Este artigo foi publicado como parte do Data Science Blogathon
Oi, pessoal! Neste blog, Vou discutir tudo sobre classificação de imagens.
Nos últimos anos, O Deep Learning provou ser uma ferramenta muito poderosa devido à sua capacidade de lidar com grandes quantidades de dados. O uso de camadas ocultas excede as técnicas tradicionais, especialmente para reconhecimento de padrões. Uma das redes neurais profundas mais populares são as redes neurais convolucionais (CNN).
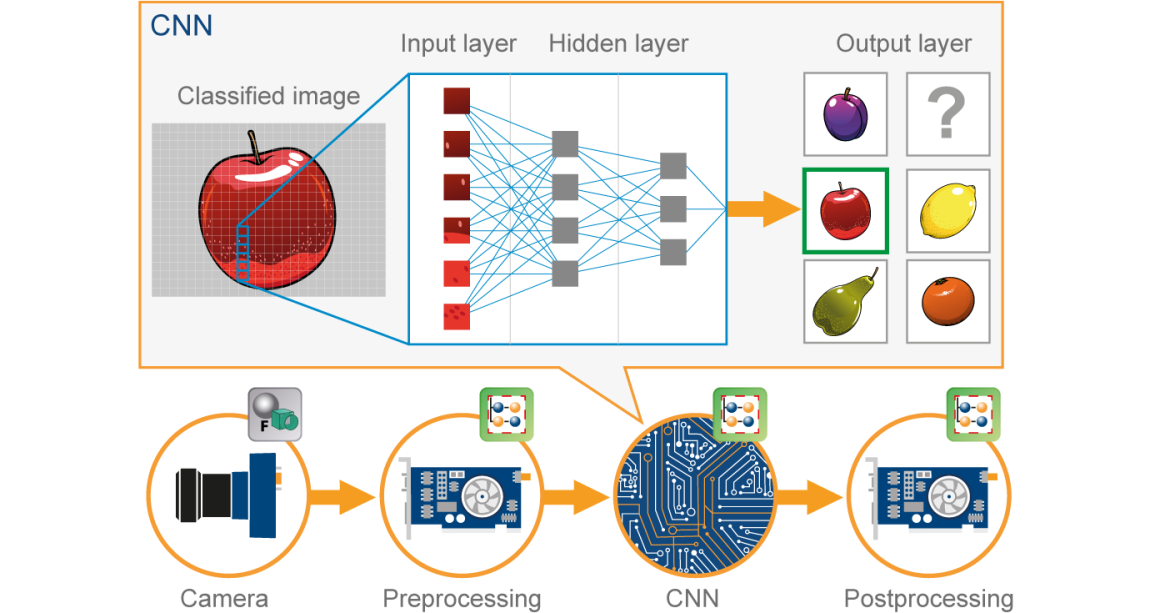
Uma rede neural convolucional (CNN) é um tipo de Neuronal vermelho artificial (ANN) usado no reconhecimento e processamento de imagem, que é especialmente projetado para processar dados (píxeis).
Fonte da imagem: Google.com
Antes de seguir em frente, devemos entender o que é a rede neural. Vamos lá…
Neuronal vermelho:
Uma rede neural é construída a partir de vários nós interconectados chamados “Neurônios”. Os neurônios são organizados em camada de entrada, camada oculta e camada de saída. A camada de entrada corresponde aos nossos preditores / características e a camada de saída para nossas variáveis de resposta.
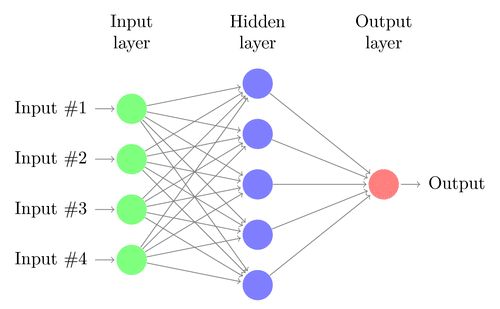
Fonte da imagem: Google.com
Perceptron Multicamadas (MLP):
A rede neural com uma camada de entrada, uma ou mais camadas ocultas e uma camada de saída é chamada perceptron multicamadas (MLP). MLP é inventado por Frank Rosenblatt No ano de 1957. MLP mostrado abaixo tem 5 nós de entrada, 5 nós ocultos com duas camadas ocultas e um nó de saída
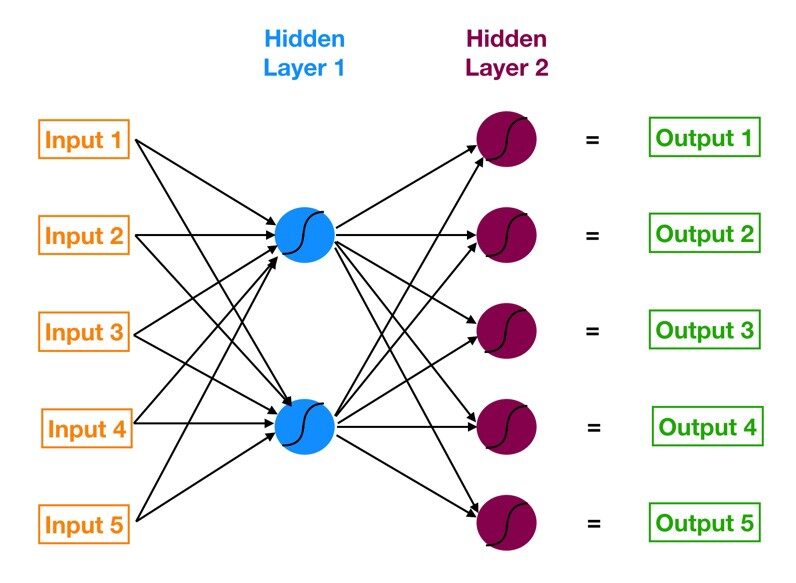
Fonte da imagem: Google.com
Como esta rede neural?
– Os neurônios da camada de entrada recebem informações dos dados que eles processam e distribuem para o camadas escondidas.
– Essa informação, na sua vez, é processado por camadas ocultas e passado para a saída. neurônios.
– As informações desta rede neural artificial (ANN) é processado em termos de um função de despertar. Esta função realmente imita os neurônios do cérebro.
– Cada neurônio contém um valor de funções de gatilho e um valor limiar.
– o valor limiar é o valor mínimo que a entrada deve ter para ser ativada.
– A tarefa do neurônio é realizar uma soma ponderada de todos os sinais de entrada e aplicar a função de ativação na soma antes de passá-la para a próxima camada. (escondido ou sair).
Vamos entender o que é a soma de ponderação.
Digamos que temos valores 𝑎1, 𝑎2, 𝑎3, 𝑎4 para entrada e pesos como 𝑤1, 𝑤2, 𝑤3, 𝑤4 como entrada para um dos neurônios da camada oculta, digamos 𝑛𝑗, então a soma ponderada é representada como
𝑆𝑗 = σ 𝑖 = 1to4 𝑤𝑖 * 𝑎𝑖 + 𝑏𝑗
onde 𝑏𝑗: viés devido ao nó
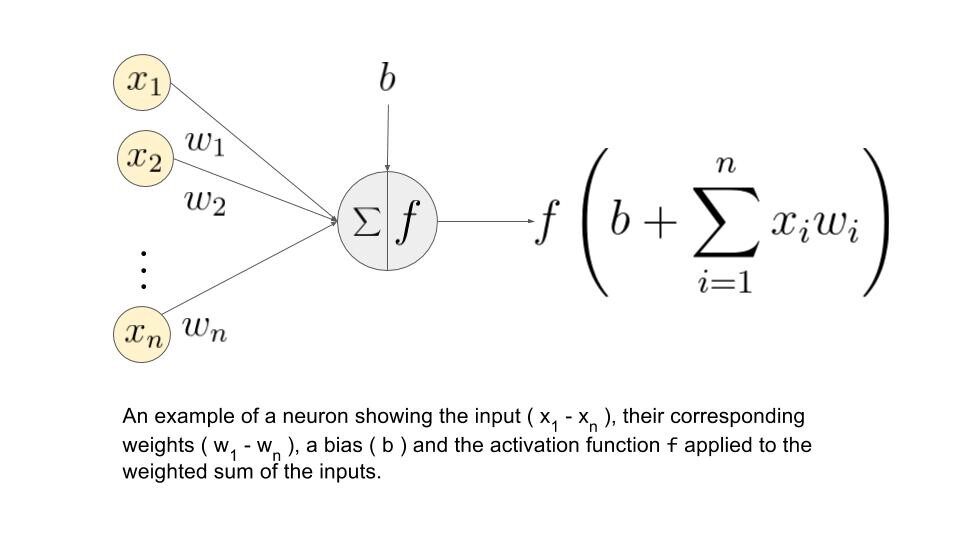
Fonte da imagem: Google.com
Quais são as funções de ativação?
