Este artigo foi publicado como parte do Data Science Blogathon
Este artículo tiene como objetivo explicar la convolucional neuronal vermelhoRedes Neurais Convolucionais (CNN) são um tipo de arquitetura de rede neural projetada especialmente para processamento de dados com uma estrutura de grade, como fotos. Eles usam camadas de convolução para extrair recursos hierárquicos, o que os torna especialmente eficazes em tarefas de reconhecimento e classificação de padrões. Graças à sua capacidade de aprender com grandes volumes de dados, As CNNs revolucionaram campos como a visão computacional.. y cómo compilar CNN con la biblioteca TensorFlow Keras. Este artigo irá discutir os seguintes tópicos.
Primero analicemos la neuronal vermelhoAs redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano. Eles usam estruturas conhecidas como neurônios artificiais para processar e aprender com os dados. Essas redes são fundamentais no campo da inteligência artificial, permitindo avanços significativos em tarefas como reconhecimento de imagem, Processamento de linguagem natural e previsão de séries temporais, entre outros. Sua capacidade de aprender padrões complexos os torna ferramentas poderosas.. convolucional.
Convolucional neuronal vermelho (CNN)
o aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde... es un subconjunto muy importante del aprendizaje automático debido a su alto rendimiento en varios dominios. A rede neural convolucional (CNN) é um poderoso tipo de processamento de imagem de aprendizagem profunda que é frequentemente usado na visão computacional e compreende o reconhecimento de imagem e vídeo, juntamente com um sistema de processamento e recomendação de linguagem natural (PNL).
CNN utiliza un sistema multicapa que consta de la camada de entradao "camada de entrada" refere-se ao nível inicial em um processo de análise de dados ou em arquiteturas de redes neurais. Sua principal função é receber e processar informações brutas antes de serem transformadas por camadas subsequentes. No contexto do aprendizado de máquina, A configuração adequada da camada de entrada é crucial para garantir a eficácia do modelo e otimizar seu desempenho em tarefas específicas...., a Camada de saídao "Camada de saída" é um conceito utilizado no campo da tecnologia da informação e design de sistemas. Refere-se à última camada de um modelo ou arquitetura de software que é responsável por apresentar os resultados ao usuário final. Essa camada é crucial para a experiência do usuário, uma vez que permite a interação direta com o sistema e a visualização dos dados processados.... y una capa oculta que comprende múltiples capas convolucionales, camadas agrupadas, camadas totalmente conectadas. Discutiremos todas as camadas na próxima seção do artigo, como explicamos a construção da CNN.
Vamos olhar para a construção da CNN usando a biblioteca Keras, juntamente com uma explicação de como a CNN funciona.
Edifício CNN
Nós vamos usar o Conjunto de dados de imagem celular da malária. Este conjunto de dados consiste em 27,558 imagens de amostras de sangue microscópica. O conjunto de dados consiste em 2 pastas: pastas: parasitado e não infectado. Imagens de amostra
uma) amostra de sangue parasitada
b) Amostra de sangue não infectada
Discutiremos a construção da CNN juntamente com a CNN trabalhando no seguinte 6 Passos:
Paso 1: importar as bibliotecas necessárias
Paso 2: inicializar CNN y agregar una capa convolucionalA camada convolucional, Fundamental em redes neurais convolucionais (CNN), É usado principalmente para processamento de dados com estruturas semelhantes a grades, como fotos. Essa camada aplica filtros que extraem recursos relevantes, como bordas e texturas, permitindo que o modelo reconheça padrões complexos. Sua capacidade de reduzir a dimensionalidade dos dados e manter informações essenciais o torna uma ferramenta fundamental nas tarefas de visão computacional..
