da jornada. Já que a variável ‘Total_Stops’ captura a informação se o vôo é direto ou conectado, Eu decidi eliminar esta variável.
dataframe.drop(["Rota", "Informação adicional"], eixo = 1, inplace = True)
Variável Total_Stops
quadro de dados["Total_Stops"].exclusivo()
Produção:
variedade(['sem parar', '2 paradas', '1 parada', '3 paradas', '4 paragens'],
dtype = objeto)
Aqui, meios sem parar 0 escalas, o que vôo direto significa. de forma similar, o significado de outros valores é óbvio. Podemos ver que é um Dados categóricos ordinais então vamos usar LabelEncoder aqui para lidar com esta variável.
dataframe.replace({"sem parar": 0, "1 Pare": 1, "2 pára": 2, "3 pára": 3, "4 pára": 4}, inplace = True)
Variável Additional_Info
dataframe.Additional_Info.unique()
Produção:
variedade(['Nenhuma informação', 'Refeição a bordo não incluída',
'Sem bagagem de porão incluída', '1 escala curta', 'Nenhuma informação',
'1 longa espera', 'Alterar aeroportos', 'Classe executiva',
'Voo de olhos vermelhos', '2 longa espera'], dtype = objeto)
Como podemos ver, este recurso captura informações relevantes que podem afetar significativamente o preço do voo. Os valores ‘Sem informação’ também são repetidos.. Vamos cuidar disso primeiro.
quadro de dados['Informação adicional'].substituir({"Nenhuma informação": 'Nenhuma informação'}, inplace = True)
Contudo, esta variável também é um dado categórico nominal. Vamos usar a codificação one-hot para lidar com essa variável.
Add_info = dataframe[["Informação adicional"]] Add_info = pd.get_dummies(Add_info, drop_first = True)
5.4 Quadro de dados final
Agora criaremos o quadro de dados final concavando todos os recursos codificados por tags e one-hot no quadro de dados original. Também eliminaremos as variáveis originais com as quais preparamos novas variáveis codificadas.
dataframe = pd.concat([quadro de dados, CIA aérea, Fonte, Destino,Add_info], eixo = 1) dataframe.drop(["CIA aérea", "Fonte", "Destino","Informação adicional"], eixo = 1, inplace = True)
Vamos olhar para o número de variáveis finais que temos no quadro de dados.
dataframe.shape[1]
Produção:
38
Então, tenho 38 variáveis no quadro de dados final, incluindo a variável dependente 'Preço'. Só há 37 variables para el TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.....
6. Construção de maquete
X=dataframe.drop('Preço',eixo = 1)
y=dataframe['Preço']
#train-test split
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, e, test_size = 0.2, random_state = 42)
6.1 Aplicação de previsão preguiçosa
Um dos problemas com o exercício de modelagem é “Como decidir qual algoritmo de aprendizagem de máquina aplicar?”
É aqui que entra a Previsão Preguiçosa.. Lazy Forecast é uma biblioteca de aprendizado de máquina disponível em Python que pode rapidamente nos fornecer o desempenho de múltiplas classificações padrão ou modelos de regressão em múltiplas matrizes de desempenho..
Vamos ver como funciona...
Como estamos trabalhando em uma tarefa de regressão, vamos usar modelos Regresores.
from lazypredict.Supervised import LazyRegressor
reg = LazyRegressor(verbose = 0, ignore_warnings=Falso, custom_metric=Nenhum)
Modelos, previsões = reg.fit(x_train, x_test, y_train, y_test)
modelos.cabeça(10)
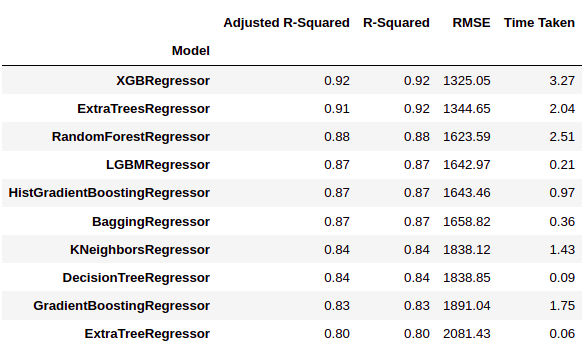
Como podemos ver, Predict Lazy nos dá resultados de vários modelos em matrizes de desempenho múltiplos. Na figura acima, nós mostramos os dez melhores modelos.
Aqui 'XGBRegressor’ e 'ExtraTreesRegressor’ significativamente superar outros modelos. Leva muito tempo de treinamento em relação a outros modelos. Nesta etapa podemos escolher a prioridade se quisermos “clima” o “Desempenho”.
Nós decidimos escolher “Desempenho” sobre o tempo de treinamento. Então vamos treinar 'XGBRegressor e visualizar os resultados finais.
6.2 Treinamento de modelo
from xgboost import XGBRegressor
model = XGBRegressor()
model.fit(x_train,y_train)
Produção:
XGBRegressor(base_score=0,5, reforço="gbtree", colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gama=0, gpu_id=-1,
importance_type="ganhar", interaction_constraints="",
learning_rate=0,30000012, max_delta_step=0, max_depth=6,
min_child_weight=1, missing=nan, monotone_constraints="()",
n_estimators = 100, n_jobs=0, num_parallel_tree=1, random_state = 0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, subsample=1,
tree_method='exata', validate_parameters=1, verbosity=Nenhum)
Vamos verificar o desempenho do modelo …
y_pred = modelo.prever(x_test)
imprimir('Pontuação de treinamento :',modelo.score(x_train, y_train))
imprimir('Pontuação de teste :',modelo.score(x_test, y_test))
Produção:
Pontuação de treinamento : 0.9680428701701702 Pontuação do teste : 0.918818721300552
Como podemos ver, pontuação modelo é muito bom. Vamos visualizar os resultados de algumas previsões.
number_of_observations=50
x_ax = range(len(y_test[:number_of_observations]))
plt.plot(x_ax, y_test[:number_of_observations], rótulo ="Original")
plt.plot(x_ax, y_pred[:number_of_observations], rótulo ="previsto")
plt.title("Teste de preço de voo e dados previstos")
plt.xlabel('Número de observação')
plt.ylabel('Preço')
plt.legend()
plt.show()
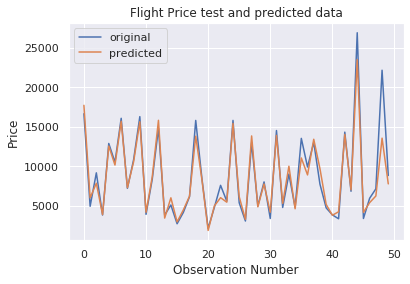
Como podemos ver na figura acima, previsões de modelo e preços originais se sobrepõem. Este resultado visual confirma a pontuação alta do modelo que vimos anteriormente..
7. conclusão
Neste artigo, vimos como aplicar a biblioteca Laze Forecast para escolher o melhor algoritmo de aprendizado de máquina para a tarefa em questão.
O Lazy Prediction economiza tempo e esforço para criar um modelo de aprendizado de máquina, fornecendo desempenho do modelo e tempo de treinamento. Pode-se escolher qualquer um de acordo com a situação em questão.
Ele também pode ser usado para criar um conjunto de modelos de aprendizado de máquina. Existem muitas maneiras de usar as funcionalidades da biblioteca LazyPredict.
Espero que este artigo tenha ajudado você a entender as abordagens de análise de dados, preparação e modelagem de dados de uma maneira muito mais fácil.
Entre em contato com a seção de comentários em caso de qualquer dúvida.
Obrigado e tenha um bom dia.. 🙂
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





