Este artigo foi publicado como parte do Data Science Blogathon.
Introdução
A inteligência artificial foi amplamente melhorada sem a necessidade de alterar a infraestrutura de hardware subjacente. Os usuários podem executar um programa de inteligência artificial em um sistema de computador antigo. Por outro lado, O efeito benéfico do aprendizado de máquina é ilimitado. O processamento de linguagem natural é um dos ramos da inteligência artificial que dá às máquinas a capacidade de ler, Compreender e transmitir significado. A PNL tem sido muito bem sucedida na assistência médica, A mídia, Finanças e recursos humanos.
A forma mais comum de dados não estruturados são textos e discursos. É abundante, mas difícil, Extraia informações úteis. Pelo contrário, Levaria muito tempo para extrair a informação. Texto escrito e fala contêm informações valiosas. É porque nós, Como seres inteligentes, Usamos a escrita e a fala como a principal forma de comunicação. A PNL pode analisar esses dados para nós e executar tarefas como análise de sentimentos., Assistente Cognitivo, Filtragem de intervalos, Identificação de notícias falsas e tradução de idiomas em tempo real.
Este artigo abordará como a PNL entende textos ou partes da fala. Vamos nos concentrar principalmente em palavras e análise de sequência. Inclui classificação de texto, Semântica vetorial e incorporação de palavras, Modelo de linguagem probabilística, Rotulação sequencial e reorganização da fala. Veremos a análise de sentimento de cinquenta mil críticos de cinema do IMDB. Nosso objetivo é identificar se a avaliação postada no site do IMDB pelo seu usuário é positiva ou negativa..
Lista de faixas
- Você entende o que é PNL??
- Para que serve a PNL??
- Palavras e sequências
- Classificação de texto
- Incorporação semântica e vetorial do Word
- Modelos probabilísticos de linguagem
- Marcação de sequência
- Analisadores
- Semântica
- Executando análise semântica no projeto de dados de revisão de filmes do IMDB
A PNL tem sido amplamente utilizada em automóveis, telefones inteligentes, Falantes, Computador, Sítios Web, etc. Google Tradutor Tradutor Automático, o que é o sistema de PNL. Google Translator escreveu e falou em linguagem natural para o idioma que os usuários querem traduzir. A PNL ajuda o Google Tradutor a entender a palavra no contexto, eliminar ruídos adicionais e criar CNNs para entender a voz nativa.
A PNL também é popular em chatbots. Os chatbots são muito úteis porque reduzem o trabalho humano de perguntar o que o cliente precisa.. Os chatbots de PNL fazem perguntas sequenciais como qual é o problema do usuário e onde encontrar a solução. Apple e AMAZON têm um chatbot robusto em seu sistema. Quando o usuário faz algumas perguntas, O chatbot as converte em frases compreensíveis no sistema interno.
Chama-se toke. Mais tarde, o token vai para a PNL para ter uma ideia do que os usuários estão perguntando. A PNL é usada na recuperação de informações (IR). IR é um programa de software que lida com um grande armazenamento, Avaliando informações de documentos de texto grandes em repositórios. Recuperar apenas informações relevantes. Por exemplo, é usado na detecção de voz do Google para cortar palavras desnecessárias.
Aplicação da PNL
- Tradução automática, quer dizer, tradutor do Google
- Recuperação de informação
- Responder a perguntas, quer dizer, ChatBot
- Resumo
- Análise de sentimentos
- Análise de Redes Sociais
- Mineração de Big Data
Palavras e sequências
O sistema de PNL precisa entender o texto corretamente, Sinais e semântica. Muitos métodos ajudam o sistema de PNL a entender texto e símbolos. Eles são classificação de texto, semântica vetorial, Incorporação de palavras, Modelo de linguagem probabilística, Marcação de sequência e reorganização de fala.
-
Classificação de texto
O esclarecimento de texto é o processo de categorização do texto em um grupo de palavras.. Ao usar a PNL, A classificação de texto pode analisar automaticamente o texto e, em seguida, atribuir um conjunto de marcas ou categorias predefinidas com base em seu contexto. A PNL é usada para análise de sentimentos, detecção de tópicos e detecção de idioma. Existem principalmente três abordagens para a classificação de texto:
- Sistema baseado em regras,
- Sistema da máquina
- Sistema híbrido.
Na abordagem baseada em regras, Os textos são separados em um grupo organizado usando um conjunto de regras linguísticas artesanais. Essas regras linguísticas artesanais contêm usuários para definir uma lista de palavras que são caracterizadas por grupos. Por exemplo, palavras como Donald Trump e Boris Johnson seriam classificadas na política. Pessoas como LeBron James e Ronaldo se qualificariam no esporte.
O classificador baseado em máquina aprende a fazer uma classificação com base em observações anteriores dos conjuntos de dados. Os dados do usuário são pré-rotulados como tarin e dados de teste. Colete a estratégia de classificação das entradas anteriores e aprenda continuamente. O classificador baseado em máquina usa um saco de uma palavra para extensão de recurso.
Em um saco de palavras, um vetor representa a frequência de palavras em um dicionário predefinido em uma lista de palavras. Podemos realizar PNL usando os seguintes algoritmos de aprendizado de máquina: Bayer ingênuo, SVM e Deep Learning.

A terceira abordagem para a classificação de texto é a abordagem híbrida. O uso da abordagem híbrida combina uma abordagem baseada em regras e em máquinas. Usando uma abordagem de sistema híbrida baseada em regras para criar uma tag e usando o aprendizado de máquina para treinar o sistema e criar uma regra. Mais tarde, A lista de regras baseadas em máquina é comparada com a lista de regras baseadas em regras. Se algo não corresponder nos rótulos, Os seres humanos melhoram a lista manualmente. É o melhor método para implementar a classificação de texto.
-
Semântica vetorial
A semântica vetorial é outra forma de análise de palavras e sequências. A semântica vetorial define a semântica e interpreta o significado das palavras para explicar características como palavras semelhantes e palavras opostas.. A ideia principal por trás da semântica vetorial é que duas palavras são as mesmas se tiverem sido usadas em um contexto semelhante.. A semântica vetorial divide as palavras em um espaço vetorial multidimensional. A semântica vetorial é útil na análise de sentimentos.
-
Incorporação de palavras
A incorporação de palavras é outro método de análise de palavras e sequências. A incorporação traduz vetores de fallback em um espaço de baixa dimensão que preserva as relações semânticas. A incorporação de palavras é um tipo de representação de palavras que permite que palavras com significado semelhante tenham uma representação semelhante.. Existem dois tipos de incorporações de palavras:
word2vec é um método estatístico para efetivamente aprender uma incorporação de palavras independente de um corpus de texto.
Doc2Vec é semelhante ao Doc2Vec, mas analisa um grupo de texto como páginas.
-
Modelo de linguagem probabilística
Outra abordagem para a análise de palavras e sequências é o modelo probabilístico de linguagem.. O objetivo do modelo probabilístico de linguagem é calcular a probabilidade de uma sentença em uma sequência de palavras.. Por exemplo, a probabilidade de que a palavra “uma” aparecem em uma determinada palavra “uma” isto é 0.00013131 por cento.
-
Marcação de sequência
A marcação de sequência é uma tarefa típica de nlp que atribui uma classe ou tag a cada token em um determinado fluxo de entrada. Se alguém disser “Reproduzir o filme de Tom Hanks”. Em sequência, A rotulagem é [Brincar, Filme, Tom Hanks]. O jogo determina uma ação. Os filmes são um exemplo de ação. Tom Hanks está à procura de uma entidade de pesquisa. Divida a entrada em vários tokens e use LSTM para analisá-la. Há duas maneiras de marcar sequências. Eles são marcação de token e marcação de tranching.
A análise é uma fase da PNL na qual o analisador determina a estrutura sintática de um texto analisando as palavras que o constituem com base em uma gramática subjacente.. Por exemplo, "Tom comeu uma maçã" será dividido em nome próprio Tom, Verbo comeu, determinante , substantivo maçã. O melhor exemplo é o Amazon Alexa.
Discutimos como o texto é classificado e como dividir a palavra e a sequência para que o algoritmo possa entendê-lo e categorizá-lo.. Neste projeto, descobriremos uma análise de sentimento de cinquenta mil críticos de cinema do IMDB. Nosso objetivo é identificar se a avaliação postada no site do IMDB pelo seu usuário é positiva ou negativa..
Este projeto abrange técnicas de mineração de texto, como incorporação de texto, Sacos de palavras, contexto de palavras e outras coisas. Também abordaremos a introdução de um classificador de sentimento LSTM bidirecional. Também veremos como importar um conjunto de dados marcado do TensorFlow automaticamente. Este projeto também abrange etapas como limpeza de dados, Tratamento de texto, Balanceamento de dados por meio de amostragem, treinamento e teste de um modelo de aprendizado profundo para classificar o texto.
