Introdução
A inteligência artificial e o aprendizado de máquina serão nossos maiores ajudantes na próxima década!!
Hoje pela manhã, Eu estava lendo um artigo que relatava que um sistema de inteligência artificial venceu 20 advogados e advogados ficaram muito felizes com o fato de a inteligência artificial poder cuidar de uma parte repetitiva de suas funções e ajudá-los a trabalhar em questões complexas. Esses advogados ficaram satisfeitos com o fato de a inteligência artificial permitir que desempenhem funções mais satisfatórias.
Hoje, Vou compartilhar um exemplo semelhante: como contar o número de pessoas em uma multidão usando Aprendizagem profunda e visão computacional? Mas, antes de fazer isso, vamos desenvolver uma noção de como a vida é fácil para um cientista que faz contagem de multidões.
Aja como um cientista contando multidões
Comecemos!
Você pode me ajudar a contar / estimar o número de pessoas nesta imagem que participarão deste evento?

OK, que tal este?

Fonte: Conjunto de dados ShanghaiTech
Você pega o jeito. No final deste tutorial, vamos criar um algoritmo para contagem de multidões com precisão surpreendente (em comparação com humanos como você e eu). Você usará tal assistente?
PD Este artigo pressupõe que você tenha um conhecimento básico de como funcionam as redes neurais convolucionais. (CNN). Você pode consultar a postagem abaixo para obter mais informações sobre este tópico antes de continuar.:
Tabela de conteúdo
- O que é contagem de multidão?
- Por que a contagem de multidões é necessária??
- Compreensão de diferentes técnicas de visão computacional para contagem de multidões
- Arquitetura CSRNet e métodos de treinamento
- Construindo Seu Próprio Modelo de Contagem de Multidão em Python
Este artigo é muito inspirado no artigo: CSRNet: Redes neurais convolucionais dilatadas para entender cenas altamente congestionadas.
O que é contagem de multidão?
Contagem de multidão é uma técnica para contar ou estimar o número de pessoas em uma imagem. Reserve um momento para analisar a imagem a seguir:
Fonte: Conjunto de dados ShanghaiTech
Você pode me dar um número aproximado de quantas pessoas estão na caixa? sim, incluindo aqueles presentes no fundo. O método mais direto é contar manualmente cada pessoa, mas isso faz sentido prático? É quase impossível quando a multidão é tão grande!
The Crowd Scientists (sim, Esse é um verdadeiro cargo!) Eles contam o número de pessoas em certas partes de uma imagem e, em seguida, extrapolam para chegar a uma estimativa. Mais comumente, tivemos que confiar em métricas brutas para estimar esse número por décadas.
Certamente deve haver uma abordagem melhor e mais precisa.
Se há!
Embora ainda não tenhamos algoritmos que podem nos dar o número EXATO, a maioria visão de computador As técnicas podem produzir estimativas impressionantemente precisas. Vamos primeiro entender por que a contagem de multidões é importante antes de mergulhar no algoritmo por trás dela..
Por que a contagem de multidões é útil??
Vamos entender a utilidade da contagem de multidão com um exemplo. Imagina isto: sua empresa acabou de hospedar uma conferência de ciência de big data. Muitas sessões diferentes foram realizadas durante o evento.
Você deve analisar e estimar o número de pessoas que participaram de cada sessão. Isso ajudará sua equipe a entender quais tipos de sessões atraíram as maiores multidões. (e quais falharam nesse sentido). Isso moldará a conferência do próximo ano, Portanto, é uma tarefa importante!

Havia centenas de pessoas no evento, Contá-los manualmente levará dias! É aí que entram suas habilidades como cientista de dados.. Ele conseguiu tirar fotos da multidão em cada sessão e criar um modelo de visão computacional para fazer o resto!!
Existem muitos outros cenários em que os algoritmos de contagem de multidões estão mudando a forma como as indústrias funcionam.:
- Contando o número de pessoas que participam de um evento esportivo
- Estimar quantas pessoas participaram de uma inauguração ou marcha (manifestações políticas, talvez)
- Monitoramento de áreas de alto tráfego
- Auxiliar na alocação de pessoal e recursos.
