Esta postagem foi lançada como parte do Data Science Blogathon.
Visão geral
Introdução
O Apache Spark é uma estrutura de processamento de dados que pode executar rapidamente tarefas de processamento em conjuntos de dados muito grandes e também pode espalhar tarefas de processamento de dados em vários computadores., sozinho ou em conjunto com outras ferramentas de computação distribuída. É um mecanismo de análise unificado ultrarrápido para big data e aprendizado de máquina.
Para oferecer suporte a Python com Spark, a comunidade Apache Spark lançou uma ferramenta, PySpark. Com PySpark, você pode trabalhar com RDD na linguagem de programação Python.
Os componentes do Spark são:
- Spark Core
- Spark SQL
- Spark Streaming
- Faísca MLlib
- GraphX
- Faísca R
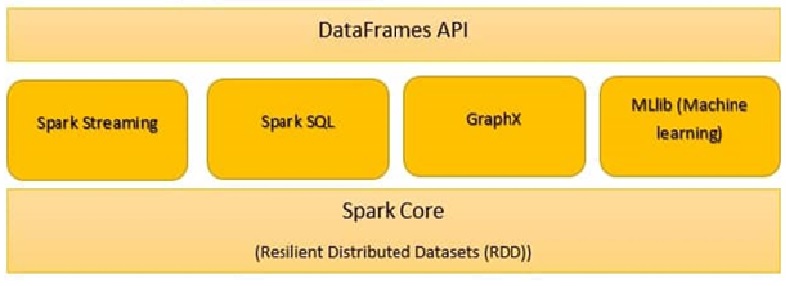
Spark Core
Todas as funcionalidades fornecidas pelo Apache Spark estão focadas na parte superior do Spark Core. Gerencia todas as funcionalidades do E / S Essencial. Usado para despacho de tarefas e recuperação de falhas. O Spark Core está incorporado com uma coleção especial chamada RDD (Conjunto de dados distribuído resiliente). RDD está entre as abstrações do Spark. O Spark RDD lida com o particionamento de dados em todos os nós em um cluster. Mantém-nos no pool de memória do cluster como uma única unidade. Há duas operações feitas em RDD:
Transformação: É uma função que produz novos RDDs a partir de RDDs existentes.
Açao: Em Transformação, RDDs criam uns aos outros. Mas quando queremos trabalhar com o conjunto de dados real, então, Nesse ponto, usamos a Ação.
Spark SQL
O componente Spark SQL é uma estrutura distribuída para o processamento de dados estruturados. O Spark SQL funciona para inserir informações estruturadas e semiestruturadas. Ele também permite aplicações analíticas poderosas e interativas em dados históricos e de transmissão.. DataFrames e SQL fornecem uma maneira comum de inserir uma variedade de fontes de dados. Sua principal característica é ser um otimizador baseado em custos e tolerância a falhas de consulta média.
Spark Streaming
É um complemento à API principal do Spark que permite o processamento de fluxo escalável, Fluxos de dados em tempo real de alto desempenho e tolerantes a falhas. Spark Streaming, Agrupar dados em tempo real em pequenos lotes. Em seguida, ele o entrega ao sistema em lotes para processamento.. Ele também fornece recursos de tolerância a falhas.
Spark GraphX:
O GraphX no Spark é uma API para gráficos e execução de gráficos paralelos. É um mecanismo de análise de gráficos de rede e data warehouse. Nos gráficos também é viável agrupar, categorizar, Scooch, Pesquisar e encontrar rotas.
SparkR:
O SparkR fornece uma implementação de estrutura de dados distribuídos. Suporta operações como seleção, filtrado, agregação, mas em grandes conjuntos de dados.
Faísca MLlib:
O Spark MLlib é usado para executar o aprendizado de máquina no Apache Spark. MLlib consiste em algoritmos e utilitários populares. MLlib on Spark é uma biblioteca de aprendizado de máquina escalável que analisa algoritmos de alta qualidade e alta velocidade. Algoritmos de Machine Learning como regressão, classificação, agrupamento, Mineração de padrões e filtragem colaborativa. Primitivas de aprendizado de máquina de nível inferior, como o algoritmo genérico de otimização de descida de gradiente, eles também estão presentes no MLlib.
Spark.ml é a principal API de aprendizado de máquina do Spark. A biblioteca Spark.ml oferece uma API de nível superior criada sobre DataFrames para criar pipelines de ML.
As ferramentas do Spark MLlib são fornecidas abaixo:
- Algoritmos ML
- Caracterização
- Pipelines
- Persistência
- Serviços de utilidade pública
-
Algoritmos ML
Os algoritmos ML formam o núcleo do MLlib. Estes incluem algoritmos de aprendizagem comuns, como a classificação, regressão, Agrupamento e filtragem colaborativos.
MLlib padroniza APIs para ajudar a combinar vários algoritmos em um único pipeline ou fluxo de trabalho. Os principais conceitos são Pipelines de API, Onde o conceito de canalização é inspirado no projeto Scikit-Learn.
Transformador:
Um transformador é um algoritmo que pode transformar um DataFrame em outro DataFrame. Tecnicamente, um transformador implementa um método de transformação (), que converte um DataFrame em outro, geralmente adicionando uma ou mais colunas. Como um exemplo:
Um transformador de recurso pode ter um DataFrame, Ler uma coluna (como um exemplo, texto), atribuí-lo a uma nova coluna (como um exemplo, vetores de feição) e gerar um novo DataFrame com a coluna atribuída anexada.
