Introdução
Você já se deparou com um conjunto de dados ou uma imagem e se perguntou se poderia criar um sistema capaz de diferenciar ou identificar a imagem??
O conceito de classificação de imagens nos ajudará nisso.. A classificação de imagens é uma das aplicações mais populares da visão computacional e um conceito obrigatório para quem deseja desempenhar um papel neste campo..
Neste artigo, Veremos um aplicativo muito simples, mas amplamente utilizado, que é o Image Classification. Não veremos apenas como fazer um modelo simples e eficiente para classificar os dados, mas também aprenderemos como implementar um modelo previamente treinado e comparar o desempenho dos dois.
No final do artigo, você será capaz de encontrar seu próprio conjunto de dados e implementar a classificação de imagens com facilidade.
Pré-requisitos antes de começar:
Parece interessante? Portanto, prepare-se para criar seu próprio classificador de imagens!!
Tabela de conteúdo
- Classificação de imagem
- Compreendendo a declaração do problema
- Configurações de dados de imagem
- Vamos construir nosso modelo de classificação de imagens
- Pré-processamento de dados
- Aumento de dados
- Definição e formação do modelo
- Avaliação de resultados
- A arte da aprendizagem transferida
- Importar modelo base MobileNetV2
- Sintonia FINA
- Treinamento
- Avaliação de resultados
- Que segue?
O que é classificação de imagem?
A classificação de imagens é a tarefa de atribuir uma imagem de entrada, uma tag de um conjunto fixo de categorias. Este é um dos problemas centrais da Visão Computacional que, apesar de sua simplicidade, tem uma grande variedade de aplicações práticas.
Vamos dar um exemplo para entender melhor. Quando fazemos a classificação da imagem, nosso sistema receberá uma imagem como entrada, por exemplo, um gato. Agora o sistema conhecerá um conjunto de categorias e seu objetivo é atribuir uma categoria à imagem.
Este problema pode parecer simples ou fácil, mas é um problema muito difícil para o computador resolver. Como você vai saber, o computador vê uma grade de números e não a imagem de um gato como o vemos. As imagens são matrizes tridimensionais de inteiros de 0 uma 255, tamanho Largura x Altura x 3. o 3 representa os três canais em vermelho, Verde, Azul.
Então, Como nosso sistema pode aprender a identificar esta imagem? Usando redes neurais convolucionais. Las redes neuronales convolucionales o CNN son una clase de redes neuronales de aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde... que representan un gran avance en el reconocimiento de imágenes. Você já deve ter um conhecimento básico da CNN, e sabemos que as CNNs consistem em camadas convolucionais, capas ReluA função de ativação do ReLU (Unidade linear retificada) É amplamente utilizado em redes neurais devido à sua simplicidade e eficácia. Definido como ( f(x) = máx.(0, x) ), O ReLU permite que os neurônios disparem apenas quando a entrada é positiva, o que ajuda a mitigar o problema do desbotamento do gradiente. Seu uso demonstrou melhorar o desempenho em várias tarefas de aprendizado profundo, tornando o ReLU uma opção..., camadas agrupadas e camadas densas totalmente conectadas.
Para ler sobre a classificação de imagens e CNN em detalhes, você pode consultar os seguintes recursos: –
- https://www.analyticsvidhya.com/blog/2020/02/learn-image-classification-cnn-convolutional-neural-networks-3-datasets/
- https://www.analyticsvidhya.com/blog/2019/01/build-image-classification-model-10-minutes/
Agora que entendemos os conceitos, vamos mergulhar em como um modelo de classificação de imagem pode ser construído e como pode ser implementado.
Compreendendo a declaração do problema
Considere a seguinte imagem:

Uma pessoa experiente em esportes será capaz de reconhecer a imagem como Rugby. Pode haver diferentes aspectos da imagem que ajudaram a identificá-la como Rugby, pode ser o formato da bola ou a roupa do jogador. Mas você percebeu que essa imagem poderia muito bem ser identificada como uma imagem de futebol??
Vamos considerar outra imagem: –

O que você acha que esta imagem representa? Difícil de adivinhar, verdade? A imagem para o olho humano inexperiente pode facilmente ser mal classificada como futebol, Mas na verdade, é uma imagem de rugby, já que podemos ver que a trave atrás não é uma rede e é maior. A questão agora é se podemos fazer um sistema que possa classificar a imagem corretamente.