Paso 3: operação de agrupamento
Paso 4: adicionar duas camadas convolucionais
Paso 5 – Operação de achatamento
Paso 6: camada e camada de saída totalmente conectadas
Estes 6 passos vai explicar como a CNN funciona, mostrado na imagem a seguir:
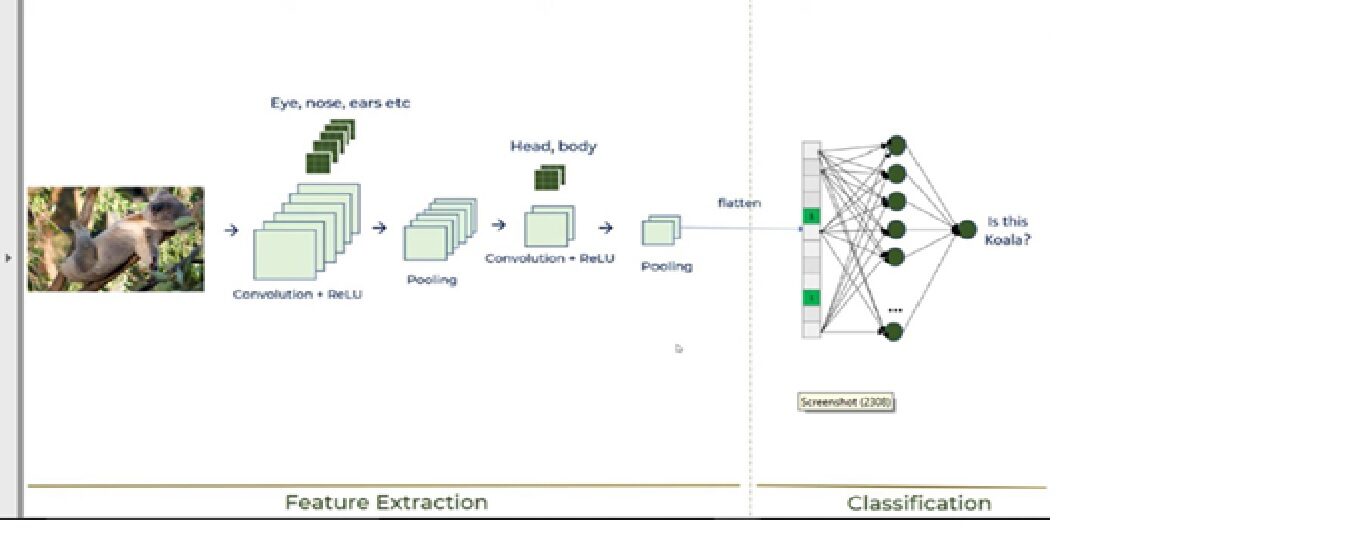
Agora, vamos analisar cada passo:
1. Importar bibliotecas necessárias
Por favor, veja link abaixo para explicações detalhadas dos módulos Keras.
https://keras.io/getting_started/
Código Python:
from tensorflow.keras.layers importação Entrada, Lambda, Denso, Achatar,Conv2D de tensorflow.keras.models import Model de tensorflow.keras.applications.vgg19 importação VGG19 de tensorflow.keras.applications.resnet50 preprocess_input de importação de tensorflow.keras.preprocessando imagem de importação de tensorflow.keras.preprocessing.image import ImageDataGenerator,load_img de tensorflow.keras.models importar Sequencial importar numpy como np de glob importação glob import matplotlib.pyplot as plt de tensorflow.keras.layers importar MaxPooling2D
2. Inicialize a CNN e adicione uma camada convolucional
Código Python:
modelo=Sequencial() model.add(Conv2D(filtros=16.kernel_size=2,estofamento="mesmo",ativação ="retomar",input_shape =(224,224,3)))
Primeiro temos que começar a classe sequencial, já que existem várias camadas para construir a CNN e todos devem estar em sequência. Em seguida, adicionamos a primeira camada convolucional onde precisamos especificar 5 argumentos. Então, vamos analisar cada argumento e seu propósito.
· Filtros
O principal objetivo da convolução é encontrar recursos na imagem usando um detector de recursos. Mais tarde, colocá-los em um mapa de características, que preserva as características distintas das imagens.
O detector de recursos, que é conhecido como um filtro, ele também é aleatoriamente inicializado e, em seguida,, depois de muitas iterações, o parâmetro de matriz de filtro que será melhor para separar imagens é selecionado. Por exemplo, o olho, o nariz, etc. dos animais devem ser considerados uma característica usada para classificar imagens por meio de filtros ou detectores característicos. Aqui estamos usando 16 funções.
· Kernel_size
Kernel_size refere-se ao tamanho da matriz do filtro. Aqui estamos usando um tamanho de filtro de 2 * 2.
