Visão geral
- Saiba mais sobre marcação de voz (POS),
- Compreenda a análise de dependência e a análise distrital
Introdução
Conhecimento de línguas é a porta para a sabedoria.
– Roger Bacon
Fiquei surpreso que Roger Bacon deu a citação acima no século XIII, e ainda se mantém, não é assim? Tenho certeza que todos vão concordar comigo.
Hoje em dia, a maneira de entender as línguas mudou muito desde o século 13. Agora nos referimos a ele como linguística e processamento de linguagem natural. Mas sua importância não diminuiu; em vez de, aumentou enormemente. Você sabe porque? Porque é Formulários foram baleados e um deles é o motivo pelo qual você pousou neste artigo.

Cada uma dessas aplicações envolve técnicas complexas de PNL e, para entendê-los, é necessário ter um bom conhecimento dos fundamentos da PNL. Portanto, antes de passar para tópicos complexos, é importante manter os fundamentos corretos.
É por isso que criei este artigo no qual abordarei alguns conceitos básicos da PNL.: rotulagem de classe gramatical (POS), Análise de dependência e análise de distrito em processamento de linguagem natural. Vamos entender esses conceitos e também implementá-los em Python. Vamos começar!
Tabela de conteúdo
- Rotulando classes gramaticais (POS)
- Análise de dependência
- Análise de constituintes
Rotulando classes gramaticais (POS)
Em nossos dias de escola, todos nós estudamos as classes gramaticais, isso inclui substantivos, pronomes, adjetivos, verbos, etc. Palavras que pertencem a várias classes gramaticais formam uma frase. Saber a parte da fala das palavras em uma frase é importante para entendê-la.
Daí a criação do conceito de etiquetagem POS.. Tenho certeza que você já deve ter adivinhado o que é marcação de PDV. Ainda assim, deixe-me explicar.
Rotulando classes gramaticais (POS) é o processo de atribuição de diferentes marcas conhecidas como marcas de PDV a palavras em uma frase que nos fala sobre a parte da fala da palavra.
Em termos gerais, existem dois tipos de tags POS:
1. Tags POS universais: Essas tags são usadas em dependências universais (FORA) (última versão 2), um projeto que está desenvolvendo anotações de treebank consistentes em vários idiomas para muitos idiomas. Essas tags são baseadas no tipo de palavras. Por exemplo, SUBSTANTIVO (nome comum), ADJ (adjetivo), ADV (advérbio).
Lista de rótulos de PDV universal
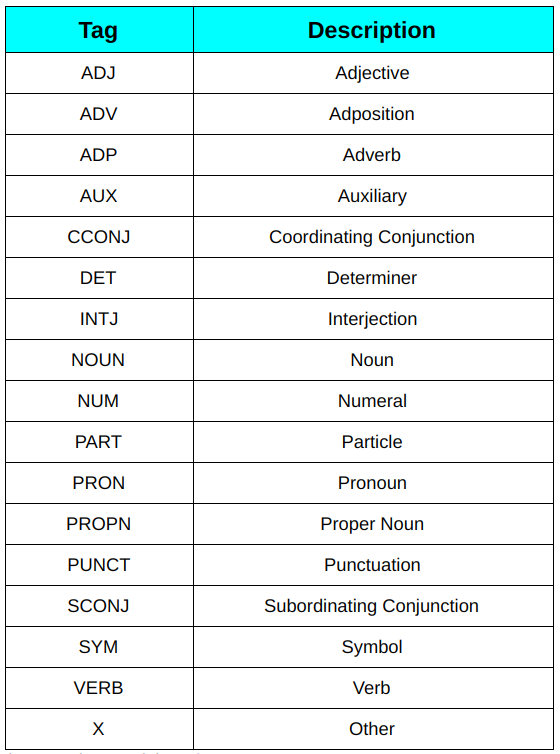
Você pode ler mais sobre cada um deles aqui.
2. Rótulos detalhados de pontos de venda: Essas etiquetas são o resultado da divisão das etiquetas POS universais em várias etiquetas, como NNS para substantivos comuns no plural e NN para substantivos comuns no singular em comparação com NOUN para substantivos comuns em inglês. Essas tags são específicas do idioma. Você pode dar uma olhada na lista completa aqui.
Agora você sabe o que são rótulos de ponto de venda e o que é rótulo de ponto de venda. Então, vamos escrever o código Python para as frases de marcação POS. Para este propósito, Eu usei o Spacy aqui, mas existem outras bibliotecas como NLTK e Estrofe, que também pode ser usado para fazer o mesmo.