Essa é a ideia por trás do nosso projeto aqui, queremos construir um sistema que seja capaz de identificar o esporte representado naquela imagem. As duas classes de classificação aqui são Rugby e Futebol.. Expor o problema pode ser um pouco complicado, pois os esportes têm muitos aspectos em comum, porém, vamos aprender como resolver o problema e criar um sistema de bom desempenho.
Configuração dos nossos dados de imagem
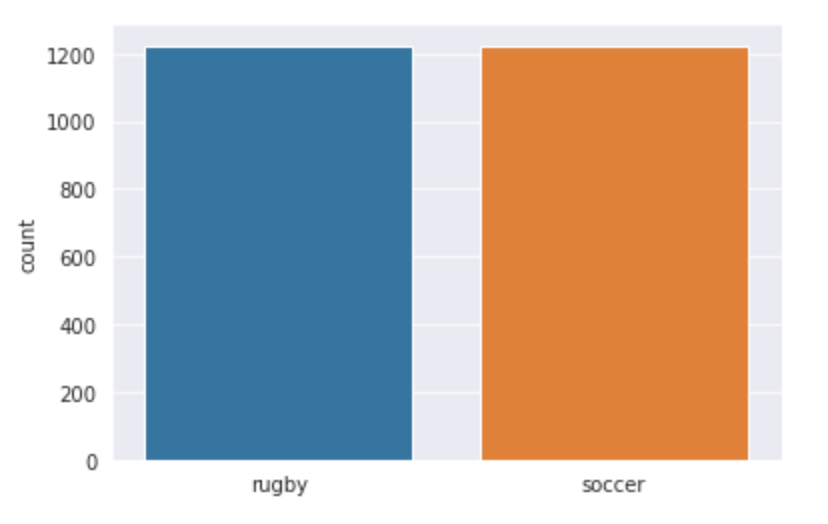
Já que estamos trabalhando em um problema de classificação de imagens, Usei duas das maiores fontes de dados de imagem, quer dizer, ImageNet e Google OpenImages. Implementei dois scripts python para que possamos baixar as imagens facilmente. Um total de 3058 imagens, que foram divididos em treinar e testar. Eu fiz uma divisão 80-20 com a pasta do trem que eu tinha 2448 imagens e a pasta de teste tem 610. Ambas as classes de rúgbi e futebol têm 1224 imagens de cada.
Nossa estrutura de dados é a seguinte: –
- Entrada – 3058
- Trem – 2048
- Rúgbi – 1224
- Futebol – 1224
- Trem – 2048
-
- Teste – 610
- Rúgbi – 310
- Futebol – 310
- Teste – 610
Vamos construir nosso modelo de classificação de imagens!
Paso 1: – Importe as bibliotecas necessárias
Aqui, usaremos a biblioteca Keras para criar nosso modelo e treiná-lo. Também usamos Matplotlib e Seaborn para visualizar nosso conjunto de dados e obter um melhor entendimento das imagens que iremos manipular.. Outra importante biblioteca para o tratamento de dados de imagem é o Opencv.
import matplotlib.pyplot as plt import seaborn as sns import keras from keras.models import Sequential from keras.layers import Dense, Conv2D , MaxPool2D , Achatar , Dropout from keras.preprocessing.image import ImageDataGenerator from keras.optimizers import Adam from sklearn.metrics import classification_report,confusion_matrix import tensorflow as tf import cv2 import os import numpy as np
Paso 2: – Carregando os dados
A seguir, vamos definir o caminho para nossos dados. Vamos definir uma função chamada get_data () que facilita a criação de nossa validação e conjunto de dados de trem. Definimos as duas tags 'Rugby'’ e 'Futebol'’ o que vamos usar. Usamos la función imread de Opencv para leer las imágenes en formato RGB y cambiar el tamaño de las imágenes a nuestro ancho y alto deseados, en este caso ambos filho 224.
a primeira coisa que fazemos é identificar se os dados são estacionários ou não estacionários ['Rugby', 'futebol']
img_size = 224
def get_data(data_dir):
dados = []
para rótulos em rótulos:
path = os.path.join(data_dir, rótulo)
class_num = rótulos.índice(rótulo)
para img em os.listdir(caminho):
Experimente:
img_arr = cv2.imread(os.path.join(caminho, img))[...,::-1] #convert BGR to RGB format
resized_arr = cv2.resize(img_arr, (img_size, img_size)) # Reshaping images to preferred size
data.append([resized_arr, class_num])
exceto exceção como e:
imprimir(e)
retorno np.array(dados)
Agora podemos facilmente buscar nossos dados de trem e validação.
