Este artigo foi publicado como parte do Data Science Blogathon
A criação de reconhecimento facial é considerada uma tarefa muito fácil no campo da visão computacional., mas é extremamente difícil ter um pipeline que possa prever faces com fundos complexos quando você tem múltiplas faces, diferentes condições de iluminação e diferentes escalas de imagem. Este blog irá descrever como criamos um modelo que pode superar os humanos em alguns casos. Nosso conjunto de dados consiste em 3 aulas (Não posso compartilhar os dados devido a questões de confidencialidade, mas vou te mostrar como fica). A aula 1 é Jesse Eisenberg (ator), a aula 2 é Mila Kunis (pop star) e a classe 0, qualquer um. É assim que nosso trem se parecia (80 imagens) e dados de teste (mais de 1800 imagens).
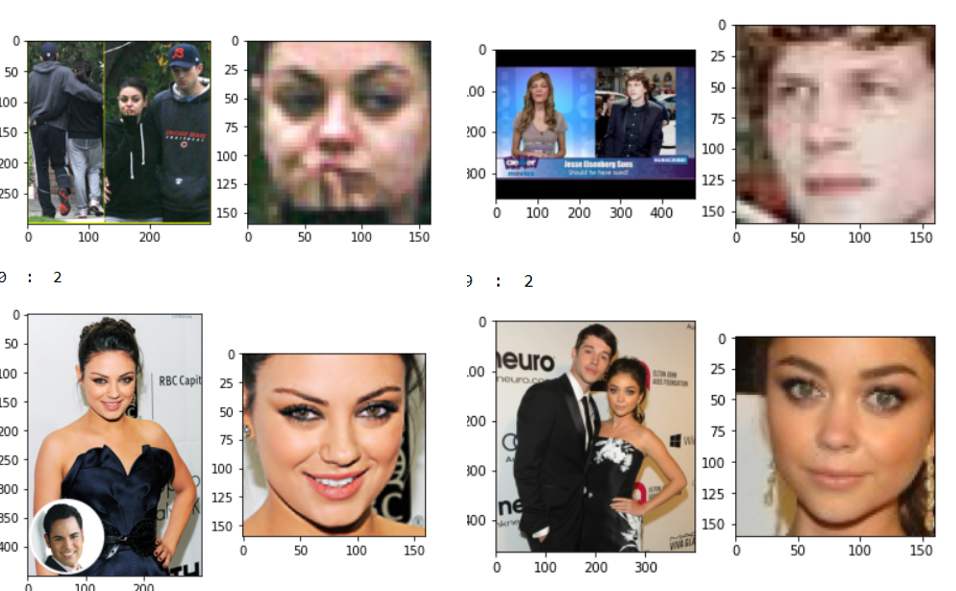
Estes são os nossos dados de teste e as faces extraídas dessas imagens, estes dados são extremamente complexos devido a múltiplas faces, fundos complexos e muitas imagens pixeladas. Por outro lado, nossos dados de trem são extremamente limpos, conforme mostrado na imagem abaixo. Temos muitas diferenças na distribuição dos dados de teste e treinamento. Precisamos de uma técnica que possa generalizar bem, independentemente de quantas amostras você precisa e quão diferentes são os dados de trem e teste.

A técnica que vamos usar para esta tarefa é, em primeiro lugar, gere a tonalidade facial a partir de um modelo de aprendizado profundo e, em seguida, aplique um classificador simples.
Usando FACENET
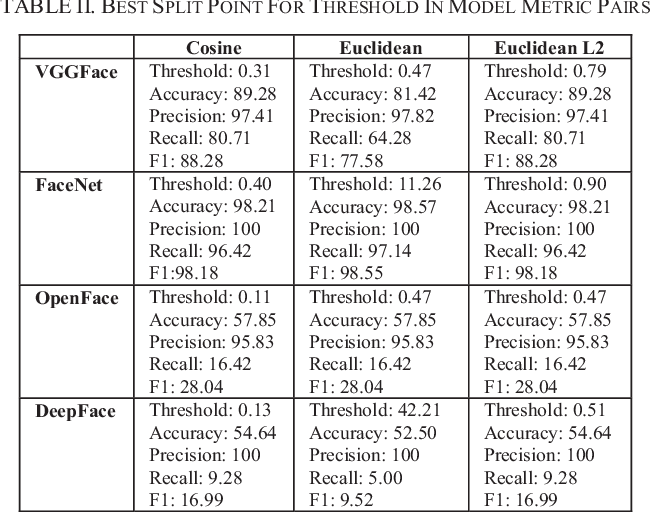
Para realmente ultrapassar os limites da detecção de rosto, veremos alguns métodos de ponta. Técnicas modernas de extração de rosto fizeram uso de redes de convolução profunda. Como todos sabemos, os recursos criados por estruturas de aprendizado profundo modernas são, na verdade, melhores do que a maioria dos recursos feitos à mão. Verificamos 4 modelos de aprendizagem profunda, a saber, FaceNet (Google), DeepFace (Facebook), VGGFace (Oxford) e OpenFace (CMU). Destes 4 Modelos FaceNet estava nos dando o melhor resultado. Em geral, FaceNet oferece melhores resultados que os outros 3 Modelos.
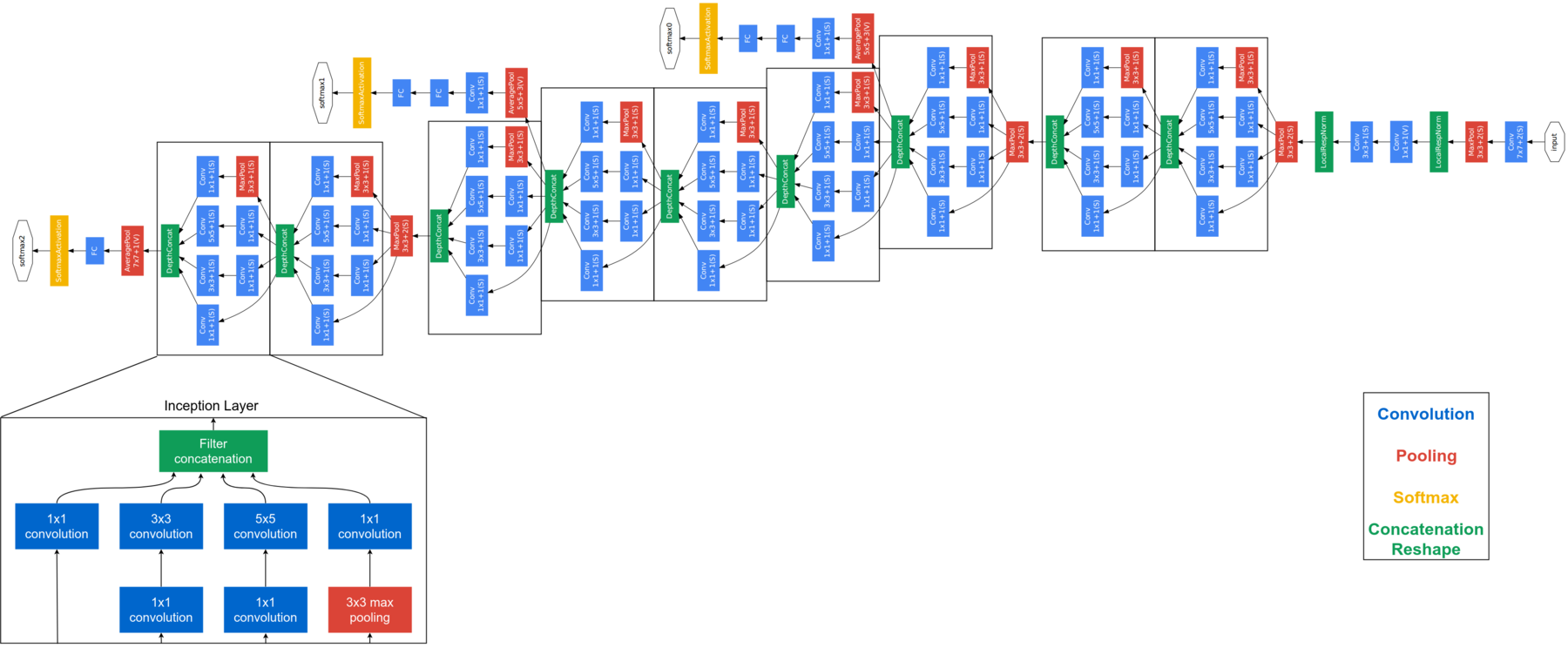
FaceNet é considerado um modelo de última geração desenvolvido pelo Google. Baseia-se na camada inicial, explicar a arquitetura completa do FaceNet está além do escopo deste blog. Abaixo está a arquitetura FaceNet. FaceNet usa módulos de início de bloco para reduzir o número de parâmetros treináveis. Este modelo obtém imagens RGB de 160 × 160 e gera um embed de tamanho 128 para uma foto. Para esta implementação, vamos precisar de algumas funções adicionais. Pero antes de enviar la imagen de la cara a FaceNet, necesitamos extraer las caras de las imágenes.
