Introdução
Dados e informações na web estão crescendo exponencialmente. Hoje em dia, todos nós usamos o Google como nossa primeira fonte de conhecimento, se deve encontrar comentários sobre um lugar para entender um novo termo. Todas essas informações já estão disponíveis na web.
Com a quantidade de dados disponíveis na web, abre novos horizontes de possibilidades para uma Cientista de dados. Acredito firmemente que o web scraping é uma habilidade obrigatória para qualquer cientista de dados.. No mundo real, todos os dados que você precisa já estão disponíveis na internet; a única coisa que impede você de usá-los é a capacidade de acessá-los. Com a ajuda deste artigo, você também será capaz de superar essa barreira.
A maioria dos dados disponíveis na web não está disponível. Está presente em um formato não estruturado (Formato HTML) e não consigo baixar. Portanto, conhecimento e experiência são necessários para usar esses dados para, eventualmente, construir um modelo útil.
Neste artigo, vou orientá-lo através do processo de web scraping em R. com este item, você ganhará experiência para usar qualquer tipo de dado disponível na internet.
Tabela de conteúdo
- O que é Web Scraping?
- Por que precisamos de Web Scraping em Ciência de dados?
- Maneiras de extrair dados
- Pré-requisitos
- Raspando una página web usando R
- Analise dados extraídos da web
1. O que é Web Scraping?
Web scraping é uma técnica para converter os dados presentes em formato não estruturado (Tags HTML) na web para um formato estruturado que pode ser facilmente acessado e usado.
Quase todos os principais idiomas fornecem maneiras de realizar a raspagem da web. Neste artigo, usaremos R para extrair os dados dos longas-metragens mais populares de 2016 do IMDb site web.
Obteremos uma série de funções para cada uma das 100 filmes populares lançados em 2016. O que mais, Analisaremos os problemas mais comuns que podem ocorrer ao extrair dados da Internet devido a inconsistências no site.. código e veja como resolver esses problemas.
Se você se sentir mais confortável usando Python, Eu recomendo que você leia este guia para começar a raspagem da web com Python.
2. Por que precisamos de Web Scraping?
Tenho certeza de que as primeiras perguntas que devem ter surgido na sua cabeça agora são “Por que precisamos de raspagem na web”? Como eu disse antes, as possibilidades com web scraping são imensas.
Para lhe dar conhecimento prático, vamos extrair dados do IMDB. Alguns outros aplicativos possíveis para os quais você pode usar a raspagem da web são:
- Extraia dados de classificação de filmes para criar mecanismos de recomendação de filmes.
- Extraer datos de texto de Wikipedia y otras fuentes para crear sistemas basados en PNL o entrenar modelos de aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde... para tareas como el reconocimiento de temas del texto dado.
- Extraia dados de imagens marcadas de sites como o Google, Flickr, etc. treinar modelos de classificação de imagens.
- Coleta de dados de sites de redes sociais como Facebook e Twitter para realizar tarefas de análise de sentimentos, mineração de opinião, etc.
- Extraia avaliações e comentários de usuários de sites de comércio eletrônico como a Amazon, Flipkart, etc.
3. Maneiras de extrair dados
Existem várias maneiras de extrair dados da web. Algumas das formas populares são:
- Copie e cole humanos: Esta é uma maneira lenta e eficiente de extrair dados da web. Isso envolve os próprios humanos analisando e copiando os dados para armazenamento local.
- Correspondência de padrões de texto: Outra abordagem simples, mas poderosa, para extrair informações da web é usar as funções de correspondência de expressões regulares das linguagens de programação.. Você pode aprender mais sobre expressões regulares aqui.
- Interface da API: Muitos sites como o Facebook, Twitter, LinkedIn, etc. fornecer APIs públicas e / ou privado que pode ser chamado usando código padrão para recuperar os dados no formato prescrito.
- Análise DOM: Usando navegadores da web, programas podem recuperar conteúdo dinâmico gerado por scripts do lado do cliente. Também é possível analisar páginas da Web em uma árvore DOM, dependendo dos programas que podem recuperar partes dessas páginas.
Usaremos a abordagem de análise do DOM ao longo deste artigo.. E confie nos seletores CSS da página da web para encontrar os campos relevantes que contêm as informações desejadas. Mas antes de começarmos, existem alguns pré-requisitos necessários para extrair dados de qualquer site com competência.