· O preenchimento
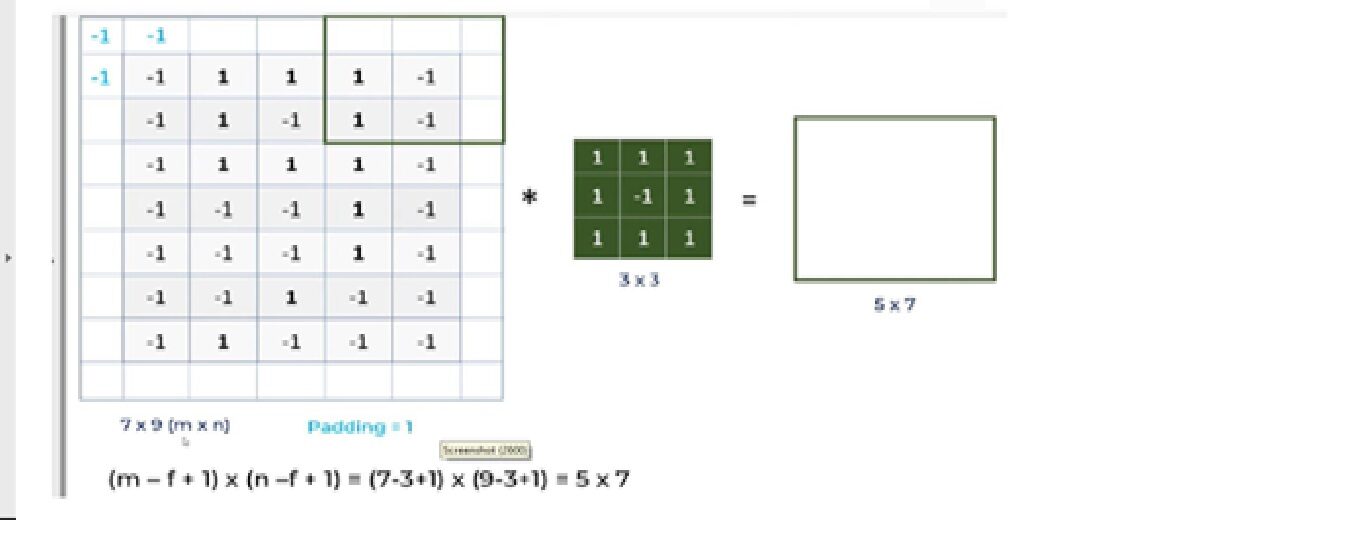
Vamos discutir qual é o problema com a CNN e como a operação de preenchimento resolverá o problema.
uma. Para uma imagem em escala de cinza (nxn) e um filtro / núcleo (fxf), as dimensões da imagem resultante de uma operação de convolução é (n – f + 1) x (n – f + 1).
Então, por exemplo, uma imagem de 5 * 7 e um tamanho do núcleo do filtro de 3 * 3, o resultado de saída após a operação de convolução seria um tamanho de 3 * 5. Portanto, a imagem encolhe cada vez que a operação convolucional é realizada.
B. Pixels, localizado nos cantos, ter uma contribuição muito pequena em comparação com os pixels no meio.
Então, para mitigar esses problemas, a operação de preenchimento é realizada. Preenchimento é um processo simples de adicionar camadas com 0 o -1 para inserir imagens para evitar os problemas mencionados acima.
Aqui estamos usando Estofamento = Mesmos argumentos, que descreve que as imagens de saída têm as mesmas dimensões das imagens de entrada.
· Função de gatilhoA função de ativação é um componente chave em redes neurais, uma vez que determina a saída de um neurônio com base em sua entrada. Seu principal objetivo é introduzir não linearidades no modelo, permitindo que você aprenda padrões complexos em dados. Existem várias funções de ativação, como o sigmóide, ReLU e tanh, cada um com características particulares que afetam o desempenho do modelo em diferentes aplicações.... – ReluA função de ativação do ReLU (Unidade linear retificada) É amplamente utilizado em redes neurais devido à sua simplicidade e eficácia. Definido como ( f(x) = máx.(0, x) ), O ReLU permite que os neurônios disparem apenas quando a entrada é positiva, o que ajuda a mitigar o problema do desbotamento do gradiente. Seu uso demonstrou melhorar o desempenho em várias tarefas de aprendizado profundo, tornando o ReLU uma opção...
