Este artigo foi publicado como parte do Data Science Blogathon.
Introdução
O Big Data é frequentemente caracterizado por: –
uma) Volume: – Volume significa uma enorme, enorme quantidade de dados que precisam ser processados.
B) Velocidade: – A velocidade com que os dados chegam como processamento em tempo real.
C) Veracidade: – Veracidade significa a qualidade dos dados (o que deve ser ótimo para gerar relatórios de análise, etc.)
D) Variedade: – Isso significa que os diferentes tipos de dados, como
* Dados estruturados: – Dados em formato de tabela.
* Dados não estruturados: – Dados não em formato de tabela
* Dados semiestruturados: – Mistura de dados estruturados e não estruturados.
Para trabalhar com grandes bytes de dados, primeiro precisamos armazenar ou despejar os dados em algum lugar. Por tanto, a solução para isso é HDFSHDFS, o Sistema de Arquivos Distribuído Hadoop, É uma infraestrutura essencial para armazenar grandes volumes de dados. Projetado para ser executado em hardware comum, O HDFS permite a distribuição de dados em vários nós, garantindo alta disponibilidade e tolerância a falhas. Sua arquitetura é baseada em um modelo mestre-escravo, onde um nó mestre gerencia o sistema e os nós escravos armazenam os dados, facilitando o processamento eficiente de informações.. (Sistema de arquivos distribuídoUm sistema de arquivos distribuído (DFS) Permite armazenamento e acesso a dados em vários servidores, facilitando o gerenciamento de grandes volumes de informações. Esse tipo de sistema melhora a disponibilidade e a redundância, à medida que os arquivos são replicados para locais diferentes, Reduzindo o risco de perda de dados. O que mais, Permite que os usuários acessem arquivos de diferentes plataformas e dispositivos, promovendo colaboração e... Hadoop).
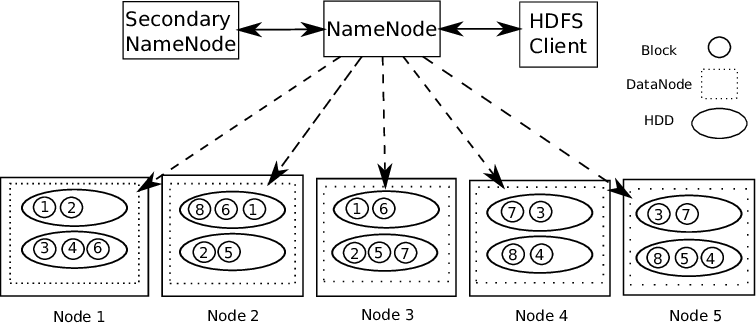
Suporte para Hadoop Arquitetura mestre-escravo. É um tipo de sistema distribuído onde o processamento de dados paralelo é realizado.. O Hadoop consiste em 1 mestre e vários escravos.
NodoO Nodo é uma plataforma digital que facilita a conexão entre profissionais e empresas em busca de talentos. Através de um sistema intuitivo, permite que os usuários criem perfis, Compartilhar experiências e acessar oportunidades de trabalho. Seu foco em colaboração e networking torna o Nodo uma ferramenta valiosa para quem deseja expandir sua rede profissional e encontrar projetos que se alinhem com suas habilidades e objetivos.... de regla de nombre: – Para cada bloco de dados armazenado, existem 2 cópias presentes. Uma em diferentes nós de dados e uma segunda cópia em outro nó de dados. Desta forma, problema de tolerância a falhas corrigido.
O nó de nome contém as seguintes informações: –
1) Informações de metadados para arquivos armazenados em nós de dados. Os metadados consistem em 2 registros: FsImage e EditLogs. FsImage consiste no estado completo do sistema de arquivos desde o início do Name Node. EditLogs contém modificações recentes feitas no sistema de arquivos.
2) localização do bloco de arquivos armazenados no nó de dados.
3) tamanho do arquivo.
O nó de dados contém os dados reais.
Portanto, Suporta HDFS integridade de dados. Os dados armazenados são verificados se estão corretos ou não, comparando os dados com sua soma de verificação. Se forem detectadas falhas, o nó de nomes é informado. Portanto, cria cópias adicionais dos mesmos dados e exclui cópias danificadas.
O HDFS consiste em nó de nome secundário que funciona ao mesmo tempo que o Name Node principal como um daemon auxiliar. Não é um nó de nome de backup. Lê constantemente todos os sistemas de arquivos e metadados da RAM do Name Node para o disco rígido. É responsável por combinar EditLogs com FSImage de Name Node.
Portanto, O HDFS é como um data warehouse onde podemos despejar qualquer tipo de dados. El procesamiento de estos datos requiere herramientas de Hadoop como ColmeiaHive é uma plataforma de mídia social descentralizada que permite que seus usuários compartilhem conteúdo e se conectem com outras pessoas sem a intervenção de uma autoridade central. Usa a tecnologia blockchain para garantir a segurança e a propriedade dos dados. Ao contrário de outras redes sociais, O Hive permite que os usuários monetizem seu conteúdo por meio de recompensas criptográficas, que incentiva a criação e a troca ativa de informações .... (para lidar com dados estruturados), HBaseO HBase é um banco de dados NoSQL projetado para lidar com grandes volumes de dados distribuídos em clusters. Com base no modelo de coluna, Permite acesso rápido e dimensionável às informações. O HBase se integra facilmente ao Hadoop, tornando-o uma escolha popular para aplicativos que exigem armazenamento e processamento massivos de dados. Sua flexibilidade e capacidade de crescimento o tornam ideal para projetos de big data.... (para lidar com dados não estruturados), etc. O Hadoop suporta o conceito “escreva uma vez, pronto para muitos”.
Então, vamos dar um exemplo e entender como podemos processar uma enorme quantidade de dados e realizar muitas transformações usando a linguagem Scala.
UMA) Configurando o Eclipse IDE com configuração Scala.
Link para baixar o Eclipse IDE – https://www.eclipse.org/downloads/
Você deve baixar o Eclipse IDE considerando os requisitos do seu computador. Ao iniciar o Eclipse IDE, você verá esse tipo de tela.

Vamos para Ajudar -> Mercado Eclipse -> Olhe para -> Scala-Ide -> Instalar no pc
Depois disso no Eclipse IDE – selecionar perspectiva aberta -> Scala, você obterá todos os componentes scala no ide para usar.
Crie um novo projeto no eclipse e atualize o arquivo pom com as seguintes etapas:https://medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883
Altere a versão da biblioteca scala clicando com o botão direito do mouse em Projeto -> caminho de construção -> Configurar caminho de compilação.
Atualize o projeto clicando com o botão direito do mouse em Projeto -> Especialista -> Atualizar projeto maven -> Forçar atualização de instantâneo / versões. Portanto, o arquivo pom é salvo e todas as dependências necessárias são baixadas para o projeto.
Depois disso, baixe a versão do Spark com os winutils do Hadoop colocados no caminho da lixeira. Siga este caminho para concluir a configuração: https://stackoverflow.com/questions/25481325/how-to-set-up-spark-on-windows
B) Criar sessões do Spark – 2 tipos.
Spark Session é o ponto de entrada ou o começo para criar RDD'S, Quadro de dados, Conjuntos de dados. Para criar qualquer aplicativo Spark, primero necesitamos una sessãoo "Sessão" É um conceito-chave no campo da psicologia e da terapia. Refere-se a uma reunião agendada entre um terapeuta e um cliente, onde os pensamentos são explorados, Emoções e comportamentos. Essas sessões podem variar em duração e frequência, e seu principal objetivo é facilitar o crescimento pessoal e a resolução de problemas. A eficácia das sessões depende da relação entre o terapeuta e o terapeuta.. de chispa.
A Sessão Spark pode ser de 2 tipos: –
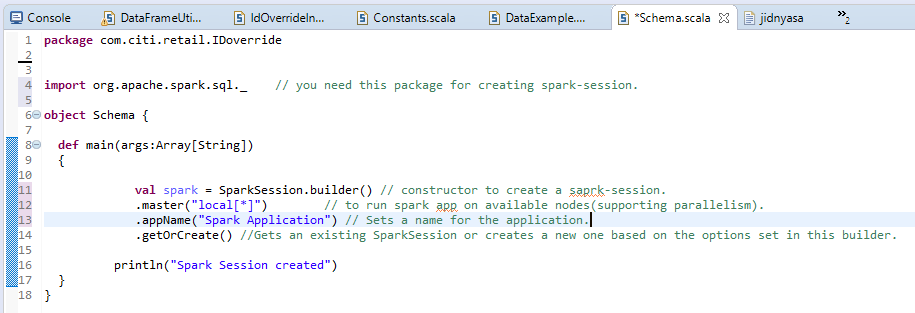
uma) Iniciar sessão normal: –
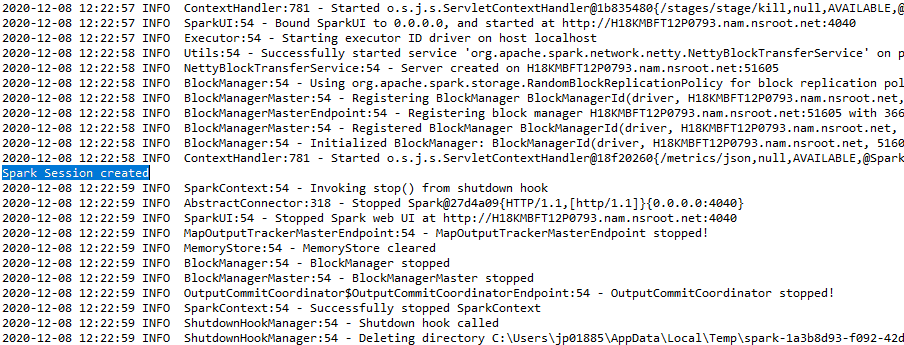
A saída será exibida como: –
b) Sessão do Spark para o ambiente Hive: –
Para criar um ambiente de colmeia em escala, precisamos da mesma sessão de faísca com uma linha extra adicionada. enableHiveSupport () – ativar suporte de colmeia, incluindo conectividade com o metastore Hive persistente, suporte para serdes Hive e funções definidas pelo usuário Hive.
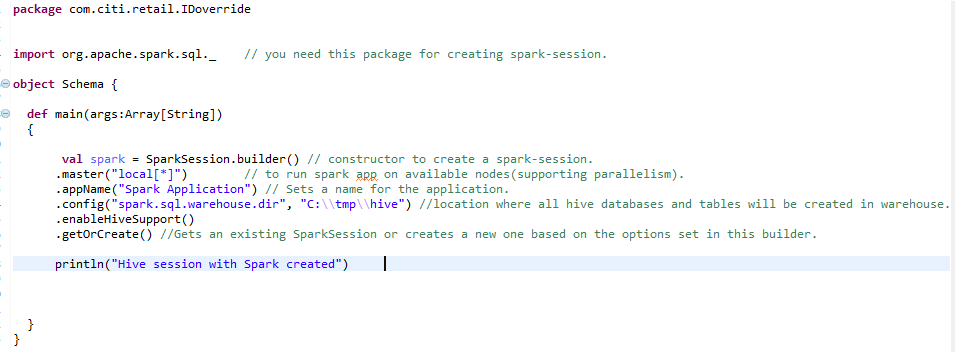
C) Creación de RDD (Conjunto de dados distribuído resiliente)RDD (Conjunto de dados distribuído resiliente) é uma abstração fundamental no Apache Spark que permite o processamento eficiente de grandes volumes de dados. É caracterizada por sua capacidade de ser tolerante a falhas, Habilitando a recuperação de dados perdidos reconstruindo partições. RDDs são imutáveis, Facilitando a paralelização de operações e melhorando o desempenho na computação distribuída. Seu uso é essencial para a análise dos dados.. e transformação de RDD em DataFrame: –
Então, após a primeira etapa de criação da Spark-Session, somos livres para criar RDD, conjuntos de dados ou dataframes. Estas são as estruturas de dados nas quais podemos armazenar grandes quantidades de dados.
Elástico:- significa tolerância a falhas para que eles possam recalcular partições ausentes ou danificadas devido a falhas de nó.
Distribuído:- significa que os dados são distribuídos por vários nós (poder do paralelismo).
Conjuntos de dados: – Dados carregáveis externamente que podem estar em qualquer formato, quer dizer, JSONJSON, o Notação de objeto JavaScript, É um formato leve de troca de dados que é fácil para os humanos lerem e escreverem, e fácil para as máquinas analisarem e gerarem. É comumente usado em aplicativos da web para enviar e receber informações entre um servidor e um cliente. Sua estrutura é baseada em pares de valores-chave, tornando-o versátil e amplamente adotado no desenvolvimento de software.., CSV ou arquivo de texto.
Os recursos dos RDDs incluem: –
uma) Cálculo na memória: – Depois de realizar transformações nos dados, os resultados são armazenados na RAM em vez de no disco. Portanto, RDD não pode usar grandes conjuntos de dados. A solução para isso é, em vez de usar RDD, o uso do DataFrame é considerado / Conjunto de dadosuma "conjunto de dados" ou conjunto de dados é uma coleção estruturada de informações, que pode ser usado para análise estatística, Aprendizado de máquina ou pesquisa. Os conjuntos de dados podem incluir variáveis numéricas, categórico ou textual, e sua qualidade é crucial para resultados confiáveis. Seu uso se estende a várias disciplinas, como remédio, Economia e Ciências Sociais, facilitando a tomada de decisão informada e o desenvolvimento de modelos preditivos.....