Essas funções são necessárias para introduzir uma não linearidade na rede. A função de gatilho é aplicada e a saída é passada para a próxima camada.
* Possíveis funções *
• Sigmoide: função sigmóide é diferenciável. Produz uma saída entre 0 e 1.
• Tangente hiperbólica: A tangente hiperbólica também é diferenciável. Isso produz uma saída entre -1 e 1.
• ReLU: ReLU é a função mais popular. ReLU é amplamente utilizado em aprendizagem profunda.
• Softmax: a função softmax é usada para vários problemas de classificação de classe. É uma generalização da função sigmóide. Ele também produz uma saída entre 0 e 1
Agora, vamos com o nosso tema da CNN …
CNN:
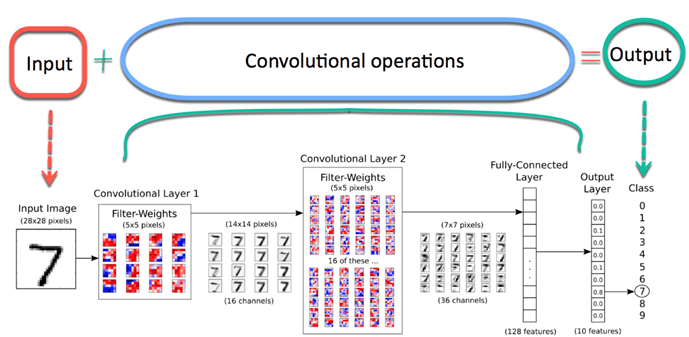
Agora imagine que há uma foto de um pássaro, e você deseja identificá-lo se é realmente um pássaro ou outra coisa. A primeira coisa que você precisa fazer é alimentar os pixels da imagem na forma de matrizes para a camada de entrada da rede neural (Redes MLP são usadas para classificar essas coisas). Camadas ocultas realizam extração de recursos realizando vários cálculos e operações. Existem várias camadas ocultas, como convolução, o ReLU e a camada de agrupamento que executa a extração de recursos de sua imagem. Então, Finalmente, há uma camada totalmente conectada que você pode ver que identifica o objeto exato na imagem. Você pode entender muito facilmente com a figura a seguir:
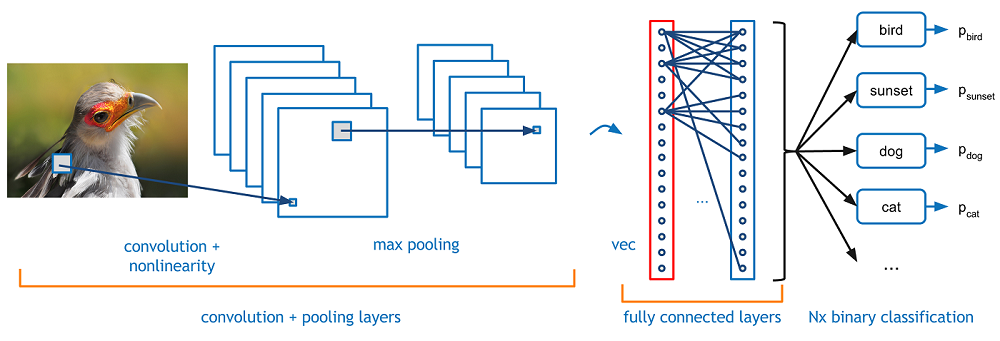
Fonte da imagem: Google.com
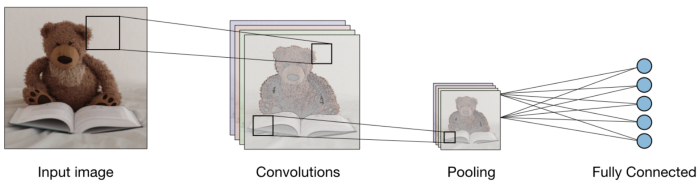
Convolução:-
A operação de convolução envolve operações aritméticas de matriz e cada imagem é representada como um array de valores (píxeis).