trem = get_data('.. /input/traintestsports/Main/train')
val = get_data('.. /input/traintestsports/Main/test')
Paso 3: – Visualize os dados
Visualicemos nuestros datos y veamos con qué estamos trabajando exactamente. Nós usamos seaborn para traçar o número de imagens em ambas as classes e você pode ver como a saída se parece.
l = []
para eu no trem:
E se(eu[1] == 0):
l.append("rúgbi")
else
l.append("futebol")
sns.set_style('darkgrid')
sns.countplot(eu)
Produção:
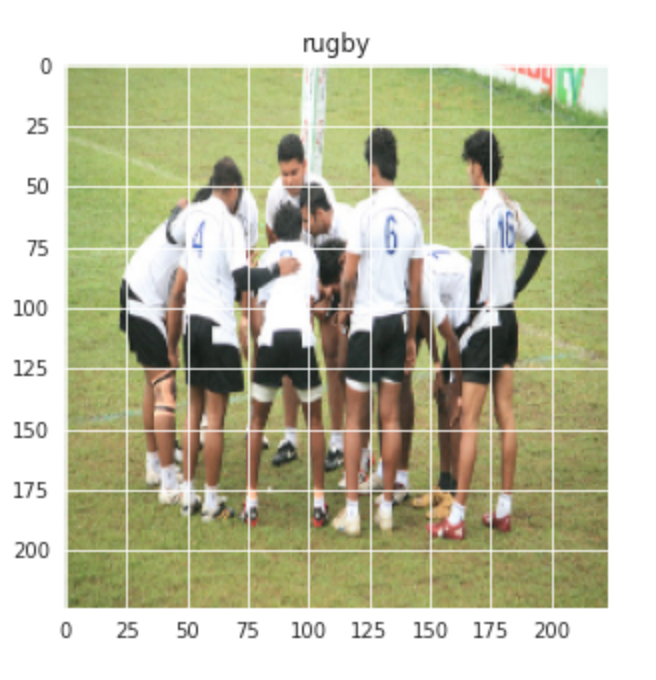
Vamos também visualizar uma imagem aleatória das aulas de Rugby e Futebol: –
plt.figure(figsize = (5,5)) plt.imshow(Comboio[1][0]) plt.title(rótulos[Comboio[0][1]])
Produção:-
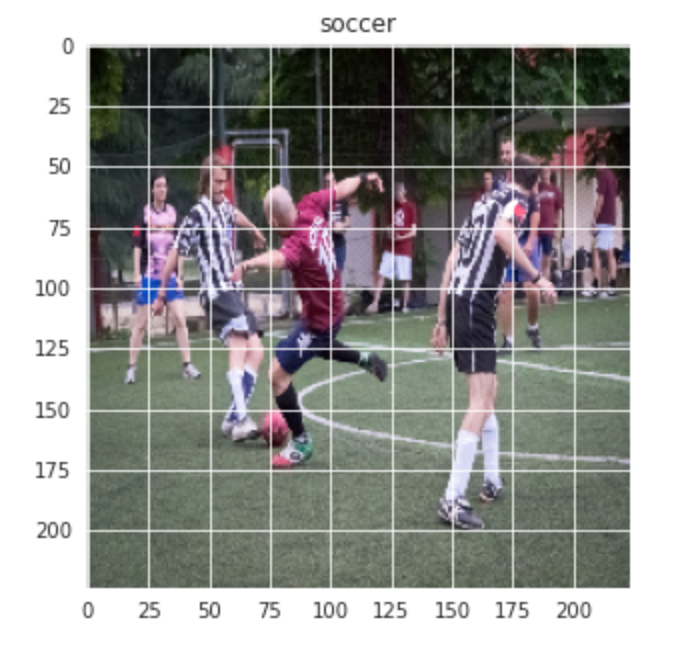
Da mesma forma para a imagem do futebol: –
plt.figure(figsize = (5,5)) plt.imshow(Comboio[-1][0]) plt.title(rótulos[Comboio[-1][1]])
Produção:-
Paso 4: – Pré-processamento e aumento de dados
A seguir, fazemos algum pré-processamento e aumento de dados antes que possamos prosseguir com a construção do modelo.
