Visão geral
- Abordagem passo a passo para realizar EDA
- Recursos como blogs, MOOCS para se familiarizar com EDA
- Familiarize-se com as várias técnicas de visualização de dados, gráficos e diagramas.
- Demonstração de algumas etapas com o snippet de código Python
O que diferencia um profissional de ciência de dados de outro?
Não é aprendizado de máquina, não é aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde..., não é SQL, é a análise exploratória de dados (EDA). Quão bom é alguém em identificar padrões / Tendências de dados ocultos e o valor dos insights que você obtém, é o que diferencia os profissionais de dados.

1. O que é análise exploratória de dados?
A análise exploratória de dados é uma abordagem para analisar conjuntos de dados para resumir suas características principais, frequentemente usando gráficos estatísticos e outros métodos de visualização de dados.
EDA ajuda os profissionais de ciência de dados de várias maneiras: –
1 Obtenha uma melhor compreensão dos dados
2 Identifique vários padrões de dados
3 Compreender melhor a declaração do problema
[ Observação: a conjunto de dadosuma "conjunto de dados" ou conjunto de dados é uma coleção estruturada de informações, que pode ser usado para análise estatística, Aprendizado de máquina ou pesquisa. Os conjuntos de dados podem incluir variáveis numéricas, categórico ou textual, e sua qualidade é crucial para resultados confiáveis. Seu uso se estende a várias disciplinas, como remédio, Economia e Ciências Sociais, facilitando a tomada de decisão informada e o desenvolvimento de modelos preditivos.... in this blog is being opted as iris dataset]
2. Verificando os detalhes introdutórios sobre os dados
A primeira e mais importante etapa de qualquer análise de dados, depois de carregar o arquivo de dados, deve consistir em verificar alguns detalhes introdutórios. O que, não. De colunas, não. de linhas, tipos de recursos (categóricas o numéricas), tipos de dados de entrada de coluna.
Snippet de código Python
data.info ()
RangeIndex: 150 ingressos, 0 uma 149
Colunas de dados (5 colunas no total):
# Coluna de tipo de contagem não nula
– —— ————– —–
0 sepal_length 150 não nulo float64
1 sepal_width 150 float64 não nulo
2 petal_length 150 não nulo float64
3 petal_width 150 não nulo float64
4 espécies 150 objeto não nulo
dtypes: float64 (4), objeto (1)
uso de memória: 6.0+ KB
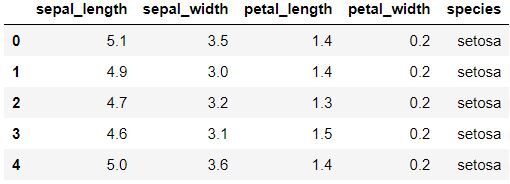
data.head () Para exibir as primeiras cinco linhas
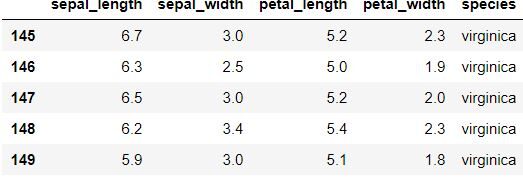
data.tail () para mostrar as últimas cinco linhas
3. Perspectiva estatística
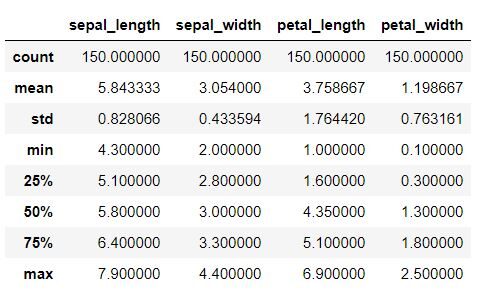
Esta etapa deve ser realizada para obter detalhes sobre vários dados estatísticos como a média, Desvio padrão, medianaA mediana é uma medida estatística que representa o valor central de um conjunto de dados ordenados. Para calculá-lo, Os dados são organizados do menor para o maior e o número no meio é identificado. Se houver um número par de observações, Os dois valores principais são calculados em média. Este indicador é especialmente útil em distribuições assimétricas, uma vez que não é afetado por valores extremos...., valor máximo, valor minimo.
Snippet de código Python
data.describe ()
4. Limpeza de dados
Esta é a etapa mais importante no EDA, que envolve a exclusão de linhas / colunas duplicadas, preencha entradas vazias com valores como média / mediana de dados, remover vários valores, remover entradas nulas
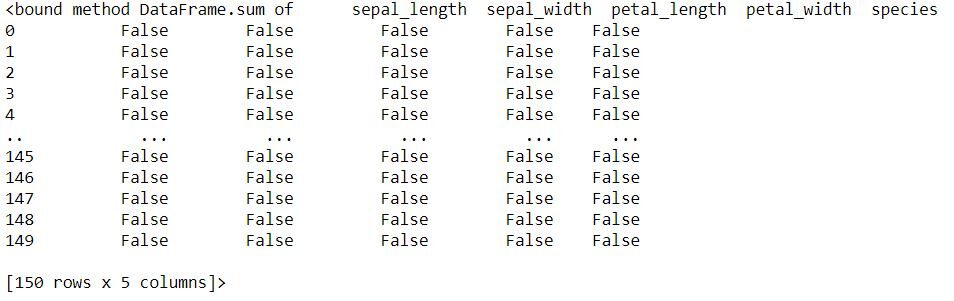
Verificando entradas nulas
Snippet de código Python
data.IsNull (). sum da el número de valores perdidos para cada variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos....
Remover entradas nulas
Snippet de código Python
data.dropna (eixo = 0, inplace = True) Se houver entradas nulas
Preencha os valores em vez de entradas nulas (se é uma função numérica)
Os valores podem ser a média, a mediana ou qualquer número inteiro
Snippet de código Python
dados[“Sepal_length”].Fillna (valor = dados[“Sepal_length”].quer dizer (), inplace = True) se houver uma entrada nula
Verificando duplicatas
Snippet de código Python
data.duplicated (). soma () retorna o número total de entradas duplicadas
Remover duplicatas
Snippet de código Python
data.drop_duplicates (inplace = True)
5. Visualização de dados
A visualização de dados é o método de conversão de dados brutos em uma forma visual, como um mapa ou gráfico, para tornar os dados mais fáceis de entender e extrair informações úteis..
O principal objetivo da visualização de dados é colocar grandes conjuntos de dados em uma representação visual. É uma das etapas importantes e fáceis quando se trata de ciência de dados.
Você pode verificar o blog abaixo para obter mais detalhes sobre visualização de dados.
Vários tipos de análise de visualização são:
uma. Análise univariada:
Isso mostra cada observação / distribuição de dados em uma única variável de dados.. Se puede mostrar con la ayuda de varios diagramas como Diagrama de dispersãoO gráfico de dispersão é uma ferramenta gráfica usada em estatística para visualizar a relação entre duas variáveis. Consiste em um conjunto de pontos em um plano cartesiano, onde cada ponto representa um par de valores correspondentes às variáveis analisadas. Este tipo de gráfico permite identificar padrões, Tendências e possíveis correlações, facilitando a interpretação dos dados e a tomada de decisão com base nas informações visuais apresentadas...., diagrama de linha, diagrama de histograma (resumo), plotagens de caixaDiagramas de caixa, Também conhecido como diagramas de caixa e bigode, são ferramentas estatísticas que representam a distribuição de um conjunto de dados. Esses diagramas mostram a mediana, Quartis e outliers, permitindo que a variabilidade e a simetria dos dados sejam visualizadas. Eles são úteis na comparação entre diferentes grupos e na análise exploratória, facilitando a identificação de tendências e padrões nos dados...., diagrama de violinoO diagrama de violino é uma representação gráfica que combina características de um boxplot e um gráfico de densidade. Usado para visualizar a distribuição de um conjunto de dados, mostrando a mediana e a variabilidade através de sua forma, que se assemelha a um violino. Este tipo de gráfico é muito útil na análise estatística, ya que permite comparar múltiples distribuciones de forma clara y efectiva...., etc.
B. Análise bi-variável:
Telas de análise bivariada são realizadas para revelar a relação entre duas variáveis de dados. Também pode ser mostrado com a ajuda de diagramas de dispersão, histogramasHistogramas são representações gráficas que mostram a distribuição de um conjunto de dados. Eles são construídos dividindo o intervalo de valores em intervalos, o "Caixas", e contando quantos dados caem em cada intervalo. Essa visualização permite identificar padrões, tendências e variabilidade de dados de forma eficaz, facilitando a análise estatística e a tomada de decisões informadas em várias disciplinas...., mapas de calor, plotagens de caixa, diagramas de violino, etc.
C. Analisis multivariável:
Análise multivariada, como o nome sugere, são exibidos para revelar a relação entre mais de duas variáveis de dados.
Diagramas de dispersão, histogramas, plotagens de caixa, diagramas de violino podem ser usados para análise multivariada
Plotagens múltiplas
Abaixo estão alguns dos gráficos que podem ser implementados para análise univariada, bivariada e multivariada
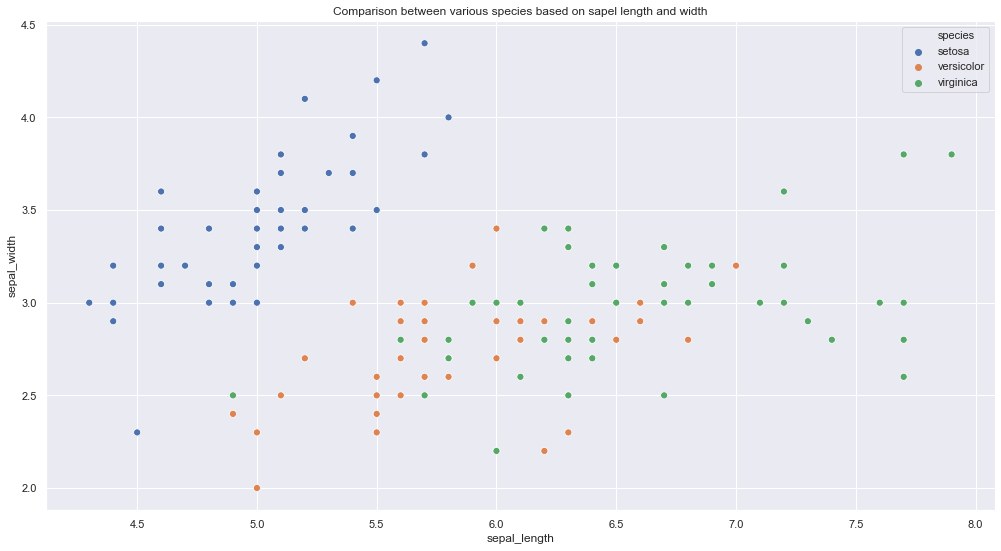
uma. Gráfico de dispersãoUm gráfico de dispersão é uma representação visual que mostra a relação entre duas variáveis numéricas usando pontos em um plano cartesiano. Cada eixo representa uma variável, e a localização de cada ponto indica seu valor em relação a ambos. Esse tipo de gráfico é útil para identificar padrões, Correlações e tendências nos dados, facilitando a análise e interpretação de relações quantitativas....
Snippet de código Python
plt.figure (figsize = (17,9))
plt.title (‘Comparação entre várias espécies de acordo com o comprimento e largura do sapel’)
sns.scatterplot (dados[‘Sepal_length’],dados[‘Sepal_width’], tom = dados['espécies'], s = 50)
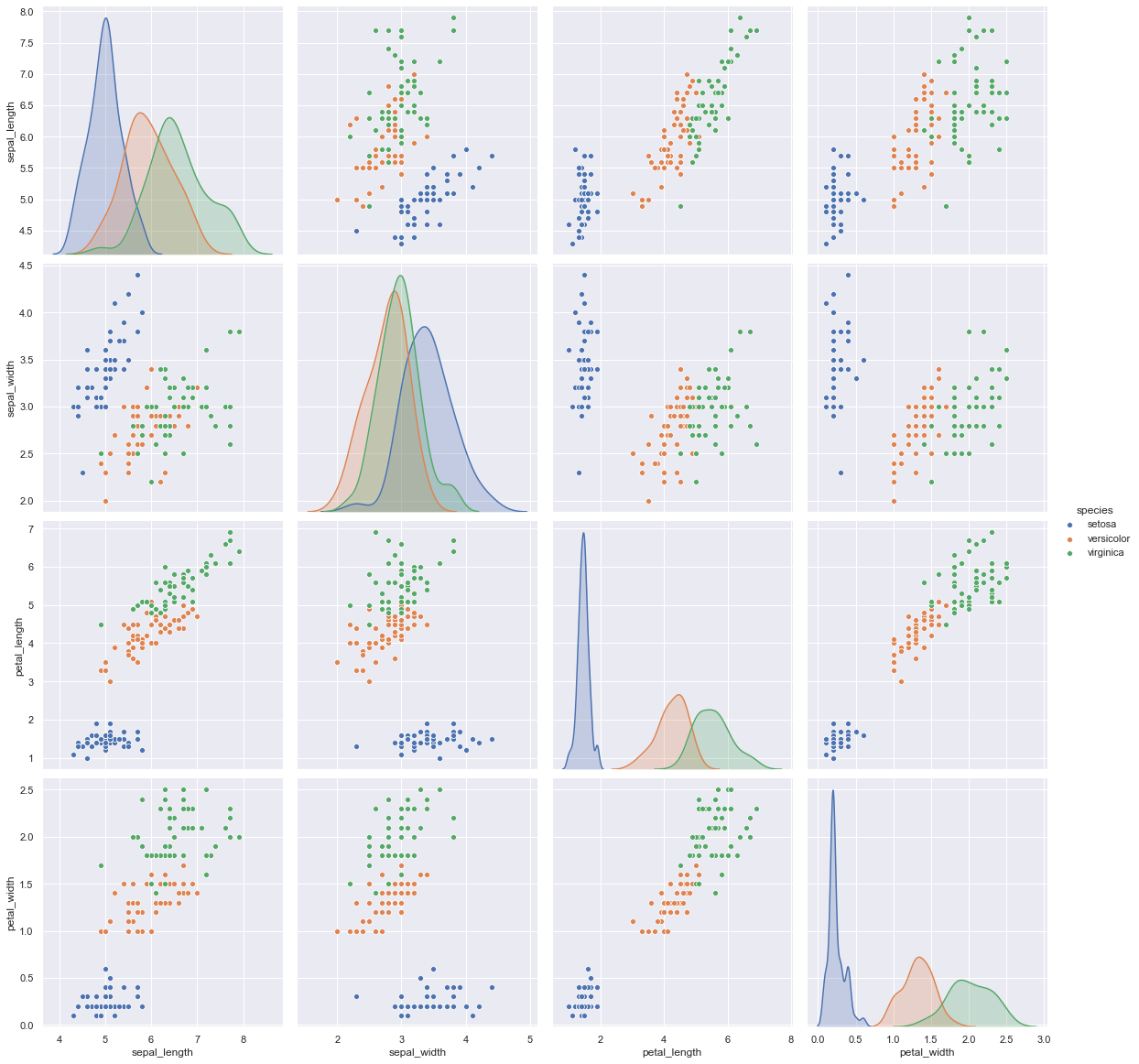
Para análise multivariada
Snippet de código Python
sns.pairplot (dados, matiz = "espécie", altura = 4)
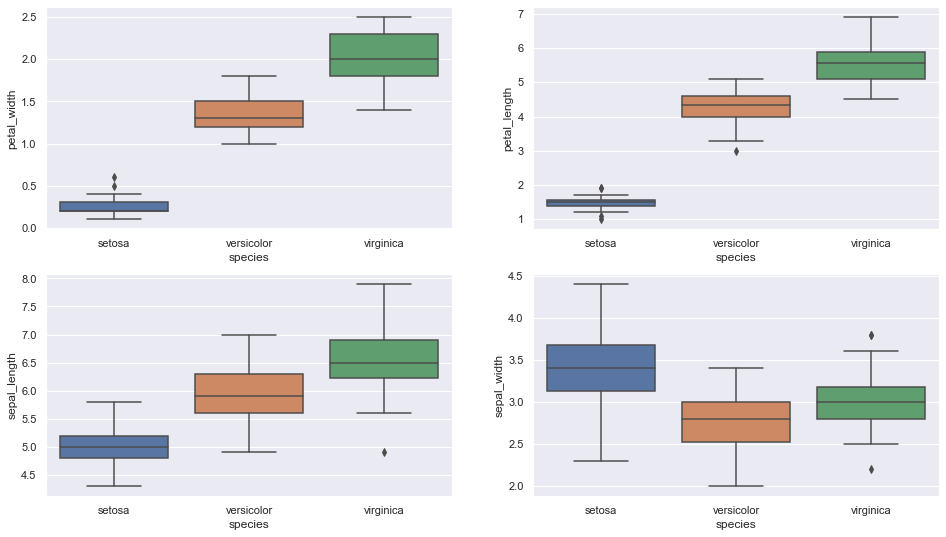
B. Box plot
Gráfico de caixa para ver como a característica categórica é distribuída “Espécies” com as outras quatro variáveis de entrada
Snippet de código Python
FIG, axes = plt.subplots (2, 2, figsize = (16,9))
sns.boxplot (y = “petal_width”, x = “espécies”, data = iris_data, orient = ‘v’, ax = axes[0, 0])
sns.boxplot (y = “petal_length”, x = “espécies”, data = iris_data, orient = ‘v’, ax = axes[0, 1])
sns.boxplot (y = ”sepal_length”, x = "espécie", data = iris_data, orient = ‘v’, ax = axes[1, 0])
sns.boxplot (y = “sepal_width”, x = “espécies”, data = iris_data, orient = ‘v’, ax = ejes[1, 1])
plt.show ()
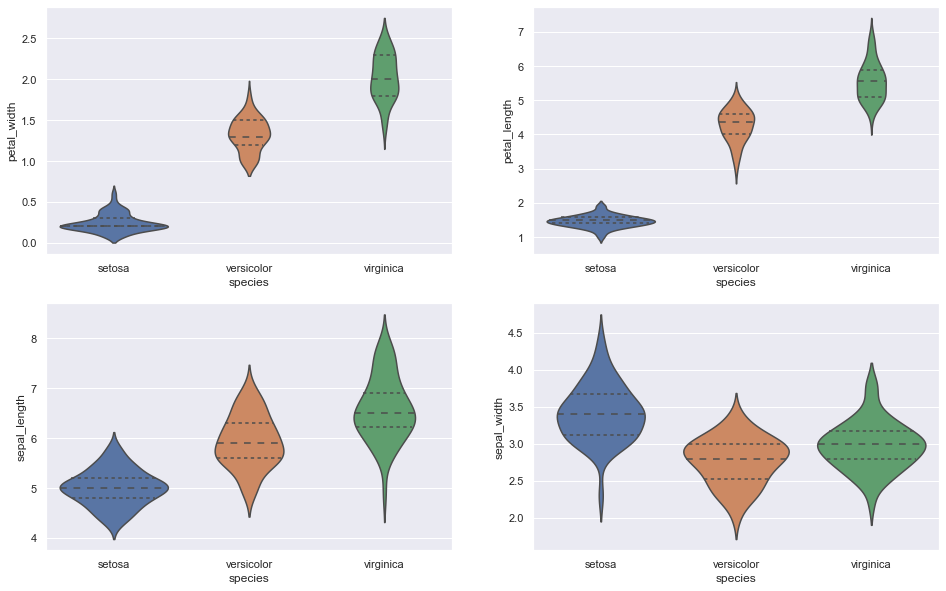
C. Moldura de violino
Mais informativo do que o gráfico de caixa e mostra a distribuição completa dos dados.
Snippet de código Python
FIG, axes = plt.subplots (2, 2, figsize = (16,10))
sns.violinplot (y = ”petal_width”, x = "espécie", data = iris_data, orient = ‘v’, ax = axes[0, 0], interno = ‘quartil’)
sns.violinplot (y = “petal_length”, x = “espécies”, data = iris_data, orient = ‘v’, ax = ejes[0, 1], interno = ‘quartil’)
sns.violinplot (y = ”sepal_length”, x = "espécie", data = iris_data, orient = ‘v’, ax = axes[1, 0], interno = ‘quartil’)
sns.violinplot (y = ”sepal_width”, x = "espécie", data = iris_data, orient = ‘v’, ax = axes[1, 1], interno = ‘quartil’)
plt.show ()
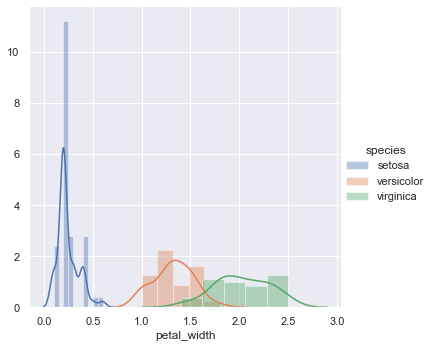
D. Histogramas
Pode ser usado para visualizar a função de densidade de probabilidade (PDF)
Snippet de código Python
sns.FacetGrid (iris_data, matiz = "espécie", altura = 5)
.mapa (sns.distplot, “petal_width”)
.add_legend ();
Com isso eu termino este blog.
Olá a todos, Namaste
Chamo-me Pranshu Sharma e eu sou um entusiasta da ciência de dados
Muito obrigado por dedicar seu valioso tempo para ler este blog.. Sinta-se à vontade para apontar quaisquer erros (depois de tudo, eu sou um aprendiz) e fornecer os comentários correspondentes ou deixar um comentário.
Dhanyvaad !!
Comentários:
Correio eletrônico: [e-mail protegido]
Você pode consultar o blog mencionado abaixo para se familiarizar com a análise exploratória de dados.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