Analisando
O analisador determina a estrutura sintática de um texto analisando as palavras que o constituem com base em uma gramática subjacente. Divida as palavras no grupo em partes componentes e separe as palavras.
Para mais detalhes sobre a análise, consulte Este artigo.
Semântico
O texto está no centro de como nos comunicamos. O que é realmente difícil é entender o que é dito em uma conversa escrita ou falada?? Entender livros e artigos longos é ainda mais difícil. A semântica é um processo que busca compreender o significado linguístico por meio da construção de um modelo do princípio que o falante utiliza para transmitir significado.. Usado na análise de feedback do cliente, Análise do artigo, detecção de notícias falsas, Análise semântica, etc.
Aplicativo de exemplo
Aqui está o exemplo de código:
Importando a biblioteca necessária
# Ele é definido pela imagem do Docker kaggle/python: https://github.com/kaggle/docker-python # Por exemplo, here's several helpful packages to load import numpy as np # linear algebra import pandas as pd # processamento de dados, I/O do arquivo CSV (por exemplo. pd.read_csv) # Os arquivos de dados de entrada estão disponíveis no somente leitura "../entrada/" diretório # Por exemplo, executando este (clicando em executar ou pressionando Shift+Enter) will list all files under the input directory import os for dirname, _, nomes de arquivos em os.walk('/kaggle/input'): para nome de arquivo em nomes de arquivos: imprimir(os.path.join(dirname, nome do arquivo)) # Você pode gravar até 20 GB no diretório atual (/kaggle/trabalho/) que é preservado como saída quando você cria uma versão usando "Salvar & Executar tudo" # Você também pode gravar arquivos temporários em /kaggle/temp/, but they won't be saved outside of the current session #Importing require Libraries import os import matplotlib.pyplot as plt import nltk from tkinter import * import seaborn as sns import matplotlib.pyplot as plt sns.set() import scipy import tensorflow as tf import tensorflow_hub as hub import tensorflow_datasets as tfds from tensorflow.python import keras from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Embedding, LSTM from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix from sklearn.metrics import classification_report
Descargando el archivo necesario
# esta célula leva tempo, por favor, execute uma vez
# Divida o conjunto de treinamento em 60% e 40%, então vamos acabar com 15,000 Exemplos
# para treinamento, 10,000 exemplos de validação e 25,000 exemplos de teste.
original_train_data, original_validation_data, original_test_data = tfds.load(
nome ="imdb_reviews",
dividir=(«comboio[:60%]', «comboio[60%:]', 'teste'),
as_supervised=Verdadeiro)
