Este artigo foi publicado como parte do Data Science Blogathon
Introdução
Existem muitas maneiras de comparar texto em Python. Porém, frequentemente procuramos uma maneira fácil de comparar texto. A comparação de texto é necessária para vários propósitos de análise de texto e processamento de linguagem natural.
Uma das maneiras mais fáceis de comparar texto em Python é usar a biblioteca fuzzy-wuzzy. Aqui, nós temos uma pontuação de 100, de acordo com a semelhança das cadeias. Basicamente, recebemos o índice de similaridade. A biblioteca usa a distância de Levenshtein para calcular a diferença entre duas strings.

Distância de Levenshtein
A distância de Levenshtein é uma métrica de string para calcular a diferença entre duas strings diferentes. O matemático soviético Vladimir Levenshtein formulou este método e leva o seu nome..
A distância de Levenshtein entre duas cordas uma, b (de comprimento {| uma | e | b | respectivamente) É dado por lev (uma, b) Onde
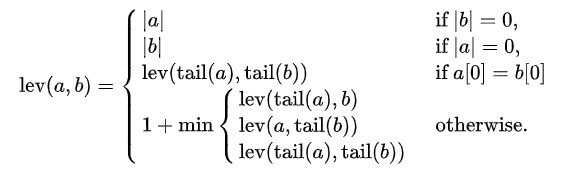
onde ele Cola de alguma corda X é uma sequência de todos, exceto o primeiro caractere de X, e X[n] é o Norteº caractere de string X começando com o personagem 0.
(Fonte: https://en.wikipedia.org/wiki/Levenshtein_distance)
Felpudo, macio
Fuzzy Wuzzy é uma biblioteca de código aberto desenvolvida e lançada pela SeatGeek. Você pode ler o blog original dele aqui. Implementação simples e pontuação única (sobre 100) meticulosos tornam interessante o uso do FuzzyWuzzy para comparação de texto e tem inúmeras aplicações.
Instalação:
pip install fuzzywuzzy
pip install python-Levenshtein
Estes são os requisitos que devem ser instalados.
Agora vamos começar com o código importando as bibliotecas necessárias.
de importação fuzzywuzzy penugem de importação fuzzywuzzy processo
Importações necessárias são feitas.
#comparação de cordas #exatamente o mesmo texto penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.ratio'}, '*')">Razão('Londres é uma cidade grande.', 'Londres é uma cidade grande.')
Partida: 100
Uma vez que as duas cordas são exatamente iguais aqui, nós obtemos o resultado 100, indicando strings idênticas.
#comparação de cordas #não é o mesmo texto penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.ratio'}, '*')">Razão('Londres é uma cidade grande.', 'Londres é uma cidade muito grande.')
Partida: 89
Como as cordas estão diferentes agora, a pontuação é 89. Então, nós assistimos trabalho fuzzy wuzzy.
#agora vamos fazer a conversão de casos a1 = "Programa Python" a2 = "PROGRAMA PYTHON" Razão = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.ratio'}, '*')">Razão(a1.diminuir(),a2.diminuir()) imprimir(Razão)
Partida: 100
Aqui, neste caso, embora as duas cadeias diferentes tenham casos diferentes, ambos foram convertidos para minúsculas e a pontuação foi 100.
Correspondência de substring
Agora, muitas vezes, podem surgir vários casos de correspondência de texto em que precisamos comparar duas strings diferentes, onde uma pode ser uma substring da outra. Por exemplo, estamos testando um resumo em texto e precisamos verificar se ele está funcionando bem. Então, o texto resumido será uma substring da string original. FuzzyWuzzy tem funções poderosas para lidar com esses casos.
#funções fuzzywuzzy para trabalhar com correspondência de substring b1 = "O Grupo Samsung é um conglomerado multinacional sul-coreano com sede em Samsung Town, Seul." b2 = "Samsung Group é uma empresa sul-coreana com sede em Seul" Razão = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.ratio'}, '*')">Razão(b1.diminuir(),b2.diminuir()) Partial_Ratio = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">proporção_parcial(b1.diminuir(),b2.diminuir()) imprimir("Razão:",Razão) imprimir("Razão Parcial:",Partial_Ratio)
Produção:
Razão: 64 Razão Parcial: 74
Aqui, podemos ver que a pontuação da função Motivo parcial é maior. Isso indica que ele é capaz de reconhecer o fato de que a corda b2 tem palavras de b1.
Razão de classificação de token
Mas o método de comparação de substring acima não é infalível. Frequentemente, as palavras estão misturadas e não seguem uma ordem. de forma similar, no caso de sentenças semelhantes, a ordem das palavras é diferente ou misturada. Neste caso, nós usamos uma função diferente.
c1 = "Samsung Galaxy SmartPhone" c2 = "SmartPhone Samsung Galaxy" Razão = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.ratio'}, '*')">Razão(c1.diminuir(),c2.diminuir()) Partial_Ratio = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">proporção_parcial(c1.diminuir(),c2.diminuir()) Token_Sort_Ratio = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">token_sort_ratio(c1.diminuir(),c2.diminuir()) imprimir("Razão:",Razão) imprimir("Razão Parcial:",Partial_Ratio) imprimir("Razão de classificação de token:",Token_Sort_Ratio)
Produção:
Razão: 56 Razão Parcial: 60 Razão de classificação de token: 100
Então, aqui, neste caso, podemos ver que as strings são apenas versões misturadas umas das outras. E as duas strings mostram o mesmo sentimento e também mencionam a mesma entidade. A função fuzz padrão mostra que a pontuação entre eles é 56. E a função Token Sort Ratio mostra que a semelhança é 100.
Então, é claro que em algumas situações ou aplicações, o índice de classificação de tokens será mais útil.
Proporção de conjunto de token
Mas, agora, se as duas cordas têm comprimentos diferentes. As funções de relacionamento de classificação de token podem não funcionar bem nesta situação. Para isso, temos a função Token Set Ratio.
d1 = "O Windows é desenvolvido pela Microsoft Corporation" d2 = "Microsoft Windows" Razão = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.ratio'}, '*')">Razão(d1.diminuir(),d2.diminuir()) Partial_Ratio = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">proporção_parcial(d1.diminuir(),d2.diminuir()) Token_Sort_Ratio = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">token_sort_ratio(d1.diminuir(),d2.diminuir()) Token_Set_Ratio = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.token_set_ratio'}, '*')">token_set_ratio(d1.diminuir(),d2.diminuir()) imprimir("Razão:",Razão) imprimir("Razão Parcial:",Partial_Ratio) imprimir("Razão de classificação de token:",Token_Sort_Ratio) imprimir("Proporção do conjunto de token:",Token_Set_Ratio)
Produção:
Razão: 41 Razão Parcial: 65 Razão de classificação de token: 59 Proporção do conjunto de token: 100
¡Ah! A pontuação de 100. Nós vamos, a razão é que a corrente d2 os componentes estão totalmente presentes na cadeia d1.
Agora, vamos modificar ligeiramente a string d2.
d1 = "O Windows é desenvolvido pela Microsoft Corporation" d2 = "Microsoft Windows 10" Razão = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.ratio'}, '*')">Razão(d1.diminuir(),d2.diminuir()) Partial_Ratio = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">proporção_parcial(d1.diminuir(),d2.diminuir()) Token_Sort_Ratio = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">token_sort_ratio(d1.diminuir(),d2.diminuir()) Token_Set_Ratio = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.token_set_ratio'}, '*')">token_set_ratio(d1.diminuir(),d2.diminuir()) imprimir("Razão:",Razão) imprimir("Razão Parcial:",Partial_Ratio) imprimir("Razão de classificação de token:",Token_Sort_Ratio) imprimir("Proporção do conjunto de token:",Token_Set_Ratio)
Por, modificando ligeiramente o texto d2 podemos ver que a pontuação é reduzida para 92. Isso ocorre porque o texto “10“Não presente na rede d1.