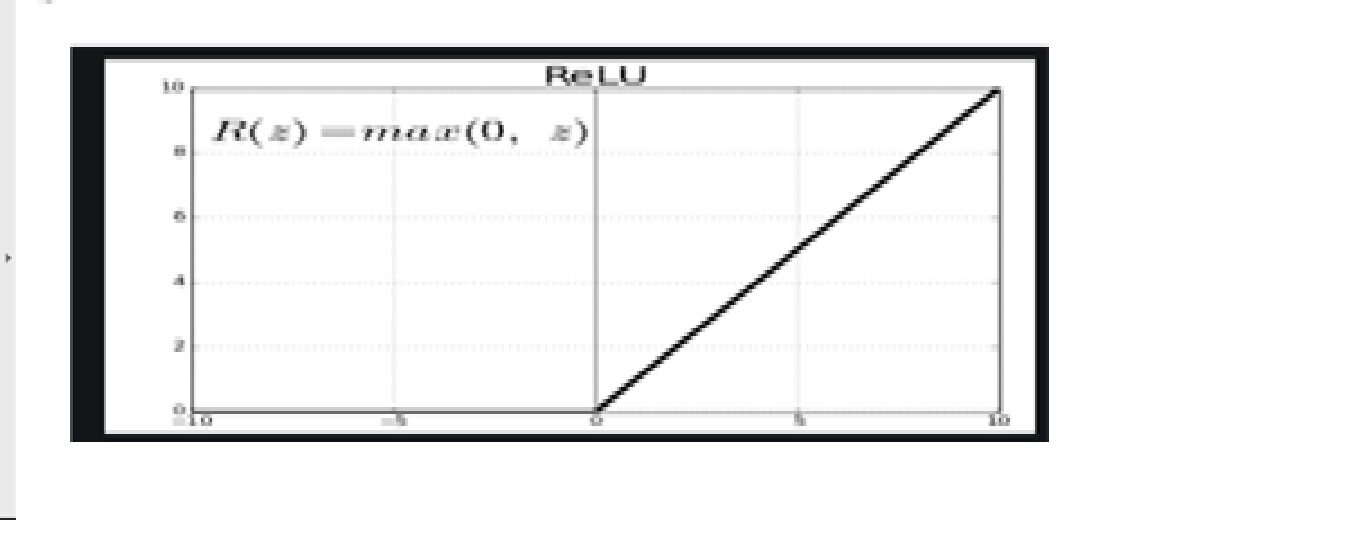
Uma vez que as imagens não são lineares, para fornecer não linearidade, a Função de ativação ReluA função de ativação do ReLU (Unidade linear retificada) É amplamente utilizado em redes neurais devido à sua simplicidade e eficácia. é definido como ( f(x) = máx.(0, x) ), o que significa que produz uma saída de zero para valores negativos e um incremento linear para valores positivos. Sua capacidade de mitigar o problema de desvanecimento de gradiente o torna a escolha preferida em arquiteturas profundas.... se aplica después de la operación convolucional.
Relu significa função de ativação linear retificada. a função relu vai gerar a entrada diretamente se for positiva; pelo contrário, vai gerar zero.
· Formulário de entrada
este argumento mostra o tamanho da imagem: 224 * 224 * 3. Uma vez que as imagens em formato RGB são assim, la tercera dimensão"Dimensão" É um termo usado em várias disciplinas, como a física, Matemática e filosofia. Refere-se à extensão em que um objeto ou fenômeno pode ser analisado ou descrito. Em física, por exemplo, fala-se de dimensões espaciais e temporais, enquanto em matemática pode se referir ao número de coordenadas necessárias para representar um espaço. Compreendê-lo é fundamental para o estudo e... de la imagen es 3.
3. Operação de agrupamento
Código Python:
model.add(MaxPooling2D(pool_size=2))
Precisamos aplicar a operação do pool depois de inicializar a CNN. Agrupamento é uma operação de downsampling da imagem. A camada de agrupamento é usada para reduzir as dimensões dos mapas de recursos. Portanto, la capa Pooling reduce la cantidad de parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... a aprender y reduce el cálculo en la red neuronal.
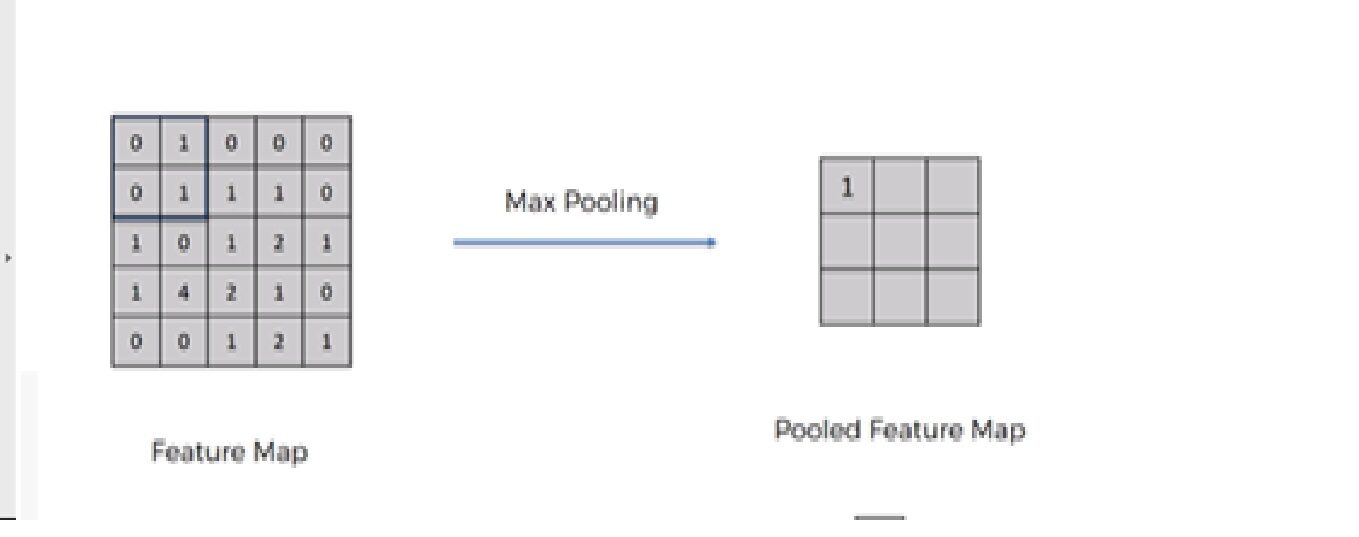
Operações futuras são realizadas em recursos de resumo criados pela camada de agrupamento. em vez de recursos precisamente localizados gerados pela camada de convolução. Isso leva ao modelo mais robusto a variações na orientação de recursos na imagem..
Existem principalmente 3 tipos de agrupamento: –
1. Agrupamento máximo
2. Agrupamento médio
3. Agrupamento global
4. Adicione duas camadas convolucionais
Para adicionar mais duas camadas convolucionais, precisamos repetir os passos 2 e 3 com uma pequena modificação no número de filtros.
Código Python:
model.add(Conv2D(filtros=32.kernel_size=2,estofamento="mesmo",ativação ="retomar")) model.add(MaxPooling2D(pool_size=2)) model.add(Conv2D(filtros=64.kernel_size=2,estofamento="mesmo",ativação ="retomar")) model.add(MaxPooling2D(pool_size=2))
Nós modificamos o 2Dakota do Norte e 3rd camadas convolucionais com número de filtro 32 e 64 respectivamente.
5. Operação de achatamento
Código Python:
model.add(Achatar())
A operação de achatamento é converter o conjunto de dados em uma matriz 1D para entrar na próxima camada, que é a camada totalmente conectada.
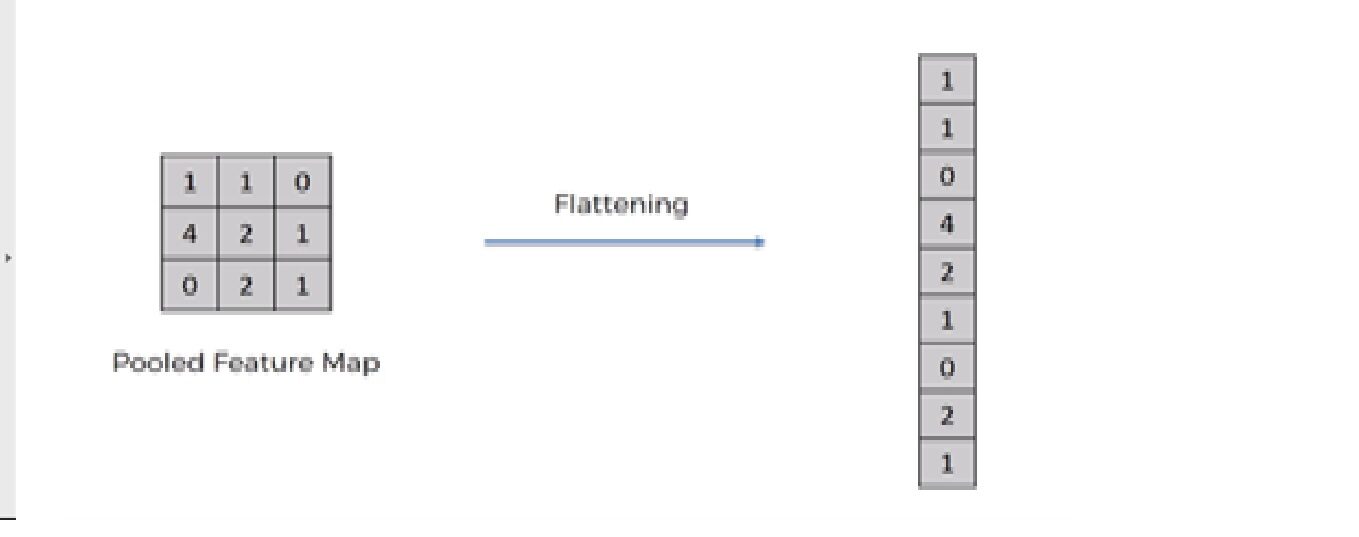
Depois de terminar o 3 Passos, agora nós agrupamos o mapa de recursos. Estamos agora achatando nossa saída depois de dois passos em uma coluna. Porque precisamos inserir esses dados 1D em uma camada de rede neural artificial.
6. Camada e camada de saída totalmente conectadas
A saída da operação de achatamento funciona como entrada para a rede neural. O objetivo da rede neural artificial torna a rede neural convolucional mais avançada e suficientemente capaz de classificar imagens..
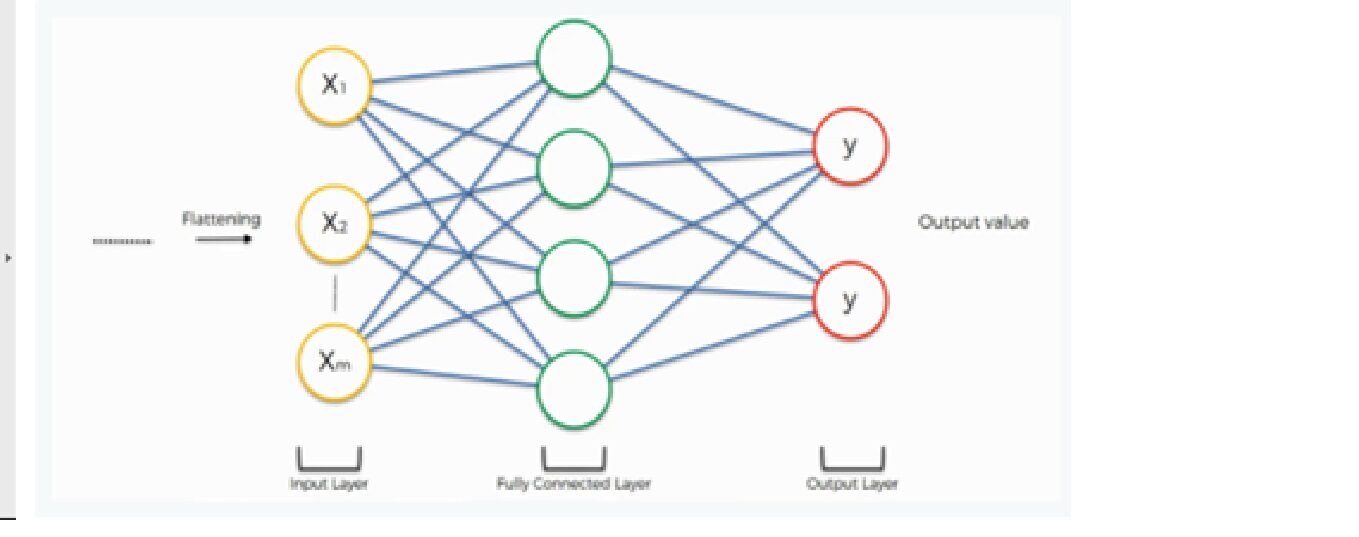
Aqui estamos usando uma classe densa da biblioteca Keras para criar uma camada e camada de saída totalmente conectada.
Código Python:
model.add(Denso(500,ativação ="retomar")) model.add(Denso(2,ativação ="softmax"))
A função de ativação SoftMax é usada para construir a camada de saída. Vamos analisar a função de ativação do softmax.
Função de ativação Softmax
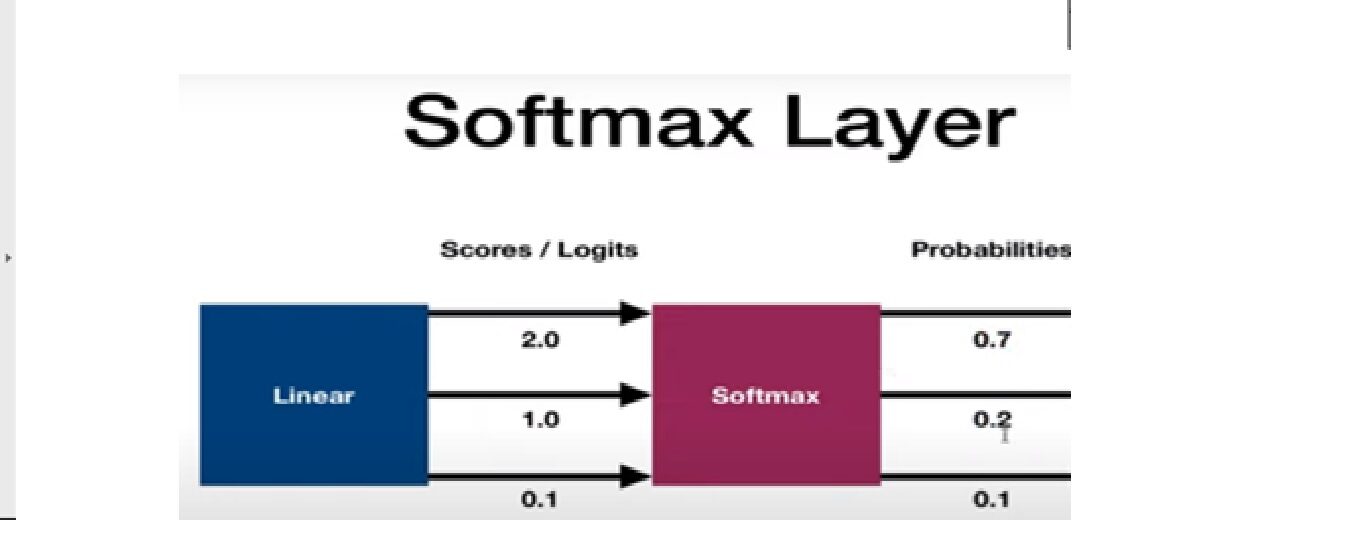
É usado como a função de ativação final de uma rede neural para levar a saída da rede neural a uma distribuição de probabilidades sobre as classes de predição.. A saída do Softmax está em probabilidades de cada resultado possível para prever a classe. A soma das probabilidades deve ser uma para todas as classes de previsão possíveis.
Agora, analicemos el TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... y la evaluación de la red neuronal convolucional. Vamos discutir esta seção em 3 Passos; –
Paso 1: compila o modelo CNN
Paso 2: ajustar o modelo no conjunto de treinamento
Paso 3: avaliar o resultado
Paso 1: compilar o modelo CNN
Linha de código
model.compile (perda = 'categorical_crossentropy', otimizador = 'adam', metrics =['precisão'])
Aqui estamos usando 3 argumentos: –
· Função de perdaA função de perda é uma ferramenta fundamental no aprendizado de máquina que quantifica a discrepância entre as previsões do modelo e os valores reais. Seu objetivo é orientar o processo de treinamento, minimizando essa diferença, permitindo assim que o modelo aprenda de forma mais eficaz. Existem diferentes tipos de funções de perda, como erro quadrático médio e entropia cruzada, cada um adequado para diferentes tarefas e...
Estamos usando o categorical_crossentropy função de perda que é usada na tarefa de classificação. Esta pérdida es una muy buena mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... de cuán distinguibles son dos distribuciones de probabilidad discretas entre sí.
Por favor, veja o link abaixo para uma descrição detalhada dos diferentes tipos de função de perda:
· Otimizador
Estamos usando Adam Optimizer que é usado para atualizar pesos de rede neural e taxa de aprendizado. Otimizadores são usados para resolver problemas de otimização minimizando a função.
Por favor, veja o link abaixo para uma explicação detalhada dos diferentes tipos de otimizador:
· Argumentos métricos
Aqui, estamos usando a precisão como uma métrica para avaliar o desempenho do algoritmo de rede neural convolucional.
Paso 2: ajuste modelo no conjunto de treinamento
Linha de código:
model.fit_generator(training_set,validation_data=test_set,épocas=50, steps_per_epoch=len(training_set), validation_steps=len(test_set) )
Estamos ajustando o modelo cnn no conjunto de dados de treinamento com 50 iterações e cada iteração tem passos diferentes para treinar e avaliar etapas dependendo da duração do teste e conjunto de treinamento.
Paso 3: – Avalie o resultado
Comparamos a função de precisão e perda para o conjunto de dados de treinamento e teste.
Código: Conspiração de perdas
plt.plot(r.history['perda'], rótulo ="perda de trem")
plt.plot(r.history['val_loss'], rótulo ="val_loss")
plt.legend()
plt.show()
plt.savefig('LossVal_loss')
Produção
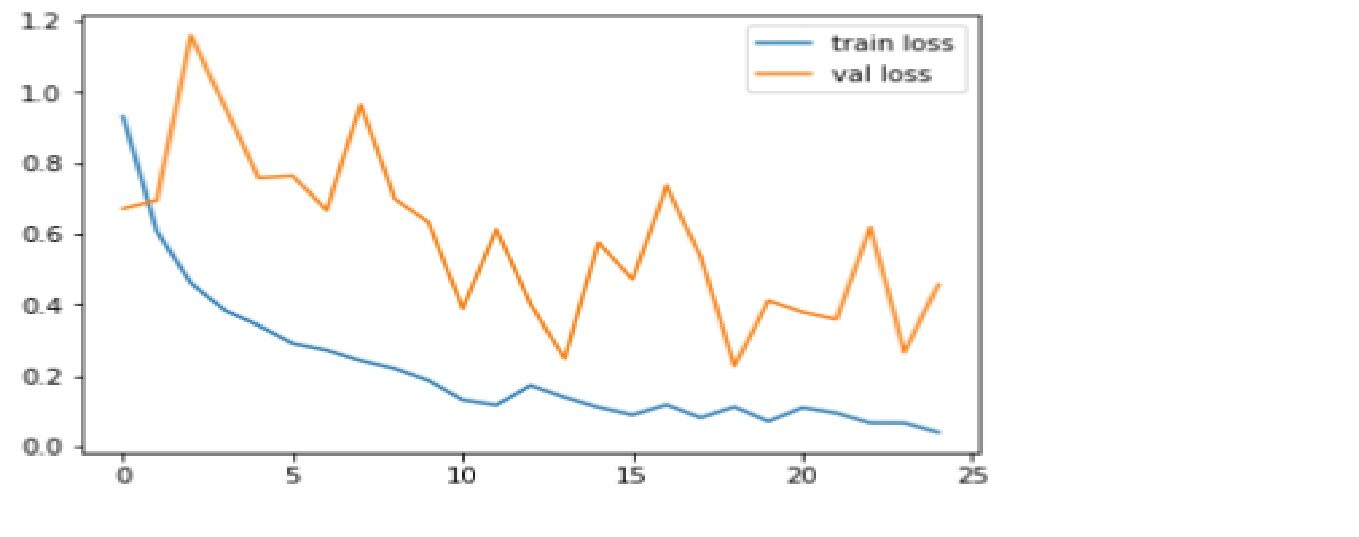
Perda é a punição para uma previsão ruim. O objetivo é tornar a perda de validação o mais baixa possível. Um pouco de overfit é quase sempre uma coisa boa. Tudo o que importa, ao final, isto é: é a menor perda possível de validação.
Código: Gráfico de precisão do gráfico
plt.plot(r.history['precisão'], rótulo ="acc trem")
plt.plot(r.history['val_accuracy'], rótulo ="val_acc")
plt.legend()
plt.show()
plt.savefig('AccVal_acc')
Produção
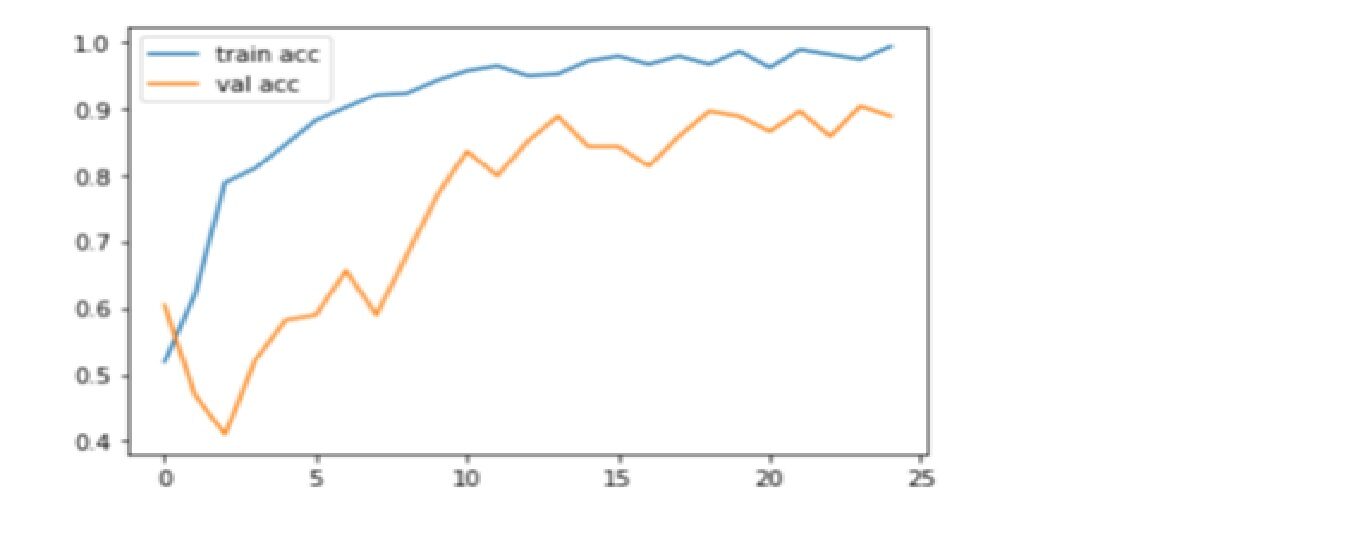
A precisão é uma métrica para avaliar modelos de classificação. Informalmente, precisão é a fração de previsões nosso modelo tem direito. Aqui, podemos observar que a precisão está perto do 90% no teste de validação mostrando que um modelo CNN está tendo um bom desempenho em métricas de precisão.
Obrigado pela leitura! Feliz aprendizado profundo!
Referências:
1. https://www.superdatascience.com/
2. https://www.youtube.com/watch?v=H-bcnHE6Mes
Sobre mim :
Sou Jitendra Sharma., estagiário de ciência de dados em Nabler, e me dedico ao PGDM-Big Data Analytics do Goa Institute of Management. Você pode entrar em contato comigo através LinkedIn e Github.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





