Este artigo foi publicado como parte do Data Science Blogathon.
Introdução
“Faz parte do estágio de editor de conteúdo”
“Toda vez que vou ao cinema, é mágico, não importa o que seja”. – Steven Spielberg
Todo mundo adora filmes, independente da sua idade, sexo, raça, cor ou localização geográfica. Todo mundo, de alguma forma, estamos conectados uns aos outros através deste meio incrível. Porém, o mais interessante é o fato de exclusivo nossas escolhas e combinações são em termos de preferências de filme. Algumas pessoas gostam de filmes de gênero específico, qualquer suspense, romance ou ficção científica, enquanto outros se concentram nos atores e diretores principais. Quando levamos tudo isso em consideração, é incrivelmente difícil generalizar um filme e dizer que todos gostariam dele. Mas com tudo que disse, Filmes semelhantes ainda são vistos como apreciados por uma parte específica da sociedade.
Então é aqui que nós, como cientistas de dados, nós entramos em jogo e extraímos o suco de todos padrões de comportamento não só do público, mas também dos próprios filmes. Então, sem mais preâmbulos, vamos direto ao básico de um sistema de recomendação.
O que é um sistema de recomendação?
Basta colocar um Sistema de recomendação é um programa de filtragem cujo objetivo principal é prever o “qualificação” o la “preferência” de um usuário para um elemento específico ou elemento do domínio. No nosso caso, este item específico do domínio é um filme, portanto, o foco principal de nosso sistema de recomendação é filtrar e prever apenas os filmes que um usuário prefere, dados alguns dados sobre o próprio usuário.
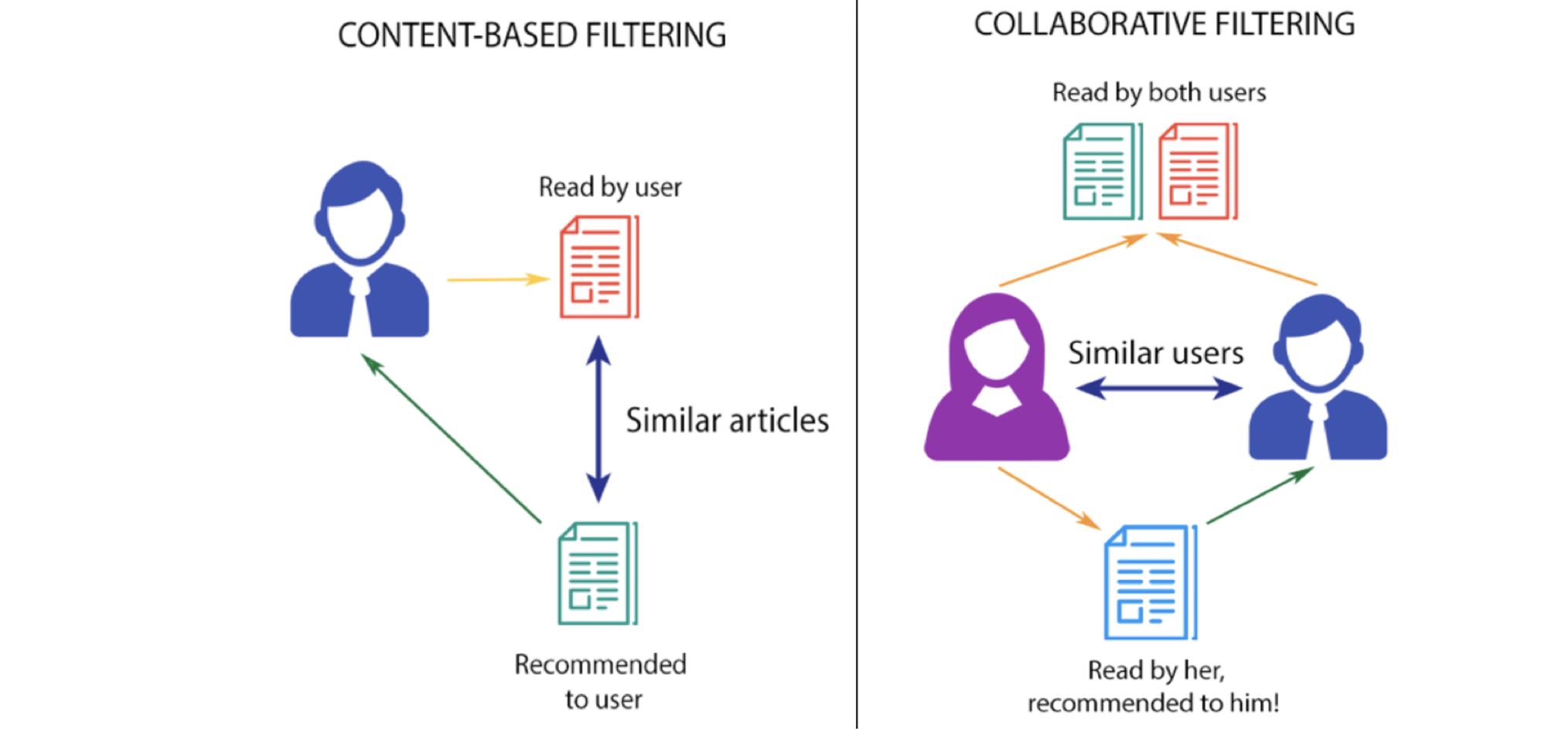
-
filtragem baseada em conteúdo
Esta estratégia de filtragem é baseada nos dados fornecidos sobre os artigos. O algoritmo recomenda produtos que são semelhante que gostou de um usuário no último. Esta semelhança (geralmente semelhança de cosseno) é calculado a partir dos dados que temos sobre os elementos, bem como as preferências anteriores do usuário.
