Visão geral
- Hadoop está entre as ferramentas mais populares na área de engenharia de dados e Big Data
- Aqui está uma introdução a tudo que você precisa saber sobre o ecossistema Hadoop.
Introdução
Na atualidade, nós temos mais que 4 1 bilhão de usuários da Internet. Em termos de dados brutos, é assim que a imagem se parece:
9.176 Tweets por segundo
1.023 Imagens do Instagram enviadas por segundo
5.036 Chamadas Skype por segundo
86,497 Pesquisas do Google por segundo
86,302 Vídeos do YouTube vistos por segundo
2.957.983 Emails enviados por segundo
e muito mais…
Essa é a quantidade de dados com que estamos lidando no momento: surpreendente! Estima-se que no final de 2020 terá produzido 44 zetabytes de dados. Isso é 44 * 10 ^ 21!
Essa enorme quantidade de dados gerados a uma taxa feroz e em todos os tipos de formatos é o que hoje chamamos de Big Data. Mas não é viável armazenar esses dados em sistemas tradicionais que temos usado por mais de 40 anos. Para lidar com esse big data, precisamos de uma estrutura muito mais complexa que consiste não apenas em um, mas em vários componentes que lidam com diferentes operações.

Nos referimos a esta estrutura como Hadoop e junto com todos os seus componentes, ligar Ecossistema HadoopO ecossistema Hadoop é uma estrutura de código aberto projetada para processar e armazenar grandes volumes de dados. É composto por vários componentes-chave, como Sistema de Arquivos Distribuído do Hadoop (HDFS) para armazenamento e MapReduce para processamento. O que mais, inclui ferramentas complementares, como o Hive, Porco e HBase, que facilitam a gestão, Análise e consulta de dados. Este ecossistema é fundamental no campo do Big Data e do Big Data... Mas porque existem tantos componentes dentro deste ecossistema Hadoop, às vezes pode ser realmente desafiador entender e lembrar o que cada componente faz e onde ele se encaixa neste grande mundo.
Então, neste artigo, vamos tentar entender este ecossistema e quebrar seus componentes.
Tabela de conteúdo
- Problema com sistemas tradicionais
- O que é Hadoop?
- Componentes do ecossistema Hadoop
- HDFSHDFS, o Sistema de Arquivos Distribuído Hadoop, É uma infraestrutura essencial para armazenar grandes volumes de dados. Projetado para ser executado em hardware comum, O HDFS permite a distribuição de dados em vários nós, garantindo alta disponibilidade e tolerância a falhas. Sua arquitetura é baseada em um modelo mestre-escravo, onde um nó mestre gerencia o sistema e os nós escravos armazenam os dados, facilitando o processamento eficiente de informações.. (Sistema de arquivos distribuídoUm sistema de arquivos distribuído (DFS) Permite armazenamento e acesso a dados em vários servidores, facilitando o gerenciamento de grandes volumes de informações. Esse tipo de sistema melhora a disponibilidade e a redundância, à medida que os arquivos são replicados para locais diferentes, Reduzindo o risco de perda de dados. O que mais, Permite que os usuários acessem arquivos de diferentes plataformas e dispositivos, promovendo colaboração e... Hadoop)
- Mapa pequeno
- HILO
- HBaseO HBase é um banco de dados NoSQL projetado para lidar com grandes volumes de dados distribuídos em clusters. Com base no modelo de coluna, Permite acesso rápido e dimensionável às informações. O HBase se integra facilmente ao Hadoop, tornando-o uma escolha popular para aplicativos que exigem armazenamento e processamento massivos de dados. Sua flexibilidade e capacidade de crescimento o tornam ideal para projetos de big data....
- Carne de porco
- Colmeia