detector = dlib.cnn_face_detection_model_v1("../input/pretrained-models-faces/mmod_human_face_detector.dat") def rect_to_bb(rect): # take a bounding predicted by dlib and convert it # to the format (x, e, C, h) as we would normally do # with OpenCV x = rect.rect.left() y = rect.rect.top() w = rect.rect.right() - x h = rect.rect.bottom() - e # return a tuple of (x, e, C, h) Retorna (x, e, C, h) def dlib_corrected(dados, data_type="Comboio"): #We set the size of the image dim = (160, 160) data_images=[] #If we are processing training data we need to keep track of the labels if data_type=='train': data_labels=[] #Loop over all images for cnt in range(0,len(dados)): image = data['img'][cnt] #The large images are resized if image.shape[0] > 1000 and image.shape[1] > 1000: image = cv2.resize(imagem, (1000,1000), interpolação = cv2.INTER_AREA) #The image is converted to grey-scales gray = cv2.cvtColor(imagem, cv2.COLOR_BGR2GRAY) #Detect the faces rects = detector(cinza, 1) sub_images_data = [] #Loop over all faces in the image for (eu, rect) em enumerar(rects): #Convert the bounding box to edges (x, e, C, h) = rect_to_bb(rect) #Here we copy and crop the face out of the image clone = image.copy() E se(x>=0 and y>=0 and w>=0 and h>=0): crop_img = clone[e:y+h, x:x+w] outro: crop_img = clone.copy() #We resize the face to the correct size rgbImg = cv2.resize(crop_img, Ofuscar, interpolação = cv2.INTER_AREA) #In the test set we keep track of all faces in an image if data_type == 'train': sub_images_data = rgbImg.copy() outro: sub_images_data.append(rgbImg) #If no face is detected in the image we will add a NaN if(len(rects)== 0): if data_type == 'train': sub_images_data = np.empty(Ofuscar + (3,)) sub_images_data[:] = np.nan if data_type=='test': nan_images_data = np.empty(Ofuscar + (3,)) nan_images_data[:] = np.nan sub_images_data.append(nan_images_data) #Here we add the the image(s) to the list we will return data_images.append(sub_images_data) #And add the label to the list if data_type=='train': data_labels.append(dados['class'][cnt]) #Lastly we need to return the correct number of arrays if data_type=='train': retorno np.array(data_images), np.array(data_labels) outro: retorno np.array(data_images)
USANDO DLIB
DLIB es un modelo ampliamente utilizado para detectar rostros. En nuestros experimentos, descobrimos que dlib produz melhores resultados do que HAAR, embora notemos que algumas melhorias ainda podem ser feitas:
- Se os limites da face do retângulo forem movidos para fora da imagem, pegamos a imagem inteira em vez do recorte do rosto. É implementado da seguinte forma:
- e (x> = 0 e e> = 0 y w> = 0 y h> = 0):
- crop_img = clon[e:y+h, x:x+w]
- o resto:
- e (x> = 0 e e> = 0 y w> = 0 y h> = 0):
- Para imagens de teste, em vez de salvar um rosto por imagem, nós salvamos todos os rostos para previsão.
- Em vez de um detector baseado em HOG, podemos usar um detector baseado na CNN. Como esses aprimoramentos são projetados para otimizar seu uso com FaceNet, vamos definir uma nova detecção de rosto corrigida.
O bloco de código acima extrai os rostos da imagem, para muitas imagens temos vários rostos, então devemos colocar todos esses rostos em uma lista. Para extrair os rostos que estamos usando dlib.cnn_face_detection_model_v1, observe que você não deve alimentar imagens de dimensões muito grandes para este, caso contrário, você obterá um erro de memória dlib. Se uma imagem não tiver rosto, armazena NaN nesses lugares. Vamos FaceNet essas imagens de dados agora. O pré-processamento acima é necessário apenas para dados de teste, os dados do trem já estão limpos, o que pode ser visto nas fotos acima. Assim que terminarmos de obter as inscrições de rosto dos dados do trem, obter inscrições de rosto para dados de teste, pero primero debe usar el preprocesamiento proporcionado en el bloque de código anterior para extraer caras de los datos de prueba.
def get_embedding(modelo, face_pixels): # scale pixel values face_pixels = face_pixels.astype('float32') # standardize pixel values across channels (global) quer dizer, std = face_pixels.mean(), face_pixels.std() face_pixels = (face_pixels - quer dizer) / std # transform face into one sample samples = expand_dims(face_pixels, eixo = 0) # make prediction to get embedding yhat = model.predict(amostras) return yhat[0] modelo = load_model('../input/pretrained-models-faces/facenet_keras.h5') svmtrainX = [] para índice, face_pixels em enumerar(newTrainX): embedding = get_embedding(modelo, face_pixels) svmtrainX.append(incorporação)
Depois de gerar os inlays para treinamento e teste, vamos usar SVM para classificação. Por que SVM, Você pode perguntar? Com muita experiencia, Eu descobri que as funções baseadas em SVM + DL pode superar qualquer outro método, até mesmo métodos de aprendizagem profunda, quando a quantidade de dados é pequena.
from sklearn.svm import SVC from sklearn.pipeline import make_pipeline from sklearn.naive_bayes import GaussianNB from sklearn.neural_network import MLPClassifier from sklearn.preprocessing import StandardScaler, MinMaxScaler, Normalizer linear_model = make_pipeline(StandardScaler(), SVC(kernel="rbf", C=1,0, gamma=0.01, probability =True)) linear_model.fit(svmtrainX, svmtrainY)
Una vez que el SVM está entrenado, es hora de hacer algunas pruebas, pero nuestros datos de prueba tienen varias caras en una lista. Então, siempre que tengamos a Jesse o Mila en una imagen, ignoraremos la clase 0 y cuando tanto Jesse como Mila estén presentes en una imagen, entonces elegiremos la que nos brinde la mayor precisión.
predicitons=[] for i in corrected_test_X: flag=0 if(len(eu)== 1): embedding = get_embedding(modelo, eu[0]) tmp_output = linear_model.predict([incorporação]) predicitons.append(tmp_output[0]) outro: tmp_sub_pred = [] tmp_sub_prob = [] for j in i: j= j.astype(int) embedding = get_embedding(modelo, j) tmp_output = linear_model.predict([incorporação]) tmp_sub_pred.append(tmp_output[0]) tmp_output_prob = linear_model.predict_log_proba([incorporação]) tmp_sub_prob.append(np.max(tmp_output_prob[0])) E se 1 in tmp_sub_pred and 2 in tmp_sub_pred: index_1 = np.where(np.array(tmp_sub_pred)== 1)[0][0] index_2 = np.where(np.array(tmp_sub_pred)== 2)[0][0] E se(tmp_sub_prob[index_1] > tmp_sub_prob[index_2] ): predicitons.append(1) outro: predicitons.append(2) elif 1 não em tmp_sub_pred e 2 não em tmp_sub_pred: predicitons.append(0) elif 1 in tmp_sub_pred and 2 não em tmp_sub_pred: predicitons.append(1) elif 1 não em tmp_sub_pred e 2 in tmp_sub_pred: predicitons.append(2)
DISCUSSÃO
Considerações finais, este é um conjunto de dados muito pequeno, então os resultados podem mudar enormemente, mesmo ao adicionar ou remover algumas imagens. Em nosso teste, descobrimos que ele nos traiu muitas vezes, havia por aí 20 imagens no teste que foram previstas incorretamente por nós, mas corretamente por nosso modelo. Confirmamos o resultado esperado pesquisando essas imagens no Google.
Redes neurais profundas podem extrair recursos mais significativos do que modelos de aprendizado de máquina. Porém, a queda dessas grandes redes é a necessidade de uma grande quantidade de dados. Conseguimos lidar com este problema usando um modelo previamente treinado, um modelo que foi treinado em um conjunto de dados muito maior para reter o conhecimento de como codificar imagens faciais, que então usamos para nossos propósitos neste desafio. O que mais, O ajuste fino do SVM realmente nos ajudou a ir além da precisão do 95%.