Você consegue pensar em outros casos de uso? Me avise na seção de comentários abaixo!! Podemos nos conectar e tentar descobrir como podemos usar técnicas de contagem de multidão em seu palco..
Compreensão de diferentes técnicas de visão computacional para contagem de multidões
Em termos gerais, existem atualmente quatro métodos que podemos usar para contar o número de pessoas em uma multidão:
1. Métodos baseados em detecção
Aqui, usamos um detector móvel semelhante a uma janela para identificar as pessoas em uma imagem e contar quantas. Os métodos usados para detecção requerem classificadores bem treinados que podem extrair características de baixo nível. Embora esses métodos funcionem bem para detectar faces, não funcionam bem em imagens lotadas, uma vez que a maioria dos objetos alvo não são claramente visíveis.
2. Métodos baseados em regressão
Não foi possível extrair recursos de baixo nível com a abordagem acima. Métodos baseados em regressão triunfam aqui. Primeiro, cortamos os patches da imagem e depois, para cada patch, nós extraímos as características de baixo nível.
3. Métodos baseados em estimativa de densidade
Primeiro, criamos um mapa de densidade para os objetos. Mais tarde, o algoritmo aprende um mapeamento linear entre os recursos extraídos e seus mapas de densidade de objeto. Também podemos usar a regressão de floresta aleatória para aprender o mapeamento não linear.
4. Métodos baseados em CNN
Ah, boas e confiáveis redes neurais convolucionais (CNN). Em vez de olhar para as manchas de uma imagem, criamos um método de regressão ponta a ponta usando CNN. Isso leva a imagem inteira como entrada e produz diretamente a contagem de pessoas. CNNs funcionam muito bem com tarefas de regressão ou classificação, e eles também provaram seu valor na geração de mapas de densidade.
CSRNet, uma técnica que implementaremos neste artigo, implementa CNN mais profundo para capturar recursos de alto nível e gerar mapas de densidade de alta qualidade sem expandir a complexidade da rede. Vamos entender o que é CSRNet antes de passar para a seção de codificação.
Compreender a arquitetura CSRNet e o método de treinamento
CSRNet usa VGG-16 como uma interface devido às suas capacidades de aprendizagem de alta transferência. O tamanho de saída VGG é um quinto do tamanho de entrada original. CSRNet também usa camadas convolucionais dilatadas na parte traseira.
Mas, Que diabos são convoluções dilatadas? É uma pergunta justa. Considere a seguinte imagem:
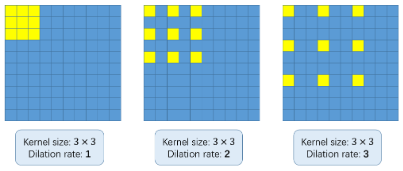
O conceito básico de usar convoluções dilatadas é aumentar o kernel sem aumentar os parâmetros. Então, se a taxa de dilatação é 1, pegamos o kernel e o convertemos na imagem inteira. Enquanto que, se aumentarmos a taxa de dilatação para 2, o núcleo se estende conforme mostrado na imagem acima (siga os rótulos em cada imagem). Pode ser uma alternativa ao agrupamento de camadas.
Matemática subjacente (recomendado, mas opcional)
Vou tomar um momento para explicar como funciona a matemática. Observe que isso não é obrigatório para implementar o algoritmo em Python, mas eu recomendo que você aprenda a ideia subjacente. Isso será útil quando você precisar ajustar ou modificar seu modelo..
Suponha que temos uma entrada x (m, n), um filtro w (eu, j) e a taxa de dilatação r. A saída e (m, n) será:
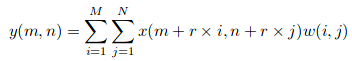
Podemos generalizar esta equação usando um kernel (k * k) com uma taxa de dilatação r. O núcleo aumenta para:
([k + (k-1)*(r-1)] * [k + (k-1)*(r-1)])
Então, a verdade básica foi gerada para cada imagem. A cabeça de cada pessoa em uma determinada imagem é desfocada usando um kernel gaussiano. Todas as imagens são cortadas em 9 patches e o tamanho de cada patch é um quarto do tamanho da imagem original. Comigo até agora?