x_train = []
y_train = []
x_val = []
y_val = []
para recurso, rótulo no trem:
x_train.append(recurso)
y_train.append(rótulo)
para recurso, rótulo em val:
x_val.append(recurso)
y_val.append(rótulo)
# Normalize the data
x_train = np.array(x_train) / 255
x_val = np.array(x_val) / 255
x_train.remodele(-1, img_size, img_size, 1)
y_train = np.array(y_train)
x_val.remodele(-1, img_size, img_size, 1)
y_val = np.array(y_val)
Aumento de dados sobre dados de trens: –
datagen = ImageDataGenerator(
featurewise_center=Falso, # definir entrada significa para 0 over the dataset
samplewise_center=False, # definir cada média amostral para 0
featurewise_std_normalization=Falso, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range = 30, # rodar aleatoriamente imagens na faixa (Graus, 0 para 180)
zoom_range = 0.2, # Randomly zoom image
width_shift_range=0.1, # aleatoriamente mudar imagens horizontalmente (fração de largura total)
height_shift_range=0,1, # aleatoriamente mudar imagens verticalmente (fração de altura total)
horizontal_flip = Verdade, # randomly flip images
vertical_flip=False) # randomly flip images
datagen.fit(x_train)
Paso 5: – Definir el modelo
Definamos un modelo CNN simples con 3 camadas convolucionais seguidas por camadas de agrupamento máximo. Uma camada de queda é adicionada após a terceira operação maxpool para evitar sobreajuste.
modelo = Sequencial() model.add(Conv2D(32,3,preenchimento ="mesmo", ativação ="retomar", input_shape =(224,224,3))) model.add(MaxPool2D()) model.add(Conv2D(32, 3, preenchimento ="mesmo", ativação ="retomar")) model.add(MaxPool2D()) model.add(Conv2D(64, 3, preenchimento ="mesmo", ativação ="retomar")) model.add(MaxPool2D()) model.add(Cair fora(0.4)) model.add(Achatar()) model.add(Denso(128,ativação ="retomar")) model.add(Denso(2, ativação ="softmax")) model.summary()
Compilemos el modelo ahora usando Adam como nuestro optimizador y SparseCategoricalCrossentropy como la Função de perdaA função de perda é uma ferramenta fundamental no aprendizado de máquina que quantifica a discrepância entre as previsões do modelo e os valores reais. Seu objetivo é orientar o processo de treinamento, minimizando essa diferença, permitindo assim que o modelo aprenda de forma mais eficaz. Existem diferentes tipos de funções de perda, como erro quadrático médio e entropia cruzada, cada um adequado para diferentes tarefas e.... Estamos usando uma taxa de aprendizagem mais baixa de 0.000001 para uma curva mais suave.
opt = Adam(lr = 0,000001) model.compile(otimizador = opt , loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits = True) , metrics = ['precisão'])
Agora, vamos treinar nosso modelo durante 500 épocas, uma vez que nossa taxa de aprendizagem é muito pequena.
history = model.fit(x_train,y_train,épocas = 500 , validação_data = (x_val, y_val))
Paso 6: – Avaliação do resultado
Trazaremos nuestra precisión de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... y validación junto con la pérdida de entrenamiento y validación.