4. Requisitos anteriores
Os pré-requisitos para realizar a raspagem da web em R se dividem em dois grupos:
- Para começar com a raspagem da web, deve ter conhecimento prático da linguagem R. Se você está apenas começando ou quer aprimorar o básico, Eu recomendo seguir este caminho de aprendizado em R. Ao longo deste artigo, vamos usar o pacote 'rvest’ em R escrito por Hadley Wickham. Você pode acessar a documentação do pacote rvest aqui. Certifique-se de ter este pacote instalado. Se você ainda não tem este pacote, você pode seguir o código abaixo para instalá-lo.
install.packages('rvest')
- Adicionar conhecimento de HTML e CSS será um bônus adicional. Uma das melhores fontes que encontrei para aprender HTML e CSS é Está. Observei que a maioria dos cientistas de dados não é muito forte com conhecimento técnico de HTML e CSS. Portanto, usaremos um software de código aberto chamado Selector Gadget que será mais que suficiente para qualquer pessoa fazer web scraping. Você pode acessar e baixar a extensão Selector Gadget aqui. Certifique-se de ter esta extensão instalada seguindo as instruções no site. Eu fiz o mesmo. Estou usando o Google Chrome e posso acessar a extensão na barra de extensão no canto superior direito.
Com isto, você pode selecionar as partes de qualquer site e obter as tags relevantes para acessar essa parte simplesmente clicando nessa parte do site. Observe que esta é uma maneira de aprender HTML e CSS e fazê-lo manualmente. Mas para dominar a arte de raspagem da web, Eu recomendo muito que você aprenda HTML e CSS para entender melhor e apreciar o que está acontecendo sob o capô.
4. Raspando uma página web com R
Agora, vamos começar a olhar no site do IMDb para 100 filmes mais populares lançados em 2016. Você pode acessá-los aqui.
#Loading the rvest package library('rvest') #Specifying the url for desired website to be scraped url <- 'http://www.imdb.com/search/title?conde=100&release_date=2016.2016&title_type=feature' #Reading the HTML code from the website webpage <- read_html(url)
Agora, vamos extrair os seguintes dados deste site.
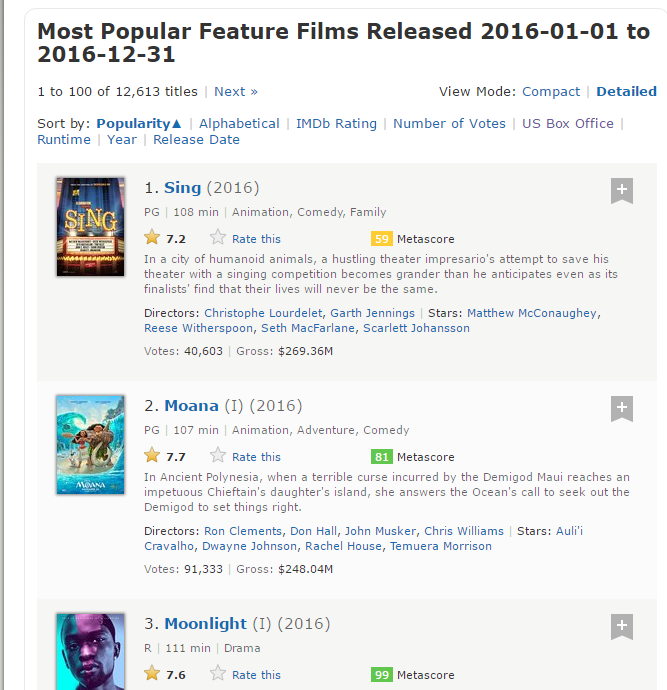
- Classificação: A gama do filme de 1 uma 100 na lista de 100 filmes mais populares lançados em 2016.
- Título: O título do longa-metragem.
- Descrição: A descrição do longa-metragem.
- Runtime: A duração do longa-metragem.
- Gênero: O gênero do longa-metragem,
- Classificação: A classificação IMDb do longa-metragem.
- Metascore: O metascore no site do IMDb para o longa-metragem.
- Votos: Votos a favor do longa-metragem.
- Gross_Revenue_in_Thousand: Ganhos brutos de longas-metragens em milhões.
- Diretor: O diretor principal do longa-metragem. tenha em conta que, no caso de vários diretores, vou pegar só o primeiro.
- Ator: O ator principal do filme. tenha em conta que, no caso de vários atores, vou pegar só o primeiro.
Aqui está uma captura de tela contendo como todos esses campos estão organizados.
Paso 1: Agora, vamos começar raspando o campo Range. Para isso, usaremos o gadget seletor para obter os seletores CSS específicos que incluem as classificações. Você pode clicar na extensão em seu navegador e selecionar o campo de classificação com o cursor.