Os primeiros 4 patches são divididos em 4 quartos e os outros 5 patches são cortados aleatoriamente. Finalmente, o espelho de cada patch é usado para duplicar o conjunto de treinamento.
Isso, em poucas palavras, são os detalhes da arquitetura por trás do CSRNet. A seguir, nós veremos seus detalhes de treinamento, incluindo avaliação métrica usada.
A descida gradiente estocástica é usada para treinar CSRNet como uma estrutura ponta a ponta. Durante o treinamento, a taxa de aprendizagem fixa é definida para 1e-6. A função de perda é considerada como a distância euclidiana para medir a diferença entre a verdade fundamental e o mapa de densidade estimada.. Isso é representado como:
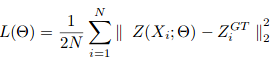
onde N é o tamanho do lote de treinamento. A métrica de avaliação usada no CSRNet é MAE e MSE, quer dizer, erro médio absoluto e erro médio quadrado. Estes são dados por:
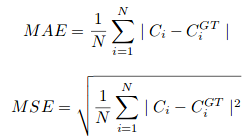
Aqui, Ci é a contagem estimada:
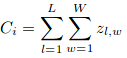
L e W são a largura do mapa de densidade prevista.
Nosso modelo irá primeiro prever o mapa de densidade para uma determinada imagem. O valor do pixel será 0 se não houver pessoa presente. Um certo valor predefinido será atribuído se esse pixel corresponder a uma pessoa. Então, calcular os valores totais de pixels correspondentes a uma pessoa nos dará a contagem de pessoas naquela imagem. Impressionante, verdade?
E agora, damas e cavalheiros, É hora de finalmente construir nosso próprio modelo de contagem de multidões!!
Construindo seu próprio modelo de contagem de multidões
Pronto com seu laptop ligado?
Implementaremos CSRNet no conjunto de dados ShanghaiTech. Este contém 1198 imagens anotadas de um total combinado de 330,165 pessoas. Você pode baixar o conjunto de dados em aqui.
Use o seguinte bloco de código para clonar o repositório CSRNet-pytorch. Contém todo o código para criar o conjunto de dados, treinar o modelo e validar os resultados:
git clone https://github.com/leeyeehoo/CSRNet-pytorch.git
Por favor instale MILAGRES e PyTorch antes de continuar. Esses são o backbone por trás do código que usaremos a seguir.
Agora, mova o conjunto de dados para o repositório que você clonou anteriormente e descompacte-o. Mais tarde, precisaremos criar os valores básicos de verdade. a make_dataset.ipynb arquivo é nosso salvador. Precisamos apenas fazer pequenas alterações nesse bloco de notas:
#definindo a raiz para o conjunto de dados de Shanghai que você baixou # mude o caminho raiz de acordo com a localização do conjunto de dados root ="/home / pulkit / CSRNet-pytorch /"
Agora, vamos gerar os valores reais básicos para as imagens na parte_A e na parte_B:
Gerar o mapa de densidade para cada imagem é uma etapa do tempo. Então, faça uma xícara de café enquanto o código é executado.
Até agora, geramos os valores de verdade básicos para as imagens na parte_A. Faremos o mesmo com as imagens part_B. Mas antes disso, Vamos dar uma olhada em uma imagem de amostra e traçar seu mapa de calor real do solo.:
plt.imshow(Image.open(img_paths[0]))
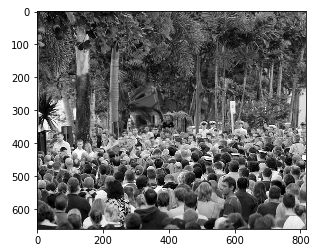
As coisas estão ficando interessantes!
gt_file = h5py.File(img_paths[0].substituir('.jpg','.h5').substituir('imagens','verdade fundamental'),'r')
groundtruth = np.asarray(gt_file['densidade'])
plt.imshow(verdade fundamental,cmap = CM.jet)
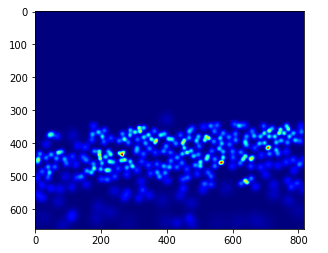
Vamos contar quantas pessoas estão presentes nesta imagem:
np.sum(verdade fundamental)
270.32568
Do mesmo modo, generaremos valores para part_B:
Agora, nós temos as imagens, bem como seus valores de verdade fundamentais correspondentes. É hora de treinar nosso modelo!
Usaremos os arquivos .json disponíveis no diretório clonado. Só temos que mudar a localização das imagens nos arquivos json. Para fazer isso, abra o arquivo .json e substitua o local atual pelo local onde suas imagens estão.
Observe que todo esse código é escrito em Python 2. Faça as seguintes alterações se estiver usando qualquer outra versão do Python:
- Em model.py, mudar xrange na linha 18 um intervalo
- Mudar a linha 19 em model.py com: Lista (self.frontend.state_dict (). Itens ())[eu][1].dados[:] = lista (mod.state_dict (). Itens ())[eu][1].dados[:]
- Em image.py, substitua ground_truth por ground-truth
Você fez as mudanças?? Agora, abrir uma nova janela terminal e digitar os seguintes comandos:
cd CSRNet-pytorch
python train.py part_A_train.json part_A_val.json 0 0
Novamente, sentar-se, porque isso vai levar algum tempo. Ele pode reduzir o número de épocas no train.py arquivo para acelerar o processo. Uma boa opção alternativa é baixar os pesos pré-treinados. daqui se você não quiser esperar.
Finalmente, vamos verificar o desempenho do nosso modelo em dados invisíveis. Nós vamos usar o val.ipynb arquivo para validar os resultados. Lembre-se de mudar a rota para pesos e imagens previamente treinados.
#defining the image path
img_paths = []
para o caminho em path_sets:
para img_path em glob.glob(os.path.join(caminho, '*.jpg')):
img_paths.append(img_path)
modelo = CSRNet()
#defining the model
model = model.cuda()
#loading the trained weights
checkpoint = torch.load('part_A/0model_best.pth.tar')
model.load_state_dict(Ponto de verificação['state_dict'])
Verifique o MAE (erro absoluto médio) nas imagens de teste para avaliar nosso modelo:
Temos um valor MAE de 75,69, o que é muito bom. Agora vamos revisar as previsões em uma única imagem:
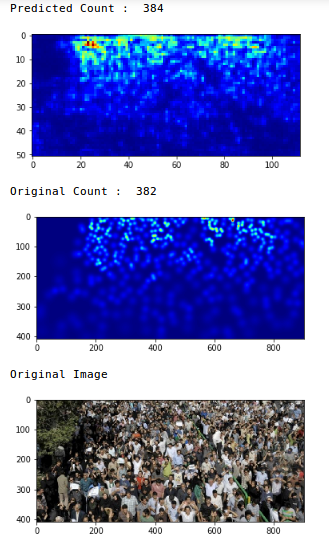 Uau, a contagem original era 382 e nosso modelo estimou que havia 384 pessoas na foto. Esse é um desempenho muito impressionante!!
Uau, a contagem original era 382 e nosso modelo estimou que havia 384 pessoas na foto. Esse é um desempenho muito impressionante!!
Parabéns por construir seu próprio modelo de contagem de multidões!!
Notas finais
Eu o encorajo a tentar essa abordagem em imagens diferentes e compartilhar seus resultados na seção de comentários abaixo.. A contagem de multidões tem muitas aplicações diversas e já está sendo adotada por organizações e agências governamentais..
É uma habilidade útil para adicionar ao seu portfólio. Um grande número de indústrias estará procurando cientistas de dados que possam trabalhar com algoritmos de contagem de multidões. Aprender, experimente e dê a si mesmo o dom do aprendizado profundo!
Você achou este artigo útil? Fique à vontade para me deixar suas sugestões e comentários abaixo, e ficarei feliz em me comunicar com você.
Você também deve verificar os recursos abaixo para aprender e explorar o maravilhoso mundo da visão computacional.:





