[*]
Este artigo foi publicado como parte do Data Science Blogathon
Introdução
clima. São dados tão grandes e complexos que nenhuma das ferramentas tradicionais de gerenciamento de dados os armazena ou processa com eficiência..
Big Data é um campo que trata das formas de investigar, analisar e extrair informações consistentemente de uma grande quantidade de dados estruturados ou não estruturados.
Python tem vários recursos integrados para dar suporte ao processamento de dados, tamanho pequeno ou grande. Essas funções suportam o processamento de dados não estruturados e não convencionais. Esta é a razão pela qual os cientistas de dados e as empresas de Big Data preferem escolher o Python para processamento de dados, por ser considerado um dos requisitos mais importantes em Big Data.
Existem também outras tecnologias que podem processar Big Data com mais eficiência do que o Python.. Son Hadoop e Spark.
Hadoop
Hadoop es la mejor solución para almacenar y procesar Big Data porque Hadoop almacena archivos enormes en forma de Sistema de arquivos distribuídoUm sistema de arquivos distribuído (DFS) Permite armazenamento e acesso a dados em vários servidores, facilitando o gerenciamento de grandes volumes de informações. Esse tipo de sistema melhora a disponibilidade e a redundância, à medida que os arquivos são replicados para locais diferentes, Reduzindo o risco de perda de dados. O que mais, Permite que os usuários acessem arquivos de diferentes plataformas e dispositivos, promovendo colaboração e... (HDFSHDFS, o Sistema de Arquivos Distribuído Hadoop, É uma infraestrutura essencial para armazenar grandes volumes de dados. Projetado para ser executado em hardware comum, O HDFS permite a distribuição de dados em vários nós, garantindo alta disponibilidade e tolerância a falhas. Sua arquitetura é baseada em um modelo mestre-escravo, onde um nó mestre gerencia o sistema e os nós escravos armazenam os dados, facilitando o processamento eficiente de informações..) Hadoop sem especificar nenhum esquema.
É altamente escalável, uma vez que qualquer número de nós pode ser adicionado para melhorar o desempenho. E Hadoop, os dados estão altamente disponíveis se ocorrer alguma falha de hardware.
Fagulha – fagulha
O Spark também é uma boa opção para processar um grande número de conjuntos de dados estruturados ou não estruturados., uma vez que os dados são armazenados em clusters. O Spark conceberá armazenar a quantidade máxima de dados na memória para que eles sejam derramados no disco. Ele armazenará uma parte do conjunto de dados na memória e, portanto, os dados restantes no disco.
A primeira escolha de linguagem do Toady Data Scientist é o Python e tanto o Hadoop quanto o Spark fornecem APIs Python que fornecem processamento de Big Data e também permitem acesso fácil a plataformas de Big Data..
Fonte da imagem: por mim
Necessidade de Python em Big Data
1. Código aberto:
Python é uma linguagem de programação de código aberto desenvolvida abaixo sob uma Open Supply License aprovada pela OSI., o que o torna livremente utilizável e distribuível, mesmo para uso comercial.
Python é uma linguagem interpretada de alto nível e de propósito geral.. Não há necessidade de compilar para executar. Um programa conhecido como interpretador executa código Python em praticamente qualquer tipo de sistema.. Isso significa que um desenvolvedor pode modificar o código e ver rapidamente os resultados..
2. fácil de aprender:
Python é muito fácil de aprender, assim como o idioma inglês. Sua sintaxe e código são fáceis e legíveis também para iniciantes. Python tem muitas aplicações como desenvolvimento de aplicações web, ciência de dados, aprendizado de máquina, etc.
Python nos permite escrever programas com menos linhas de código do que a maioria das outras linguagens de programação.. A popularidade do Python está crescendo rapidamente devido à sua simplicidade..
3. Bibliotecas de Processamento de Dados:
Quando se trata de processamento de dados, Python tem um
rico conjunto de ferramentas com uma ampla gama de benefícios. Como é uma linguagem de código aberto?, é fácil de aprender e também melhora continuamente. Python consiste em uma lista de várias bibliotecas úteis para processamento de dados e também integradas com outras linguagens. (como Java), bem como com as estruturas existentes. Python é mais rico em bibliotecas que melhoram ainda mais sua funcionalidade.