B) avaliações preguiçosas: – Isso significa que as ações das transformações realizadas são avaliadas apenas quando o valor é necessário.
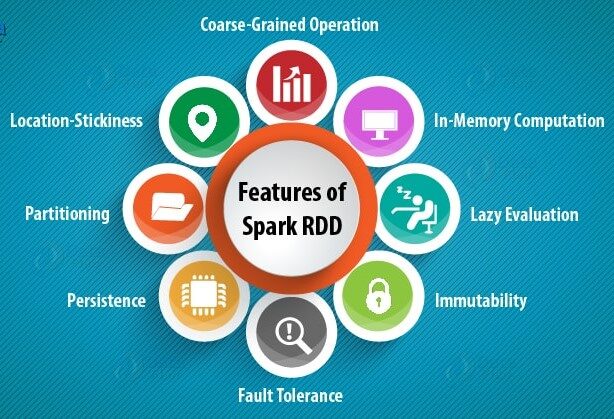
C) Tolerância ao erro: – Spark RDDs são tolerantes a falhas, pois rastreiam informações de linhagem de dados para reconstruir automaticamente dados perdidos em caso de falha.
D) Imutabilidade: – dados imutáveis (não modificáveis) são sempre seguros para compartilhar em vários processos. Podemos recriar o RDD a qualquer momento.
mim) Divisão: – Significa dividir os dados, para que cada partição possa ser executada por nós diferentes, para que o processamento de dados se torne mais rápido.
F) Persistência:- Os usuários podem escolher qual RDD eles precisam usar e escolher uma estratégia de armazenamento para eles.
grama) Operações grosseiras: – Isso significa que quando os dados são divididos em diferentes clusters para diferentes operações, podemos aplicar transformaciones una vez para todo el cachoUm cluster é um conjunto de empresas e organizações interconectadas que operam no mesmo setor ou área geográfica, e que colaboram para melhorar sua competitividade. Esses agrupamentos permitem o compartilhamento de recursos, Conhecimentos e tecnologias, Promover a inovação e o crescimento económico. Os clusters podem abranger uma variedade de setores, Da tecnologia à agricultura, e são fundamentais para o desenvolvimento regional e a criação de empregos.... y no para diferentes particiones por separado.
D) Usando o quadro de dados e realizando transformações: –
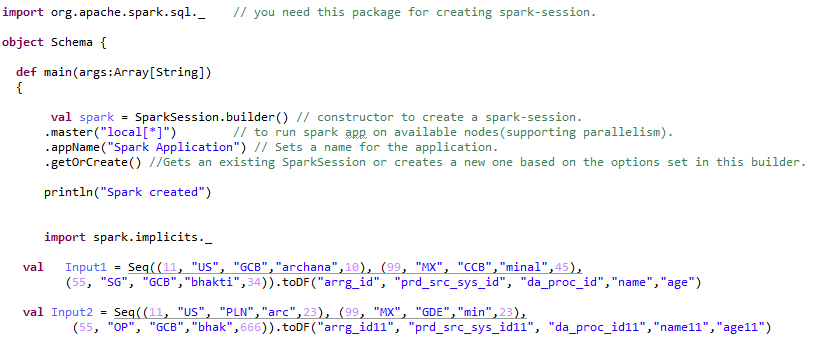
Ao converter RDD em dataframes, deve adicionar import spark.implicits._ depois da faísca sessão.
O quadro de dados pode ser criado de várias maneiras. Vejamos as diferentes transformações que podem ser aplicadas ao quadro de dados.
Paso 1:- Criando quadro de dados: –
Paso 2:- Executando diferentes tipos de transformações em um quadro de dados: –
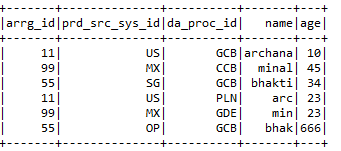
uma) Por favor selecione:- Selecione as colunas necessárias do quadro de dados que o usuário requer.
Entrada1.selecionar (“arrg_id”, “da_proc_id”). Mostrar ()

B) selecioneExpr: – Selecione as colunas necessárias e também renomeie as colunas.
Input2.selectExpr (“arrg_id11”, “prd_src_sys_id11 como prd_src_new”, “da_proc_id11”). Mostrar ()

C) com coluna: – withColumns ajuda a adicionar uma nova coluna com o valor específico que o usuário deseja no dataframe selecionado.
