Tipos de aprendizado de máquina

1. Aprendizagem supervisionadaO aprendizado supervisionado é uma abordagem de aprendizado de máquina em que um modelo é treinado usando um conjunto de dados rotulados. Cada entrada no conjunto de dados está associada a uma saída conhecida, permitindo que o modelo aprenda a prever resultados para novas entradas. Este método é amplamente utilizado em aplicações como classificação de imagens, Reconhecimento de fala e previsão de tendências, destacando sua importância em...: Em um modelo de aprendizagem supervisionada, o algoritmo aprende em um conjunto de dados rotulado para gerar previsões esperadas para a solução de novos dados.
P.ej; Para previsão de preços de residências, primeiro precisamos de dados sobre habitações, como; pé quadrado, não. de quartos, a casa tem jardim ou não, e assim por diante. Então, precisamos saber os preços dessas casas, Em outras palavras; rótulos de classe. Agora que os dados vêm de centenas de casas, suas características e preços, agora podemos treinar um modelo de aprendizado de máquina supervisionado para prever o preço de uma nova casa com base em experiências anteriores do modelo.
A aprendizagem supervisionada é de dois tipos:
uma) Classificação: Em classificação, Um programa de computador é treinado em um conjunto de dados de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... e, de acordo com o treinamento, categorizar os dados em diferentes rótulos de classe. Este algoritmo é usado para prever os valores discretos como masculinos | mulher, verdade | falso, Spam | sem spam, etc.
P.ej; Detecção de spam, acreditação de voz, identificação de células cancerosas, etc.
Tipos de algoritmos de classificação:
- Classificador Naive Bayes
- Árvores de decisão
- Regressão logística
- Vizinhos mais próximos
- Máquinas de vetor de suporte
- Classificação de floresta aleatória
b) Regressão: A tarefa do algoritmo de regressão é encontrar a função de mapeamento para mapear as variáveis de entrada (x) a variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... Saída contínua (e). Algoritmos de regressão são usados para prever valores contínuos, como preço, salário, era, notas, etc.
P.ej; Previsão de tempo, previsão do preço da casa, detecção de notícias falsas, etc.
Tipos de algoritmos de regressão:
- Regressão linear simples
- Regressão linear múltipla
- regressão polinomial
- Regressão da árvore de decisão
- Regressão de floresta aleatória
- Método de definição
2. Aprendizagem não supervisionadaO aprendizado não supervisionado é uma técnica de aprendizado de máquina que permite que os modelos identifiquem padrões e estruturas em dados sem rótulos predefinidos. Por meio de algoritmos como k-means e análise de componentes principais, Essa abordagem é usada em uma variedade de aplicações, como segmentação de clientes, detecção de anomalias e compactação de dados. Sua capacidade de revelar informações ocultas o torna uma ferramenta valiosa no...: Em um modelo de aprendizagem não supervisionado, o algoritmo aprende em um conjunto de dados não rotulado e tenta fazer sentido extraindo recursos, co-ocorrência e padrões subjacentes sozinhos.
P.ej; Detecção de anomalia, incluindo detecção de fraude. Outro exemplo é a abertura de hospitais de emergência para áreas de maior risco de acidentes.. o agrupamentoo "agrupamento" É um conceito que se refere à organização de elementos ou indivíduos em grupos com características ou objetivos comuns. Este processo é usado em várias disciplinas, incluindo psicologia, Educação e biologia, para facilitar a análise e compreensão de comportamentos ou fenômenos. No campo educacional, por exemplo, O agrupamento pode melhorar a interação e o aprendizado entre os alunos, incentivando o trabalho.. de K-media agrupará esses locais de áreas propensas máximas em grupos e definirá um centro de grupo (Em outras palavras, hospital) para cada grupo (Em outras palavras, áreas propensas a acidentes).
Tipos de aprendizagem não supervisionada:
- Agrupamento
- Detecção de anomalia
- Associação
- Codificadores de carros
- Modelos de variáveis latentes
- Redes neurais
3. Aprendizagem por reforçoO aprendizado por reforço é uma técnica de inteligência artificial que permite que um agente aprenda a tomar decisões interagindo com um ambiente. Por meio de feedback na forma de recompensas ou punições, O agente otimiza seu comportamento para maximizar as recompensas acumuladas. Essa abordagem é usada em uma variedade de aplicações, De videogames a robótica e sistemas de recomendação, destacando-se por sua capacidade de aprender estratégias complexas....: Aprendizagem por reforço é um tipo de aprendizagem de máquina em que o modelo aprende a se comportar em um ambiente executando algumas ações e analisando as reações. RL toma as medidas adequadas para maximizar a solução positiva na situação particular. O modelo de reforço decide quais ações tomar para realizar uma determinada tarefa, é por isso que ele é obrigado a aprender com a própria experiência.
P.ej; Vamos dar um exemplo de um bebê aprendendo a andar. No primeiro caso, quando o bebê começa a andar e chega ao chocolate, dado que o chocolate é o objetivo final do bebê e a solução do bebê é positiva porque ele está feliz. No segundo caso, quando o bebê começa a andar e enquanto caminha é atingido pela cadeira e não consegue pegar o chocolate, começa a chorar, o que é uma resposta negativa. Em outras palavras, como os humanos aprendem com rastros e erros. Aqui, o bebê é o “agente”, chocolate é o “recompensa” e muitos obstáculos entre. Agora o agente tenta de várias maneiras e descobre a melhor maneira viável de obter a recompensa.
Ciclo de vida do aprendizado de máquina
O aprendizado de máquina ajuda a aumentar o desempenho da tarefa e a produtividade. Inclui aprendizagem e autocorreção quando apresentados a novos dados.
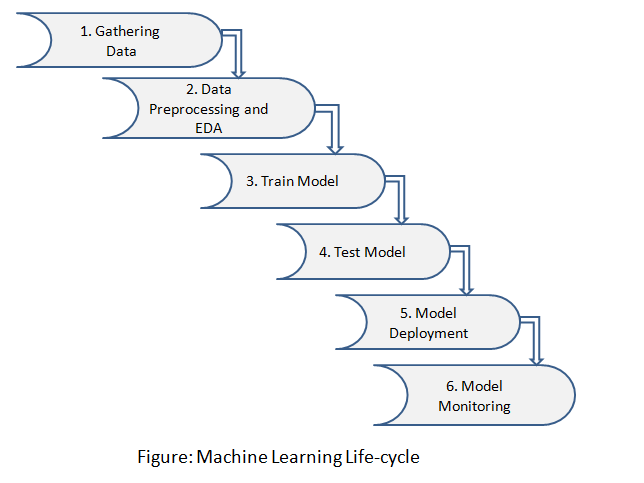
O ciclo de vida do aprendizado de máquina envolve seis etapas principais:
Paso 1: coleta de dados
Identifique várias fontes de dados como Kaggle e colete o conjunto de dados necessário
Paso 2: pré-processamento de dados e EDA
Nesta etapa, fazemos uma análise dos dados em busca de valores perdidos, dados duplicados, dados inválidos usando diferentes técnicas analíticas. E também pré-processar os dados para extrações de recursos, análise de recursos e visualização de dados.
Paso 3: trem modelo
Usamos um conjunto de dados para treinar o modelo usando vários algoritmos de aprendizado de máquina. Treinar um modelo é essencial para que ele possa entender os vários padrões, regras e características.
Paso 4: modelo de teste
Nesta etapa, verificamos a precisão do nosso modelo, fornecendo um conjunto de dados de teste para o modelo treinado.
Paso 5: Implementação de modelo
Implementação de modelo significa integrar um modelo de aprendizado de máquina em um ambiente de produção existente que obtém entradas e retorna resultados para tomar decisões de negócios baseadas em dados. Várias tecnologias que você pode usar para colocar seus modelos de aprendizado de máquina em prática são listadas.:
- Arrumação
- Governadores
- AWS SageMaker
- MLFlow
- Serviço de aprendizado de máquina do Azure
Paso 6: Monitoramento de modelo
Após a implementação do modelo, aqui vem o monitoramento de modelo, que monitora seus modelos de aprendizado de máquina em busca de fatores como erros, falhas e latência e, o mais importante, para garantir que seu modelo mantenha o desempenho desejado. O monitoramento do modelo é muito importante, pois seus modelos irão degradar ao longo do tempo devido a vários fatores, como dados invisíveis, mudanças no ambiente e relações entre as variáveis.
Algumas aplicações de aprendizado de máquina no mundo real
- Tradução automática de idiomas no Google Translate
- Seleção de rota mais rápida no motor de busca Google Map
- Carro sem motorista / Autônomo
- Smartphone com credenciamento facial
- Acreditação de voz
- Sistema de recomendação de anúncios
- Sistema de recomendação Netflix
- Sugestão de marcação automática de amigos no Facebook
- Negociação do mercado de ações
- Detecção de fraude
- Previsão de tempo
- Diagnóstico médico
- Chatbot
- Aprendizado de máquina na agricultura
Benefícios do aprendizado de máquina
- Automação de trabalho
- Capacidade preditiva poderosa
- Aumento das vendas no mercado de e-commerce.
- Benefícios do AA no domínio médico para impulsionar o diagnóstico médico e o desenvolvimento de medicamentos
- O aprendizado de máquina é usado em cirurgia médica robótica
- ML em finanças aumenta a produtividade, melhora a receita e fornece transações seguras
- Modele os dados para tomar decisões úteis
Resumo
O aprendizado de máquina pode ser usado em quase todos os setores da vida humana para fazer nosso trabalho eficiente, robusto, e Simples. Como sabemos, tudo tem seus prós e contras, o aprendizado de máquina também tem suas desvantagens, como um exemplo, com a ascensão do aprendizado de máquina, muitas pessoas podem perder seu emprego atual no palco. Mas mais em um tom bombástico Está benéfico no longo prazo para humanidade.
A mídia mostrada nesta postagem não é propriedade da DataPeaker e é usada a critério do autor.