Por exemplo, se um usuário gosta de filmes como 'The Prestige’ então podemos recomendar-lhe os ‘filmes de Christian Bale’ ou filmes do gênero ‘Thriller’ ou talvez até filmes dirigidos por ‘Christopher Nolan’. O sistema de recomendação verifica as preferências anteriores do usuário e encontra o filme “O prestígio”, luego intenta encontrar películas similares a la que utiliza la información disponible en la base de dadosUm banco de dados é um conjunto organizado de informações que permite armazenar, Gerencie e recupere dados com eficiência. Usado em várias aplicações, De sistemas corporativos a plataformas online, Os bancos de dados podem ser relacionais ou não relacionais. O design adequado é fundamental para otimizar o desempenho e garantir a integridade das informações, facilitando assim a tomada de decisão informada em diferentes contextos...., como os atores principais, o diretor, o gênero do filme, a casa de produção, etc y, com base nesta informação, Procure por filmes como “The Prestige”.
Desvantagens
- Produtos diferentes não ganham muito exposição ao usuário.
- Os negócios não podem ser expandidos porque o usuário não tenta diferentes tipos de produtos.
-
Filtragem colaborativa
Esta estratégia de filtragem é baseada na combinação do comportamento do usuário, comparando-o e contrastando-o com Outros usuários comportamento no banco de dados. A historia de todos os usuários desempenha um papel importante neste algoritmo. A principal diferença entre a filtragem baseada em conteúdo e a filtragem colaborativa é que na última, a interação de todos os usuários com artigos influencia o algoritmo de recomendação, enquanto para filtragem baseada em conteúdo apenas dados do usuário interessado é levado em consideração.
Existem várias maneiras de implementar a filtragem colaborativa, mas o principal conceito a entender é que na filtragem colaborativa múltiplo Os dados do usuário influenciam o resultado da recomendação. e não depende de apenas um dado de usuário para modelar.
Existem 2 tipos de algoritmos de filtragem colaborativa:
-
Filtragem colaborativa baseada no usuário
A ideia básica aqui é encontrar usuários que tenham padrões de preferência anteriores semelhantes Como o usuário ‘A’ e, em seguida, recomendar itens que agradam aos usuários semelhantes a 'A’ ainda não encontrei. Isso é feito fazendo um matriz de itens que cada usuário classificou, visto, curtiu ou clicou dependendo da tarefa em mãos, e, em seguida, calcular a pontuação de similaridade entre os usuários e, finalmente, recomendar itens que o usuário em questão não conhece, mas isso para usuários semelhantes a ele / eles gostam dela.