Vamos entender o exemplo:
a = [2,5,8,4,7,9]
b = [1,2,3]
Na operação de convolução, matrizes são multiplicadas uma a uma em termos de elementos, e o produto é agrupado ou somado para criar uma nova matriz que representa uma * b.
Os primeiros três elementos da matriz uma agora multiplique pelos elementos da matriz B. O produto é adicionado para obter o resultado e é armazenado em uma nova matriz de uma * b.
Este processo permanece contínuo até que a operação seja concluída..
Fonte da imagem: Google.com
Agrupamento:
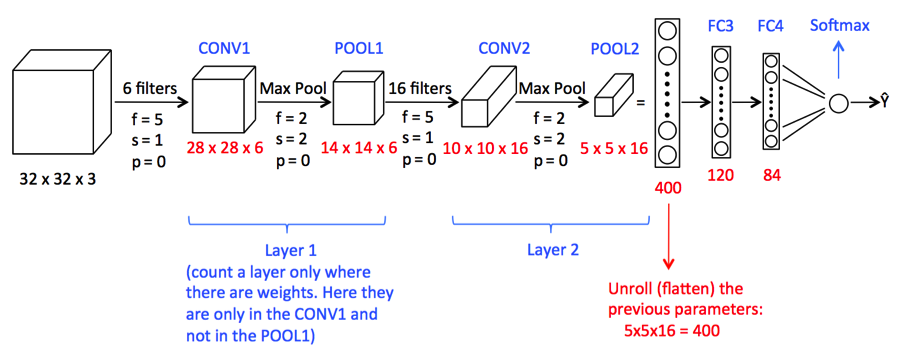
Depois da convolução, existe outra operação chamada agrupamento. Então, Na corrente, convolução e agrupamento são aplicados sequencialmente nos dados, a fim de extrair algumas características dos dados. Após as camadas sequenciais agrupadas e convolucionais, os dados são achatados
em uma rede neural de feedback, também chamada de perceptron multicamadas.
Fonte da imagem: Google.com
Até aqui, vimos conceitos que são importantes para o nosso modelo de construção CNN.
Agora vamos seguir em frente para ver um estudo de caso da CNN.
1) Aqui vamos importar as bibliotecas necessárias que são necessárias para executar tarefas cnn.
import NumPy as np
%matplotlib inline
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import TensorFlow as tf
tf.compat.v1.set_random_seed(2019)
2) Aqui exigimos o seguinte código para formar o modelo CNN
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16,(3,3),ativação = "retomar" , input_shape = (180,180,3)) ,
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32,(3,3),ativação = "retomar") ,
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64,(3,3),ativação = "retomar") ,
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128,(3,3),ativação = "retomar"),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.hard.layers.Dense(550,ativação ="retomar"), #Adding the Hidden layer
tf.keras.layers.Dropout(0.1,semente = 2019),
tf.hard.layers.Dense(400,ativação ="retomar"),
tf.keras.layers.Dropout(0.3,semente = 2019),
tf.hard.layers.Dense(300,ativação ="retomar"),
tf.keras.layers.Dropout(0.4,semente = 2019),
tf.hard.layers.Dense(200,ativação ="retomar"),
tf.keras.layers.Dropout(0.2,semente = 2019),
tf.hard.layers.Dense(5,ativação = "softmax") #Adicionando a camada de saída
])
Uma imagem complicada pode ser muito grande e, portanto, encolhe sem perder características ou padrões, para que o agrupamento seja feito.
Aqui, Criar uma rede neural é inicializar a rede usando o modelo sequencial Keras.
Achatar (): o achatamento transforma uma matriz bidimensional de recursos em um vetor de características.