WRatio ()
Este recurso ajuda a gerenciar a capitalização, letras minúsculas e alguns outros parâmetros.
#fuzz.WRatio() imprimir("Ligeira mudança de casos:",penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.WRatio'}, '*')">WRatio('Ferrari LaFerrari', 'FerrarI LAFerrari'))
Produção:
Ligeira mudança de casos: 100
Vamos tentar remover um espaço.
#fuzz.WRatio() imprimir("Ligeira mudança de casos e um espaço removido:",penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.WRatio'}, '*')">WRatio('Ferrari LaFerrari', 'FerrarILAFerrari'))
Produção:
Ligeira mudança de casos e um espaço removido: 97
Vamos tentar alguns sinais de pontuação.
#lidar com algumas pontuações aleatórias g1= 'Microsoft Windows é bom, mas ocupa um patamar de carneiro!!!' g2= 'Microsoft Windows é bom, mas ocupa muito de RAM?' imprimir(penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.WRatio'}, '*')">WRatio(g1,g2 ))
Partida: 99
Portanto, podemos ver que o FuzzyWuzzy tem muitas funções interessantes que podem ser usadas para realizar tarefas interessantes de comparação de texto.
Algumas aplicações adequadas:
O FuzzyWuzzy pode ter alguns aplicativos interessantes.
Pode ser usado para avaliar resumos de texto mais longos e julgar sua semelhança. Isso pode ser usado para medir o desempenho de resumos de texto.
De acordo com a semelhança dos textos, também pode ser usado para identificar a autenticidade de um texto, Artigo, Notícia, livro, etc. Frequentemente, encontramos vários textos / dados incorretos. Frequentemente, não é possível verificar todos os dados de texto. Usando similaridade de texto, verificação cruzada de vários textos pode ser realizada.
FuzzyWuzzy também pode ser útil para selecionar o melhor texto semelhante entre vários textos. Então, As aplicações do FuzzyWuzzy são numerosas.
Similaridade de texto é uma métrica importante que pode ser usada para vários propósitos de PNL e análise de texto.. O interessante sobre o FuzzyWuzzy é que as semelhanças são dadas como uma pontuação de 100. Isso permite uma pontuação relativa e também gera uma nova característica / dados que podem ser usados para fins analíticos / ML.
Semelhança resumida:
#usos de fuzzy wuzzy #summary similarity Entrada de texto="Análise de texto envolve o uso de dados de texto não estruturados, processando-os em dados estruturados utilizáveis. Text Analytics é uma aplicação interessante de Processamento de Linguagem Natural. Text Analytics tem vários processos, incluindo limpeza de texto, removendo palavras irrelevantes, cálculo da frequência da palavra, e muito mais. Text Analytics ganhou muita importância nos dias de hoje. Enquanto milhões de pessoas se envolvem em plataformas online e se comunicam entre si, uma grande quantidade de dados de texto é gerada. Os dados de texto podem ser blogs, postagens de mídia social, tweets, revisão de produtos, pesquisas, discussões do fórum, e muito mais. Essas enormes quantidades de dados criam enormes dados de texto para as organizações usarem. A maioria dos dados de texto disponíveis são desestruturados e dispersos. A análise de texto é usada para coletar e processar essa vasta quantidade de informações para obter insights. A Análise de Texto serve como base para muitas tarefas avançadas de PNL, como Classificação, Categorização, Análise de sentimentos, e muito mais. Text Analytics é usado para entender padrões e tendências em dados de texto. Palavras-chave, tópicos, e recursos importantes de texto são encontrados usando analítica de texto. Existem muitos outros aspectos interessantes da Análise de Texto, agora vamos prosseguir com nosso conjunto de dados de currículo. O conjunto de dados contém textos de vários tipos de currículos e pode ser usado para entender o que as pessoas usam principalmente em currículos. Resume Text Analytics é frequentemente usado por recrutadores para entender o perfil dos candidatos e filtrar as inscrições. O recrutamento para empregos se tornou uma tarefa difícil nos dias de hoje, com um grande número de candidatos a empregos. Os executivos de Recursos Humanos costumam usar várias ferramentas de processamento de texto e leitura de arquivos para entender os currículos enviados. Aqui, trabalhamos com um conjunto de dados de currículo de amostra, que contém o texto do currículo e a categoria do currículo. Devemos ler os dados, limpe-o e tente obter alguns insights dos dados."
O texto acima é o texto original.
output_text="Análise de texto envolve o uso de dados de texto não estruturados, processando-os em dados estruturados utilizáveis. Text Analytics é uma aplicação interessante de Processamento de Linguagem Natural. Text Analytics tem vários processos, incluindo limpeza de texto, removendo palavras irrelevantes, cálculo da frequência da palavra, e muito mais. Text Analytics é usado para entender padrões e tendências em dados de texto. Palavras-chave, tópicos, e recursos importantes de texto são encontrados usando analítica de texto. Existem muitos outros aspectos interessantes da Análise de Texto, agora vamos prosseguir com nosso conjunto de dados de currículo. O conjunto de dados contém texto de vários tipos de currículos e pode ser usado para entender o que as pessoas usam principalmente em currículos."
Razão = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.ratio'}, '*')">Razão(Entrada de texto.diminuir(),output_text.diminuir()) Partial_Ratio = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">proporção_parcial(Entrada de texto.diminuir(),output_text.diminuir()) Token_Sort_Ratio = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">token_sort_ratio(Entrada de texto.diminuir(),output_text.diminuir()) Token_Set_Ratio = penugem.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.token_set_ratio'}, '*')">token_set_ratio(Entrada de texto.diminuir(),output_text.diminuir()) imprimir("Razão:",Razão) imprimir("Razão Parcial:",Partial_Ratio) imprimir("Razão de classificação de token:",Token_Sort_Ratio) imprimir("Proporção do conjunto de token:",Token_Set_Ratio)
Produção:
Razão: 54 Razão Parcial: 79 Razão de classificação de token: 54 Proporção do conjunto de token: 100
Podemos ver as diferentes pontuações. A relação parcial mostra que eles são bastante semelhantes, qual deveria ser o caso. O que mais, a proporção do conjunto de tokens é 100, o que é evidente, uma vez que o resumo foi completamente retirado do texto original.
Melhor correspondência de string possível:
Vamos usar a biblioteca de processos para encontrar a melhor correspondência de string possível entre uma lista de strings.
#escolhendo a possível correspondência de string #using process library consulta = 'Stack Overflow' escolhas = ['Estoque Overhead', 'Stack Overflowing', 'S. Transbordar',"Stoack Overflow"] imprimir("Lista de proporções: ") imprimir(processo.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.process.extract'}, '*')">extrair(consulta, escolhas)) imprimir("Melhor escolha: ",processo.<um onclick ="parent.postMessage({'referente':'.fuzzywuzzy.process.extractOne'}, '*')">extractOne(consulta, escolhas))
Produção:
Lista de proporções:
[('Stoack Overflow', 97), ('Stack Overflowing', 90), ('S. Transbordar', 85), ('Estoque Overhead', 64)]
Melhor escolha: ('Stoack Overflow', 97)
Portanto, pontuações de similaridade e melhor correspondência são fornecidas.
Ultimas palavras
A biblioteca FuzzyWuzzy é construída sobre a biblioteca difflib. E python-Levenshtein usado para otimizar a velocidade. Portanto, podemos entender que FuzzyWuzzy é uma das melhores maneiras de comparar strings em Python.
Verifique o código no Kaggle aqui.
Sobre mim:
Prateek Majumder
Ciência e análise de dados | Especialista em marketing digital | SEO | Criação de conteúdo
Conecte-se comigo no Linkedin.
Meus outros artigos sobre DataPeaker: Ligação.
Obrigado.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