acc = history.history['precisão']
val_acc = history.history['val_accuracy']
perda = história.história['perda']
val_loss = history.history['val_loss']
epochs_range = range(500)
plt.figure(figsize =(15, 15))
plt.subplot(2, 2, 1)
plt.plot(epochs_range, acc, rótulo ="Precisão de treinamento")
plt.plot(epochs_range, val_acc, rótulo ="Precisão de validação")
plt.legend(loc ="inferior direito")
plt.title('Precisão de treinamento e validação')
plt.subplot(2, 2, 2)
plt.plot(epochs_range, perda, rótulo ="Perda de treinamento")
plt.plot(epochs_range, val_loss, rótulo ="Perda de Validação")
plt.legend(loc ="canto superior direito")
plt.title('Perda de treinamento e validação')
plt.show()
Vamos ver como fica a curva: –
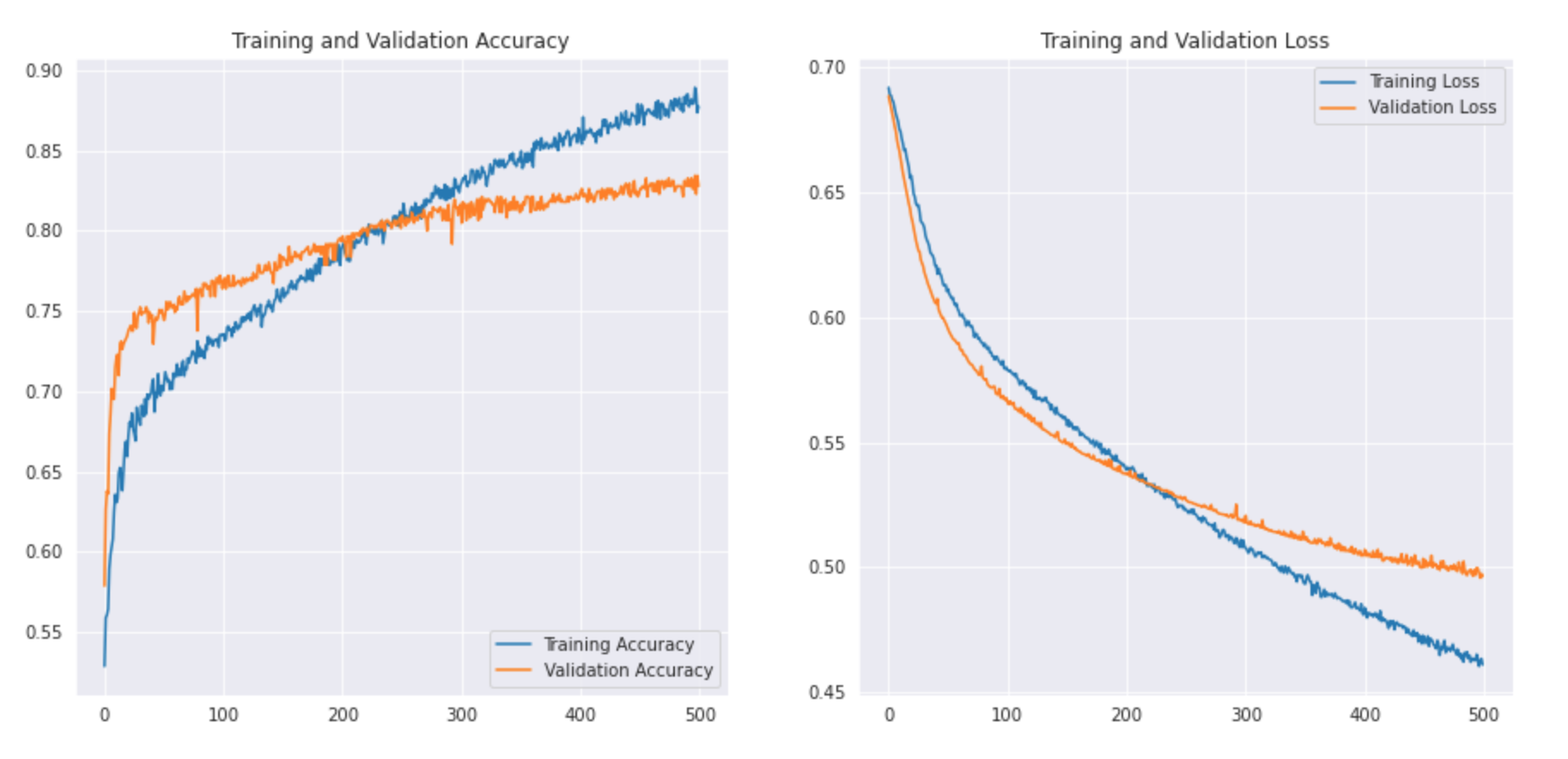
Podemos imprimir o relatório de classificação para ver a precisão e exatidão.