Por exemplo, sim para o usuário 'A’ ele gosta de 'Batman Begins', 'Liga da Justiça’ y ‘Os Vingadores’ enquanto o usuário ‘B’ ele gosta de 'Batman Begins', 'Liga da Justiça’ e ‘Thor’, então eles têm interesses semelhantes porque sabemos que esses filmes pertencem ao gênero de super-heróis. Portanto, há uma grande probabilidade de que o usuário ‘A’ como ‘Thor’ e para o usuário 'B’ você gosta de The Avengers '.
Desvantagens
- A gente é volúvel quer dizer, seu gosto muda de tempos em tempos e como este algoritmo é baseado na semelhança do usuário, pode detectar padrões de semelhança inicial entre 2 usuários que depois de um tempo podem ter preferências completamente diferentes.
- Existem muitos mais usuários do que elementos portanto, é muito difícil manter matrizes tão grandes e, portanto, eles precisam ser recalculados regularmente.
- Este algoritmo é muito suscetível a ataques de xelim onde perfis de usuário falsos que consistem em padrões de preferência distorcidos são usados para manipular decisões-chave.
-
Filtragem colaborativa baseada em elemento
O conceito neste caso é procure por filmes semelhantes em vez de usuários semelhantes e depois recomendar filmes semelhantes aos ‘A’ teve em suas preferências anteriores. Isso é feito encontrando cada par de itens que foram avaliados / vistos / Eles gostam de mim / clicado pelo mesmo usuário, em seguida, medindo a semelhança daqueles avaliados / vistos / apreciado / clicou em todos os usuários que avaliaram / eles viram / me agradaram / eles clicaram em ambos, e, finalmente, recomendando-os com base nas pontuações de similaridade.
Aqui, por exemplo, nós levamos 2 filmes 'A’ e B’ e verificamos suas avaliações de todos os usuários que avaliaram os dois filmes e com base na semelhança dessas avaliações, e com base nessa semelhança de classificação por usuários que avaliaram ambos, encontramos filmes semelhantes. Então, se os usuários mais comuns classificaram 'A’ e B’ da mesma forma e é altamente provável que 'A’ e B’ são similares, portanto, se alguém viu e gostou de 'A', ele deve ser recomendado 'B’ e vice-versa.
Vantagens sobre a filtragem colaborativa baseada no usuário
- Ao contrário do gosto do povo, os filmes não mudam.
- Geralmente há muitos menos artigos do que pessoas, portanto, é mais fácil manter e calcular as matrizes.
- Ataques de xelim são muito mais difíceis porque itens não podem ser falsificados.
-
Vamos começar a programar nosso próprio sistema de recomendação de filmes.
Nesta implementação, quando o usuário procura por um filme, nós iremos recomendar o 10 melhores filmes semelhantes usando nosso sistema de recomendação de filmes. Nós vamos usar filtragem colaborativa baseada em elemento algoritmo para o nosso propósito. O conjunto de dados usado nesta demonstração é o movielens-small data set.
Coloque os dados para trabalhar
Primeiro, precisamos importar bibliotecas que usaremos em nosso sistema de recomendação de filmes. O que mais, vamos importar o conjunto de dados adicionando o caminho do CSV registros.
importar pandas como pd import numpy as np from scipy.sparse import csr_matrix from sklearn.neighbors import NearestNeighbors import matplotlib.pyplot as plt import seaborn as sns movies = pd.read_csv("../input/movie-lens-small-latest-dataset/movies.csv") avaliações = pd.read_csv("../input/movie-lens-small-latest-dataset/ratings.csv")
Agora que adicionamos os dados, vamos dar uma olhada nos arquivos usando o dataframe.head () comando para imprimir os primeiros 5 linhas no conjunto de dados.