- SqoopSqoop es una herramienta de código abierto diseñada para facilitar la transferencia de datos entre bases de datos relacionales y el ecosistema Hadoop. Permite la importación de datos desde sistemas como MySQL, PostgreSQL y Oracle a HDFS, así como la exportación de datos desde Hadoop a estas bases de datos. Sqoop optimiza el proceso mediante la paralelización de las operaciones, lo que lo convierte en una solución eficiente para el...
- Canal artificial
- Kafka
- Funcionário do zoológico
- Fagulha – fagulha
- Estágios do processamento de Big Data
Problema com sistemas tradicionais
Por sistemas tradicionais, Quero dizer, sistemas como bancos de dados relacionais e data warehouses. As organizações os têm usado no passado 40 anos para armazenar e analisar seus dados. Mas os dados que são gerados hoje não podem ser manipulados por esses bancos de dados pelos seguintes motivos:
- A maioria dos dados gerados hoje são semiestruturados ou não estruturados. Mas os sistemas tradicionais foram projetados para lidar apenas com dados estruturados com linhas e colunas bem projetadas.
- Bancos de dados de relacionamento são verticalmente escaláveis, o que significa que você precisa adicionar mais processamento, memória e armazenamento para o mesmo sistema. Isso pode ser muito caro
- Os dados armazenados hoje estão em diferentes silos. Coletá-los e analisá-los em busca de padrões pode ser uma tarefa muito difícil.
Então, Como lidamos com Big Data? É aí que entra o Hadoop!!
O que é Hadoop?
Os funcionários do Google também enfrentaram os desafios mencionados acima quando queriam classificar páginas na internet.. Eles descobriram que os bancos de dados relacionais são muito caros e inflexíveis. Então, surgiu com sua própria solução inovadora. Eles criaram o Sistema de arquivos do Google (GFS).
GFS é um sistema de arquivos distribuído que supera as desvantagens dos sistemas tradicionais. Funciona em hardware barato e fornece paralelização, escalabilidade e confiabilidade. Isso definiu o trampolim para a evolução de Apache Hadoop.
Apache Hadoop é uma estrutura de código aberto baseada no sistema de arquivos do Google que pode lidar com big data em um ambiente distribuído.. Este ambiente distribuído é formado por um grupo de máquinas trabalhando juntas para dar a impressão de uma única máquina em operação..
Aqui estão algumas das propriedades importantes do Hadoop que você deve conhecer:
- Hadoop é altamente escalável porque lida com os dados de forma distribuída
- Comparado com a escala vertical em RDBMS, Ofertas Hadoop escala horizontal
- Crie e salve réplicas de dados ao fazer isso tolerante a falhas
- Está econômico ya que todos los nodos del cachoUm cluster é um conjunto de empresas e organizações interconectadas que operam no mesmo setor ou área geográfica, e que colaboram para melhorar sua competitividade. Esses agrupamentos permitem o compartilhamento de recursos, Conhecimentos e tecnologias, Promover a inovação e o crescimento económico. Os clusters podem abranger uma variedade de setores, Da tecnologia à agricultura, e são fundamentais para o desenvolvimento regional e a criação de empregos.... son hardware básico que no es más que máquinas económicas
- Hadoop usa o conceito de localidade de dados para processar os dados nos nós onde estão armazenados, em vez de mover os dados pela rede, reduzindo assim o tráfego
- Poderia lidar com qualquer tipo de dados: estruturada, semi-estruturado e não estruturado. Isso é extremamente importante hoje porque a maioria de nossos dados (E-mails, Instagram, Twitter, Dispositivos IoT, etc.) não tem um formato definido.
Agora, vamos dar uma olhada nos componentes do ecossistema Hadoop.
Componentes do ecossistema Hadoop
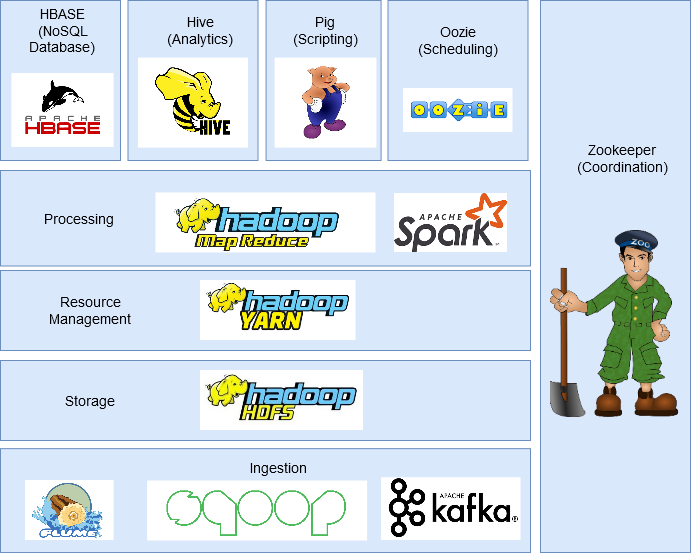
Nesta secção, discutiremos os diferentes componentes do ecossistema Hadoop.
HDFS (Sistema de arquivos distribuído Hadoop)