predictions = model.predict_classes(x_val) predictions = predictions.reshape(1,-1)[0] imprimir(classificação_report(y_val, previsões, target_names = ['Rugby (Classe 0)','Futebol (Classe 1)']))
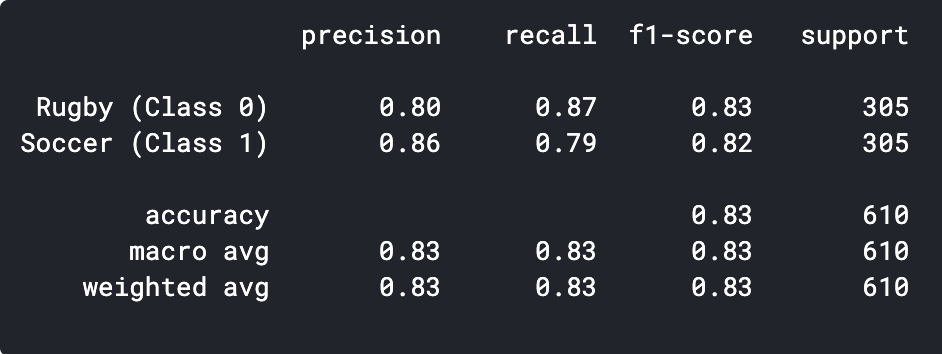
Como podemos ver, nosso modelo CNN simples foi capaz de atingir uma precisão do 83%. Com algumas configurações de hiperparâmetros, poderíamos alcançar uma precisão de 2-3%.
Também podemos visualizar algumas das imagens previstas incorretamente e ver onde nosso classificador está falhando.
A arte da aprendizagem transferida
Vamos primeiro ver o que é a aprendizagem por transferência. O aprendizado por transferência é uma técnica de aprendizado de máquina em que um modelo treinado em uma tarefa é redirecionado para uma segunda tarefa relacionada. Outra aplicação crucial da aprendizagem por transferência é quando o conjunto de dados é pequeno, Usando um modelo previamente treinado em imagens semelhantes, podemos facilmente alcançar alto desempenho. Uma vez que nossa declaração de problema é um bom ajuste para aprendizagem por transferência, vamos ver como podemos implementar um modelo pré-treinado e que precisão podemos alcançar.
Paso 1: – Importe o modelo
Vamos criar um modelo básico a partir do modelo MobileNetV2. Isso é pré-treinado no conjunto de dados ImageNet, um grande conjunto de dados que consiste em 1,4 milhões de imagens e 1000 aulas. Essa base de conhecimento nos ajudará a classificar o rúgbi e o futebol de nosso conjunto de dados específico..
Especificando o argumento include_top = False, carrega uma rede que não inclui as camadas de classificação no topo.
base_model = tf.keras.applications.MobileNetV2(input_shape = (224, 224, 3), include_top = False, pesos = "imagenet")
É importante congelar nosso banco de dados antes de compilar e treinar o modelo. O congelamento impedirá que nossos pesos de modelo base sejam atualizados durante o treinamento.
base_model.trainable = False
A seguir, definimos nosso modelo usando nosso base_model seguido por uma função GlobalA AveragePooling para converter os recursos em um único vetor por imagem. Nós adicionamos um abandono de 0.2 e o camada densaA camada densa é uma formação geológica que se caracteriza por sua alta compactação e resistência. É comumente encontrado no subsolo, onde atua como uma barreira ao fluxo de água e outros fluidos. Sua composição varia, mas geralmente inclui minerais pesados, o que lhe confere propriedades únicas. Essa camada é crucial na engenharia geológica e nos estudos de recursos hídricos, uma vez que influencia a disponibilidade e a qualidade da água.. final con 2 neurônios e ativação de softmax.
model = tf.keras.Sequential([base_model,
tf.hard.layers.GlobalAffetPooling2D(),
tf.keras.layers.Dropout(0.2),
tf.hard.layers.Dense(2, ativação ="softmax")
])
A seguir, vamos compilar o modelo e começar a treiná-lo.
base_learning_rate = 0.00001
model.compile(optimizer = tf.hard.optimizers.Adam(lr = base_learning_rate),
loss = tf.keras.losses.BinaryCrossentropy(from_logits = True),
metrics =['precisão'])
history = model.fit(x_train,y_train,épocas = 500 , validação_data = (x_val, y_val))
Paso 2: – Avaliação do resultado.
