Introdução
Os recursos conduzidos pela ciência de dados não estão crescendo como esperado e o crescimento é apenas por 14%.
Mesmo na era digital de hoje, a ciência de dados ainda requer muito trabalho manual. Armazene os dados gerados, limpe-os, análise exploratória, visualize os dados e, finalmente, ajuste um modelo para permitir a tomada de decisão. O trabalho manual pode ser automatizado até certo ponto e, portanto, o início da automação em ciência de dados.
O ciclo de vida de um conjunto de dados no projeto de ciência de dados é o seguinte
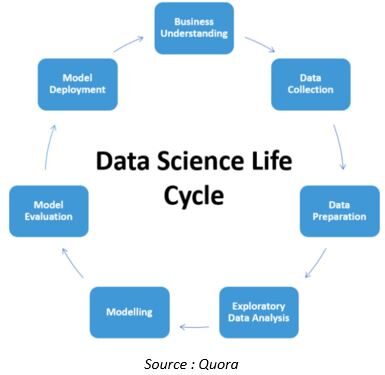
Exceto para compreensão de negócios e implementação de modelo, quase todos os aspectos do pipeline de ciência de dados estão em processo de automação. Vamos ver alguns dos desenvolvimentos nesta área.
Coleta automática de dados
Uma vez que os dados são a base de todas as análises, devemos gastar uma quantidade considerável de nosso tempo entendendo-os. Dados incompletos podem levar a modelos não confiáveis ou tendenciosos e, se a empresa toma decisões sobre esses modelos, Desnecessário dizer que isso levaria a desastres que nem sequer se poderia imaginar.
Dataprep é uma biblioteca Python de código aberto que nos permite preparar dados com apenas algumas linhas de código. O Dataprep nos permite visualizar quaisquer dados ausentes em nosso conjunto de dados, descobrir os dados ausentes é obrigatório enquanto preparamos os dados para que possamos substituí-los por dados úteis de acordo.
Abaixo está a sintaxe para instalar a biblioteca Dataprep usando pip install
pip install -U dataprep
O conector é um componente do DataPrep que visa simplificar a coleta de dados de APIs da web, fornecendo um conjunto padrão de operações. É um contêiner de API de código aberto que acelera o desenvolvimento fazendo várias chamadas de API. Simplifica a chamada de várias APIs por meio de uma biblioteca intuitiva.
Abaixo está a sintaxe para instalar Dataprep.connector
da importação dataprep.connector *
Vejamos um exemplo de uso de conexão para coletar dados. Con Conector, você pode coletar dados de um dos principais sites de recomendação online: Yelp.
de dataprep.connector import connect
# use a função de conexão com o "uivo" string e token de acesso do Yelp, ambos especificados como parâmetros. Esta ação nos permite criar um Conector para a API da Web do Yelp:
yelp_connector = conectar("uivo", _auth ={"access_token":"<Seu token de acesso do Yelp>"})
yelp_connector.info()# fornece informações sobre como usar o Connector over Web API
Produção

neste exemplo, há apenas um endpoint disponível para o Yelp: O negócio. Porém, se você quiser se conectar a um endpoint do Yelp diferente, você pode criar um novo arquivo de configuração.
yelp_connector.show_schema (“o negócio”) # explorar esquema de endpoint “o negócio” de acordo com a definição do seu arquivo de configuração
Limpeza automática de dados
A limpeza de dados é uma das tarefas mais tediosas para um cientista de dados, ocupa seu precioso tempo. Tem sido objeto de pesquisa exclusiva nos últimos anos. Tanto startups quanto empresas grandes e estabelecidas oferecem automação e ferramentas para limpeza de dados.
DataPrep.Clean visa fornecer um grande número de funções com uma interface unificada para limpar e padronizar dados de vários tipos semânticos em Pandas.
DataPrep.Clean contém funções simples projetadas para limpar e validar dados em um DataFrame. Abaixo estão os destaques da biblioteca DataPrep.Clean.
O código a seguir demonstra como usar DataPrep.Clean. Usaremos el conjunto de datos waste_hauler del repositorio interno de conjuntos de datos de DataPrep.
de dataprep.importação limpa *
from dataprep.datasets import load_dataset
df = load_dataset('waste_hauler')
df.head()
Produção

df = clean_headers(df)#converts the headers into snake case
print(df.columns)
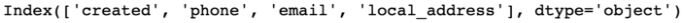
Hay muchas más funciones en dataprep.clean como se muestra a continuación
df = clean_phone(df, 'Telefone')#Para padronizar seus formatos, podemos usar a função clean_phone() df = clean_address(df, 'local_address')#para padronizar as inconsistências no endereço
Exploración automática de datos:
A exploração de dados refere-se às etapas preliminares na análise de dados e construção de modelo em que os analistas de dados usam técnicas estatísticas para descrever as características do conjunto de dados., como tamanho, qualidade, quantidade e precisão, e resumi-lo para entender melhor a natureza dos dados.
DataPrep.EDA é a ferramenta de EDA mais rápida e fácil do Python. Permite que os cientistas de dados entendam os pandas com algumas linhas de código em segundos.
A função plot_missing () permite uma análise abrangente de valores ausentes e seu impacto no conjunto de dados. O seguinte descreve a funcionalidade de plot_missing () para um determinado quadro de dados df.
de dataprep.eda import plot_missing
de dataprep.datasets import load_dataset
df = load_dataset("titânico")
plot_missing(df)
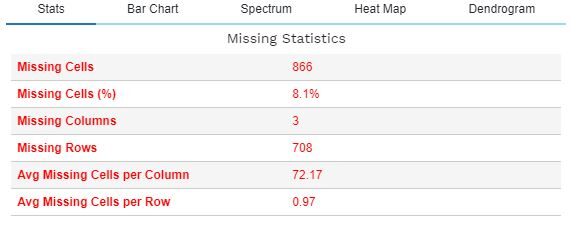
Existem muitas outras funções em dataprep.eda, conforme mostrado abaixo
plot_correlation() #gera matrizes de correlação e coeficiente de correlação enredo(df) #traça um histograma para cada coluna numérica, um gráfico de barras para cada coluna categórica, e calcula estatísticas de conjunto de dados.
Ele nos permite criar relatórios detalhados de um Pandas / Dask DataFrame com função create_report. DataPrep.EDA é 100 vezes mais rápido do que as ferramentas de perfil baseadas no pandas, gera visualizações interativas em um relatório que torna o relatório mais atraente e também suporta big data com milhões de linhas trabalhando, o que não era fácil com a biblioteca tradicional do pandas.
Modelado automático de ML:
A próxima etapa e mais procurada no ciclo de vida da ciência de dados é o ajuste do modelo. Aprendizado de máquina automatizado (AutoML) atualmente é o assunto da cidade na comunidade de ciência de dados. O Auto ML nos fornece as ferramentas que nos ajudam a encontrar o modelo de aprendizado de máquina apropriado para o conjunto de dados fornecido com o mínimo de envolvimento do usuário..
LightAutoML é uma das bibliotecas Python projetadas para realizar várias tarefas, como classificação binária e regressão / multiclasse em conjuntos de dados tabulares, contendo diferentes tipos de dados como numéricos, categórico, textos, etc.
Outro exemplo é Auto-Sklearn. É uma biblioteca Python usada para descobrir automaticamente modelos de alto desempenho para tarefas de regressão. Usa modelos de aprendizado de máquina da biblioteca de aprendizado de máquina scikit-learn.
A vantagem do Auto-Sklearn é que, bem como descobrir a preparação de dados e o modelo que funciona para um conjunto de dados, você também pode aprender com os modelos que tiveram um bom desempenho em conjuntos de dados semelhantes e pode criar automaticamente um conjunto de dados de alto desempenho. modelos descobertos como parte do processo de otimização.
No exemplo a seguir, usaremos Auto-Sklearn para descobrir um modelo para o conjunto de dados da sonda. a AutoSklearnClassifier está configurado para ser executado por 5 minutos com 8 núcleos e limitar a avaliação de cada modelo a 30 segundos.
do pandas import read_csv
de sklearn.model_selection import train_test_split
de sklearn.preprocessing import LabelEncoder
de sklearn.metrics import precision_score
from autosklearn.classification import AutoSklearnClassifier
url ="https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv"
dataframe = read_csv(url, header = None)
# dividido em elementos de entrada e saída
data = dataframe.values
X, y = dados[:, :-1], dados[:, -1]
# preparar minimamente conjunto de dados
X = X.astype('float32')
y = LabelEncoder().fit_transform(y.astype('str'))
# dividir em conjuntos de treinamento e teste
X_train, X_test, y_train, y_test = train_test_split(X, e, test_size = 0,33, random_state = 1)
# definir pesquisa
model = AutoSklearnClassifier(time_left_for_this_task = 5 * 60, per_run_time_limit = 30, n_jobs = 8)
model.fit(X_train, y_train)#realizar a pesquisa
imprimir(model.sprint_statistics())#resumir
Produção
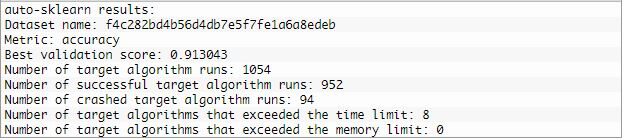
Avaliação de modelo:
Uma vez que o modelo é construído, é hora de verificar o desempenho do mesmo ou melhor, a precisão com que o modelo está trabalhando. Se a precisão não estiver à altura da marca, o modelo não é considerado o ajuste correto para esse conjunto de dados.

Como no caso do exemplo anterior, definimos uma classe AutoSklearnClassifier para controlar a pesquisa e configurá-la para ser executada por um período específico, Digamos 2 minutos, e descartar qualquer modelo que demore mais do que 30 segundos para avaliar. No final desses 2 minutos, podemos revisar as estatísticas de pesquisa e avaliar o modelo de melhor desempenho.
# avalie o melhor modelo
y_hat = model.predict(X_test)
acc = precisão_score(y_test, y_hat)
imprimir("Precisão: %.2f" % acc)
A precisão da classificação do 81,2 por cento, o que é razoavelmente habilidoso.
Limitações

Apesar do fato de que a automação tem aumentado nos últimos tempos, existem definitivamente algumas ressalvas / desvantagens. Mais importante, o AutoML precisa de mais recursos, pelo contrário, vai demorar mais para correr. O processamento de máquina de aprendizado de máquina de dados não estruturados e semiestruturados é tecnicamente difícil.
Frequentemente, problemas realistas são uma combinação de múltiplos objetivos, Como tal, há uma necessidade de fazer diferenças sutis entre a tomada de decisão e o custo, que requer a intervenção de um cientista de dados. Sempre haverá a necessidade de pontos de verificação manuais onde os humanos possam entrar e assinar partes do processo automatizado. Isso pode adicionar a responsabilidade necessária e ajudar com a regulamentação e governança. Portanto, a aprovação final sempre será dada pelo cientista de dados.
Referências
https://machinelearningmastery.co
A mídia mostrada neste artigo sobre Automation in Data Science não é propriedade da DataPeaker e é usada a critério do autor.