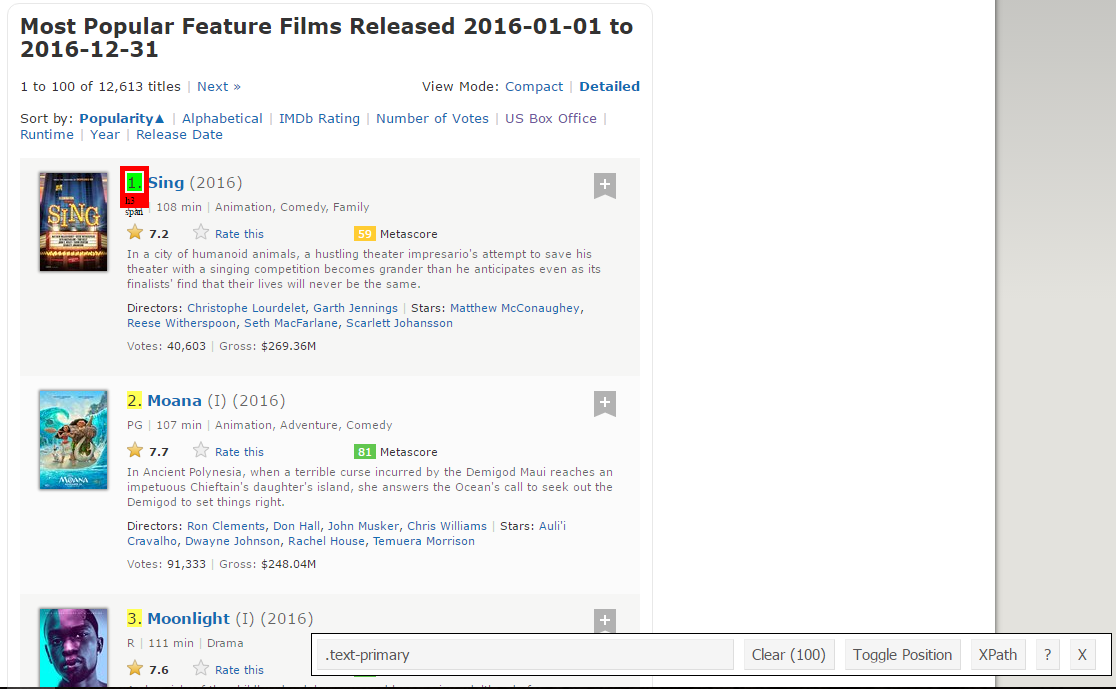
Certifique-se de que todas as classificações estão selecionadas. Você pode selecionar mais algumas seções de classificação no caso de não conseguir todas e também pode desmarque-as clicando na seção selecionada para ter certeza de que você só tem as seções destacadas que deseja raspar até lá.. .
Paso 2: Uma vez que você tenha certeza de que fez as seleções corretas, você deve copiar o seletor css correspondente que você pode ver no centro inferior.
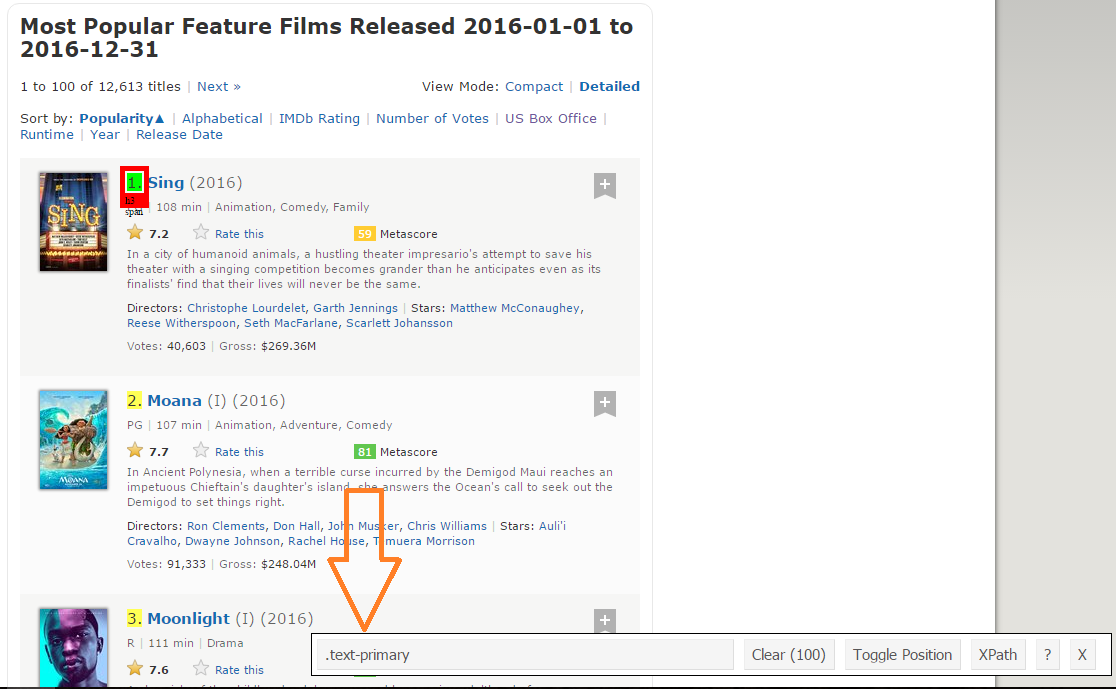
Paso 3: Uma vez que você conhece o seletor CSS que contém as classificações, você pode usar este código R simples para obter todas as classificações:
#Using CSS selectors to scrape the rankings section rank_data_html <- html_nodes(página web,'.text-primary') #Converting the ranking data to text rank_data <- html_text(rank_data_html) #Let's have a look at the rankings head(rank_data) [1] "1." "2." "3." "4." "5." "6."
Paso 4: Uma vez que você tem os dados, certifique-se de que eles são vistos no formato desejado. Estou pré-transformando meus dados para convertê-lo em formato numérico.
#Pré-processamento de dados: Converting rankings to numerical rank_data<-como.numérico(rank_data) #Let's have another look at the rankings head(rank_data) [1] 1 2 3 4 5 6
Paso 5: Agora você pode limpar a seção seletor e selecionar todos os títulos. você pode inspecionar visualmente que todos os títulos são selecionados. Faça as adições e exclusões necessárias com a ajuda do seu cursor. Eu fiz a mesma coisa aqui..
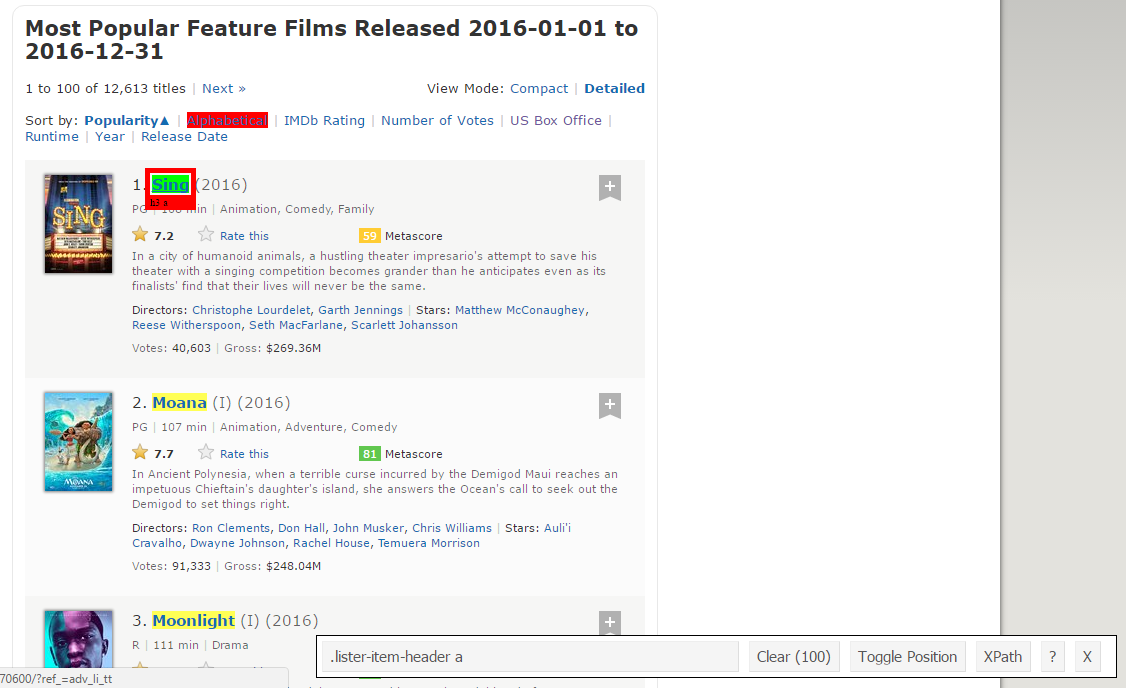
Paso 6: Novamente, Eu tenho o seletor CSS correspondente para títulos: .lister-item-cabeçalho um. Usaré este seletor para raspar todos los títulos usando el siguiente código.
#Using CSS selectors to scrape the title section title_data_html <- html_nodes(página web,'.lister-item-header a') #Converting the title data to text title_data <- html_text(title_data_html) #Let's have a look at the title head(title_data) [1] "Cantar" "Rio Moana" "Luar" "Cordilheira Hacksaw" [5] "Passageiros" "Trolls"
Paso 7: No seguinte código, hecho lo mismo para el raspado: Descrição, tempo de execução, Gênero sexual, qualificação, metapuntuacion, votos, ingresos brutos en mil, datos de diretor y ator.