acc = history.history['precisão']
val_acc = history.history['val_accuracy']
perda = história.história['perda']
val_loss = history.history['val_loss']
epochs_range = range(500)
plt.figure(figsize =(15, 15))
plt.subplot(2, 2, 1)
plt.plot(epochs_range, acc, rótulo ="Precisão de treinamento")
plt.plot(epochs_range, val_acc, rótulo ="Precisão de validação")
plt.legend(loc ="inferior direito")
plt.title('Precisão de treinamento e validação')
plt.subplot(2, 2, 2)
plt.plot(epochs_range, perda, rótulo ="Perda de treinamento")
plt.plot(epochs_range, val_loss, rótulo ="Perda de Validação")
plt.legend(loc ="canto superior direito")
plt.title('Perda de treinamento e validação')
plt.show()
Vamos ver como fica a curva: –
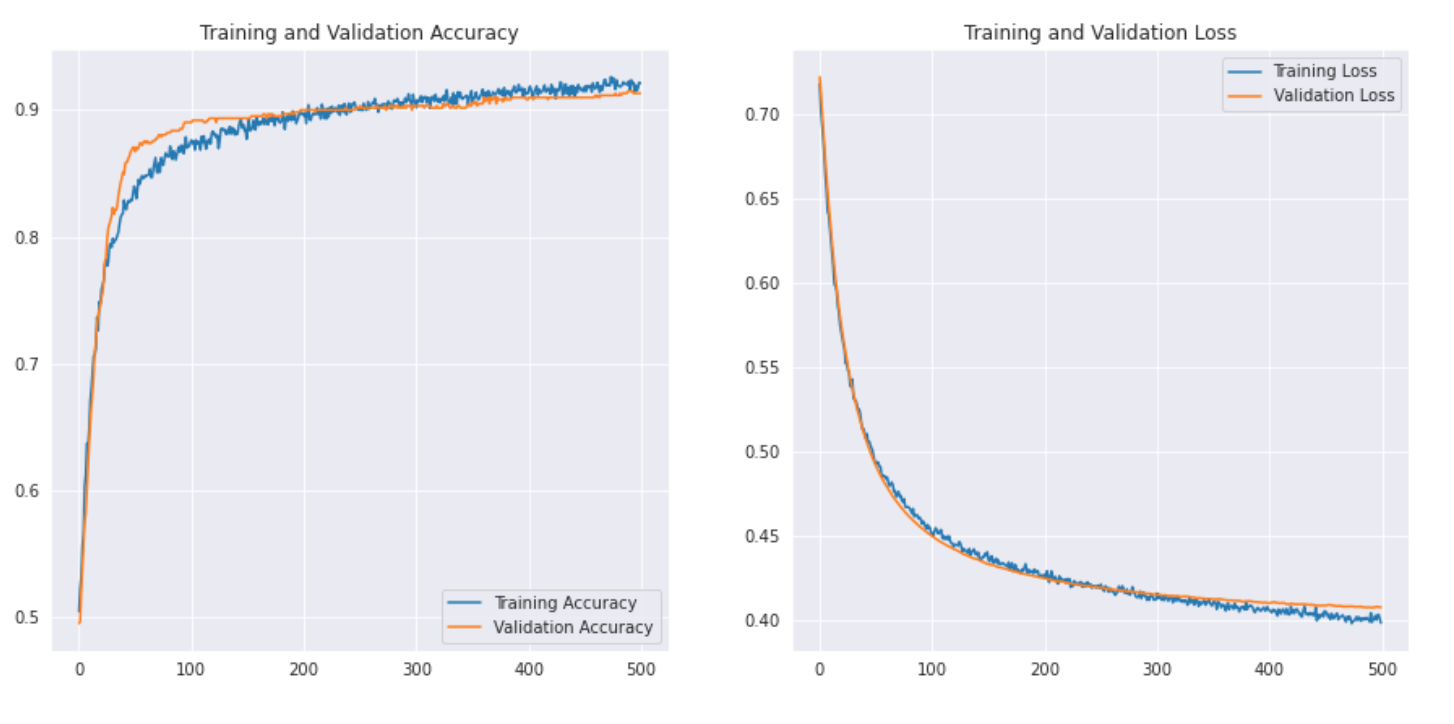
Também imprimimos o relatório de classificação para obter resultados mais detalhados.