No exemplo de código acima, Eu carreguei o espaço en_web_core_sm modelo e usei-o para obter as tags POS. Você pode ver que o pos_ retorna tags POS universais, e rótulo_ retorna tags POS detalhadas para as palavras na frase.
Análise de dependência
A análise de dependência é o processo de analisar a estrutura gramatical de uma frase com base nas dependências entre as palavras de uma frase.
Na análise de dependência, vários rótulos representam a relação entre duas palavras em uma frase. Essas tags são as tags de dependência. Por exemplo, na frase “tempo chuvoso”, palavra chuvoso modificar o significado do substantivo clima. Portanto, existe uma dependência do clima -> chuvoso em que o clima aja como ele cabeça e ele chuvoso Agir como dependente o Menino. Esta dependência é representada por doença marcação, que representa o adjetivo modificador.
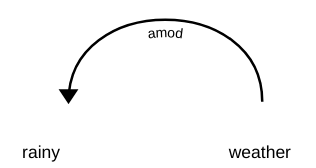
de forma similar, existem muitas dependências entre as palavras em uma frase, mas note que uma dependência envolve apenas duas palavras em que uma atua como o chefe e a outra atua como a criança. A partir de agora, existem 37 Relacionamentos de dependência universal usados na dependência universal (versão 2). Você pode dar uma olhada em todos eles aqui. Além destes, também existem muitas tags específicas de idioma.
Agora vamos usar o Spacy e encontrar as dependências em uma frase.

No exemplo de código acima, a dep_ retorna a tag de dependência de uma palavra e cabeça de texto retorna o respectivo cabeça palavra. Se você notou, na foto acima, palavra eu pego tem uma tag de dependência de RAIZ. Esta marca é atribuída à palavra que atua como o título de muitas palavras em uma frase, mas não é filha de nenhuma outra palavra. Geralmente, é o verbo principal da frase semelhante a ‘levou’ neste caso.
Agora você sabe quais tags de dependência e qual palavra principal, secundário e raiz são. Mas a análise não significa gerar uma árvore de análise?
sim, estamos gerando a árvore aqui, mas não estamos visualizando isso. A árvore gerada pela análise de dependência é conhecida como árvore de dependência. Existem várias maneiras de visualizá-lo, mas por uma questão de simplicidade, usaremos DESLOCAMENTO que é usado para exibir a análise de dependência.

Na foto acima, as setas representam a dependência entre duas palavras em que a palavra na ponta da seta é a criança e a palavra no final da seta é a cabeça. A palavra raiz pode atuar como o título de várias palavras em uma frase, mas não é filha de nenhuma outra palavra. Você pode ver acima que a palavra 'levou’ tem várias setas de saída, mas nenhuma de entrada. Por tanto, é a raiz da palavra. Uma coisa interessante sobre a palavra raiz é que se você começar a rastrear as dependências em uma frase, pode chegar à palavra raiz, não importa de que palavra comece.
Agora que você sabe sobre a análise de dependência, Vamos aprender sobre outro tipo de análise conhecido como Análise Constituinte.
Análise de constituintes
A análise de constituintes é o processo de analisar sentenças dividindo-as em subfrases também conhecidas como constituintes.. Essas subfrases pertencem a uma categoria específica de gramática como NP (frase nominal) o VP (frase verbal).
Vamos entender com a ajuda de um exemplo. Suponha que eu tenha a mesma frase que usei nos exemplos anteriores, quer dizer, “Levei mais de duas horas para traduzir algumas páginas do inglês”. e fiz uma análise de constituintes sobre ele. Então, a árvore de análise constituinte para esta frase é dada por:
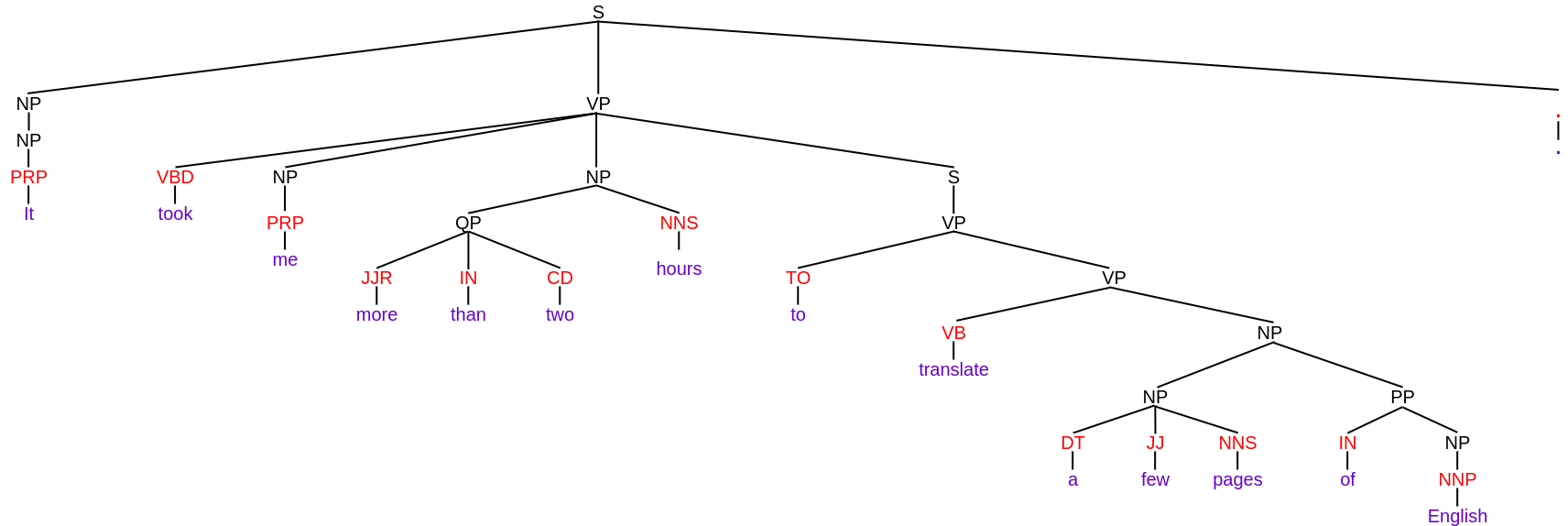
Na árvore acima, as palavras da frase são escritas em roxo e as tags POS são escritas em vermelho. Exceto por estes, tudo está escrito em preto, que representa os componentes. Você pode ver claramente como toda a frase é dividida em sub-frases até que apenas as palavras sejam deixadas nos terminais. O que mais, existem rótulos diferentes para denotar componentes como
- VP para frase verbal
- NP para sintagmas nominais
Estes são os rótulos constituintes. Você pode ler sobre os diferentes rótulos constituintes aqui.
Agora você sabe o que é análise de constituintes, então é hora de codificar em python. Agora, spaCy não fornece uma API oficial para análise de constituintes. Portanto, vamos usar o Analisador Neural de Berkeley. É uma implementação Python de analisadores baseados em Análise de constituintes com um codificador atento por ACL 2018.
Você também pode usar StanfordParser com Stanza ou NLTK para esta finalidade, mas aqui eu usei Berkely Neural Parser. Para usar isto, precisamos instalá-lo primeiro. Você pode fazer isso executando o seguinte comando.
!pip install benepar
Então você tem que baixar o benerpar_en2 modelo.
Você deve ter notado que estou usando o TensorFlow 1.x aqui porque atualmente, benepar não é compatível com TensorFlow 2.0. Agora é a hora de analisar os distritos eleitorais.

Aqui, _.parse_string gera a árvore de análise como uma string.
Notas finais
Agora, você já sabe o que é rotulagem de PDV, análise de dependência e análise constituinte e como elas ajudam você a entender os dados de texto, quer dizer, As tags POS informam sobre a parte gramatical das palavras em uma frase, A análise de dependência informa sobre as dependências entre as palavras em uma frase e a análise constituinte informa sobre as subfrases ou constituintes de uma frase. Agora você está pronto para avançar para partes mais complexas da PNL.. Como próximos passos, Você pode ler os seguintes artigos sobre extração de informações.
Nestes artigos, você aprenderá como usar tags POS e tags de dependência para extrair informações do corpus. O que mais, para obter mais informações sobre spaCy, você pode ler este artigo: Tutorial SpaCy para aprender e dominar o processamento de linguagem natural (PNL) Além destes, se você quiser aprender processamento de linguagem natural por meio de um curso, Posso recomendar o seguinte isso inclui tudo, de projetos a tutoriais individuais:
Se você achou este artigo informativo, Compartilhe com seus amigos. O que mais, você pode comentar abaixo de suas dúvidas.