#Using CSS selectors to scrape the description section description_data_html <- html_nodes(página web,'.ratings-bar+ .text-muted') #Converting the description data to text description_data <- html_text(description_data_html) #Let's have a look at the description data head(description_data) [1] "nEm uma cidade de animais humanoides, a tentativa de um empresário de teatro apressado de salvar seu teatro com uma competição de canto torna-se mais grandiosa do que ele antecipa, mesmo quando seus finalistas descobrem que suas vidas nunca mais serão as mesmas." [2] "nNa Polinésia Antiga, quando uma terrível maldição incorrida pelo semideus Maui atinge a ilha da filha de um impetuoso Chieftain, ela responde ao chamado do Oceano para procurar o Semideus para acertar as coisas." [3] "nUma crônica da infância, adolescência e a idade adulta florescente de um jovem, Afro-americano, gay crescendo em um bairro violento de Miami." [4] "nWWII Médico do Exército Americano Desmond T. Doss, que serviu durante a Batalha de Okinawa, se recusa a matar pessoas, e se torna o primeiro homem na história americana a receber a Medalha de Honra sem disparar um tiro." [5] "nA nave espacial viajando para um planeta colônia distante e transportando milhares de pessoas tem um defeito em suas câmaras de sono. Como resultado, dois passageiros são despertados 90 anos antes." [6] "nDepois que os Bergens invadem a Vila Troll, Papoula, o Troll mais feliz já nascido, eo ramo curmudgeonly partiu em uma jornada para resgatar seus amigos. #Pré-processamento de dados: removing 'n' description_data<-gsub("n","",description_data) #Let's have another look at the description data head(description_data) [1] "Em uma cidade de animais humanoides, a tentativa de um empresário de teatro apressado de salvar seu teatro com uma competição de canto torna-se mais grandiosa do que ele antecipa, mesmo quando seus finalistas descobrem que suas vidas nunca mais serão as mesmas." [2] "Na Polinésia Antiga, quando uma terrível maldição incorrida pelo semideus Maui atinge a ilha da filha de um impetuoso Chieftain, ela responde ao chamado do Oceano para procurar o Semideus para acertar as coisas." [3] "Uma crônica da infância, adolescência e a idade adulta florescente de um jovem, Afro-americano, gay crescendo em um bairro violento de Miami." [4] "Médico do Exército Americano da Segunda Guerra Mundial Desmond T. Doss, que serviu durante a Batalha de Okinawa, se recusa a matar pessoas, e se torna o primeiro homem na história americana a receber a Medalha de Honra sem disparar um tiro." [5] "Uma nave espacial viajando para um planeta colônia distante e transportando milhares de pessoas tem um defeito em suas câmaras de sono. Como resultado, dois passageiros são despertados 90 anos antes." [6] "Depois que os Bergens invadem a Vila Troll, Papoula, o Troll mais feliz já nascido, e o ramo curmudgeonly partiu em uma jornada para resgatar seus amigos." #Using CSS selectors to scrape the Movie runtime section runtime_data_html <- html_nodes(página web,'.text-muted .runtime') #Converting the runtime data to text runtime_data <- html_text(runtime_data_html) #Let's have a look at the runtime head(runtime_data) [1] "108 min" "107 min" "111 min" "139 min" "116 min" "92 min" #Pré-processamento de dados: removing mins and converting it to numerical runtime_data<-gsub(" min","",runtime_data) runtime_data<-como.numérico(runtime_data) #Let's have another look at the runtime data head(runtime_data) [1] 1 2 3 4 5 6 #Using CSS selectors to scrape the Movie genre section genre_data_html <- html_nodes(página web,'.gênero') #Converting the genre data to text genre_data <- html_text(genre_data_html) #Let's have a look at the runtime head(genre_data) [1] "nAnimation, Comédia, Família " [2] "nAnimation, Aventura, Comédia " [3] "nDrama " [4] "nBiografia, Drama, História " [5] "nAdventure, Drama, Romance " [6] "nAnimation, Aventura, Comédia " #Pré-processamento de dados: removing n genre_data<-gsub("n","",genre_data) #Pré-processamento de dados: removing excess spaces genre_data<-gsub(" ","",genre_data) #taking only the first genre of each movie genre_data<-gsub(",.*","",genre_data) #Convering each genre from text to factor genre_data<-as.fator(genre_data) #Let's have another look at the genre data head(genre_data) [1] Animação animação drama de aventura animação aventura 10 Níveis: Action Adventure Animation Biography Comedy Crime Drama ... Thriller #Using CSS selectors to scrape the IMDB rating section rating_data_html <- html_nodes(página web,'.ratings-imdb-rating forte') #Converting the ratings data to text rating_data <- html_text(rating_data_html) #Let's have a look at the ratings head(rating_data) [1] "7.2" "7.7" "7.6" "8.2" "7.0" "6.5" #Pré-processamento de dados: converting ratings to numerical rating_data<-como.numérico(rating_data) #Let's have another look at the ratings data head(rating_data) [1] 7.2 7.7 7.6 8.2 7.0 6.5 #Using CSS selectors to scrape the votes section votes_data_html <- html_nodes(página web,'.num_votes-visível:nth-criança(2)') #Converting the votes data to text votes_data <- html_text(votes_data_html) #Let's have a look at the votes data head(votes_data) [1] "40,603" "91,333" "112,609" "177,229" "148,467" "32,497" #Pré-processamento de dados: removing commas votes_data<-gsub(",","",votes_data) #Pré-processamento de dados: converting votes to numerical votes_data<-como.numérico(votes_data) #Let's have another look at the votes data head(votes_data) [1] 40603 91333 112609 177229 148467 32497 #Using CSS selectors to scrape the directors section directors_data_html <- html_nodes(página web,'.text-muted+ p a:nth-criança(1)') #Converting the directors data to text directors_data <- html_text(directors_data_html) #Let's have a look at the directors data head(directors_data) [1] "Christophe Lourdelet" "Ron Clements" "Barry Jenkins" [4] "Mel Gibson" "Morten Tyldum" "Walt Dohrn" #Pré-processamento de dados: converting directors data into factors directors_data<-as.fator(directors_data) #Using CSS selectors to scrape the actors section actors_data_html <- html_nodes(página web,'.lister-item-content .ghost+ a') #Converting the gross actors data to text actors_data <- html_text(actors_data_html) #Let's have a look at the actors data head(actors_data) [1] "Matthew McConaughey" "Auli'i Cravalho" "Mahershala Ali" [4] "Andrew Garfield" "Jennifer Lawrence" "Anna Kendrick" #Pré-processamento de dados: converting actors data into factors actors_data<-as.fator(actors_data)
Pero quiero que siga de cerca lo que sucede cuando hago lo mismo con los datos de Metascore.
#Using CSS selectors to scrape the metascore section metascore_data_html <- html_nodes(página web,'.metascore') #Converting the runtime data to text metascore_data <- html_text(metascore_data_html) #Let's have a look at the metascore data head(metascore_data) [1] "59 " "81 " "99 " "71 " "41 " [6] "56 " #Pré-processamento de dados: removing extra space in metascore metascore_data<-gsub(" ","",metascore_data) #Lets check the length of metascore data length(metascore_data) [1] 96
Paso 8: O comprimento dos dados metascore é 96 enquanto estamos raspando os dados de 100 Filmes. A razão pela qual isso aconteceu é que há 4 filmes que não têm os campos Metascore correspondentes.
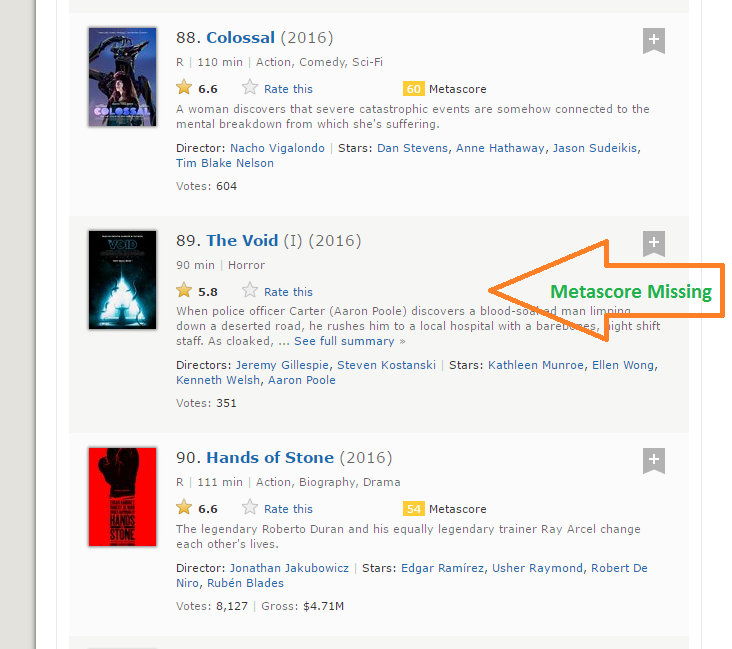
Paso 9: É uma situação prática que pode surgir ao raspar qualquer site. Infelizmente, se simplesmente adicionar NA ao mais recente 4 ingressos, NA será designado como Metascore para filmes 96 uma 100, enquanto, na verdade,, dados perdidos para alguns outros filmes. Após uma inspeção visual, Descobri que metascore estava faltando para filmes 39, 73, 80 e 89. Eu escrevi o seguinte recurso para corrigir este problema.