É o componente de armazenamento do Hadoop que armazena dados na forma de arquivos.
Cada arquivo é dividido em blocos de 128 MB (configurável) e os armazena em diferentes máquinas no cluster.
Possui uma arquitetura mestre-escravo com dois componentes principais: NodoO Nodo é uma plataforma digital que facilita a conexão entre profissionais e empresas em busca de talentos. Através de um sistema intuitivo, permite que os usuários criem perfis, Compartilhar experiências e acessar oportunidades de trabalho. Seu foco em colaboração e networking torna o Nodo uma ferramenta valiosa para quem deseja expandir sua rede profissional e encontrar projetos que se alinhem com suas habilidades e objetivos.... de nombre y Nodo de datos.
- Nó de nome é o nó principal e há apenas um por cluster. Sua tarefa é saber onde cada bloco que pertence a um arquivo está localizado no cluster.
- Nó de dados é o nodo esclavoo "nodo esclavo" es un concepto utilizado en redes y sistemas distribuidos que se refiere a un dispositivo o componente que opera bajo la dirección de un nodo principal o "nodo maestro". Este tipo de arquitectura permite una gestión centralizada, donde el nodo esclavo ejecuta tareas específicas, recopilando datos o ejecutando procesos, mientras el nodo maestro coordina las operaciones de todo el sistema para optimizar el rendimiento y la eficiencia.... que almacena los bloques de datos y hay más de uno por clúster. Sua tarefa é recuperar os dados quando necessário. Permanece em contato constante com o nó Nome por meio de pulsações.
Mapa pequeno

Para lidar com Big Data, Hadoop é baseado em Algoritmo MapReduce introduzido pelo Google e facilita a distribuição de uma tarefa e sua execução em paralelo em um cluster. Basicamente, divide uma única tarefa em várias tarefas e as processa em máquinas diferentes.
Em termos simples, trabalha de forma dividir e conquistar e executa processos em máquinas para reduzir o tráfego de rede.
Tem duas fases importantes: Mapa e menos zoom.
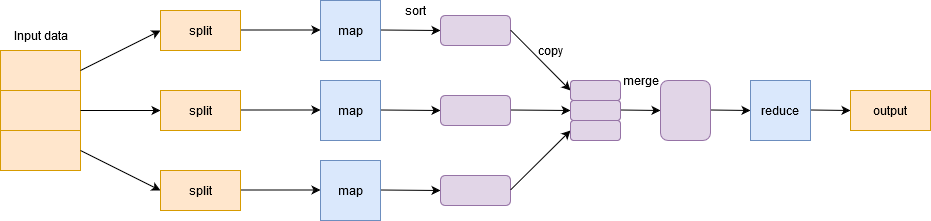
Fase cartográfica filtro, agrupar e ordenar os dados. Os dados de entrada são divididos em vários divisões. Cada tarefa de mapa funciona em uma fatia de dados paralela em máquinas diferentes e gera um par de valores-chave. A saída desta fase é acionada pelo reduzir o dever de casa e é conhecido como o Fase de redução. Adicione os dados, resume o resultado e o armazena em HDFS.
HILO

FIOYARN es un gestor de paquetes para JavaScript que permite la instalación y gestión eficiente de dependencias en proyectos de desarrollo. Desarrollado por Facebook, se caracteriza por su rapidez y seguridad en comparación con otros gestores. YARN utiliza un sistema de caché para optimizar las instalaciones y proporciona un archivo de bloqueo para garantizar la consistencia de las versiones de las dependencias en diferentes entornos de desarrollo.... o Yet Another Resource Negotiator administra los recursos en el clúster y administra las aplicaciones a través de Hadoop. Permite que os dados armazenados no HDFS sejam processados e executados por vários mecanismos de processamento de dados, como processamento em lote, processamento de fluxo, processamento interativo, processamento gráfico e muito mais. Isso aumenta a eficiência com o uso de YARN.
HBase

HBase é um Banco de dados NoSQLOs bancos de dados NoSQL são sistemas de gerenciamento de dados que se caracterizam por sua flexibilidade e escalabilidade. Ao contrário dos bancos de dados relacionais, Usar modelos de dados não estruturados, como documentos, Chave-valor ou gráficos. Eles são ideais para aplicações que exigem o manuseio de grandes volumes de informações e alta disponibilidade, como no caso de redes sociais ou serviços em nuvem. Sua popularidade cresceu em... basada en columnas. Ele roda em HDFS e pode lidar com qualquer tipo de dados. Permite processamento em tempo real e operações de leitura / gravações aleatórias realizadas nos dados.
Carne de porco