Entrada1.comColuna (“Nova_coluna”, iluminado (nulo))

D) withColumnRenamed: – Renomeia as colunas do dataframe específico que o usuário requer.
Input1.withColumnRenamed (“da_proc_id”, “da_proc_id_newname”)

mim) soltar:- Remova as colunas que o usuário não deseja.
Input2.drop (“arrg_id11 ″,” prd_src_sys_id11 ″, “da_proc_id11”)
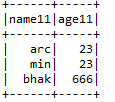
F) Entrar:- UMA 2 dataframes junto com chaves de junção de ambos os dataframes.
Entrada1.junção (Entrada2, Entrada1.col (“arrg_id”) === Entrada2.col (“arrg_id11 ″),” direito “)
.withColumn (“prd_src_sys_id”, iluminado (nulo))
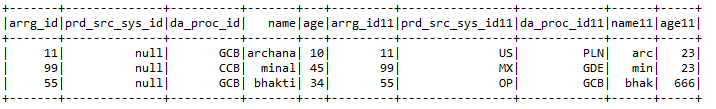
grama) Recursos adicionados:- Alguns dos recursos adicionados incluem
* Contar:- Dá a contagem de uma coluna específica ou a contagem do dataframe como um todo.
println (Entrada1.contagem ())
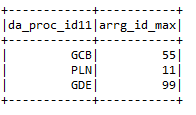
* Máx .: – Dá o valor máximo da coluna de acordo com uma condição particular.
entrada2.grupopor (“da_proc_id”). max (“arrg_id”). withColumnRenamed (“max (arrg_id)”,
“Arrg_id_max”)
* Mín.: – Fornece um valor mínimo da coluna do dataframe.

h) filtro: – Filtre as colunas de um quadro de dados executando uma condição específica.

eu) printSchema: – Forneça detalhes como nomes de colunas, tipos de dados de coluna e se as colunas podem ser anuláveis ou não.
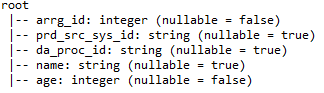
j) União: – Combine os valores de 2 dataframes, desde que os nomes das colunas de ambos os dataframes sejam os mesmos.
MIM) Colmeia:-
Hive é um dos bancos de dados mais usados em Big Data. Es una especie de base de dadosUm banco de dados é um conjunto organizado de informações que permite armazenar, Gerencie e recupere dados com eficiência. Usado em várias aplicações, De sistemas corporativos a plataformas online, Os bancos de dados podem ser relacionais ou não relacionais. O design adequado é fundamental para otimizar o desempenho e garantir a integridade das informações, facilitando assim a tomada de decisão informada em diferentes contextos.... relacional donde los datos se almacenan en formato tabular. O banco de dados padrão da colmeia é o clássico. processos de colmeia estruturada e semiestruturada dados. No caso de dados não estruturados, primeiro crie uma tabela no hive e carregue os dados na tabela, tão estruturado. O Hive suporta todos os tipos de dados primitivos SQL.
Admissão de colmeia 2 tipos de mesa: –
uma) Tabelas gerenciadas: – É a tabela padrão no hive. Quando o usuário cria uma tabela no Hive sem especificá-la como externa, por padrão, uma tabela interna é criada em um local específico no HDFS.
Por padrão, uma tabela interna será criada em um caminho de pasta semelhante a / Nome do usuário / colmeia / estoque diretório hdfs. Podemos substituir o local padrão pela propriedade de localização durante a criação da tabela.
Se descartarmos a tabela ou partição gerenciada, os dados e metadados da tabela associados a essa tabela serão removidos do HDFS.
B) mesa externa: – As tabelas externas são armazenadas fora do diretório do warehouse. Pueden acceder a los datos almacenados en fuentes como ubicaciones HDFS remotas o volúmenes de almacenamiento de Azure.
Siempre que dejamos caer la tabla externa, solo se eliminarán los metadatos asociados con la tabla, los datos de la tabla permanecen intactos por Hive.
Podemos crear la tabla externa especificando el EXTERNO palabra clave en la instrucción de tabla de creación de Hive.
Comando para crear una tabla externa.
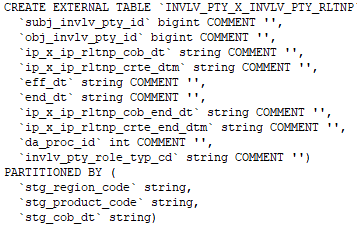
Comando para comprobar si la tabla creada es externa o no: –
desc con formato