Vamos dar uma olhada no conjunto de dados do filme:
filmes.cabeça()
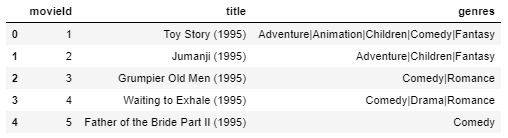
O conjunto de dados do filme tem
- movieId: uma vez que a recomendação é feita, temos uma lista de todos os movieIds semelhantes e obter o título de cada filme neste conjunto de dados.
- bens – o que é não é necessário para esta abordagem de filtragem.
classificações.cabeça()
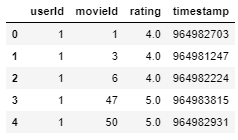
O conjunto de dados de notas tem
- ID do usuário: único para cada usuário.
- movieId: com esta função, pegamos o título do filme do conjunto de dados do filme.
- Avaliação – Avaliações dadas por cada usuário para todos os filmes usando este, vamos prever o 10 melhores filmes semelhantes.
Aqui, podemos ver aquele userId 1 tenho Visto movieId 1 e 3 e ambos pontuaram com 4.0, mas tem Não avaliado movieId 2 em absoluto. Esta interpretação é mais difícil para extrair deste quadro de dados. Portanto, para tornar as coisas mais fáceis de entender e trabalhar com, vamos criar um novo quadro de dados onde cada coluna representaria cada ID de usuário único e cada linha representaria cada ID de filme único.
final_dataset = ratings.pivot(index = 'movieId',colunas ="ID do usuário",valores ="Avaliação") final_dataset.head()
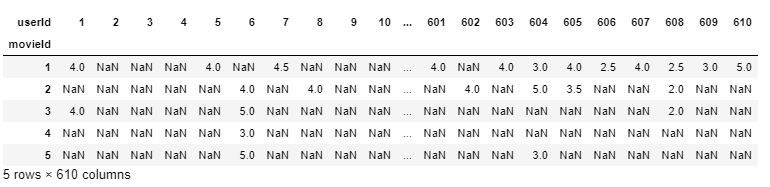
Agora, é muito mais fácil interpretar do que userId 1 avaliado movieId 1 & 3 4.0 mas não avaliado movieId 3,4,5 em absoluto (portanto, são representados como NaN) e, portanto, seus dados de avaliação estão faltando.
Vamos consertar isso e imputar NaN con 0 para tornar as coisas compreensíveis para o algoritmo e também tornar os dados mais reconfortantes para os olhos.
final_dataset.fillna(0,inplace = True) final_dataset.head()
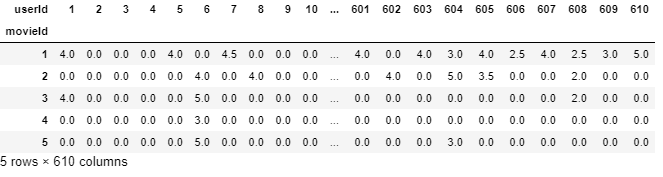
Remova o ruído dos dados
No mundo real, as notas são muito escasso e os pontos de dados são coletados principalmente de filmes populares e usuários altamente engajados. Não queremos filmes que foram avaliados por um pequeno número de usuários porque é não credível o suficiente. Do mesmo modo, usuários que avaliaram apenas um punhado de filmes também não deve ser levado em consideração.
Então, com tudo isso levado em consideração e alguns experimentos de tentativa e erro, vamos reduzir o ruído adicionando alguns filtros para o conjunto de dados final.
- Para avaliar um filme, um mínimo de 10 os usuários deveriam ter votado em um filme.
- Para avaliar um usuário, um mínimo de 50 filmes deveriam ter votado no usuário.
Vamos visualizar como são esses filtros
Adicionando o número de usuários que votaram e o número de filmes que foram votados.
no_user_voted = ratings.groupby('movieId')['Avaliação'].agg('contar')
no_movies_voted = ratings.groupby('ID do usuário')['Avaliação'].agg('contar')
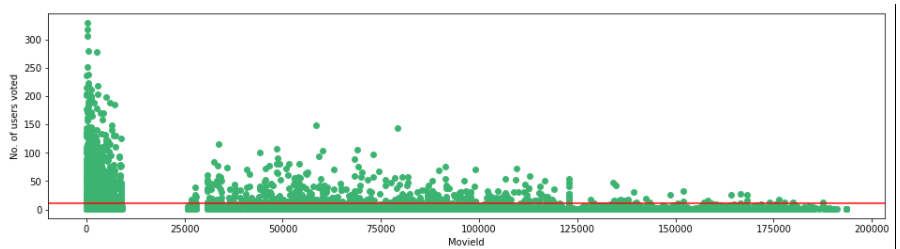
Vamos visualizar o número de usuários que votaram com nosso limite de 10.
f,ax = plt.subplots(1,1,figsize =(16,4))
# avaliações['Avaliação'].enredo(criança = 'hist')
plt.scatter(no_user_voted.index,no_user_voted,color ="médio-verde")
plt.axhline(y = 10, cor ="r")
plt.xlabel('MovieId')
plt.ylabel('Não. de usuários votaram ')
plt.show()
Faça as modificações necessárias de acordo com o limite estabelecido.
final_dataset = final_dataset.loc[no_user_voted[no_user_voted > 10].índice,:]
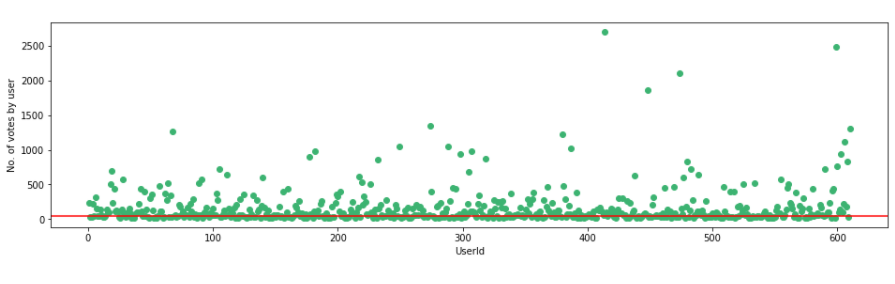
Vamos visualizar o número de votos de cada usuário com nosso limite de 50.
f,ax = plt.subplots(1,1,figsize =(16,4))
plt.scatter(no_movies_voted.index,no_movies_voted,color ="médio-verde")
plt.axhline(y = 50, cor ="r")
plt.xlabel('ID do usuário')
plt.ylabel('Não. de votos por usuário ')
plt.show()
Realizando as modificações necessárias de acordo com o limite estabelecido.
final_dataset = final_dataset.loc[:,no_movies_voted[no_movies_voted > 50].índice] final_dataset
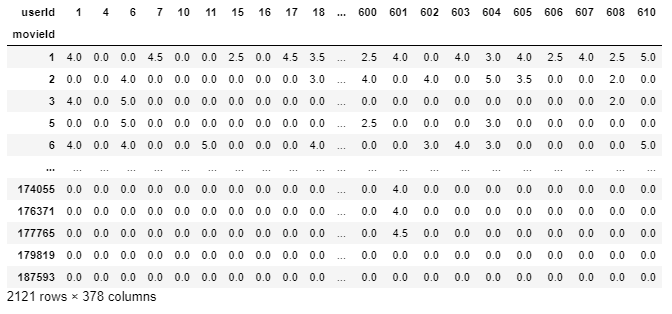
Elimine a escassez
Nosso final_dataset tem dimensões de 2121 * 378 onde a maioria dos valores são escassos. Estamos usando apenas um pequeno conjunto de dados, mas para o conjunto de dados de lente de filme grande original, que tem mais do que 100000 caracteristicas, nosso sistema pode ficar sem recursos computacionais quando alimentado para o modelo. Para reduzir a dispersão, usamos a função csr_matrix da biblioteca scipy.
Vou dar um exemplo de como funciona:
amostra = np.array([[0,0,3,0,0],[4,0,0,0,2],[0,0,0,0,1]]) esparsidade = 1.0 - ( np.count_nonzero(amostra) / flutuador(sample.size) ) imprimir(esparsidade)

csr_sample = csr_matrix(amostra) imprimir(csr_sample)

Como você pode ver, no hay un valor escaso en csr_sample y los valores se asignan como índiceo "Índice" É uma ferramenta fundamental em livros e documentos, que permite localizar rapidamente as informações desejadas. Geralmente, é apresentado no início de um trabalho e organiza os conteúdos de forma hierárquica, incluindo capítulos e seções. Sua correta preparação facilita a navegação e melhora a compreensão do material, tornando-se um recurso essencial para estudantes e profissionais de várias áreas.... de filas y columnas. para a linha 0 e a segunda coluna, o valor é 3.
Aplicando o método csr_matrix ao conjunto de dados:
csr_data = csr_matrix(final_dataset.values) final_dataset.reset_index(inplace = True)
Modelar o sistema de recomendação de filmes
Usaremos o algoritmo KNN para calcular a similaridade com distância cosseno métrica que é muito rápida e mais preferível do que coeficiente de Pearson.
knn = vizinhos mais próximos(métrica ="cosseno", algoritmo = 'bruto', n_neighbours = 20, n_jobs = -1) knn.fit(csr_data)
Fazendo a função de recomendação
O princípio de operação é muito simples. Primeiro nós verificamos se a entrada do nome do filme está no banco de dados e se for, usamos nosso sistema de recomendação para encontrar filmes semelhantes e classificá-los de acordo com sua distância de semelhança e gerar apenas o principal 10 filmes com suas distâncias do filme de entrada.
def get_movie_recommendation(movie_name):
n_movies_to_reccomend = 10
movie_list = filmes[Filmes['título'].str.contains(movie_name)]
se len(movie_list):
movie_idx= movie_list.iloc[0]['movieId']
movie_idx = final_dataset[final_dataset['movieId'] ==movie_idx].índice[0]
distâncias , índices = knn.kneighbors(csr_data[movie_idx],n_neighbors=n_movies_to_reccomend+1)
rec_movie_indices = classificado(Lista(fecho eclair(índices.squeeze().listar(),distâncias.squeeze().listar())),key=lambda x: x[1])[:0:-1]
recommend_frame = []
para val em rec_movie_indices:
movie_idx = final_dataset.iloc[val[0]]['movieId']
idx = filmes[Filmes['movieId'] ==movie_idx].index
recommend_frame.append({'Título':filmes.iloc[idx]['título'].valores[0],'Distância':val[1]})
df = pd.DataFrame(recommend_frame,índice = intervalo(1,n_movies_to_reccomend+1))
return df
else:
Retorna "Nenhum filme encontrado. Por favor, verifique sua entrada"
Finalmente, nós iremos recomendar alguns filmes!
get_movie_recommendation('Homem de Ferro')
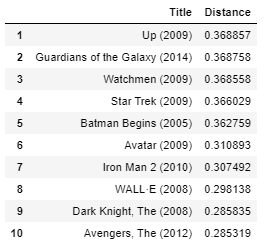
Pessoalmente, Eu acho que os resultados são muito bons. Todos os filmes no topo são super-herói ou animação filmes que são ideais para crianças, como o filme de entrada “Homem de Ferro”.
Vamos tentar outro:
get_movie_recommendation('Lembrança')
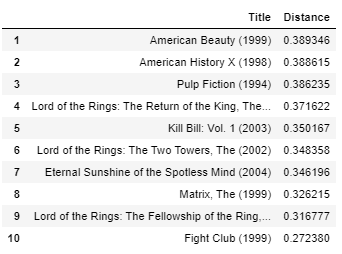
Todos os melhores filmes 10 filho sério e consciencioso filmes como o próprio "Memento", então eu acho que o resultado, neste caso, Também é bom.
Nosso modelo funciona muito bem: um sistema de recomendação de filmes baseado no comportamento do usuário. Portanto, concluímos nossa filtragem colaborativa aqui. Você pode obter o bloco de notas de implantação completo aqui.