para (i em c(39,73,80,89)){
uma<-metascore_data[1:(i-1)]
b<-metascore_data[eu:comprimento(metascore_data)]
metascore_data<-acrescentar(uma,Lista("N / D"))
metascore_data<-acrescentar(metascore_data,b)
}
#Pré-processamento de dados: converting metascore to numerical
metascore_data<-como.numérico(metascore_data)
#Let's have another look at length of the metascore data
length(metascore_data)
[1] 100
#Let's look at summary statistics
summary(metascore_data)
Mín.. 1st Qu. Média Mediana 3º Qu. Máx.. Na's
23.00 47.00 60.00 60.22 74.00 99.00 4
Paso 10: Lo mismo sucede con la variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... Bruto que representa los ingresos brutos de esa película en millones. Ele usado la misma solución para trabajar a mi manera:
#Using CSS selectors to scrape the gross revenue section gross_data_html <- html_nodes(página web,'.ghost~ .text-muted+ span') #Converting the gross revenue data to text gross_data <- html_text(gross_data_html) #Let's have a look at the votes data head(gross_data) [1] "$269.36M" "$248.04M" "$27.50M" "$67.12M" "$99.47M" "$153.67M" #Pré-processamento de dados: removing '$' and 'M' signs gross_data<-gsub("M","",gross_data) gross_data<-Subsequência(gross_data,2,6) #Let's check the length of gross data length(gross_data) [1] 86 #Filling missing entries with NA for (i em c(17,39,49,52,57,64,66,73,76,77,80,87,88,89)){ uma<-gross_data[1:(i-1)] b<-gross_data[eu:comprimento(gross_data)] gross_data<-acrescentar(uma,Lista("N / D")) gross_data<-acrescentar(gross_data,b) } #Pré-processamento de dados: converting gross to numerical gross_data<-como.numérico(gross_data) #Let's have another look at the length of gross data length(gross_data) [1] 100 resumo(gross_data) Mín.. 1st Qu. Média Mediana 3º Qu. Máx.. Na's 0.08 15.52 54.69 96.91 119.50 530.70 14
Paso 11: Ahora hemos eliminado con éxito las 11 termos de las 100 filmes mais populares lançados em 2016. Combinémoslas para crear un marco de datos e inspeccionar su estructura.
#Combining all the lists to form a data frame movies_df<-quadro de dados(Classificação = rank_data, Título = title_data, Descrição = description_data, Tempo de execução = runtime_data, Gênero = genre_data, Classificação = rating_data, Metascore = metascore_data, Votos = votes_data, Gross_Earning_in_Mil = gross_data, Diretor = directors_data, Ator = actors_data) #Structure of the data frame str(movies_df) 'data.frame': 100 obs. do 11 variáveis: $ Classificação : num 1 2 3 4 5 6 7 8 9 10 ... $ Título : Fator c/ 99 Níveis "10 Cloverfield Lane",..: 66 53 54 32 58 93 8 43 97 7 ... $ Descrição : Fator c/ 100 Níveis "19-billy lynn de ano de idade é trazido para casa para uma turnê de vitória depois de uma batalha angustiante iraque. Através de flashbacks o filme mostra o que"| __truncated__,..: 57 59 3 100 21 33 90 14 13 97 ... $ Tempo de execução : num 108 107 111 139 116 92 115 128 111 116 ... $ Gênero : Fator c/ 10 Níveis "Ação","Aventura",..: 3 3 7 4 2 3 1 5 5 7 ... $ Classificação : num 7.2 7.7 7.6 8.2 7 6.5 6.1 8.4 6.3 8 ... $ Metascore : num 59 81 99 71 41 56 36 93 39 81 ... $ Votos : num 40603 91333 112609 177229 148467 ... $ Gross_Earning_in_Mil: num 269.3 248 27.5 67.1 99.5 ... $ Diretor : Fator c/ 98 Níveis "Andrew Stanton",..: 17 80 9 64 67 95 56 19 49 28 ... $ Ator : Fator c/ 86 Níveis "Aaron Eckhart",..: 59 7 56 5 42 6 64 71 86 3 ...
Você agora raspou com sucesso o site do IMDb para o 100 filmes mais populares lançados em 2016.