4. Suporte a Hadoop e Spark:
A estrutura do Hadoop é escrita na linguagem Java.; porém, Os programas Hadoop podem ser codificados em linguagem Python ou C ++. Podemos escrever programas como MapReduce em linguagem Python, embora não seja necessário traduzir o código para arquivos jar java.
O Spark fornece uma API Python chamada PySpark lançada pela comunidade Apache Spark para dar suporte ao Python com o Spark.. Usando PySpark, one irá simplesmente integrar e trabalhar com RDD dentro da linguagem de programação Python também.
O Spark vem com um shell interativo do Python chamado shell PySpark.. Este shell PySpark é responsável pela ligação entre a API Python e o núcleo spark e por inicializar o contexto spark. O PySpark também pode ser iniciado diretamente da linha de comando, fornecendo algumas instruções para uso interativo.
5. velocidade e eficiência:
Python é uma linguagem de programação de alto nível poderosa e eficiente.. Seja desenvolvendo um aplicativo ou trabalhando para resolver qualquer problema de negócios por meio da ciência de dados, Python cobriu todos esses limites. Python sempre funciona bem para otimizar a produtividade e a eficiência do desenvolvedor.
Podemos criar rapidamente um programa que pode resolver um problema de negócios e atende a uma necessidade prática. Porém,
As soluções podem não atingir o desempenho otimizado do Python enquanto são desenvolvidas rapidamente.
6. Escalável e flexível:
Python é a linguagem mais popular para ML / IA por sua conveniência. A flexibilidade do Python também permite que o código Python seja instrumentado para formar a escalabilidade de ML. / AI possivelmente sem exigir mais experiência em sistemas distribuídos e muitas alterações de código invasivas. Portanto, Usuários de ML / A IA obtém os benefícios da escalabilidade em todo o cluster com o mínimo de esforço.
Componentes do Hadoop:
Existem basicamente dois componentes do Hadoop:
- HDFS (Sistema de arquivos distribuído Hadoop)
- Mapa pequeno
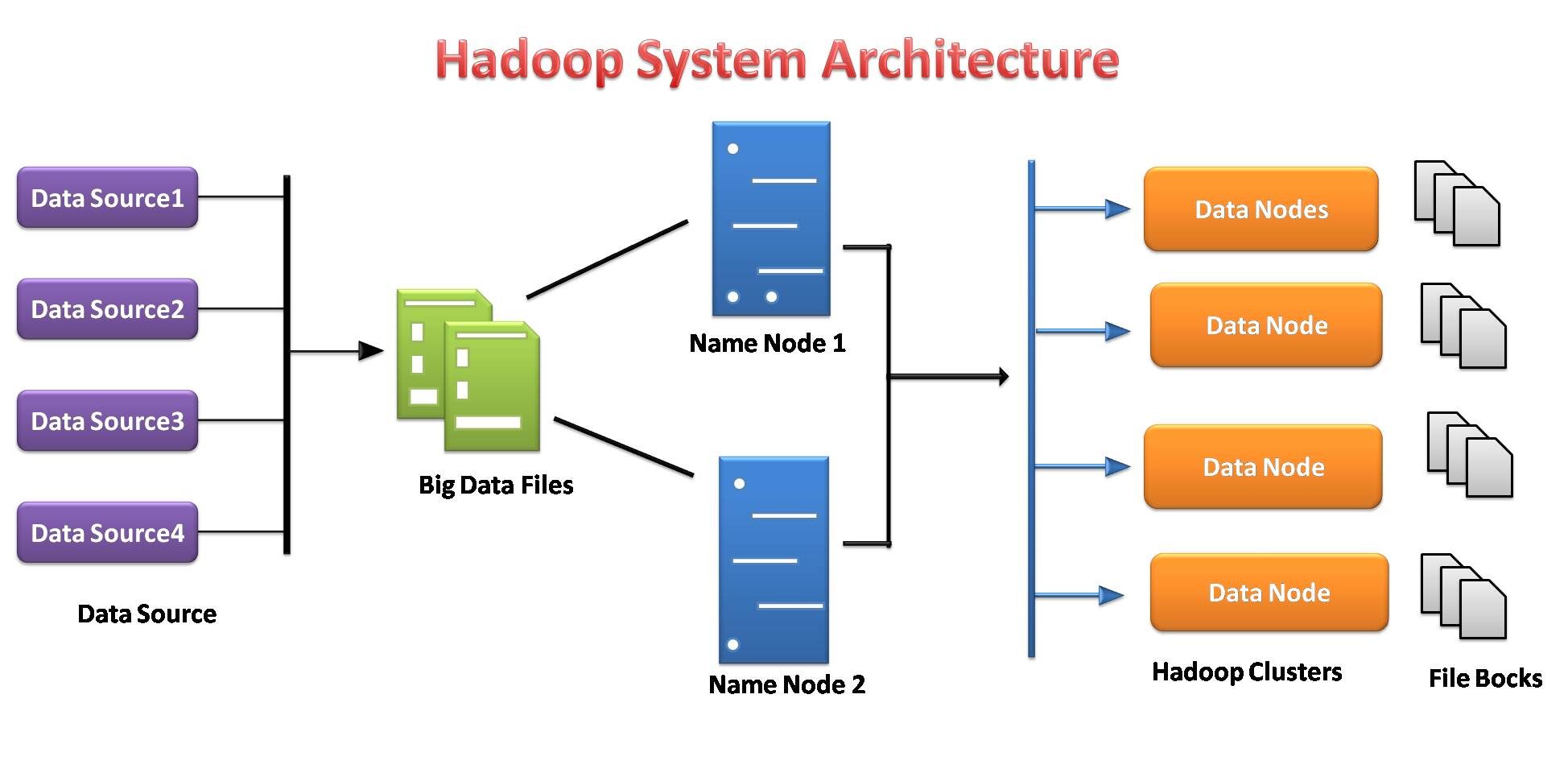
Sistema de Arquivo Distribuído Hadoop
O sistema de arquivos Hadoop foi desenvolvido com base no modelo de sistema de arquivos distribuído.. Funciona com hardware básico. Ao contrário dos diferentes sistemas distribuídos, O HDFS é extremamente tolerante a falhas e projetado em hardware barato.
O HDFS pode armazenar uma grande quantidade de dados e também fornece acesso mais fácil a esses dados.. Para armazenar uma quantidade tão grande de dados, os arquivos são armazenados em vários sistemas. Esses arquivos são armazenados de forma redundante para resgatar o sistema de uma possível perda de dados em caso de falha.. O que mais, HDFS oferece aplicativos para multiprocessamento.
- Es responsable de almacenar datos en un cachoUm cluster é um conjunto de empresas e organizações interconectadas que operam no mesmo setor ou área geográfica, e que colaboram para melhorar sua competitividade. Esses agrupamentos permitem o compartilhamento de recursos, Conhecimentos e tecnologias, Promover a inovação e o crescimento económico. Os clusters podem abranger uma variedade de setores, Da tecnologia à agricultura, e são fundamentais para o desenvolvimento regional e a criação de empregos.... como almacenamiento y procesamiento distribuidos.
- Los servidores de datos del nóO Nodo é uma plataforma digital que facilita a conexão entre profissionais e empresas em busca de talentos. Através de um sistema intuitivo, permite que os usuários criem perfis, Compartilhar experiências e acessar oportunidades de trabalho. Seu foco em colaboração e networking torna o Nodo uma ferramenta valiosa para quem deseja expandir sua rede profissional e encontrar projetos que se alinhem com suas habilidades e objetivos.... de nombre y del nodo de conocimiento facilitan a los usuarios comprobar simplemente el estado del clúster.
- Cada bloco é replicado várias vezes por padrão 3 vezes. As réplicas são armazenadas em nós completamente diferentes.
- O Hadoop Streaming atua como uma ponte entre seu código Python e, portanto, o HDFS baseado em Java, y le permite acceder sin problemas a los clústeres de Hadoop y ejecutar tareas de MapReduceO MapReduce é um modelo de programação projetado para processar e gerar grandes conjuntos de dados com eficiência. Desenvolvido pelo Google, Essa abordagem divide o trabalho em tarefas menores, que são distribuídos entre vários nós em um cluster. Cada nó processa sua parte e, em seguida, os resultados são combinados. Esse método permite dimensionar aplicativos e lidar com grandes volumes de informações, sendo fundamental no mundo do Big Data.....
- O HDFS fornece autenticação de arquivos e permissões.
Fonte da imagem: por mim
Instalando Hadoop no Google Colab
Hadoop é uma estrutura de processamento de dados baseada na programação Java. Vamos instalar as configurações do Hadoop passo a passo no Google Colab. Existem duas maneiras, a primeira é que temos que instalar java em nossas máquinas e a segunda é que instalamos java no Google Colab, por isso não é necessário instalar java em nossas máquinas. Como usamos o Google colab, escolhemos a segunda maneira de instalar Hadoop:
# Instalar java !apt-get instalar openjdk-8-jdk-cabeça sem cabeça -qq > /dev/nulo
#create java home variable
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ["SPARK_HOME"] = "/conteúdo/faísca-3.0.0-bin-hadoop3.2"
Paso 1: instalar Hadoop
#baixar hadoop !wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
#usaremos o comando tar com o sinalizador -x para extrair, -z para descompactar, #-v para saída detalhada, e -f para especificar que estamos extraindo de um arquivo !tar -xzvf hadoop-3.3.0.tar.gz
#copiando o arquivo hadoop para usuário/local !cp -r hadoop-3.3.0/ /usr/local/
Paso 2: configurar la variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... de inicio de Java
#encontrando o caminho Java padrão !readlink -f /usr/bin/java | sed "s:bin/java::"
Paso 3: Executar o Hadoop
#Executando o Hadoop !/usr/local/hadoop-3.3.0/bin/hadoop
!mkdir ~/entrada
!cp /usr/local/hadoop-3.3.0/etc/hadoop/*.xml ~/input
!/usr/local/hadoop-3.3.0/bin/hadoop jar /usr/local/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar grep ~/input ~/grep_example ' permitido[.]*'
Agora, O Google Colab está pronto para implantar o HDFS.
Mapa pequeno
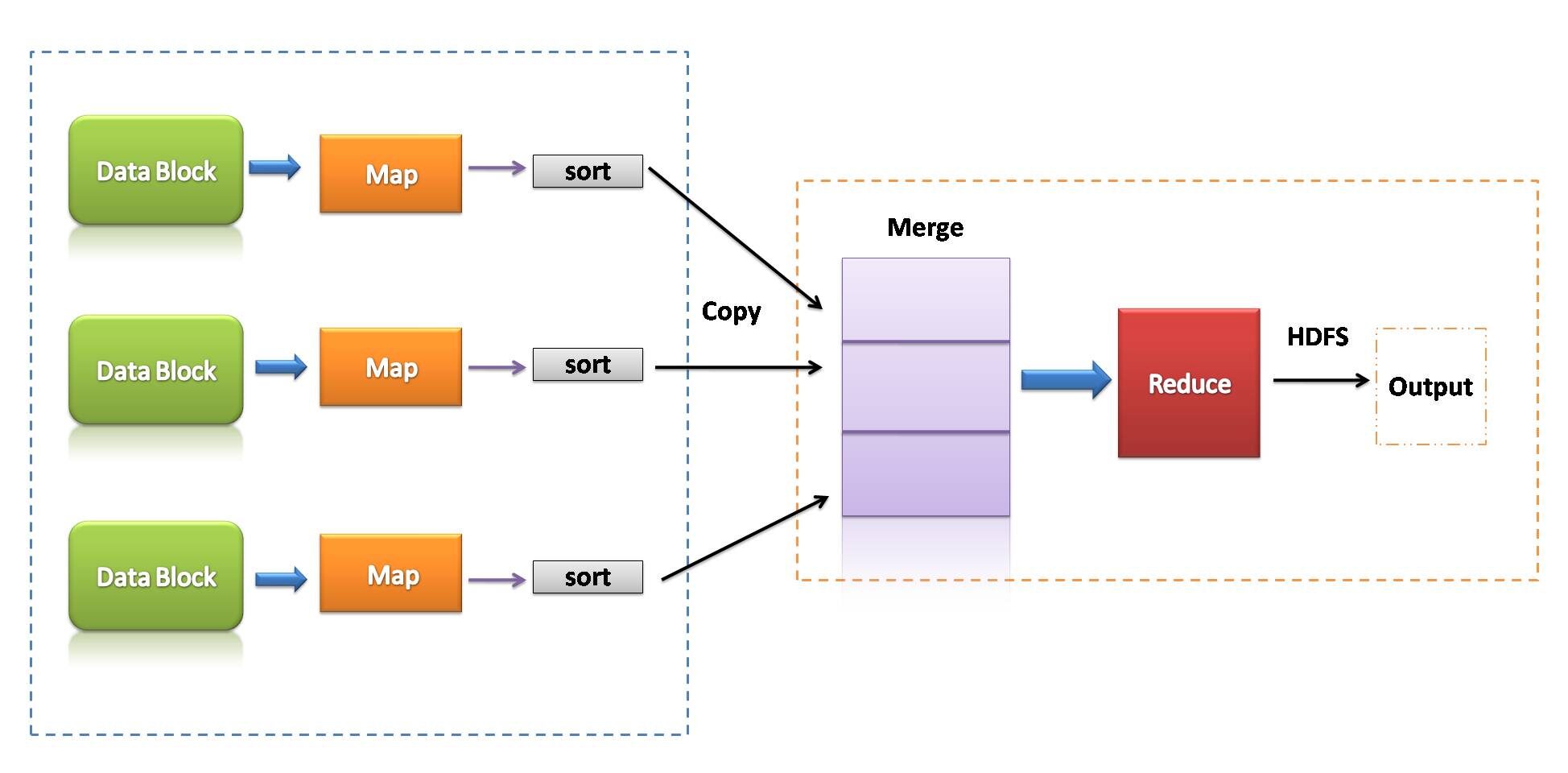
MapReduce é um modelo de programação que está associado à implementação de processamento e geração de grandes conjuntos de dados com a ajuda de regras algorítmicas paralelas distribuídas em um cluster.
Um programa MapReduce consiste em um procedimento de mapa, que realiza a filtragem e ordenação, e uma técnica de redução, que executa uma operação de esquema.
Fonte da imagem: por mim
- MapReduce pode ser uma estrutura de processamento de dados para processar dados no cluster.
- duas fases consecutivas: mapear e reduzir.
- Cada tarefa de mapa opera em partes separadas de dados.
- depois do mapa, o redutor trabalha com os dados gerados pelo mapeador nos nós de dados distribuídos.
- MapReduce usado E / disco S para realizar operações de dados.
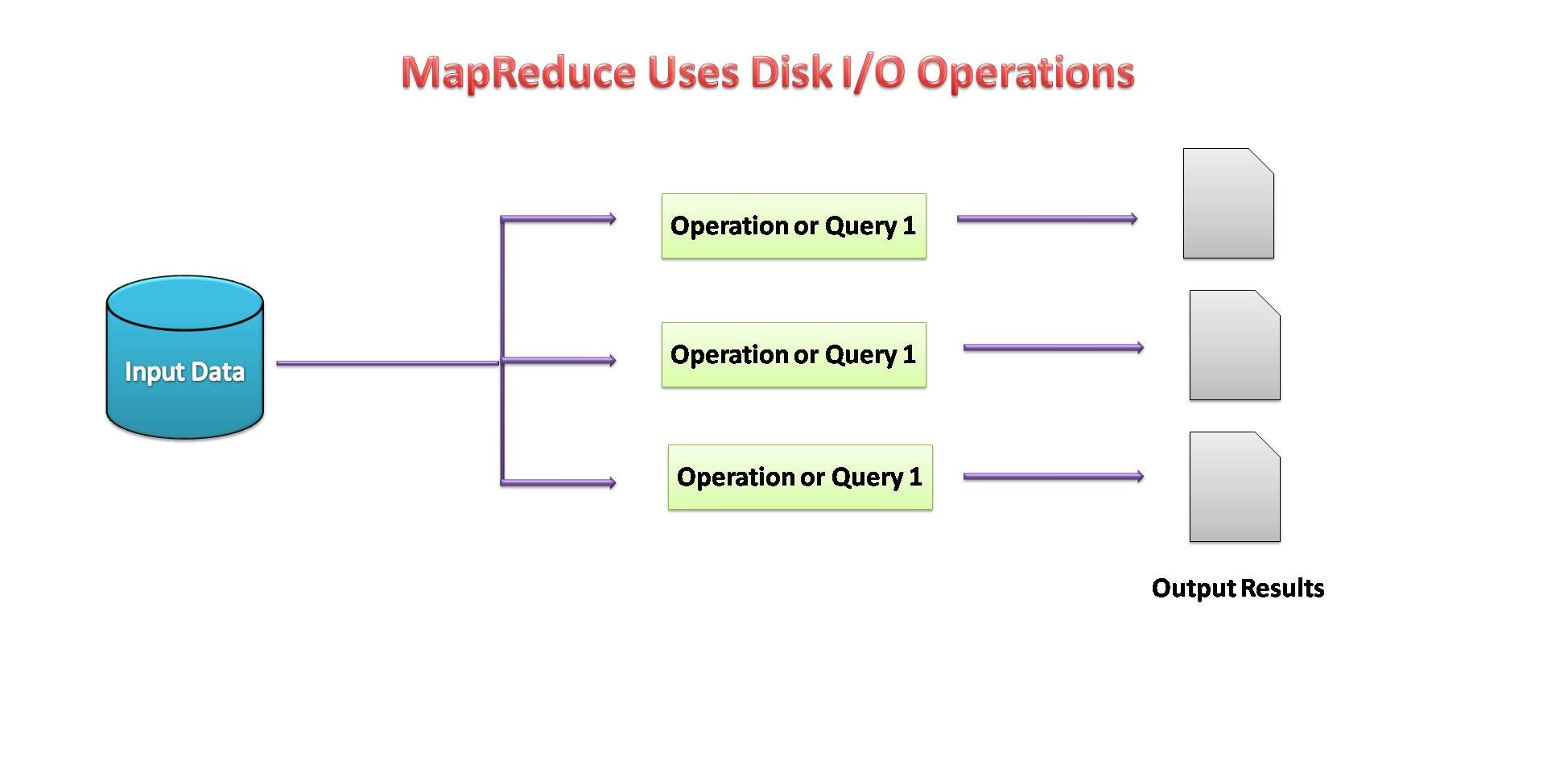
Fonte da imagem: por mim
Apache SparkO Apache Spark é um mecanismo de processamento de dados de código aberto que permite a análise de grandes volumes de informações de forma rápida e eficiente. Seu design é baseado na memória, que otimiza o desempenho em comparação com outras ferramentas de processamento em lote. O Spark é amplamente utilizado em aplicativos de big data, Aprendizado de máquina e análise em tempo real, graças à sua facilidade de uso e...
O Apache Spark é um mecanismo de análise de dados de código aberto para processamento em larga escala de dados estruturados ou não estruturados.. Para trabalhar com Python, incluindo recursos do Spark, a comunidade Apache Spark lançou uma ferramenta chamada PySpark.
A API Python do Spark (PySpark) revela o modelo de programação Spark para Python. Usando PySpark, podemos trabalhar com RDD na linguagem de programação Python. É atribuível a uma biblioteca conhecida como Py4j que pode conseguir isso.
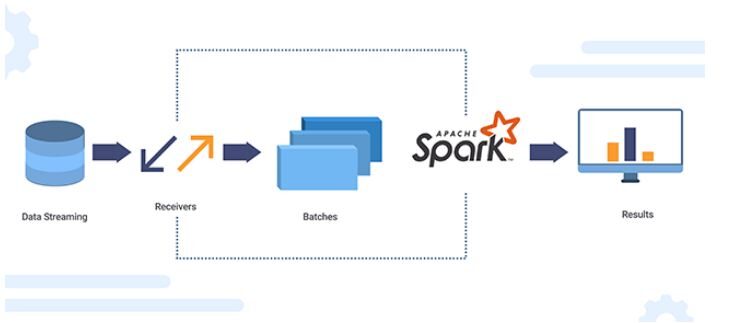
Fonte da imagem: XanonStackName
Conjuntos de dados distribuídos resilientes (RDD)
Conceitos de conjuntos de dados distribuídos resilientes (RDD) filho:
- O foco principal da programação Spark é RDD.
- Spark é extremamente tolerante a falhas. Possui coleções de objetos distribuídos em um cluster que podem operar em paralelo.
- Al usar Spark, pode recuperar automaticamente da falha da máquina.
- Podemos criar um RDD copiando os elementos de uma coleção existente ou referenciando um conjunto de dados armazenado externamente.
- Existem dois tipos de operações que os RDDs realizam: transformações e ações.
- A operação de transformação usa um conjunto de dados existente para criar um novo. Exemplo: mapear, filtro, Junte.
- Ações executadas no conjunto de dados e retornam o valor ao programa do controlador. Exemplo: reduzir, contar, não importa o nível de granularidade que você tem na tabela dinâmica, Salve .
Se a disponibilidade de memória parecer insuficiente, os dados são gravados no disco como MapReduce.
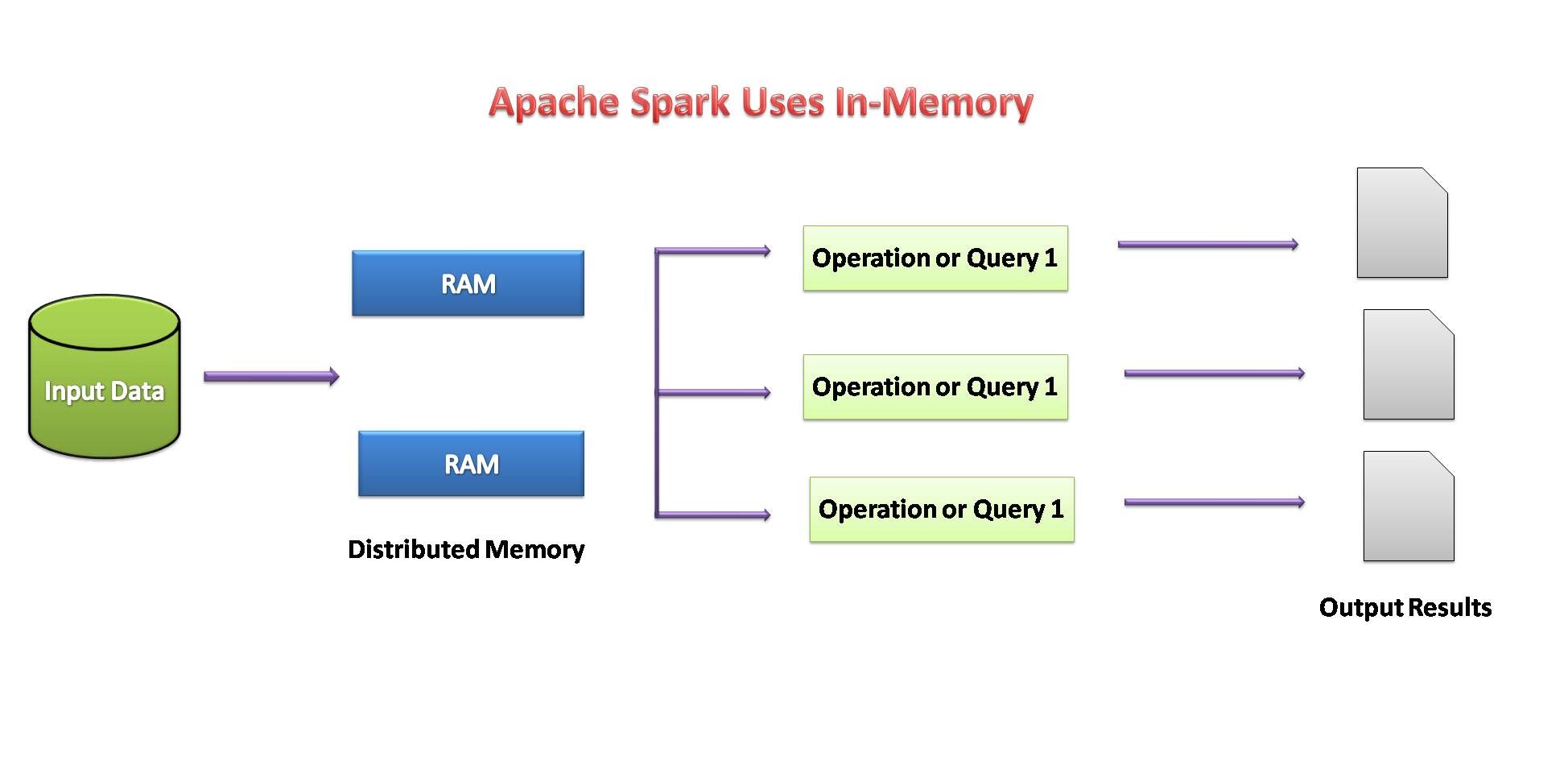
Fonte da imagem: por mim
Instalação do Spark no Google colab:
Spark é uma estrutura de processamento de dados eficiente. podemos instalarlo fácilmente en el colab de Google.
# Instalar java !apt-get instalar openjdk-8-jdk-cabeça sem cabeça -qq > /dev/nulo
#Instalar faísca (alterar o número da versão, se necessário) !wget -q https://archive.apache.org/dist/spark/spark-3.0.0/spark-3.0.0-bin-hadoop3.2.tgz
#Descompactar o arquivo de centelha para a pasta atual !piche xf faísca-3.0.0-bin-hadoop3.2.tgz
#Defina sua pasta de centelha para o ambiente de caminho do sistema. importar os os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64" os.environ["SPARK_HOME"] = "/conteúdo/faísca-3.0.0-bin-hadoop3.2"
#Instalar o findspark usando pip !pip instalar -q findspark
#Faísca para Python (pyspark) !pip install pyspark
#importing pyspark
import pyspark
#importing sparksessio
from pyspark.sql import SparkSession
#creating a sparksession object and providing appName
spark=SparkSession.builder.appName("local[*]").getOrCreate()
#printing the version of spark
print("Versão Apache Spark: ", spark.version)

Agora, Google Colab está listo para implementar Spark en Python.
Ventajas de Apache Spark:
- Faísca es de 10 uma 100 veces más rápido que Hadoop MapReduce cuando se habla de procesamiento de datos.
- Tiene sImplemente uma estrutura de processamento de dados e APIs interativas para Python para ajudar a acelerar o desenvolvimento de aplicativos.
- O que mais, é mais eficiente, pois possui várias ferramentas para operações analíticas complexas.
- Pode ser facilmente integrado à infraestrutura Hadoop existente.
conclusão:
Neste blog, estudamos como o Python também pode se tornar uma ferramenta boa e eficiente para processamento de Big Data. Podemos integrar todas as ferramentas de Big Data com Python, o que torna o processamento de dados mais fácil e rápido. O Python se tornou uma opção adequada não apenas para ciência de dados, mas também para processamento de Big Data..
Obrigado pela leitura. Por favor, deixe-me saber se houver algum comentário ou feedback.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