3) Agora vamos olhar para um resumo do modelo da CNN
model.summary()
Você imprimirá a seguinte saída
Modelo: "sequencial" _________________________________________________________________ Camada (modelo) Parâmetros de forma de saída # ================================================================= conv2d (Conv2D) (Nenhum, 178, 178, 16) 448 _________________________________________________________________ max_pooling2d (MaxPooling2D) (Nenhum, 89, 89, 16) 0 _________________________________________________________________ conv2d_1 (Conv2D) (Nenhum, 87, 87, 32) 4640 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (Nenhum, 43, 43, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (Nenhum, 41, 41, 64) 18496 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (Nenhum, 20, 20, 64) 0 _________________________________________________________________ conv2d_3 (Conv2D) (Nenhum, 18, 18, 128) 73856 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (Nenhum, 9, 9, 128) 0 _________________________________________________________________ flatten (Achatar) (Nenhum, 10368) 0 _________________________________________________________________ dense (Denso) (Nenhum, 550) 5702950 _________________________________________________________________ dropout (Cair fora) (Nenhum, 550) 0 _________________________________________________________________ dense_1 (Denso) (Nenhum, 400) 220400 _________________________________________________________________ dropout_1 (Cair fora) (Nenhum, 400) 0 _________________________________________________________________ denso_2 (Denso) (Nenhum, 300) 120300 _________________________________________________________________ dropout_2 (Cair fora) (Nenhum, 300) 0 _________________________________________________________________ denso_3 (Denso) (Nenhum, 200) 60200 _________________________________________________________________ dropout_3 (Cair fora) (Nenhum, 200) 0 _________________________________________________________________ dense_4 (Denso) (Nenhum, 5) 1005 ========================================================== =============== Params totais: 6,202,295 Parâmetros treináveis: 6,202,295 Params não treináveis: 0
4) Então agora somos obrigados a especificar otimizadores.
de tensorflow.keras.optimizers importar RMSprop,SGD,Adam
adam=Adam(lr=0,001)
model.compile(otimizador ="Adão", perda ="categorical_crossentropy", metrics = ['acc'])
O otimizador é usado para reduzir o custo calculado por entropia cruzada
a função de perda é usada para calcular o erro.
O termo métricas é usado para representar a eficiência do modelo.
5) Nesta etapa, veremos como configurar o diretório de dados e gerar dados de imagem.
bs=30 #Setting batch size train_dir = "D:/Conjuntos de dados de ciência de dados/imagem/FastFood/trem/" #Setting training directory validation_dir = "D:/Data Science/Image Datasets/FastFood/test/" #Setting testing directory from tensorflow.keras.preprocessing.image import ImageDataGenerator # Todas as imagens serão redimensionadas por 1./255. train_datagen = ImageDataGenerator( reescalou = 1.0/255. ) test_datagen = ImageDataGenerator( reescalou = 1.0/255. ) # Vaze imagens de treinamento em lotes de 20 using train_datagen generator #Flow_from_directory function lets the classifier directly identify the labels from the name of the directories the image lies in train_generator=train_datagen.flow_from_directory(train_dir,batch_size=bs,class_mode="categórico",target_size=(180,180)) # Imagens de validação de fluxo em lotes de 20 using test_datagen generator validation_generator = test_datagen.flow_from_directory(validation_dir, batch_size=bs, class_mode="categórico", target_size=(180,180))
La salida será:
Fundar 1465 imagens pertencentes a 5 Classes. Fundar 893 imagens pertencentes a 5 Classes.
6) Paso final del modelo de ajuste.