Obtener el índice de palabras de los conjuntos de datos de Keras
#tokanizing by tensorflow
word_index = tf.keras.datasets.imdb.get_word_index(
caminho ="imdb_word_index.json"
)
Sobre [8]:
{k:v para (k,v) em word_index.items() se v < 20}
Fora de[8]:
{'com': 16, 'eu': 10, 'Como': 14, 'isto': 9, 'é': 6, 'no': 8, 'mas': 18, 'do': 4, 'isso': 11, 'uma': 3, 'para': 15, 'br': 7, 'a': 1, 'era': 13, 'e': 2, 'para': 5, 'filme': 19, 'Filme': 17, 'isso': 12}
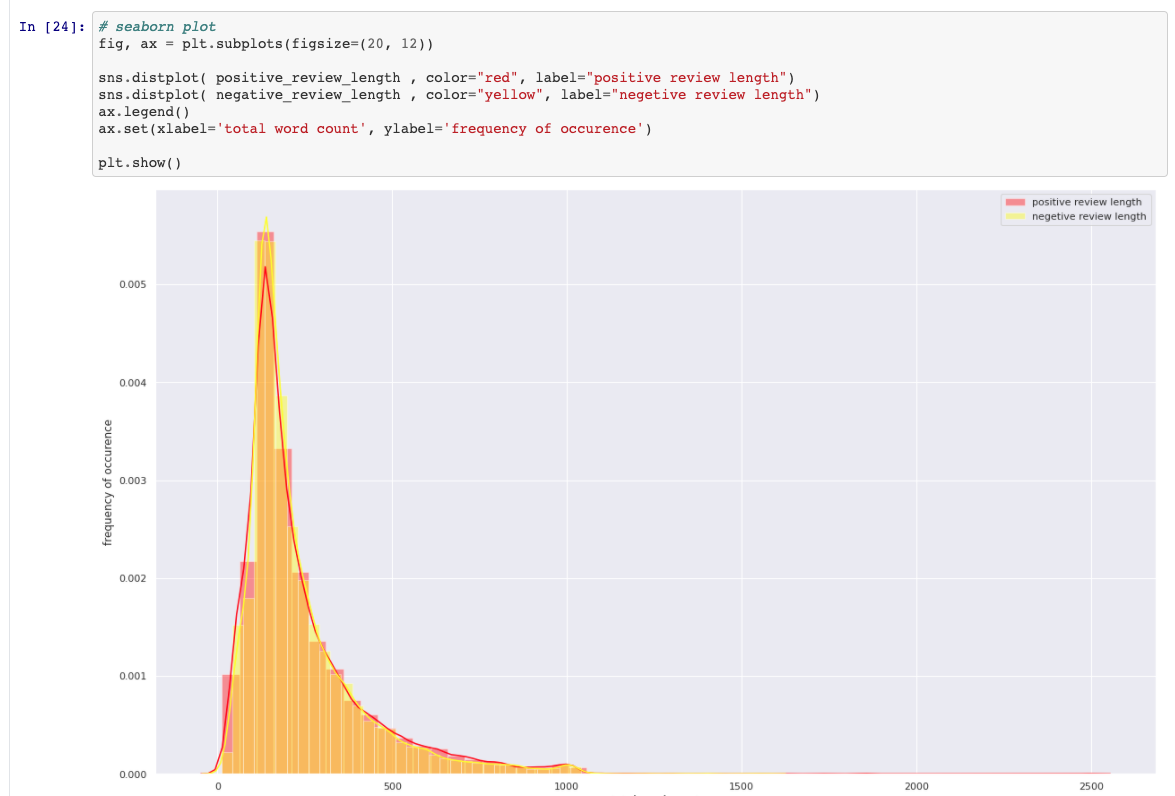
Comparação de avaliações positivas e negativas
Criar Trem, dados de teste

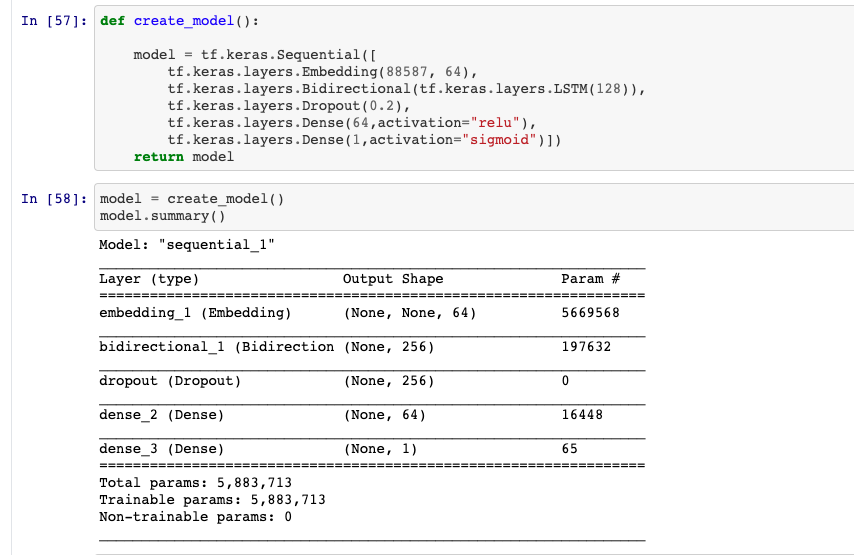
Modelo e resumo do modelo
Dividir dados e ajustar o modelo
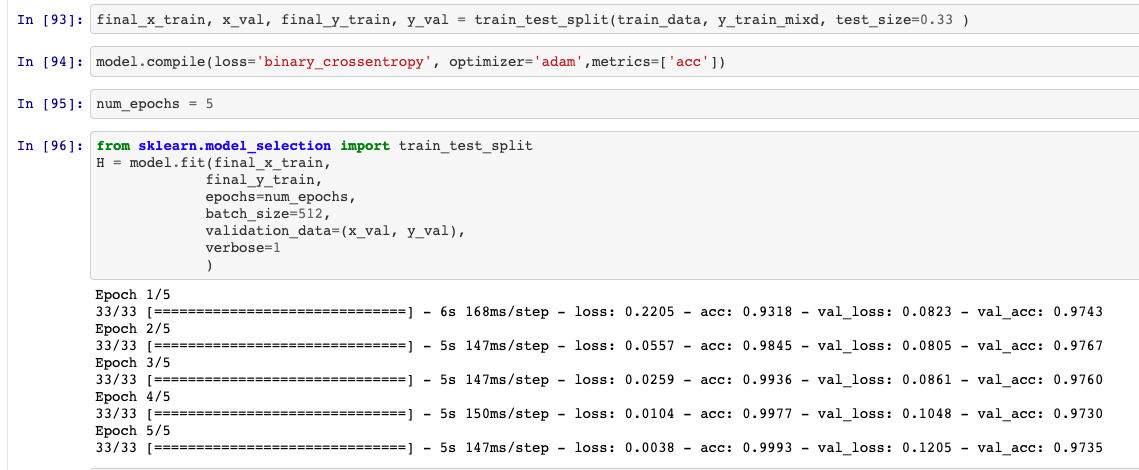
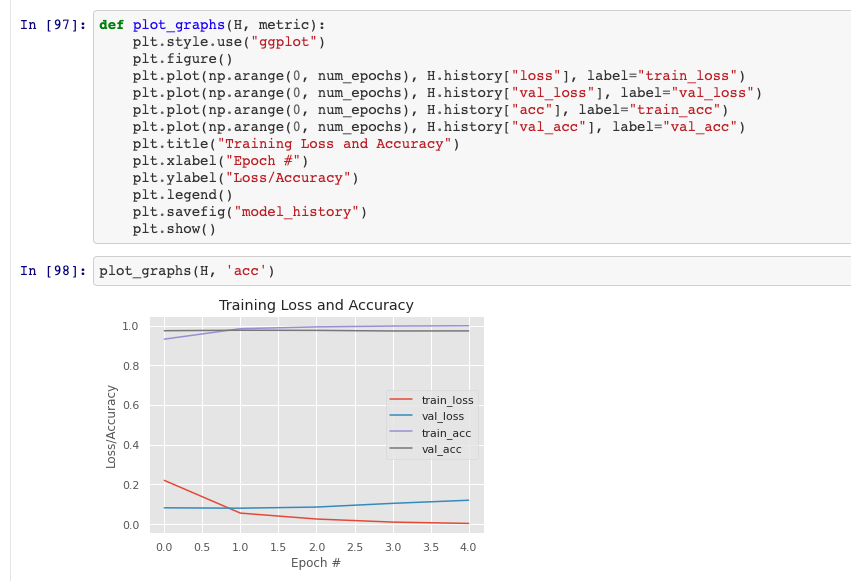
Visão geral do efeito de modelo
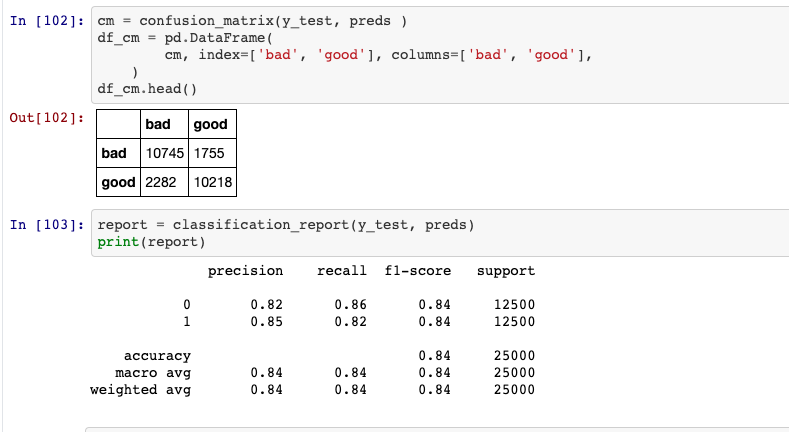
Matriz de confusão e relatório de correlação
Observação: A fonte de dados e os dados neste modelo estão disponíveis publicamente e acessíveis usando o Tensorflow.
Para obter o código completo e os detalhes, siga isto Repositório GitHub.
Em conclusão, A PNL é um campo cheio de oportunidades. A PNL tem um tremendo efeito sobre como analisar textos e discursos. A PNL está melhorando a cada dia. Extrair insights do grande conjunto de dados era impossível há cinco anos. A ascensão da técnica da PNL tornou possível e fácil. Ainda há muitas oportunidades para descobrir na PNL.





