Introdução
O aprendizado profundo está ganhando força rapidamente à medida que mais e mais trabalhos de pesquisa surgem de todo o mundo.. Com certeza, esses documentos contêm muitas informações, mas muitas vezes podem ser difíceis de analisar. E para entendê-los, você pode ter que revisar aquele documento várias vezes (E talvez até outros documentos dependentes!).
Esta é uma tarefa realmente assustadora para não acadêmicos como nós..

Pessoalmente, Acho que a tarefa de revisar um artigo de pesquisa, interpretar o ponto crucial por trás dele e implementar o código como uma habilidade importante que todo entusiasta e praticante de aprendizado profundo deve possuir. A implementação prática de ideias de pesquisa traz à tona o processo de pensamento do autor e também ajuda a transformar essas ideias em aplicações da indústria do mundo real..
Então, neste artigo (e a seguinte série de artigos) minha razão para escrever é dupla:
- Deixe os leitores se manterem atualizados com pesquisas de ponta, dividindo artigos de aprendizagem profunda em conceitos compreensíveis.
- Aprenda a transformar ideias de pesquisa em código para mim e incentive as pessoas a fazerem isso simultaneamente.
Este artigo pressupõe que você tenha um bom conhecimento dos princípios básicos do aprendizado profundo.. Caso você não precise, ou apenas precisa de uma atualização, verifique os itens abaixo primeiro e depois volte aqui em breve:
Tabela de conteúdo
- Resumo do Documento “Aprofunde-se nas convoluções”
- Objetivo do trabalho
- Detalhes arquitetônicos propostos
- Metodologia de treinamento
- Implementação GoogLeNet em Keras
Resumo do Documento “Aprofunde-se nas convoluções”
Este artigo se concentra no papel “Aprofunde-se com as convoluções” de onde veio a ideia distintiva da homenet. A rede doméstica já foi considerada uma arquitetura (o modelo) Aprendizado profundo de última geração para resolver problemas de reconhecimento e detecção de imagens.
Apresentou desempenho inovador no Desafio de Reconhecimento Visual ImageNet (sobre 2014), que é uma plataforma de renome para benchmarking de reconhecimento de imagem e algoritmos de detecção. junto com isso, muitas pesquisas foram iniciadas na criação de novas arquiteturas de aprendizagem profunda com ideias inovadoras e impactantes.
Vamos revisar as principais idéias e sugestões propostas no documento mencionado acima e tentar entender as técnicas que ele contém. Nas palavras do autor:
“Neste artigo, vamos nos concentrar em uma arquitetura de rede neural profunda eficiente para visão computacional, cujo codinome é Inception, que deriva seu nome de (…) o famoso meme da internet” precisamos ir mais fundo “.

Isso soa intrigante, não? Nós vamos, Continue lendo então!
Objetivo do trabalho
Existe uma maneira simples, mas poderosa de criar melhores modelos de aprendizado profundo. Você pode simplesmente fazer um modelo maior, seja em termos de profundidade, quer dizer, número de camadas, ou o número de neurônios em cada camada. Mas como você pode imaginar, isso muitas vezes pode criar complicações:
- Quanto maior o modelo, mais propenso a ajustes excessivos. Isso é particularmente perceptível quando os dados de treinamento são pequenos..
- Aumentar o número de parâmetros significa que você precisa aumentar seus recursos computacionais existentes
Uma solução para isso, como o documento sugere, é mudar para arquiteturas de rede fracamente conectadas que irão substituir as arquiteturas de rede totalmente conectadas, especialmente dentro de camadas convolucionais. Essa ideia pode ser conceituada nas seguintes imagens:
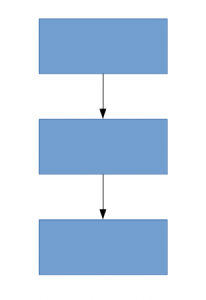
Arquitetura densamente conectada
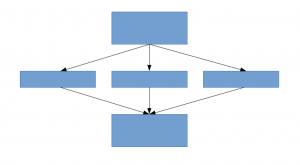
Arquitetura escassamente conectada
Este artigo propõe uma nova ideia de criação de arquiteturas profundas. Esta abordagem permite que você mantenha “orçamento computacional”, enquanto aumenta a profundidade e largura da rede. Parece bom demais para ser verdade! É assim que a ideia conceituada se parece:
Vejamos a arquitetura proposta com um pouco mais de detalhes.
Detalhes arquitetônicos propostos
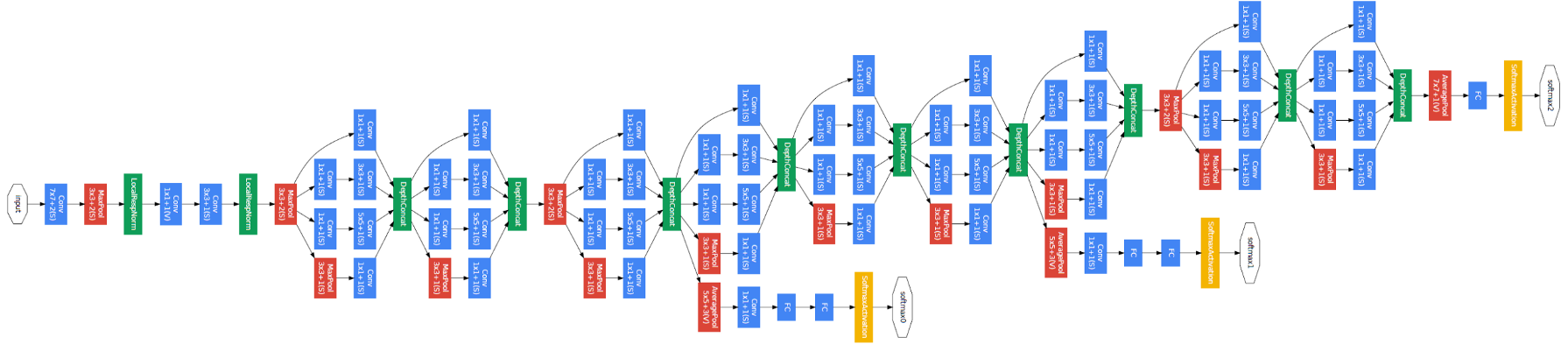
O documento propõe um novo tipo de arquitetura: GoogLeNet o Inception v1. É basicamente uma rede neural convolucional (CNN) o que tem 27 camadas profundas.. Abaixo está o resumo do modelo:

Observe na imagem acima que há uma camada chamada camada inicial. Esta é realmente a ideia principal por trás do foco do documento. A camada inicial é o conceito central de uma arquitetura fracamente conectada.
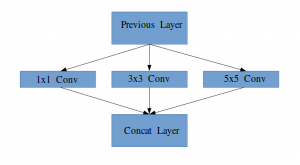
Idéia de um módulo inicial
Deixe-me explicar um pouco mais detalhadamente sobre o que é uma camada de inicialização. Pegando um trecho do artigo:
“(Camada inicial) é uma combinação de todas essas camadas (quer dizer, capa convolucional 1 × 1, capa convolucional 3 × 3, capa convolucional 5 × 5) com seus bancos de filtros de saída concatenados em um único vetor de saída que forma a entrada do cenário a seguir.”
Junto com as camadas mencionadas acima, existem dois plugins principais na camada inicial original:
- Capa convolucional 1 × 1 antes de aplicar outra camada, que é usado principalmente para redução de dimensionalidade
- Uma camada de agrupamento máximo paralela, que fornece outra opção para a camada inicial
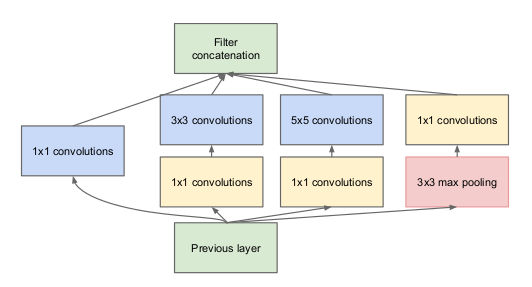
Camada inicial
Para entender a importância da estrutura da camada inicial, o autor baseia-se no princípio Hebbian de aprendizagem humana. Isso diz que “neurônios que disparam juntos, eles se conectam”. O autor sugere que Ao criar uma camada de postagem em um modelo de aprendizado profundo, deve-se prestar atenção ao aprendizado da camada anterior.
Suponha, por exemplo, que uma camada de nosso modelo de aprendizado profundo aprendeu a se concentrar em partes individuais de um rosto. A próxima camada da rede provavelmente se concentraria na face geral da imagem para identificar os diferentes objetos presentes lá. Agora, para fazer isso, a camada deve ter os tamanhos de filtro apropriados para detectar objetos diferentes.