PorcoO Porco, um mamífero domesticado da família Suidae, É conhecida por sua versatilidade na agricultura e produção de alimentos. Nativo da Ásia, Sua criação se espalhou por todo o mundo. Os porcos são onívoros e têm alta capacidade de adaptação a vários habitats. O que mais, desempenham um papel importante na economia, Fornecimento de carne, couro e outros produtos derivados. Sua inteligência e comportamento social também são ... fue desarrollado para analizar grandes conjuntos de datos y supera la dificultad de escribir mapas y reducir funciones. Consta de dos componentes: Pig Latin e Pig Engine.
Pig Latin é uma linguagem de script semelhante a SQL. Pig Engine é o tempo de execução em que o Pig Latin é executado. Internamente, el código escrito en Pig se convierte en funciones de MapReduceO MapReduce é um modelo de programação projetado para processar e gerar grandes conjuntos de dados com eficiência. Desenvolvido pelo Google, Essa abordagem divide o trabalho em tarefas menores, que são distribuídos entre vários nós em um cluster. Cada nó processa sua parte e, em seguida, os resultados são combinados. Esse método permite dimensionar aplicativos e lidar com grandes volumes de informações, sendo fundamental no mundo do Big Data.... y lo hace muy fácil para los programadores que no dominan Java.
Colmeia

ColmeiaHive é uma plataforma de mídia social descentralizada que permite que seus usuários compartilhem conteúdo e se conectem com outras pessoas sem a intervenção de uma autoridade central. Usa a tecnologia blockchain para garantir a segurança e a propriedade dos dados. Ao contrário de outras redes sociais, O Hive permite que os usuários monetizem seu conteúdo por meio de recompensas criptográficas, que incentiva a criação e a troca ativa de informações .... es un sistema de almacenamiento de datos distribuido desarrollado por Facebook. Permite uma leitura fácil, escrever e gerenciar arquivos em HDFS. Ele tem sua própria linguagem de consulta para o propósito conhecido como Linguagem de Consulta Hive (HQL), que é muito semelhante ao SQL. Isso torna muito fácil para os programadores escrever funções MapReduce usando consultas HQL simples..
Sqoop

Muitos aplicativos ainda armazenam dados em bancos de dados relacionais, lo que las convierte en una Fonte de dadosUMA "Fonte de dados" refere-se a qualquer lugar ou meio onde as informações podem ser obtidas. Essas fontes podem ser primárias e, como levantamentos e experimentos, como secundário, como bancos de dados, Artigos acadêmicos ou relatórios estatísticos. A escolha certa de uma fonte de dados é crucial para garantir a validade e confiabilidade das informações em pesquisa e análise.... muito importante. Portanto, O Sqoop desempenha um papel importante em trazer dados de bancos de dados relacionais para HDFS.
Os comandos escritos no Sqoop são convertidos internamente em tarefas MapReduce executadas no HDFS. Funciona com quase todos os bancos de dados relacionais, como MySQL, Postgres, SQLite, etc. Também pode ser usado para exportar dados de HDFS para RDBMS.
Canal artificial

FlumeFlume es un software de código abierto diseñado para la recolección y transporte de datos. Utiliza un enfoque basado en flujos, lo que permite mover datos de diversas fuentes hacia sistemas de almacenamiento como Hadoop. Su arquitectura modular y escalable facilita la integración con múltiples orígenes de datos, lo que lo convierte en una herramienta valiosa para el procesamiento y análisis de grandes volúmenes de información en tiempo real.... es un servicio de código abierto, confiável e disponível que é usado para coletar, adicionar e mover com eficiência grandes quantidades de dados de várias fontes de dados para HDFS. Pode coletar dados em tempo real e em lote. Tem uma arquitetura flexível e é tolerante a falhas com vários mecanismos de recuperação.
Kafka

Existem muitos aplicativos que geram dados e um número proporcional de aplicativos que consomem esses dados. Mas conectá-los individualmente é uma tarefa difícil. É aí que entra Kafka. Está entre os aplicativos que geram dados (produtores) e aplicativos que consomem dados (consumidores).
Kafka é distribuído e particionado, replicaçãoA replicação é um processo fundamental na biologia e na ciência, que se refere à duplicação de moléculas, células ou informações genéticas. No contexto do DNA, A replicação garante que cada célula-filha receba uma cópia completa do material genético durante a divisão celular. Esse mecanismo é crucial para o crescimento, Desenvolvimento e manutenção dos organismos, bem como para a transmissão de características hereditárias nas gerações futuras.... y tolerancia a fallas incorporados. Ele pode lidar com dados de streaming e também permite que as empresas analisem dados em tempo real.
Oozie