predictions = model.predict_classes(x_val) predictions = predictions.reshape(1,-1)[0] imprimir(classificação_report(y_val, previsões, target_names = ['Rugby (Classe 0)','Futebol (Classe 1)']))
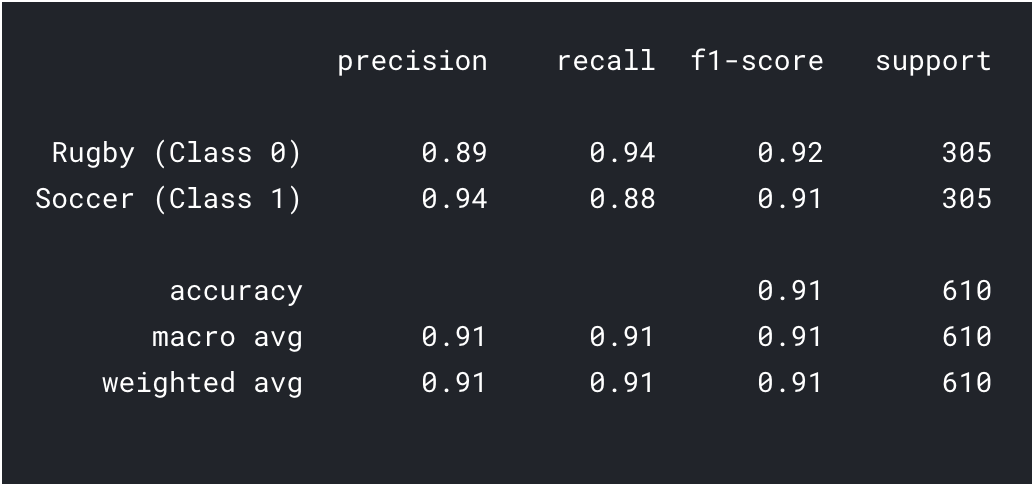
Como podemos ver com a aprendizagem por transferência, conseguimos um resultado muito melhor. A precisão do Rugby e do Futebol é superior ao nosso modelo CNN e também a precisão geral alcançou o 91%, o que é realmente bom para um conjunto de dados tão pequeno. Con un poco de ajuste de hiperparámetros y cambios de parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto...., Também poderíamos ter um desempenho um pouco melhor!!
Que segue?
Este é apenas o ponto de partida no campo da visão computacional.. De fato, tente melhorar seus modelos principais da CNN para atender ou superar o desempenho de referência.
- Você pode aprender com as arquiteturas VGG16, etc. para obter algumas dicas sobre o ajuste de hiperparâmetros.
- Você pode usar o mesmo ImageDataGenerator para aumentar suas imagens e aumentar o tamanho do conjunto de dados.
- O que mais, você pode tentar implementar arquiteturas mais novas e melhores, como DenseNet e XceptionNet.
- Você também pode passar para outras tarefas de visão computacional, como la detección y O desempenho é exibido como gráficos de dispersão e caixaA segmentação é uma técnica de marketing chave que envolve a divisão de um mercado amplo em grupos menores e mais homogêneos. Essa prática permite que as empresas adaptem suas estratégias e mensagens às características específicas de cada segmento, melhorando assim a eficácia de suas campanhas. A segmentação pode ser baseada em critérios demográficos, psicográfico, geográfico ou comportamental, facilitando uma comunicação mais relevante e personalizada com o público-alvo.... de objetos, que você vai perceber mais tarde que também pode ser reduzido à classificação de imagem.
Notas finais
Parabéns, aprenderam a criar seu próprio conjunto de dados e criar um modelo CNN ou transferir aprendizagem para resolver um problema. Aprendemos muito neste artigo, desde aprender como pesquisar dados de imagens até criar um modelo simples da CNN que foi capaz de alcançar um desempenho razoável. Também aprendemos a aplicação do aprendizado de transferência para melhorar ainda mais nosso desempenho.
Isso não é o fim, vimos que nossos modelos classificaram incorretamente muitas imagens, lo que significa que todavía hay margemMargem é um termo usado em uma variedade de contextos, como contabilidade, Economia e impressão. Em contabilidade, refere-se à diferença entre receitas e custos, que permite avaliar a rentabilidade de um negócio. No domínio da publicação, A margem é o espaço em branco ao redor do texto em uma página, que facilita a leitura e proporciona uma apresentação estética. Seu correto manejo é essencial.. de mejora. Podemos começar encontrando mais dados ou mesmo implementando arquiteturas mais novas e melhores que podem ser melhores na identificação de recursos.
Você acha útil este artigo? Compartilhe seus valiosos comentários na seção de comentários abaixo.. Sinta-se à vontade para compartilhar seus livros de código completos também, que será útil para os membros da nossa comunidade.