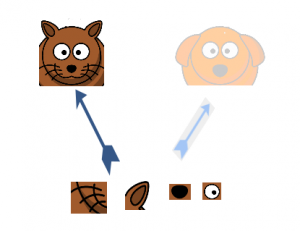
É aqui que a camada inicial vem à tona. Permite que as camadas internas escolham qual tamanho de filtro será relevante para saber as informações necessárias. Então, mesmo que o tamanho do rosto na foto seja diferente (como pode ser visto nas fotos abaixo), a capa funciona de acordo para reconhecer o rosto. Para a primeira imagem, você provavelmente precisaria de um tamanho de filtro maior, enquanto eu pegaria um menor para a segunda imagem.

Arquitetura geral, com todas as especificações, Se parece com isso:
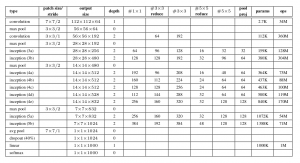
Metodologia de treinamento
Observe que essa arquitetura surgiu em grande parte porque os autores participaram de um desafio de detecção e reconhecimento de imagens.. Portanto, há muitos “sinos e assobios” que eles explicaram no documento. Esses incluem:
- O hardware que eles usaram para treinar os modelos.
- A técnica de aumento de dados para criar o conjunto de dados de treinamento.
- Os hiperparâmetros da rede neural, como a técnica de otimização e o programa de taxa de aprendizagem.
- Treinamento auxiliar necessário para treinar o modelo.
- Técnicas de montagem que eles usaram para construir a apresentação final.
Entre estes, o treinamento auxiliar realizado pelos autores é bastante interessante e inovador por natureza. Portanto, vamos nos concentrar nisso por enquanto.. Os detalhes do resto das técnicas podem ser retirados do próprio artigo, ou na implementação que veremos abaixo.
Para evitar que a parte intermediária da rede "desapareça", os autores introduziram dois classificadores auxiliares (os quadrados roxos na imagem). Basicamente, aplicou softmax às saídas de dois dos módulos de partida e calculou uma perda auxiliar nas mesmas etiquetas. A função de perda total é uma soma ponderada da perda auxiliar e a perda real. O valor do peso usado no papel foi 0,3 para cada perda auxiliar.
Implementação GoogLeNet em Keras
Agora que você entendeu a arquitetura GoogLeNet e a intuição por trás dela, É hora de iniciar o Python e implementar nossos aprendizados usando Keras!! Usaremos o conjunto de dados CIFAR-10 para esta finalidade.

CIFAR-10 é um conjunto de dados de classificação de imagem popular. Isso consiste de 60.000 Imagens de 10 aulas (cada classe é representada como uma linha na imagem acima). O conjunto de dados é dividido em 50.000 imagens de treinamento e 10.000 imagens de teste.
Lembre-se de que você deve ter as bibliotecas necessárias instaladas para implementar o código que veremos nesta seção. Isso inclui Keras e TensorFlow (como back-end para Keras). Você pode verificar o guia oficial de instalação caso você ainda não tenha o Keras instalado em sua máquina.
Agora que cuidamos dos pré-requisitos, podemos finalmente começar a codificar a teoria que cobrimos nas seções anteriores. A primeira coisa que devemos fazer é importar todas as bibliotecas e módulos necessários que usaremos em todo o código.
importar duro
a partir de hard.layers.core importar Camada
importar keras.backend Como K
importar tensorflow Como tf
a partir de hard.datasets importar cifar10
a partir de hard.models importar Modelo
a partir de hard.layers importar Conv2D, MaxPool2D,
Cair fora, Denso, Entrada, concatenar,
GlobalA AveragePooling2D, AveragePooling2D,
Achatar
importar cv2
importar entorpecido Como por exemplo
a partir de hard.datasets importar cifar10
a partir de duro importar Processo interno Como K
a partir de hard.utils importar np_utils
importar matemática
a partir de hard.optimizers importar SGD
a partir de loud.callbacks importar LearningRateScheduler
Então vamos carregar o conjunto de dados e fazer algumas etapas de pré-processamento. Esta é uma tarefa crítica antes que o modelo de aprendizado profundo seja treinado.
num_classes = 10
def load_cifar10_data(img_rows, img_cols):
# Carregar conjuntos de treinamento e validação cifar10
(X_train, Y_train), (X_valid, Y_valid) = cifar10.Carregar dados()
# Redimensionar imagens de treinamento
X_train = por exemplo.variedade([cv2.redimensionar(img, (img_rows,img_cols)) para img no X_train[:,:,:,:]])
X_valid = por exemplo.variedade([cv2.redimensionar(img, (img_rows,img_cols)) para img no X_valid[:,:,:,:]])
# Transforme alvos em formato compatível com keras
Y_train = np_utils.to_categorical(Y_train, num_classes)
Y_valid = np_utils.to_categorical(Y_valid, num_classes)
X_train = X_train.astype('float32')
X_valid = X_valid.astype('float32')
# dados de pré-processamento
X_train = X_train / 255.0
X_valid = X_valid / 255.0
Retorna X_train, Y_train, X_valid, Y_valid
X_train, y_train, X_test, y_test = load_cifar10_data(224, 224)
Agora, vamos definir nossa arquitetura de aprendizado profundo. Vamos definir rapidamente uma função para fazer isso, naquela, quando você recebe as informações necessárias, retorna toda a camada inicial.
def inception_module(x,
filtros_1x1,
filtros_3x3_reduce,
filtros_3x3,
filtros_5x5_reduce,
filtros_5x5,
filtros_pool_proj,
nome=Nenhum):
conv_1x1 = Conv2D(filtros_1x1, (1, 1), preenchimento='mesmo', ativação='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(x)
conv_3x3 = Conv2D(filtros_3x3_reduce, (1, 1), preenchimento='mesmo', ativação='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(x)
conv_3x3 = Conv2D(filtros_3x3, (3, 3), preenchimento='mesmo', ativação='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(conv_3x3)
conv_5x5 = Conv2D(filtros_5x5_reduce, (1, 1), preenchimento='mesmo', ativação='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(x)
conv_5x5 = Conv2D(filtros_5x5, (5, 5), preenchimento='mesmo', ativação='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(conv_5x5)
pool_proj = MaxPool2D((3, 3), passos largos=(1, 1), preenchimento='mesmo')(x)
pool_proj = Conv2D(filtros_pool_proj, (1, 1), preenchimento='mesmo', ativação='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(pool_proj)
saída = concatenar([conv_1x1, conv_3x3, conv_5x5, pool_proj], eixo=3, nome=nome)
Retorna saída
Em seguida, vamos criar a arquitetura GoogLeNet, como mencionado no documento.
kernel_init = duro.inicializadores.glorot_uniform()
bias_init = duro.inicializadores.Constante(valor=0.2)
camada_de_entrada = Entrada(forma=(224, 224, 3))
x = Conv2D(64, (7, 7), preenchimento='mesmo', passos largos=(2, 2), ativação='relu', nome='conv_1_7x7 / 2', kernel_initializer=kernel_init, bias_initializer=bias_init)(camada_de_entrada)
x = MaxPool2D((3, 3), preenchimento='mesmo', passos largos=(2, 2), nome='max_pool_1_3x3 / 2')(x)
x = Conv2D(64, (1, 1), preenchimento='mesmo', passos largos=(1, 1), ativação='relu', nome='conv_2a_3x3 / 1')(x)
x = Conv2D(192, (3, 3), preenchimento='mesmo', passos largos=(1, 1), ativação='relu', nome='conv_2b_3x3 / 1')(x)
x = MaxPool2D((3, 3), preenchimento='mesmo', passos largos=(2, 2), nome='max_pool_2_3x3 / 2')(x)
x = inception_module(x,
filtros_1x1=64,
filtros_3x3_reduce=96,
filtros_3x3=128,
filtros_5x5_reduce=16,
filtros_5x5=32,
filtros_pool_proj=32,
nome='inception_3a')
x = inception_module(x,
filtros_1x1=128,
filtros_3x3_reduce=128,
filtros_3x3=192,
filtros_5x5_reduce=32,
filtros_5x5=96,
filtros_pool_proj=64,
nome='inception_3b')
x = MaxPool2D((3, 3), preenchimento='mesmo', passos largos=(2, 2), nome='max_pool_3_3x3 / 2')(x)
x = inception_module(x,
filtros_1x1=192,
filtros_3x3_reduce=96,
filtros_3x3=208,
filtros_5x5_reduce=16,
filtros_5x5=48,
filtros_pool_proj=64,
nome='inception_4a')
x1 = AveragePooling2D((5, 5), passos largos=3)(x)
x1 = Conv2D(128, (1, 1), preenchimento='mesmo', ativação='relu')(x1)
x1 = Achatar()(x1)
x1 = Denso(1024, ativação='relu')(x1)
x1 = Cair fora(0.7)(x1)
x1 = Denso(10, ativação='softmax', nome='auxilliary_output_1')(x1)
x = inception_module(x,
filtros_1x1=160,
filtros_3x3_reduce=112,
filtros_3x3=224,
filtros_5x5_reduce=24,
filtros_5x5=64,
filtros_pool_proj=64,
nome='inception_4b')
x = inception_module(x,
filtros_1x1=128,
filtros_3x3_reduce=128,
filtros_3x3=256,
filtros_5x5_reduce=24,
filtros_5x5=64,
filtros_pool_proj=64,
nome='inception_4c')
x = inception_module(x,
filtros_1x1=112,
filtros_3x3_reduce=144,
filtros_3x3=288,
filtros_5x5_reduce=32,
filtros_5x5=64,
filtros_pool_proj=64,
nome='inception_4d')
x2 = AveragePooling2D((5, 5), passos largos=3)(x)
x2 = Conv2D(128, (1, 1), preenchimento='mesmo', ativação='relu')(x2)
x2 = Achatar()(x2)
x2 = Denso(1024, ativação='relu')(x2)
x2 = Cair fora(0.7)(x2)
x2 = Denso(10, ativação='softmax', nome='auxilliary_output_2')(x2)
x = inception_module(x,
filtros_1x1=256,
filtros_3x3_reduce=160,
filtros_3x3=320,
filtros_5x5_reduce=32,
filtros_5x5=128,
filtros_pool_proj=128,
nome='inception_4e')
x = MaxPool2D((3, 3), preenchimento='mesmo', passos largos=(2, 2), nome='max_pool_4_3x3 / 2')(x)
x = inception_module(x,
filtros_1x1=256,
filtros_3x3_reduce=160,
filtros_3x3=320,
filtros_5x5_reduce=32,
filtros_5x5=128,
filtros_pool_proj=128,
nome='inception_5a')
x = inception_module(x,
filtros_1x1=384,
filtros_3x3_reduce=192,
filtros_3x3=384,
filtros_5x5_reduce=48,
filtros_5x5=128,
filtros_pool_proj=128,
nome='inception_5b')
x = GlobalA AveragePooling2D(nome='avg_pool_5_3x3 / 1')(x)
x = Cair fora(0.4)(x)
x = Denso(10, ativação='softmax', nome='saída')(x)
modelo = Modelo(camada_de_entrada, [x, x1, x2], nome='inception_v1')
Vamos resumir nosso modelo para verificar se nosso trabalho até agora foi bem.
O modelo parece bom, como você pode medir a partir da saída acima. Podemos adicionar alguns toques finais antes de treinar nosso modelo. Vamos definir o seguinte:
- Função de perda para cada camada de saída
- Peso atribuído a essa camada de saída
- Função de otimização, que é modificado para incluir uma diminuição no peso após cada 8 épocas.
- Avaliação métrica
épocas = 25
taxa_inicial = 0.01
def decair(época, degraus=100):
taxa_inicial = 0.01
derrubar = 0.96
epochs_drop = 8
lrate = taxa_inicial * matemática.Pancada(derrubar, matemática.piso((1+época)/epochs_drop))
Retorna lrate
sgd = SGD(lr=taxa_inicial, impulso=0.9, Nesterov=Falso)
lr_sc = LearningRateScheduler(decair, prolixo=1)
modelo.compilar(perda=['categorical_crossentropy', 'categorical_crossentropy', 'categorical_crossentropy'], loss_weights=[1, 0.3, 0.3], otimizador=sgd, Métricas=['precisão'])
Nosso modelo agora está pronto! Experimente para ver como funciona.
história = modelo.ajuste(X_train, [y_train, y_train, y_train], Validation_data=(X_test, [y_test, y_test, y_test]), épocas=épocas, tamanho do batch=256, chamadas de retorno=[lr_sc])
Abaixo está o resultado que obtive ao treinar o modelo:
Nosso modelo deu uma precisão impressionante do 80% + no conjunto de validação, o que mostra que esta arquitetura de modelo realmente vale a pena conferir.
Notas finais
Este foi um artigo muito bom para escrever e espero que você o tenha achado igualmente útil. O início v1 foi o ponto focal deste artigo, em que expliquei os detalhes desse framework e demonstrei como implementá-lo do zero no Keras.
Nos próximos artigos, Vou me concentrar nos avanços nas arquiteturas de iniciação. Esses avanços foram detalhados em artigos posteriores., a saber, Inception v2, Inception v3, etc. E sim, eles são tão intrigantes quanto o nome sugere, Então fique ligado!
Se você tem alguma sugestão / comentário relacionado ao artigo, poste na seção de comentários abaixo.