OozieOozie es un sistema de gestión de trabajos orientado a flujos de datos, diseñado para coordinar trabajos en Hadoop. Permite a los usuarios definir y programar trabajos complejos, integrando tareas de MapReduce, Porco, Hive y otros. Oozie utiliza un enfoque basado en XML para describir los flujos de trabajo y su ejecución, facilitando la orquestación de procesos en entornos de big data. Su funcionalidad mejora la eficiencia en el procesamiento... es un sistema de programación de flujo de trabajo que permite a los usuarios vincular trabajos escritos en varias plataformas como MapReduce, Colmeia, Porco, etc. Com o Oozie, você pode agendar um trabalho com antecedência e pode criar um pipeline de trabalhos individuais para serem executados sequencialmente ou em paralelo para realizar uma tarefa maior.. Por exemplo, você pode usar o Oozie para realizar operações ETL nos dados e, em seguida, salvar a saída em HDFS.
Funcionário do zoológico

Em um cluster Hadoop, coordenar e sincronizar nós pode ser uma tarefa desafiadora. Por tanto, Funcionário do zoológico"Funcionário do zoológico" é um videogame de simulação lançado em 2001, onde os jogadores assumem o papel de um tratador. A principal missão é gerenciar e cuidar de várias espécies de animais, garantindo o seu bem-estar e a satisfação dos visitantes. Ao longo do jogo, Os usuários podem projetar e personalizar seu zoológico, enfrentando desafios, incluindo alimentos, o habitat e a saúde dos animais.... es la herramienta perfecta para resolver el problema.
É um serviço de código aberto, distribuído e centralizado para manter as informações de configuração, nomear, fornecer sincronização distribuída e fornecer serviços de grupo em todo o cluster.
Fagulha – fagulha

Spark é uma estrutura alternativa ao Hadoop construído em Scala, mas suporta vários aplicativos escritos em Java, Pitão, etc. Comparado com MapReduce, fornece processamento na memória que representa um processamento mais rápido. Além do processamento em lote oferecido pelo Hadoop, também pode lidar com processamento em tempo real.
O que mais, Spark tem seu próprio ecossistema:

- Spark Core é o tempo de execução principal para Spark e outras APIs construídas sobre ele
- API de Spark SQL permite consultar dados estruturados armazenados em DataFrames ou tabelas Hive
- API de streaming permite que o Spark lide com os dados em tempo real. Pode ser facilmente integrado com uma variedade de fontes de dados, como Flume, Kafka e Twitter.
- MLlib é uma biblioteca de aprendizado de máquina escalonável que permitirá que você execute tarefas de ciência de dados enquanto aproveita as propriedades do Spark ao mesmo tempo
- GraphX é um mecanismo de cálculo gráfico que permite aos usuários construir, transforma e raciocina interativamente em dados estruturados em gráficos em escala e vem com uma biblioteca de algoritmos comuns
Estágios do processamento de Big Data
Com tantos componentes no ecossistema Hadoop, pode ser bastante intimidante e difícil de entender o que cada componente faz. Portanto, é mais fácil agrupar alguns dos componentes com base em onde eles estão no estágio de processamento de Big Data.
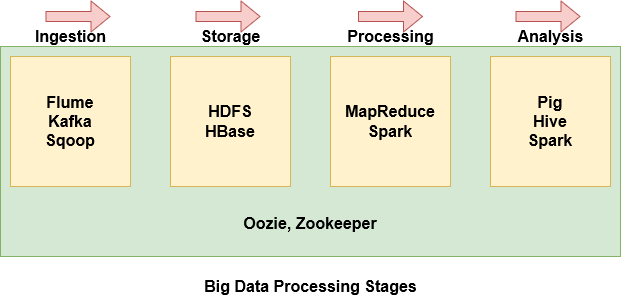
- Flume, Kafka e Sqoop são usados para ingerir dados de fontes externas no HDFS
- HDFS é a unidade de armazenamento do Hadoop. Mesmo os dados importados do Hbase são armazenados no HDFS
- MapReduce e Spark são usados para processar os dados no HDFS e executar várias tarefas
- Porco, Hive e Spark são usados para analisar os dados.
- Oozie ajuda a agendar tarefas. Uma vez que funciona com várias plataformas, usado em todas as fases.
- Zookeeper sincroniza os nós do cluster e também é usado em todos os estágios.
Notas finais
Espero que este artigo tenha sido útil para entender Big Data, por que os sistemas tradicionais não conseguem lidar com isso e quais são os componentes importantes do ecossistema Hadoop.
Eu encorajo você a verificar mais alguns artigos sobre Big Data que podem ser úteis:





