Este artigo foi publicado como parte do Data Science Blogathon
C
- Este artículo le dará una comprensión básica de cómo funciona el análisis de texto.
- Conozca los distintos pasos del proceso de PNL
- Derivación del sentimiento general del texto.
- Tablero que muestra las estadísticas generales y el análisis de sentimientos del texto.
Abstracto
En esta era digital moderna, se genera una gran cantidad de información por segundo. La mayoría de los datos que los humanos generan a través de mensajes, tweets, blogs, novos artigos, recomendaciones de productos y reseñas de WhatsApp no están estructurados. Então, para obtener información útil de estos datos altamente desestructurados, primero debemos convertirlos en forma estructurada y normalizada.
Processamento de linguagem natural (PNL) es una clase de inteligencia artificial que realiza una serie de procesos sobre estos datos no estructurados para obtener información significativa. El procesamiento del lenguaje es de naturaleza completamente no determinista porque el mismo lenguaje puede tener diferentes interpretaciones. Se vuelve tedioso porque algo adecuado para una persona no es adecuado para otra. O que mais, el uso de lenguaje coloquial, acrónimos, hashtags con palabras adjuntas, emoticonos posee una sobrecarga para su preprocesamiento.
Si le interesa el poder de la analíticaAnalytics refere-se ao processo de coleta, Meça e analise dados para obter insights valiosos que facilitam a tomada de decisões. Em vários campos, como negócio, Saúde e esporte, A análise pode identificar padrões e tendências, Otimize processos e melhore resultados. O uso de ferramentas avançadas e técnicas estatísticas é essencial para transformar dados em conhecimento aplicável e estratégico.... de redes sociales, este artículo es el punto de partida para usted. Este artículo cubre los conceptos básicos de análisis de texto y le proporciona un tutorial paso a paso para realizar el procesamiento del lenguaje natural sin el requisito de ningún conjunto de datos de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.....
Introducción a la PNL
El procesamiento del lenguaje natural es el subcampo de la inteligencia artificial que comprende procesos sistemáticos para convertir datos no estructurados en información significativa y extraer conocimientos útiles de los mismos. La PNL se clasifica además en dos categorías amplias: PNL basada en reglas y PNL estadístico. La PNL basada en reglas utiliza un razonamiento básico para procesar tareas, por lo que se requiere un esfuerzo manual sin mucho entrenamiento del conjunto de datos. La PNL estadística, por outro lado, entrena una gran cantidad de datos y obtiene información a partir de ellos. Utiliza algoritmos de aprendizaje automático para entrenar el mismo. Neste artigo, aprenderemos la PNL basada en reglas.
Aplicativos de PNL:
- Resumo do texto
- Máquina tradutora
- Sistemas de preguntas y respuestas
- Revisiones ortográficas
- autocompletar
- Análise de sentimentos
- Reconhecimento de voz
- SegmentaçãoA segmentação é uma técnica de marketing chave que envolve a divisão de um mercado amplo em grupos menores e mais homogêneos. Essa prática permite que as empresas adaptem suas estratégias e mensagens às características específicas de cada segmento, melhorando assim a eficácia de suas campanhas. A segmentação pode ser baseada em critérios demográficos, psicográfico, geográfico ou comportamental, facilitando uma comunicação mais relevante e personalizada com o público-alvo.... de temas
Canalización de PNL:

La canalización de PNL se divide en cinco subtareas:
1. Análisis léxico: El análisis léxico es el proceso de analizar la estructura de palabras y frases presentes en el texto. El léxico se define como el fragmento identificable más pequeño del texto. Podría ser una palabra, frase, etc. Implica identificar y dividir todo el texto en oraciones, párrafos y palabras.
2. Análise sintática: El análisis sintáctico es el proceso de ordenar las palabras de una manera que muestre la relación entre las palabras. Implica analizarlos en busca de patrones gramaticales. Por exemplo, la oración “La universidad va para la niña”. es rechazado por el analizador sintáctico.
3. Análise semântica: El análisis semántico es el proceso de analizar el texto para determinar su significado. Considera estructuras sintácticas para mapear los objetos en el dominio de la tarea. Por exemplo, la frase “Quiere comer helado caliente” es rechazada por el analizador semántico.
4. Integración de divulgación: La integración de la divulgación es el proceso de estudiar el contexto del texto. Las oraciones están organizadas en un orden significativo para formar un párrafo, lo que significa que la oración antes de una oración en particular es necesaria para comprender el significado general. O que mais, la oración que sigue a la oración depende de la anterior.
5. Análisis pragmático: El análisis pragmático se define como el proceso de reconfirmar que lo que el texto realmente significaba es lo mismo que lo derivado.
Leyendo el archivo de texto:
filename = "C:UsersDellDesktopexample.txt" text = open(nome do arquivo, "r").leitura()
Imprimir el texto:
imprimir(texto)

Instalación de la biblioteca para PNL:
Usaremos la biblioteca spaCy para este tutorial. espaço es una biblioteca de software de código abierto para PNL avanzada escrita en los lenguajes de programación Python y Cython. La biblioteca se publica bajo una licencia del MIT. A diferencia de NLTK, que se usa ampliamente para la enseñanza y la investigación, spaCy se enfoca en proporcionar software para uso en producción. spaCy también admite flujos de trabajo de aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde... que permiten conectar modelos estadísticos entrenados por bibliotecas de aprendizaje automático populares como TensorFlow, Pytorch a través de su propia biblioteca de aprendizaje automático Thinc.[Wikipedia]
pip install -U pip setuptools wheel
pip install -U spacy
Ya que estamos tratando con el idioma inglés. Entonces necesitamos instalar el en_core_web_sm paquete para ello.
python -m spacy download en_core_web_sm
Verificando que la descarga fue exitosa e importando el paquete spacy:
import spacy
nlp = spacy.load('en_core_web_sm')
Después de la creación exitosa del objeto NLP, podemos pasar al preprocesamiento.
Tokenización:
La tokenización es el proceso de convertir todo el texto en una serie de palabras conocidas como tokens. Este es el primer paso en cualquier proceso de PNL. Divide todo el texto en unidades significativas.
text_doc = nlp(texto) imprimir ([token.text for token in text_doc])

Como podemos observar en los tokens, hay muchos espacios en blanco, vírgulas, palabras vacías que no sirven de nada desde una perspectiva de análisis.
Identificación de la oración
Identificar las oraciones del texto es útil cuando queremos configurar partes significativas del texto que ocurren juntas. Por eso es útil encontrar frases.
about_doc = nlp(about_text) sentences = list(about_doc.sents)

Removendo palavras irrelevantes
Las palabras vacías se definen como palabras que aparecen con frecuencia en el lenguaje. No tienen ningún papel significativo en el análisis de texto y obstaculizan el análisis de Distribuição de frequênciaA distribuição de frequência é uma ferramenta estatística que organiza e resume os dados em intervalos ou categorias, facilitando sua análise. Permite visualizar com que frequência diferentes valores ocorrem em um conjunto de dados, por meio de tabelas ou gráficos. Essa técnica é fundamental na estatística descritiva, pois ajuda a identificar padrões, Tendências e dispersão de dados, apoiando a tomada de decisão informada..... Por exemplo, a, uma, uma, o, etc. Portanto, deben eliminarse del texto para obtener una imagen más clara del texto.
normalized_text = [token for token in text_doc if not token.is_stop] imprimir (normalized_text)

Eliminación de puntuación:
Como podemos ver en el resultado anterior, hay signos de puntuación que no nos sirven. Así que eliminémoslos.
clean_text = [token for token in normalized_text if not token.is_punct] imprimir (clean_text)

Lematización:
La lematización es el proceso de reducir una palabra a su forma original. Lema es una palabra que representa un grupo de palabras llamadas lexemas. Por exemplo: participar, participar, participar. Todos se reducen a un lema común, quer dizer, participar.
for token in clean_text: imprimir (símbolo, token.lemma_)
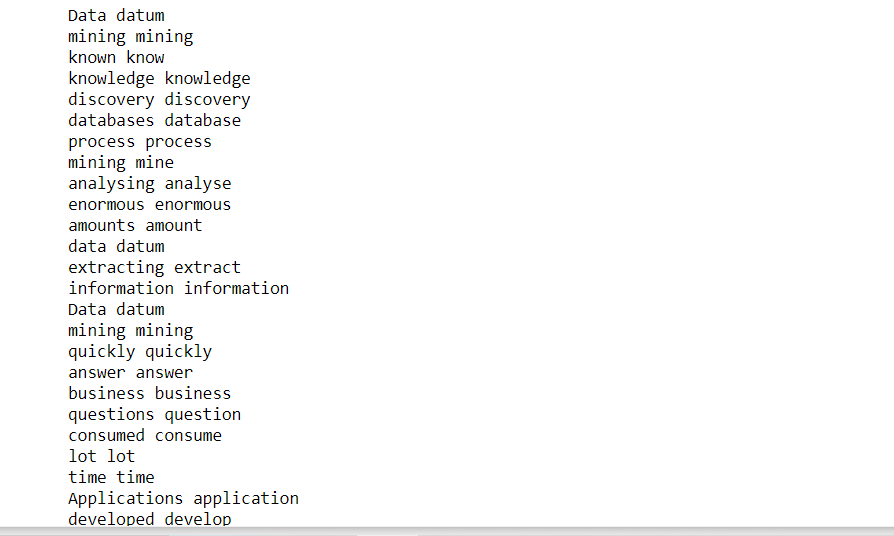
Recuento de frecuencia de palabras:
Realicemos ahora un análisis estadístico del texto. Encontraremos las diez primeras palabras según su frecuencia en el texto.
from collections import Counter words = [token.text for token in clean_text if not token.is_stop and not token.is_punct] word_freq = Counter(palavras) # 10 commonly occurring words with their frequencies common_words = word_freq.most_common(10) imprimir (common_words)

Análise de sentimentos
El análisis de sentimiento es el proceso de analizar el sentimiento del texto. Una forma de hacerlo es a través de la polaridad de las palabras, ya sean positivas o negativas.
VADER (Valence Aware Dictionary and Sentiment Reasoner) es una biblioteca de análisis de sentimientos basada en reglas y léxico en Python. Utiliza una serie de léxicos de sentimientos. Un léxico de sentimiento es una serie de palabras que se asignan a sus respectivas polaridades, quer dizer, Positivo, negativa y neutra de acuerdo con su significado semántico.
Por exemplo:
1. Palabras como bueno, grandioso, asombroso, fantástico son de polaridad positiva.
2. Palabras como malo, peor, patético son de polaridad negativa.
El analizador de sentimientos VADER encuentra los porcentajes de palabras de diferente polaridad y da puntuaciones de polaridad de cada una de ellas respectivamente. La salida del analizador se puntúa de 0 uma 1, que se puede convertir en porcentajes. No solo habla de las puntuaciones de positividad o negatividad, sino también de lo positivo o negativo que es un sentimiento.
Primero descarguemos el paquete usando pip.
pip install vaderSentiment
Mais tarde, analice las puntuaciones de sentimiento.
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
vs = Analyzer.polarity_scores(texto)
vs

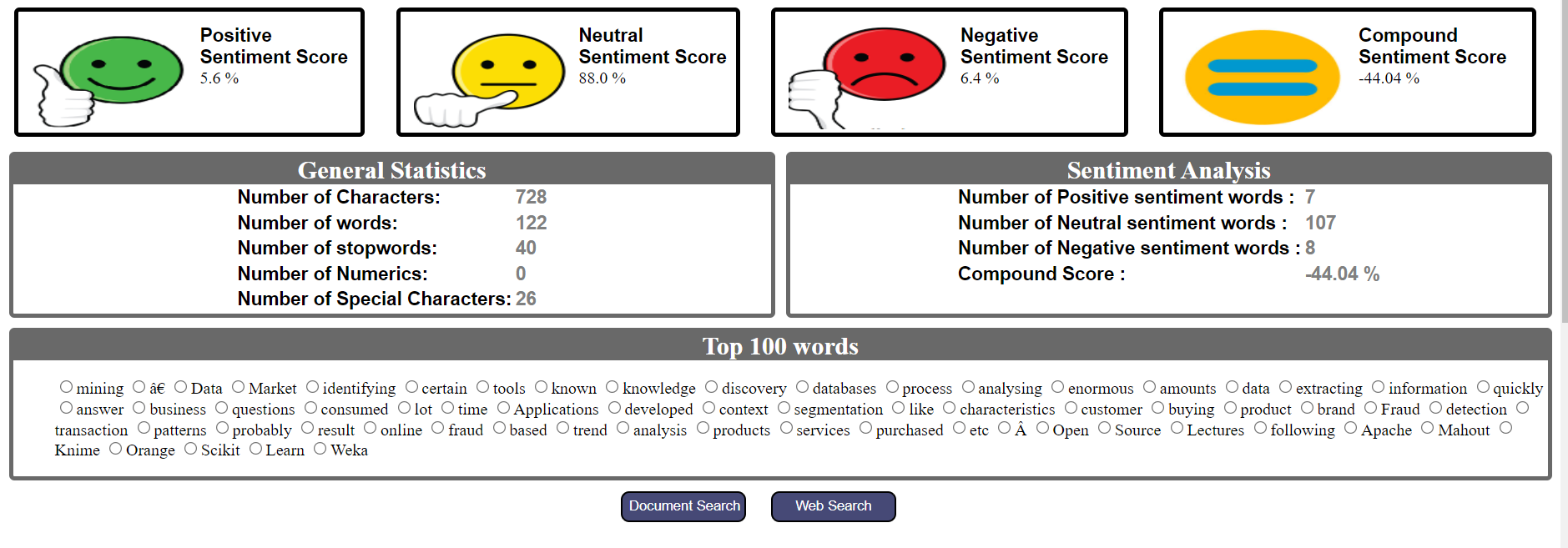
PainelUm painel é um grupo de especialistas que se reúne para discutir e analisar um tópico específico. Esses fóruns são comuns em conferências, Seminários e debates públicos, onde os participantes compartilham seus conhecimentos e perspectivas. Os painéis podem abordar uma variedade de áreas, Da ciência à política, e seu objetivo é incentivar a troca de ideias e a reflexão crítica entre os participantes.... de control del analizador de texto
Los pasos anteriores se pueden resumir para crear un tablero para el analizador de texto. Incluye la cantidad de palabras, la cantidad de caracteres, la cantidad de números, las N palabras principales, la intención del texto, la opinión general, la puntuación de la opinión positiva, la puntuación de la opinión negativa, la puntuación de la opinión neutral y el recuento de palabras de la opinión.
conclusão
La PNL ha tenido un gran impacto en campos como el análisis de reseñas de productos, recomendações, Análise de Redes Sociais, traducción de texto y, portanto, ha obtenido enormes beneficios para las grandes empresas.
Espero que este artículo le ayude a comenzar su viaje en el campo de la PNL.
E finalmente, … Não precisa dizer,
Obrigado pela leitura!
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





