Este artigo foi publicado como parte do Data Science Blogathon.
Introdução
Detecção de anomalia de série temporal
Todo o processo de detecção de anomalias para um Série temporalUma série temporal é um conjunto de dados coletados ou medidos em momentos sucessivos, geralmente em intervalos de tempo regulares. Esse tipo de análise permite identificar padrões, Tendências e ciclos nos dados ao longo do tempo. Sua aplicação é ampla, abrangendo áreas como economia, Meteorologia e saúde pública, facilitando a previsão e a tomada de decisões com base em informações históricas.... ocorre em 3 Passos:
- Decompor a série temporal nas variáveis subjacentes; Tendência, sazonalidade, resíduo.
- Crie limites superiores e inferiores com algum valor de limite
- Identifique os pontos de dados que estão fora dos limites como anomalias.
Caso de estudo
Vamos baixar o conjunto de dados do site do governo de Cingapura, que é facilmente acessível. Consumo total de eletricidade nas residências, por tipo de habitação. O site de dados do governo de Cingapura trava facilmente. Este conjunto de dados mostra o consumo total de eletricidade das famílias por tipo de habitação (e GWh).
Gerenciado pela Autoridade do Mercado de Energia
Frequência Anual
Fonte (s) Autoridade do Mercado de Energia
Licença de Licença de Dados Abertos de Cingapura
Instalar e fazer upload de pacotes R
Neste exercício, vamos trabalhar com 2 Pacotes principais para detecção de anomalias de séries temporais em R: anômalo e calendário. Isso requer que o objeto seja criado como uma tabela de tempo, então também carregaremos os pacotes tibble. Vamos primeiro instalar e carregar essas bibliotecas.
pacote <- c('tidyverse','tibbletime','anomalize','cronograma')
install.packages(pacote)
biblioteca(tidyverse)
biblioteca(tibbletime)
biblioteca(anomalizar)
biblioteca(calendário)
Carregar dados
Na etapa anterior, baixamos o arquivo de consumo total de eletricidade por tipo de residência (e GWh) do site do governo de Cingapura. Vamos carregar o arquivo CSV em um quadro de dados R.
df <- read.csv("C:Detecção de anomalias em Rtotal-domicílio-eletricidade-consumo.csv")
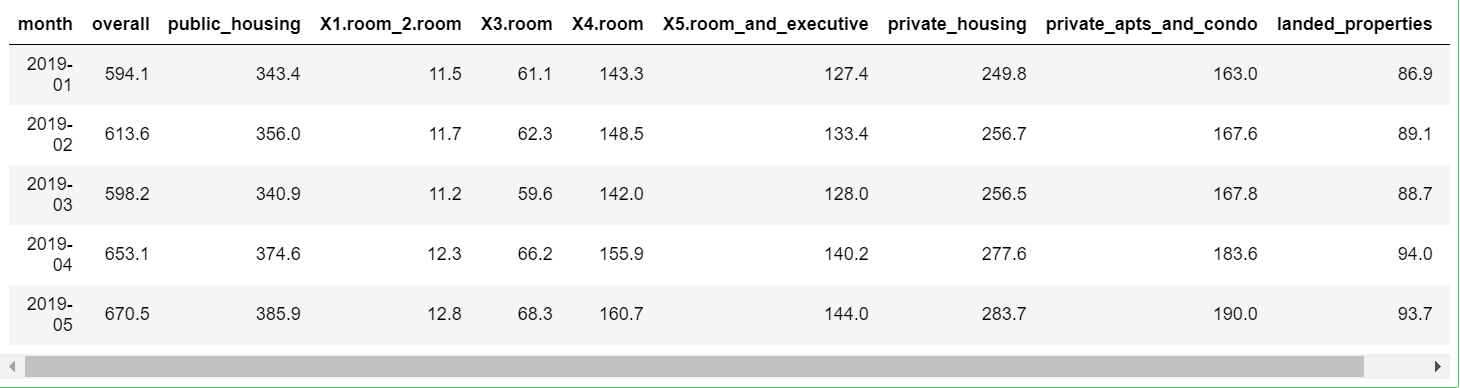
cabeça(df,5)
Processamento de dados
Antes que possamos aplicar qualquer algoritmo de anomalia aos dados, temos que mudá-lo para um formato de data.
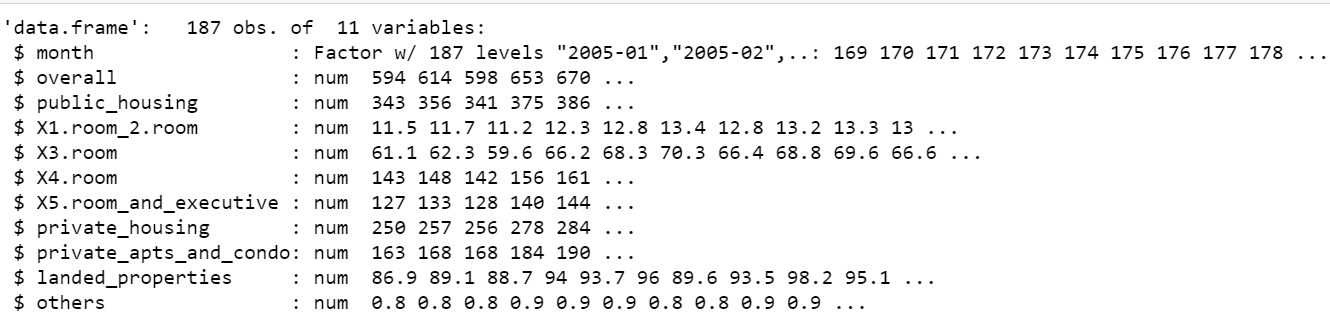
A coluna do mês’ é originalmente em formato fatorial com muitos níveis. Vamos convertê-lo para um tipo de data e selecionar apenas as colunas relevantes no quadro de dados.
str(df)
# Change Factor to Date format df$month <- colar(df$mês, "01", sep ="-") # Select only relevant columns in a new dataframe df$month <- ás. Data(df$mês,format ="%Y-%m-%d")
df <- df %>% selecionar(mês,geral)
# Convert df to a tibble
df <- as_tibble(df)
classe(df)
Usando o pacote 'anomalize'’
O pacote de anomalização R'’ permite um fluxo de trabalho para detectar anomalias nos dados. As principais funções são time_decompose (), anomalizar (), e time_recompose ().
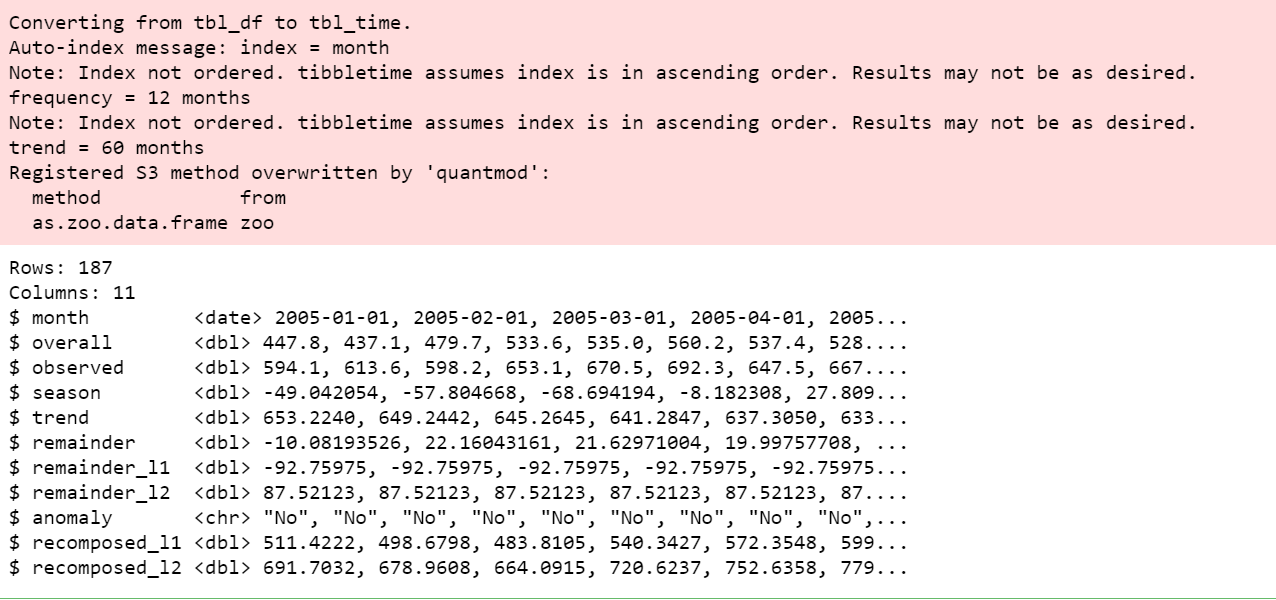
df_anomalized <- df %>%
time_decompose(geral, mesclagem = TRUE) %>%
anomalizar(restante) %>%
time_recompose()
df_anomalized%>% Vislumbre()
Visualize anomalias
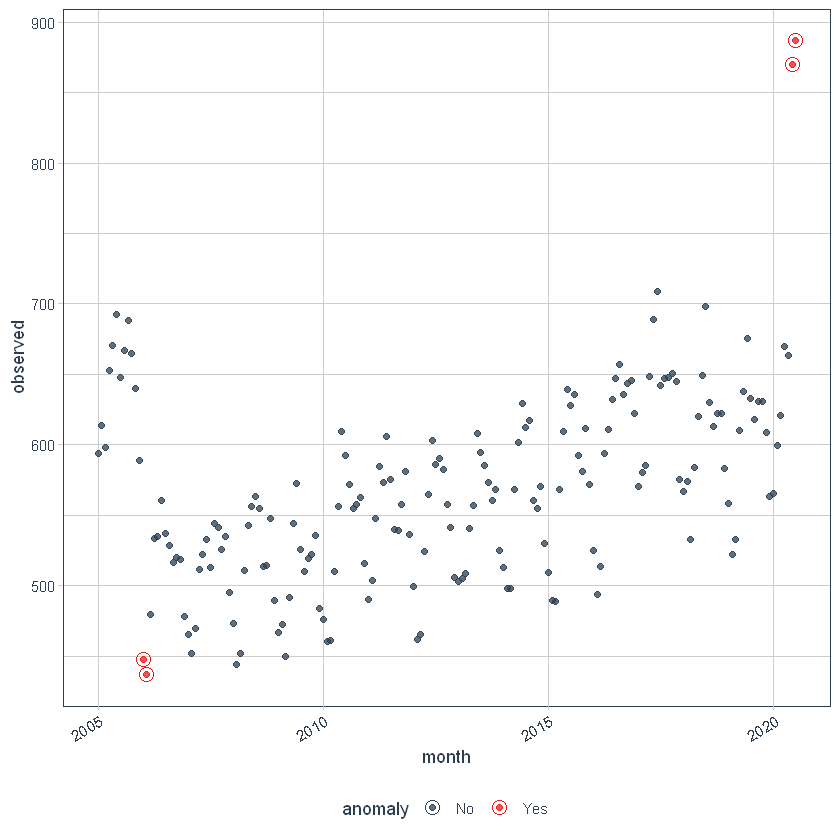
Podemos então visualizar as anomalias usando o plot_anomalies () Função.
df_anomalized%>% plot_anomalies(ncol = 3, alpha_dots = 0.75)
Ajuste de tendência e sazonalidade
Com anomalize, é fácil fazer ajustes porque tudo é feito com uma informação de data ou carimbo de data / hora, para que você possa selecionar intuitivamente incrementos para períodos de tempo que façam sentido (por exemplo, "5 minutos" ou "1 mês").
Primeiro, observe que uma frequência e uma tendência foram selecionadas automaticamente para nós. Isso ocorre por design. Os argumentos frequência = “auto” e tendência = “auto” são os valores padrão. Podemos visualizar essa decomposição usando plot_anomaly_decomposition ().
p1 <- df_anomalized%>%
plot_anomaly_decomposition() +
ggtitle("Freq / Trend = 'auto'")
p1
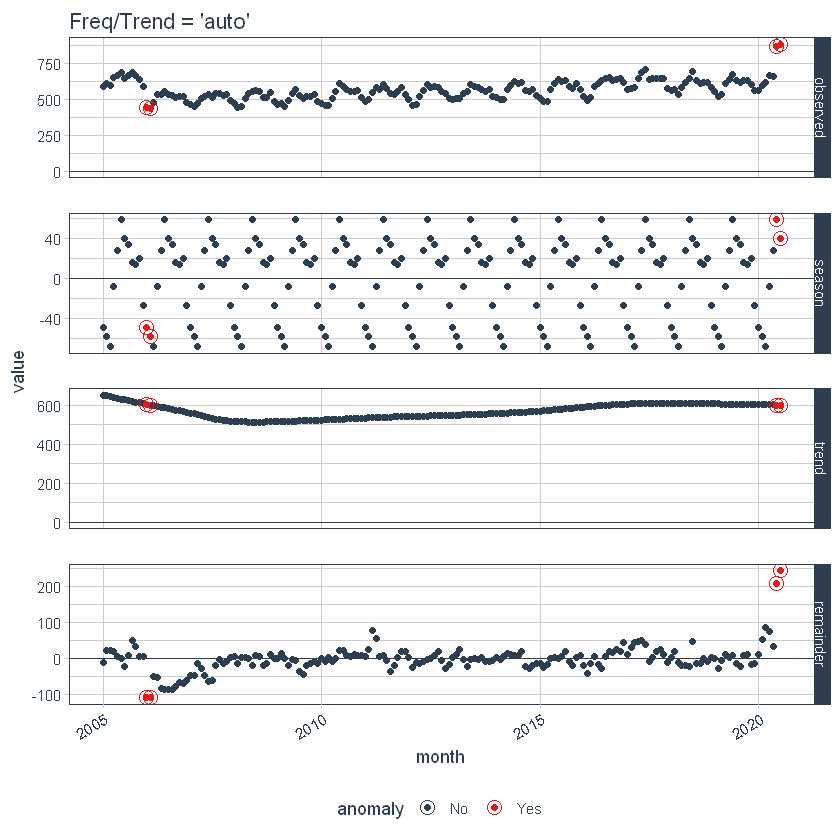
Quando é usado “auto”, get_time_scale_template () é usado para determinar frequência lógica e intervalos de tendência com base na escala dos dados. Você pode descobrir a lógica:
get_time_scale_template()

Isso implica que se a escala é 1 dia (o que significa que a diferença entre cada ponto de dados é 1 dia), então a frequência será 7 dias (o 1 semana) ea tendência será em torno de 90 dias (o 3 meses). Essa lógica pode ser facilmente ajustada de duas maneiras: configuração do parâmetro local e configuração de parâmetros globais.
Ajustando parâmetros locais
O ajuste do parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... é feito ajustando os parâmetros de acordo com. A seguir, ajustamos a tendência = “2 semanas”, o que o torna uma tendência bastante superequipada.
p2 <- df %>%
time_decompose(geral,
frequência = "auto",
tendência = "2 semanas") %>%
anomalizar(restante) %>%
plot_anomaly_decomposition() +
ggtitle("Tendência = 2 Semanas (Local)")
# Show plots
p1
p2
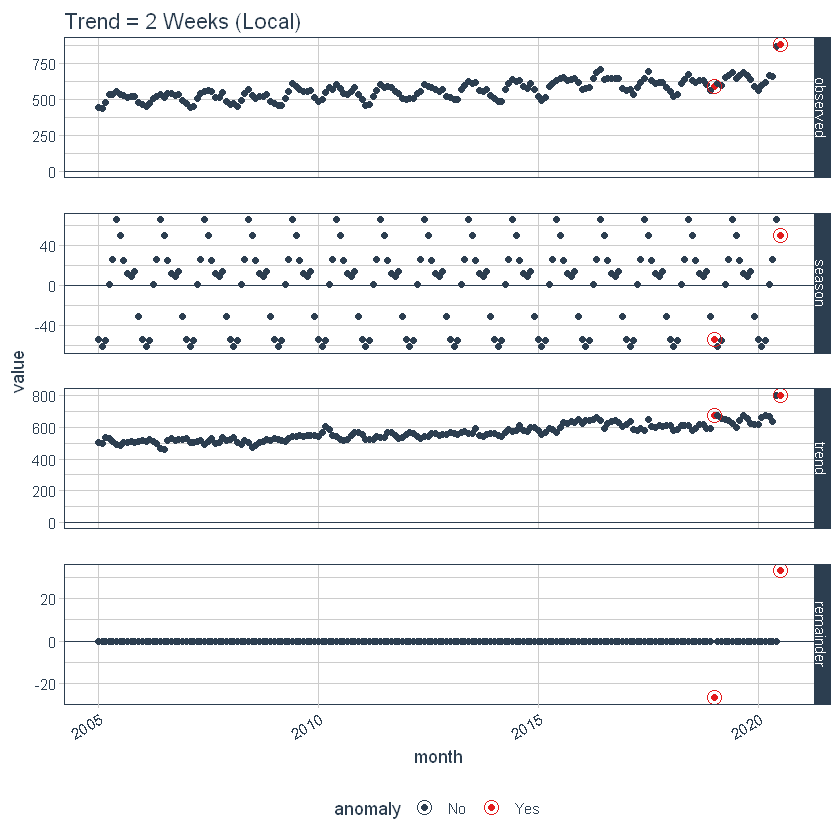
Definindo o parâmetro global
Também podemos ajustar globalmente usando set_time_scale_template () para atualizar o modelo padrão para um de nossa preferência. Vamos mudar a tendência de “3 meses” uma “2 semanas” para a escala de tempo = “dia”. Usar time_scale_template () para recuperar o modelo de cronograma com o qual a anomalia começa, mudo () o campo de tendência no local desejado e use set_time_scale_template () para atualizar o modelo nas opções globais. Podemos recuperar o modelo atualizado usando get_time_scale_template () para verificar se a mudança foi executada corretamente.
time_scale_template() %>%
mutação(tendência = ifelse(time_scale == "dia", "2 semanas", tendência)) %>%
set_time_scale_template()
get_time_scale_template()

Finalmente, podemos reexecutar o time_decompose () com valores padrão, e podemos ver que a tendência é "2 semanas".
p3 <- df %>%
time_decompose(geral) %>%
anomalizar(restante) %>%
plot_anomaly_decomposition() +
ggtitle("Tendência = 2 Semanas (Global)")
p3
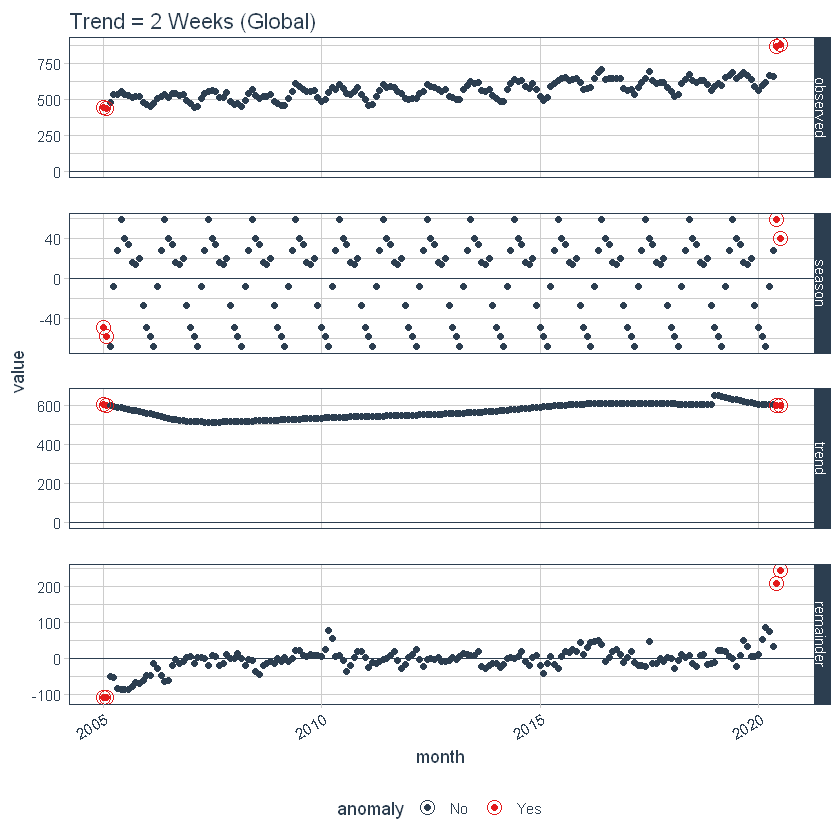
Vamos redefinir os padrões do modelo de cronograma para os padrões originais.
time_scale_template() %>%
set_time_scale_template()
# Verify the change
get_time_scale_template()

Extrair os pontos de dados anômalos
Agora, podemos extrair os pontos de dados reais que são anomalias. Para isso, o seguinte código pode ser executado.
df %>% time_decompose(geral) %>% anomalizar(restante) %>% time_recompose() %>% filtro(anomalia == 'Sim')

Ajustando Alpha e Max Anoms
a alfa e max_anoms são os dois parâmetros que controlam o anomalizar () Função. H
Alfa
Podemos ajustar o alfa, que está definido para 0.05 por padrão. Por padrão, bandas só cobrem o exterior da faixa.
p4 <- df %>%
time_decompose(geral) %>%
anomalizar(restante, alfa = 0.05, max_anoms = 0.2) %>%
time_recompose() %>%
plot_anomalies(time_recomposed = TRUE) +
ggtitle("alfa = 0.05")
#> frequência = 7 days
#> tendência = 91 days
p4
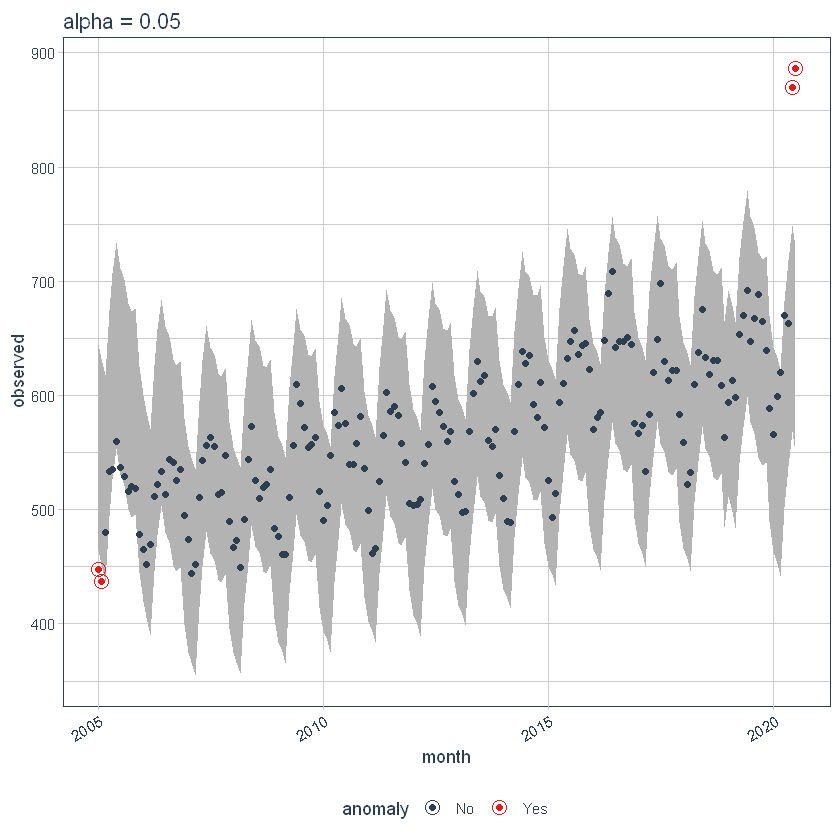
Se diminuirmos o alfa, aumenta as bandas, o que torna mais difícil ser um outlier. Aqui, você pode ver que as bandas se tornaram duas vezes maior.
p5 <- df %>%
time_decompose(geral) %>%
anomalizar(restante, alfa = 0.025, max_anoms = 0.2) %>%
time_recompose() %>%
plot_anomalies(time_recomposed = TRUE) +
ggtitle("alfa = 0.05")
#> frequência = 7 days
#> tendência = 91 days
p5
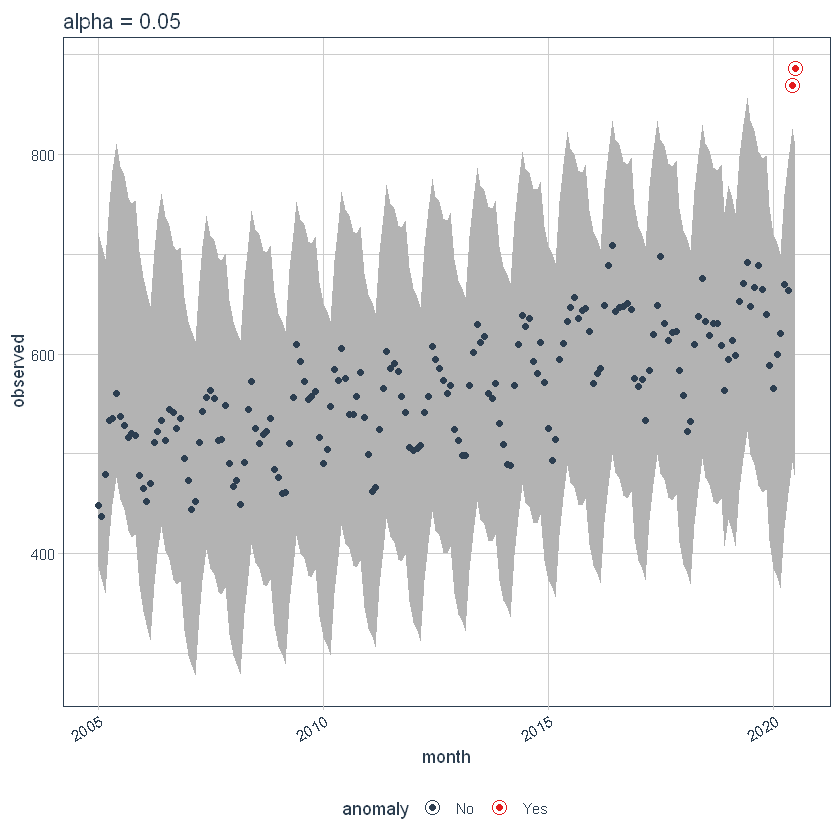
Max Anoms
a max_anoms O parâmetro é usado para controlar a porcentagem máxima de dados que podem ser uma anomalia. Vamos ajustar alfa = 0.3 de modo que praticamente qualquer coisa é um outlier. Agora vamos tentar uma comparação entre max_anoms = 0.2 (20% de anomalias permitidas) e max_anoms = 0.05 (5% de anomalias permitidas).
p6 <- df %>%
time_decompose(geral) %>%
anomalizar(restante, alfa = 0.3, max_anoms = 0.2) %>%
time_recompose() %>%
plot_anomalies(time_recomposed = TRUE) +
ggtitle("20% Anomalias")
#> frequência = 7 days
#> tendência = 91 days
p7 <- df %>%
time_decompose(geral) %>%
anomalizar(restante, alfa = 0.3, max_anoms = 0.05) %>%
time_recompose() %>%
plot_anomalies(time_recomposed = TRUE) +
ggtitle("5% Anomalias")
#> frequência = 7 days
#> tendência = 91 days
p6
p7
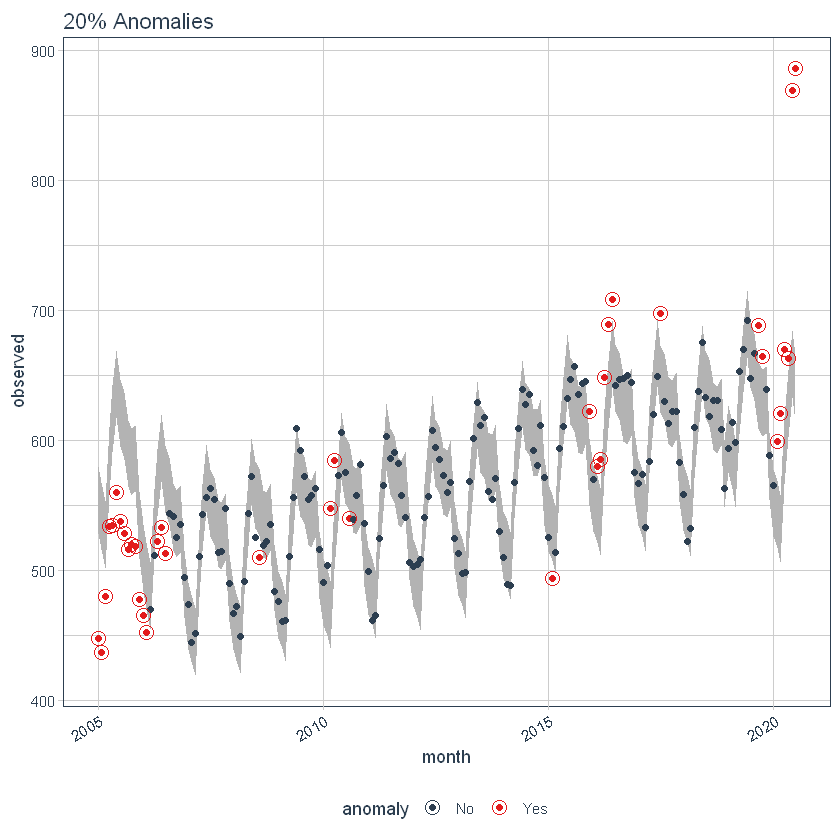
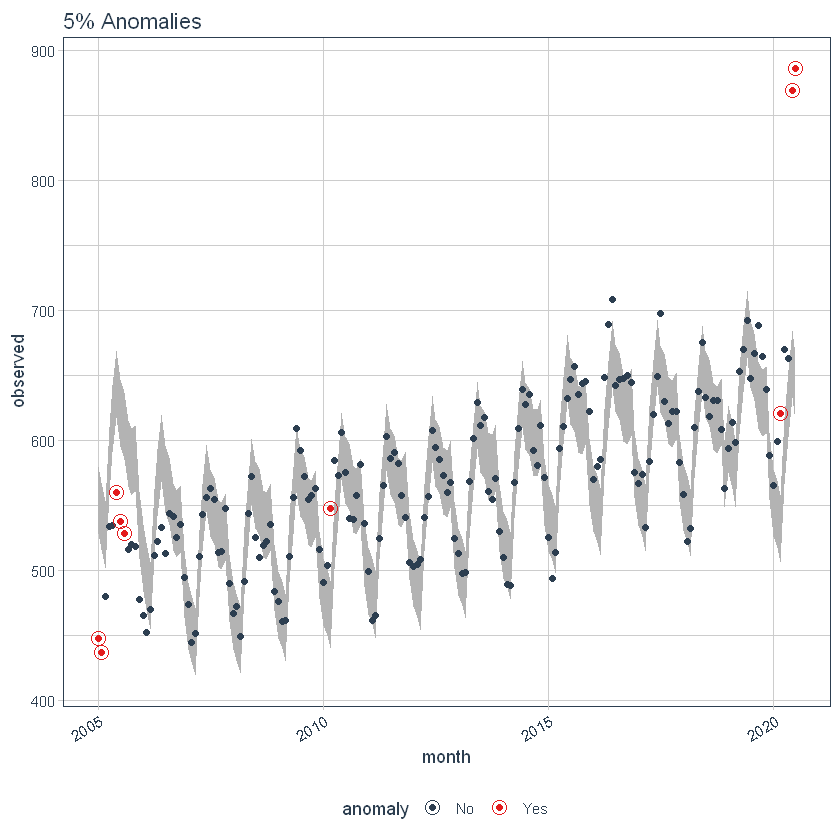
Usando o pacote 'timetk'’
É um kit de ferramentas para trabalhar com séries temporticais em R, para traçar, discutir e apresentar dados da série tempo do engenheiro para fazer previsões e previsões de aprendizado de máquina.
Visualização interativa de anomalias
Aqui, timetk A função plot_anomaly_diagnostics () permite modificar alguns dos parâmetros na mosca.
df %>% calendário::plot_anomaly_diagnostics(mês,geral, .facet_ncol = 2)
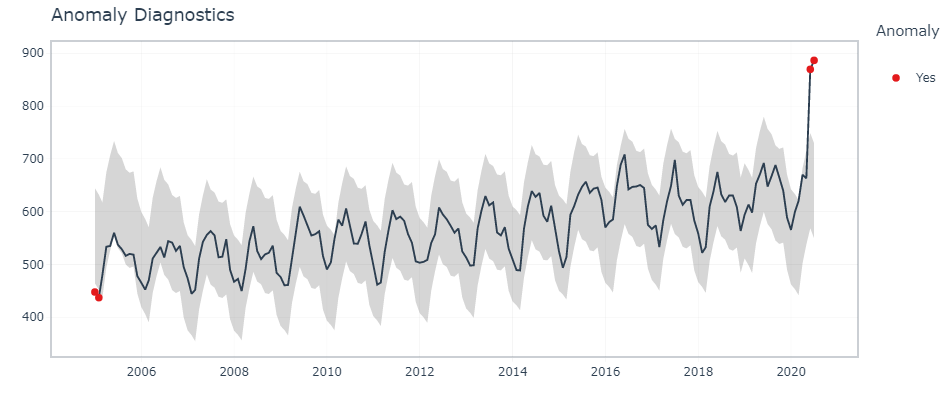
Detecção interativa de anomalias
Para encontrar os pontos de dados exatos que são anomalias, nós usamos tk_anomaly_diagnostics () Função.
df %>% calendário::tk_anomaly_diagnostics(mês, geral) %>% filtro(anomalia==='Sim')

conclusão
Neste artigo, vimos alguns dos pacotes populares em R que podem ser usados para identificar e visualizar anomalias em uma série temporal. Para fornecer alguma clareza sobre as técnicas de detecção de anomalias em R, fizemos um estudo de caso em um conjunto de dados disponível publicamente. Existem outros métodos para detectar outliers e também podem ser explorados.