6. Analise dados extraídos da Web
Uma vez que você tem os dados, pode executar várias tarefas, como analisar os dados, fazer inferências a partir deles, treinar modelos de aprendizado de máquina nesses dados, etc. Continuei a criar uma visualização interessante a partir dos dados que acabamos de extrair. Siga as visualizações e responda às perguntas abaixo. Poste suas respostas na seção de comentários abaixo.
biblioteca('ggplot2')
qplot(dados = filmes_df,Tempo de execução,preencher = Gênero,bins = 30)
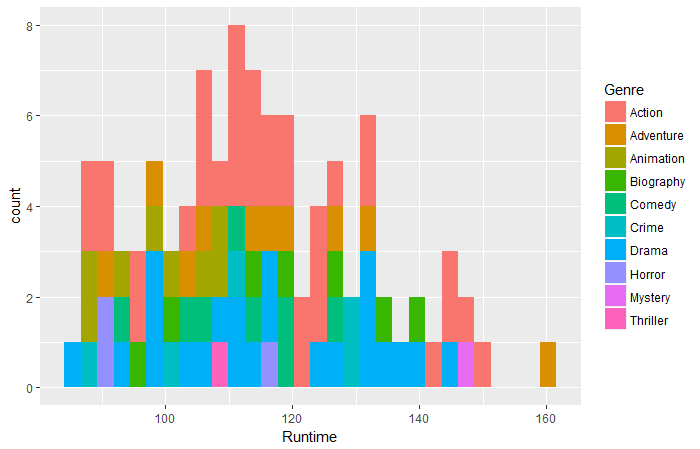
Pergunta 1: De acordo com os dados acima, qual filme de qual gênero teve o maior tempo de execução?
ggplot(movies_df,aes(x=Tempo de execução,y=Classificação))+ geom_point(aes(tamanho=votos,col=Gênero))
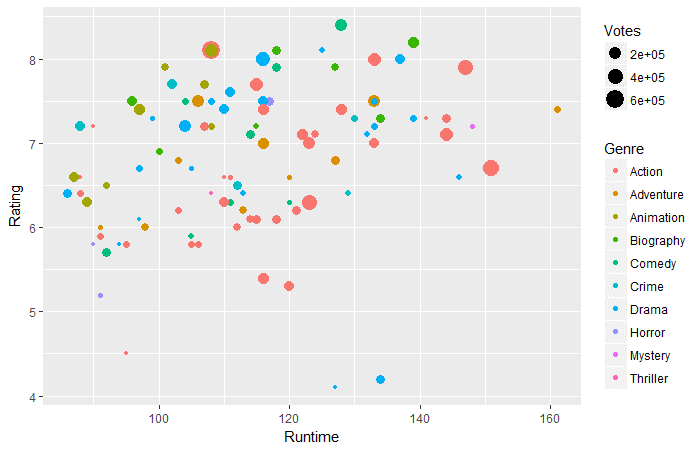
Pergunta 2: De acordo com os dados acima, em tempo de execução 130-160 minutos, qual gênero tem mais votos?
ggplot(movies_df,aes(x=Tempo de execução,y=Gross_Earning_in_Mil))+ geom_point(aes(tamanho=Classificação,col=Gênero))
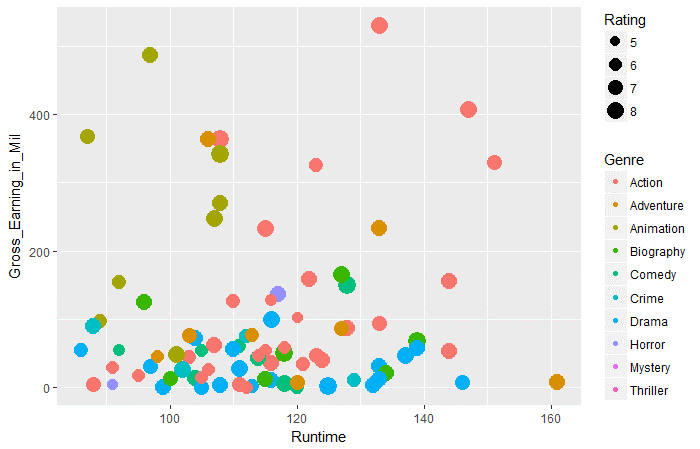
Pergunta 3: De acordo com os dados acima, em todos os gêneros, qual gênero tem os maiores ganhos brutos médios em tempo de execução de 100 uma 120.
Notas finais
Eu acho que este artigo teria lhe dado uma compreensão completa do web scraping em R. Agora, você também tem uma ideia clara dos problemas que pode encontrar e como pode corrigi-los. Como a maioria dos dados na web está presente em um formato não estruturado, web scraping é uma habilidade muito útil para qualquer cientista de dados.
O que mais, você pode postar as respostas para as três perguntas acima na seção de comentários abaixo. Você gostou de ler este artigo? Compartilhe suas opiniões comigo. Se você tiver alguma dúvida / pergunta, fique a vontade para enviar abaixo.