Um modelo de aprendizagem pode usar um DataFrame, Leia a coluna que contém os vetores de recurso, prever o rótulo para cada vetor de recurso e gerar um novo DataFrame com marcas previstas adicionadas como uma coluna.
Estimador:
Um estimador é um algoritmo que pode ser ajustado a um DataFrame para produzir um transformador.. Tecnicamente, um estimador implementa um método de ajuste (), que aceita um DataFrame e produz um Model, o que é um Transformer. Como um exemplo, um algoritmo de aprendizagem como LogisticRegression é um estimador, e chamar ajuste () treinar um LogisticRegressionModel, que é um Modelo e, por isso, um transformador.
Transformador.transformador () e Estimator.fit () são apátridas. No futuro, Algoritmos com estado podem oferecer suporte a conceitos alternativos.
Cada instância de um transformador ou estimador tem um ID exclusivo, que é útil para especificar parâmetros (descrito abaixo).
-
Caracterização
A caracterização inclui a extração, transformação, Diminuição da dimensionalidade e seleção de recursos.
- A extração de recursos tem tudo a ver com a extração de recursos de dados brutos.
- A transformação de recursos inclui dimensionamento, Renovar ou modificar recursos
- A seleção de recursos envolve a escolha de um subconjunto de recursos indispensáveis de um grande conjunto de recursos.
-
Pipelines:
Uma tubulação encadeia vários transformadores e estimadores para especificar um fluxo de trabalho de ML. Ele também fornece ferramentas para construir, examinar e ajustar pipelines de ML.
No aprendizado de máquina, É comum executar uma sequência de algoritmos para processar e aprender com os dados.. MLlib representa um fluxo de trabalho como um pipeline, que é uma sequência de Estágios de Pipeline (Transformadores e Estimadores) a ser executado em uma ordem específica. Usaremos esse fluxo de trabalho simples como um exemplo de execução nesta seção..
Exemplo: A amostra de pipeline mostrada abaixo pré-processa dados em uma ordem específica da seguinte maneira.:
1. Aplicar o método String Indexer para localizar o índice de colunas categóricas
2. Aplicar codificação OneHot para colunas categóricas
3. Aplicar o indexador de cadeia de caracteres para a coluna “rótulo” da variável de saída
4. VectorAssembler aplica-se a colunas categóricas e numéricas. VectorAssembler é um transformador que combina uma determinada lista de colunas em uma única coluna vetorial.
O fluxo de trabalho do pipeline executará a modelagem de dados na ordem específica acima.
de pyspark.ml.feature importar OneHotEncoderEstimator, Método StringIndexer, VectorAssembler
categoricalColumns = ['emprego', 'conjugal', 'educação', 'padrão', 'habitação', 'empréstimo'] estágios = [] para categoricalCol em categoricalColumns: stringIndexer = StringIndexer(inputCol = categóricoCol, outputCol = categóricoCol + 'Indexador') codificador = OneHotEncoderEstimator(inputCols=[stringIndexer.getOutputCol()], outputCols=[categóricaCol + "Vec"]) estágios += [stringIndexer, codificador] label_stringIdx = StringIndexer(inputCol="depósito", outputCol="rótulo") estágios += [label_stringIdx] numericColumns = ['era', 'equilíbrio', 'duração'] assemblerInputs = [c + "Vec" para c em categoricalColumns] + numericColumns Vassembler = VectorAssembler(inputCols = assemblerInputs, outputCol="recursos") estágios += [Vassembler]from pyspark.ml import Pipeline pipeline = Pipeline(estágios = estágios) pipelineModel = pipeline.fit(df) df = pipelineModel.transform(df) selectedCols = ['rótulo', 'características'] + cols df = df.select(selectedCols)
Quadro de dados
Los marcos de datos proporcionan una API más fácil de utilizar que los RDD. A API baseada em DataFrame para MLlib fornece uma API uniforme em algoritmos de ML e em vários idiomas. As estruturas de dados facilitam pipelines de aprendizado de máquina acionáveis, em particular transformações de recursos.
from pyspark.sql import SparkSession spark = SparkSession.builder.appName('mlearnsample').getOrCreate() df = faísca.read.csv('loan_bank.csv', cabeçalho = Verdadeiro, inferSchema = Verdadeiro) df.printSchema() -
Persistência:
A persistência ajuda a salvar e carregar algoritmos, Modelos e pipelines. Isso ajuda a reduzir o tempo e o esforço, Uma vez que o modelo é persistente, pode ser cobrado / Reutilize a qualquer momento quando necessário.
from pyspark.ml.classification import LogisticRegression lr = LogisticRegression(featuresCol="recursos", labelCol="rótulo") lrModel = lr.fit(Comboio)de pyspark.ml.evaluation import BinaryClassificationEvaluator
avaliador = BinaryClassificationEvaluator ()
imprimir ('Área de teste sob ROC', avaliador.avaliar (previsões))
previsões = lrModel.transform(teste) previsões.selecione('era', 'rótulo', 'rawPrediction', 'predição').exposição() -
Serviços de utilidade pública:
Utilitários para álgebra linear, Estatísticas e gestão de dados. Exemplo: mllib.linalg são os utilitários MLlib para álgebra linear.
Material de referência:
https://spark.apache.org/docs/latest/ml-guide.html
Notas finais
O Spark MLlib é necessário se se trata de big data e aprendizado de máquina. Neste post, aprendeu sobre os detalhes do Spark MLlib, Estruturas de dados e pipelines. No futuro post, trabalharemos em código prático para implementar Pipelines e construir modelos de dados usando MLlib.