history = model.fit(train_generator,
validation_data=validation_generator,
steps_per_epoch=150 // Bs,
épocas=30,
validation_steps=50 // Bs,
verboso = 2)
La salida será:
Época 1/30 5/5 - 4s - perda: 0.8625 - acc: 0.6933 - val_loss: 1.1741 - val_acc: 0.5000 Época 2/30 5/5 - 3s - perda: 0.7539 - acc: 0.7467 - val_loss: 1.2036 - val_acc: 0.5333 Época 3/30 5/5 - 3s - perda: 0.7829 - acc: 0.7400 - val_loss: 1.2483 - val_acc: 0.5667 Época 4/30 5/5 - 3s - perda: 0.6823 - acc: 0.7867 - val_loss: 1.3290 - val_acc: 0.4333 Época 5/30 5/5 - 3s - perda: 0.6892 - acc: 0.7800 - val_loss: 1.6482 - val_acc: 0.4333 Época 6/30 5/5 - 3s - perda: 0.7903 - acc: 0.7467 - val_loss: 1.0440 - val_acc: 0.6333 Época 7/30 5/5 - 3s - perda: 0.5731 - acc: 0.8267 - val_loss: 1.5226 - val_acc: 0.5000 Época 8/30 5/5 - 3s - perda: 0.5949 - acc: 0.8333 - val_loss: 0.9984 - val_acc: 0.6667 Época 9/30 5/5 - 3s - perda: 0.6162 - acc: 0.8069 - val_loss: 1.1490 - val_acc: 0.5667 Época 10/30 5/5 - 3s - perda: 0.7509 - acc: 0.7600 - val_loss: 1.3168 - val_acc: 0.5000 Época 11/30 5/5 - 4s - perda: 0.6180 - acc: 0.7862 - val_loss: 1.1918 - val_acc: 0.7000 Época 12/30 5/5 - 3s - perda: 0.4936 - acc: 0.8467 - val_loss: 1.0488 - val_acc: 0.6333 Época 13/30 5/5 - 3s - perda: 0.4290 - acc: 0.8400 - val_loss: 0.9400 - val_acc: 0.6667 Época 14/30 5/5 - 3s - perda: 0.4205 - acc: 0.8533 - val_loss: 1.0716 - val_acc: 0.7000 Época 15/30 5/5 - 4s - perda: 0.5750 - acc: 0.8067 - val_loss: 1.2055 - val_acc: 0.6000 Época 16/30 5/5 - 4s - perda: 0.4080 - acc: 0.8533 - val_loss: 1.5014 - val_acc: 0.6667 Época 17/30 5/5 - 3s - perda: 0.3686 - acc: 0.8467 - val_loss: 1.0441 - val_acc: 0.5667 Época 18/30 5/5 - 3s - perda: 0.5474 - acc: 0.8067 - val_loss: 0.9662 - val_acc: 0.7333 Época 19/30 5/5 - 3s - perda: 0.5646 - acc: 0.8138 - val_loss: 0.9151 - val_acc: 0.7000 Época 20/30 5/5 - 4s - perda: 0.3579 - acc: 0.8800 - val_loss: 1.4184 - val_acc: 0.5667 Época 21/30 5/5 - 3s - perda: 0.3714 - acc: 0.8800 - val_loss: 2.0762 - val_acc: 0.6333 Época 22/30 5/5 - 3s - perda: 0.3654 - acc: 0.8933 - val_loss: 1.8273 - val_acc: 0.5667 Época 23/30 5/5 - 3s - perda: 0.3845 - acc: 0.8933 - val_loss: 1.0199 - val_acc: 0.7333 Época 24/30 5/5 - 3s - perda: 0.3356 - acc: 0.9000 - val_loss: 0.5168 - val_acc: 0.8333 Época 25/30 5/5 - 3s - perda: 0.3612 - acc: 0.8667 - val_loss: 1.7924 - val_acc: 0.5667 Época 26/30 5/5 - 3s - perda: 0.3075 - acc: 0.8867 - val_loss: 1.0720 - val_acc: 0.6667 Época 27/30 5/5 - 3s - perda: 0.2820 - acc: 0.9400 - val_loss: 2.2798 - val_acc: 0.5667 Época 28/30 5/5 - 3s - perda: 0.3606 - acc: 0.8621 - val_loss: 1.2423 - val_acc: 0.8000 Época 29/30 5/5 - 3s - perda: 0.2630 - acc: 0.9000 - val_loss: 1.4235 - val_acc: 0.6333 Época 30/30 5/5 - 3s - perda: 0.3790 - acc: 0.9000 - val_loss: 0.6173 - val_acc: 0.8000
La función anterior entrena la red neuronal utilizando el conjunto de entrenamiento y evalúa su rendimiento en el conjunto de prueba. As funções retornam duas métricas para cada época 'acc’ y ‘val_acc’ quais são a precisão das previsões obtidas no conjunto de treinamento e a precisão alcançada no conjunto de teste, respectivamente.
conclusão:
Por tanto, vemos que foi cumprido com precisão suficiente. Porém, qualquer um pode executar este modelo aumentando o número de épocas ou qualquer outro parâmetro.
Espero que tenha gostado do meu artigo. Compartilhe com os seus amigos, colegas.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





