Introdução
R é uma das linguagens de programação mais famosas para análise estatística e computação.. Porque ele oferece muitos recursos, pesquisadores e cientistas de dados o usam para ciência de dados e aprendizado de máquina. Alguns desses recursos incluem bibliotecas de visualização interativa, rápido e de código aberto, execução de código sem compilador, boa comunidade e muito mais.
Uma das principais razões pelas quais está se tornando muito famoso é o grande número de pacotes R para projetos de ciência de dados., aprendizado de máquina e inteligência artificial. Ao usar esses pacotes, modelos preditivos podem ser desenvolvidos de forma fácil e eficiente. Este blog lista os 10 Principais pacotes R que você deve conhecer 2021 para ciência de dados e aprendizado de máquina.

Tabela de conteúdo
- Dplyr
- ggplot2
- KernLab
- explorador de dados
- Acento circunflexo
- randomForest
- Brilhante
- aumentar
- Completamente
- SuperML
Dplyr
É um dos pacotes R mais usados para tarefas de ciência de dados e aprendizado de máquina.. Este pacote é escrito por Hadley Wickham. É usado para resolver tarefas de manipulação de dados. Possui um conjunto de funções para manipulação de dados. Também chamada de gramática de manipulação de dados. Possui um conjunto de verbos que nos ajudam a resolver as tarefas de manipulação de dados mais desafiadoras, como mutate (), selecionar (), filtro (), resumir (), organizar ().
Para instalar este pacote, use o seguinte código:
install.packages('dplyr')


Para maiores informações, veja o link abaixo: Introdução ao dplyr
ggplot2
Um dos pacotes R mais populares e amplamente usados para visualização de dados e análise exploratória de dados. Você pode criar visualizações de dados interativas com este pacote. Fornece uma ampla gama de belos enredos que cuidam de detalhes minuciosos e desenham legendas. Este pacote funciona sob uma gramática profunda chamada “Gramática de gráficos”. Fornece uma ampla variedade de gráficos, como gráficos de dispersão e gráficos de bolhas. Os diagramas de flutuação são gráficos, histogramasHistogramas são representações gráficas que mostram a distribuição de um conjunto de dados. Eles são construídos dividindo o intervalo de valores em intervalos, o "Caixas", e contando quantos dados caem em cada intervalo. Essa visualização permite identificar padrões, tendências e variabilidade de dados de forma eficaz, facilitando a análise estatística e a tomada de decisões informadas em várias disciplinas...., parcelas de densidade, plotagens de caixaDiagramas de caixa, Também conhecido como diagramas de caixa e bigode, são ferramentas estatísticas que representam a distribuição de um conjunto de dados. Esses diagramas mostram a mediana, Quartis e outliers, permitindo que a variabilidade e a simetria dos dados sejam visualizadas. Eles são úteis na comparação entre diferentes grupos e na análise exploratória, facilitando a identificação de tendências e padrões nos dados...., diagramas de violino, dendrogramas e muito mais.
Para instalar este pacote, use o seguinte código:
install.packages('gglpot2')
Abaixo estão alguns exemplos de plotagens usando este pacote:
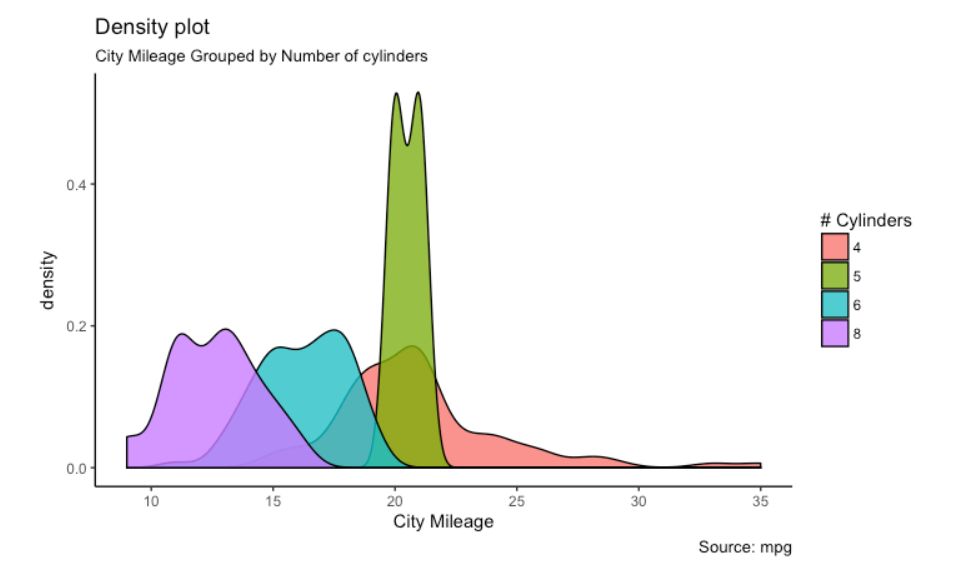

Para maiores informações, veja o link abaixo: ggplot2
KernLab
Este pacote também é chamado de laboratório de aprendizado de máquina baseado em kernel. Este pacote é usado para regressão, classificação, redução de dimensionalidade, detecção de anomalia, agrupamentoo "agrupamento" É um conceito que se refere à organização de elementos ou indivíduos em grupos com características ou objetivos comuns. Este processo é usado em várias disciplinas, incluindo psicologia, Educação e biologia, para facilitar a análise e compreensão de comportamentos ou fenômenos. No campo educacional, por exemplo, O agrupamento pode melhorar a interação e o aprendizado entre os alunos, incentivando o trabalho... Se você quiser usar algoritmos que envolvem uma abordagem baseada em kernel, você pode usá-lo como SVM, algoritmo de classificação, análise de recursos do kernel e muito mais. É amplamente utilizado para implementações SVM. Possui uma ampla gama de funções do kernel, como para a função de kernel polinomial, podemos usar polydot (), a função de kernel tangente hiperbólica para tanhdot (), etc.
Para instalar este pacote, use o seguinte código:
install.packages('kernlab')
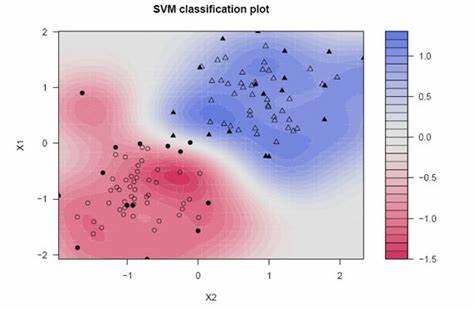
Para maiores informações, veja o link abaixo: pacote kernellab
explorador de dados
Este pacote R é um dos mais fáceis de usar para ciência de dados e aprendizado de máquina. Este pacote concentra-se principalmente em três objetivos:
- Análise exploratória de dados
- Engenharia de funções
- relatório de dados
Este pacote automatizou a análise exploratória de dados para modelagem preditiva e tarefas de análise visualizando cada recurso presente em nosso conjunto de dados.
Para instalar este pacote, use o seguinte código:
install.packages('Data Explorer')
Para encontrar uma visão geral ampla do nosso conjunto de dados, podemos usar o seguinte código:
introduzir(dados)
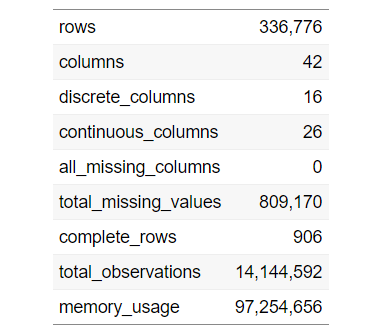
Para exibir a tabela anterior, use o seguinte código:
plot_intro(dados)
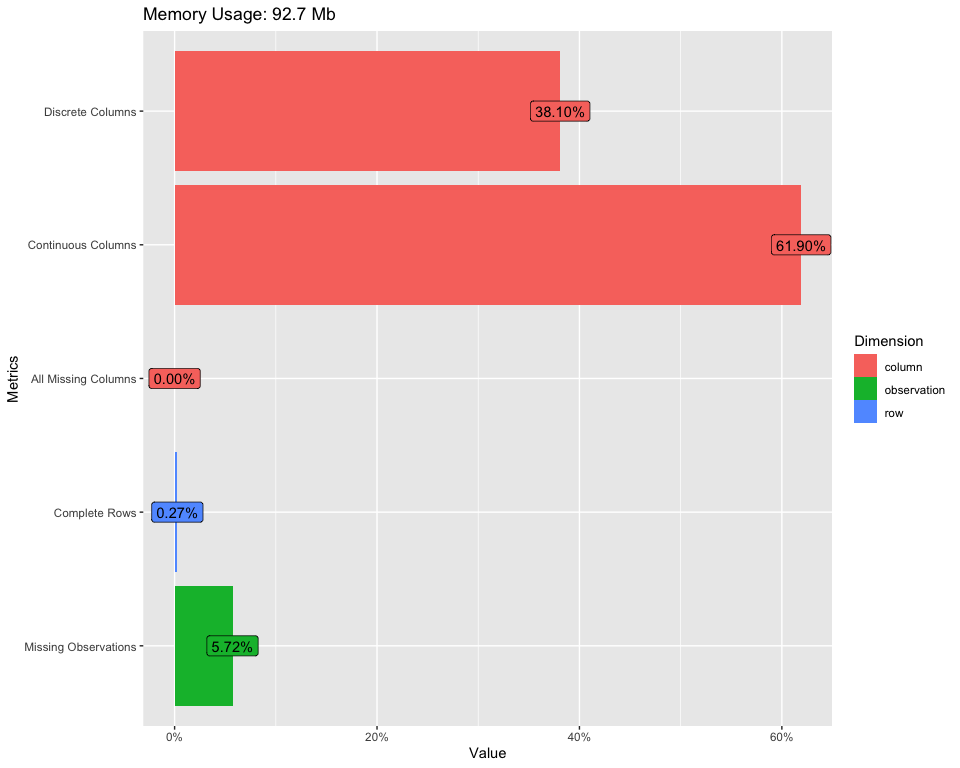
Para maiores informações, veja o link abaixo: Introdução ao DataExplorer
Acento circunflexo
Isso também é chamado TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... Classificação e regressão. É um dos melhores pacotes para tarefas de ciência de dados e aprendizado de máquina. Contém um conjunto de funções usadas para criar modelos preditivos. Tem outras funcionalidades, bem como a seleção de recursos, divisão de dados, pré-processamento de dados, ajuste do modelo, importância dos recursos e muito mais.
Para instalar este pacote, use o seguinte código:
install.packages('caret')
Para maiores informações, veja o link abaixo: acento circunflexo do pacote
randomForest
Random Forest é um dos pacotes R mais populares para aprendizado de máquina.. Este pacote é usado para criar florestas aleatórias em R. Pode ser usado para tarefas de classificação e regressão. Também podemos usá-lo para treinar valores ausentes e outliers. Este pacote usa o algoritmo de floresta aleatória Breiman para construir árvores de decisão..
Para encontrar uma visão geral ampla do nosso conjunto de dados, podemos usar o seguinte código:
install.packages('randomForest')
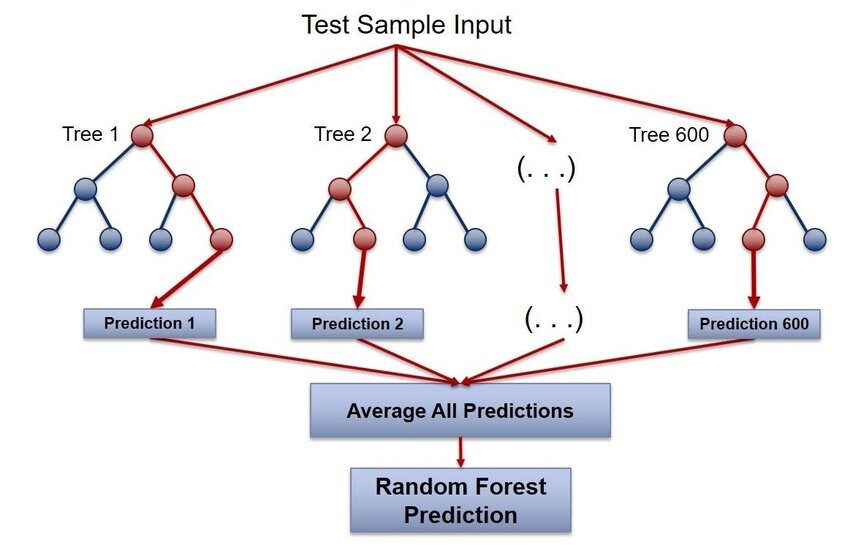
Para maiores informações, veja o link abaixo: Floresta aleatória
Brilhante

É um pacote R usado para criar uma aplicação web interativa para ciência de dados. Ele nos ajuda a criar aplicativos web R sem muito esforço. Shiny cria aplicativos da Web que são implantados na Web usando seu servidor ou serviços de hospedagem R brilhantes. Os recursos do Shiny R incluem a criação de um aplicativo com menos conhecimento de ferramentas da web, fornece visualizações ao vivo, funções de renderização e muito mais.
Exemplo de aplicação web com shiny:
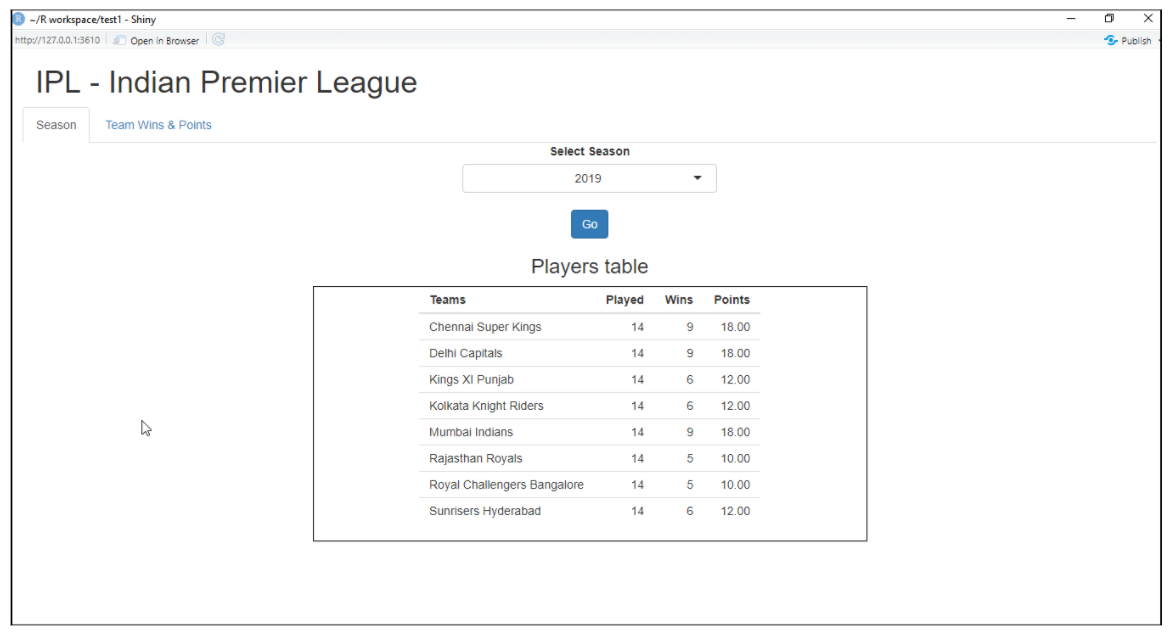
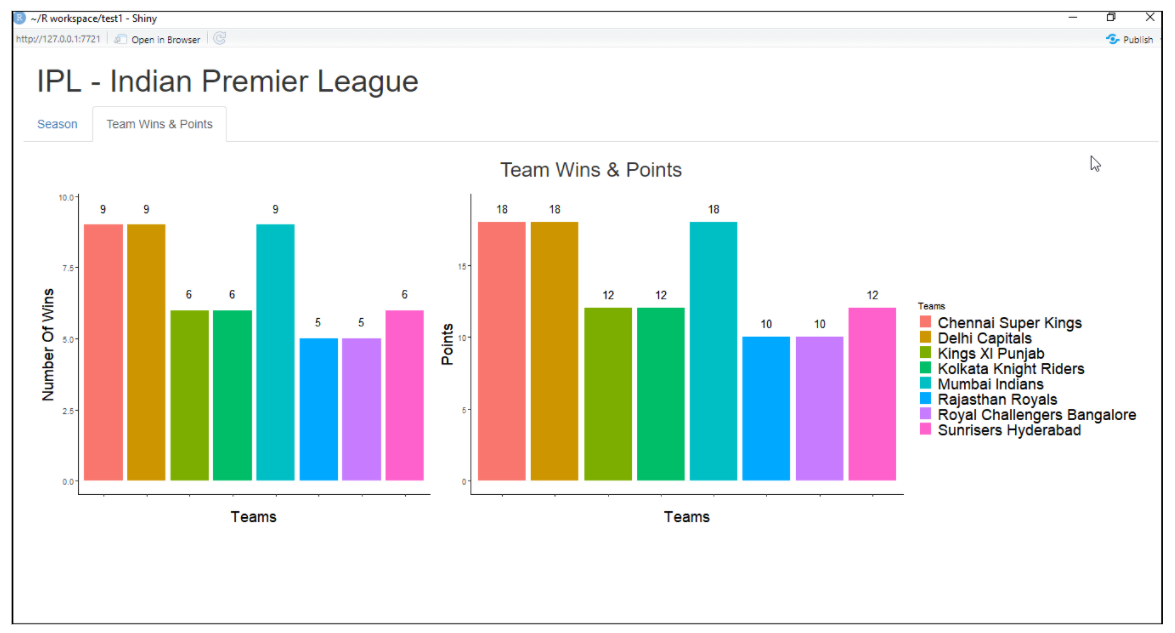
Para maiores informações, veja o link abaixo: Brilhante
aumentar
Este pacote é usado em ciência de dados para pacotes de impulso baseados em modelo e tem um algoritmo downstream funcional de gradienteGradiente é um termo usado em vários campos, como matemática e ciência da computação, descrever uma variação contínua de valores. Na matemática, refere-se à taxa de variação de uma função, enquanto em design gráfico, Aplica-se à transição de cores. Esse conceito é essencial para entender fenômenos como otimização em algoritmos e representação visual de dados, permitindo uma melhor interpretação e análise em... para otimizar as árvores de decisão. Ele também fornece um modelo de interação para dados potencialmente de alta qualidade. dimensão"Dimensão" É um termo usado em várias disciplinas, como a física, Matemática e filosofia. Refere-se à extensão em que um objeto ou fenômeno pode ser analisado ou descrito. Em física, por exemplo, fala-se de dimensões espaciais e temporais, enquanto em matemática pode se referir ao número de coordenadas necessárias para representar um espaço. Compreendê-lo é fundamental para o estudo e....
Para instalar este pacote, use o seguinte código:
install.packages('impulsionar')
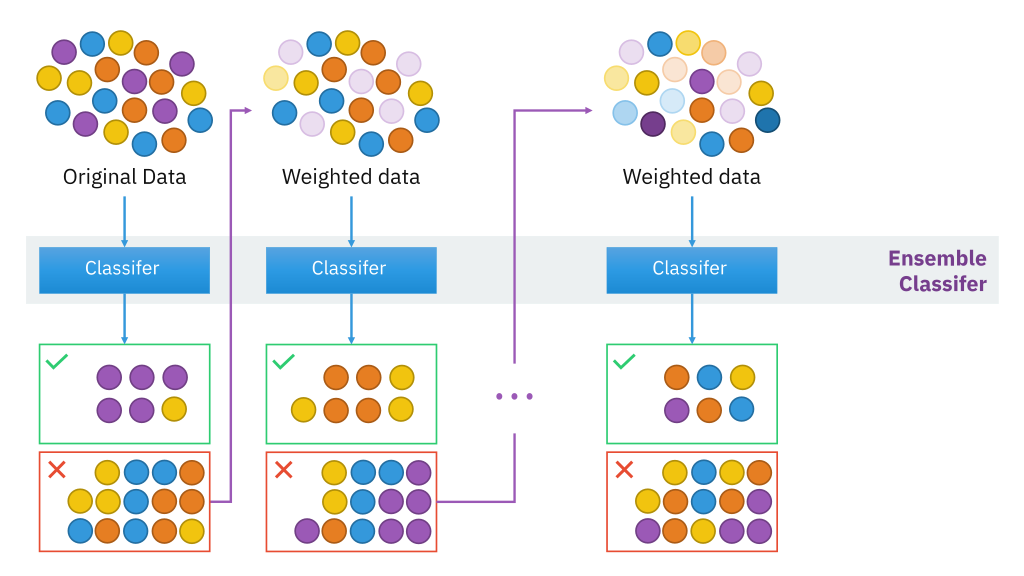
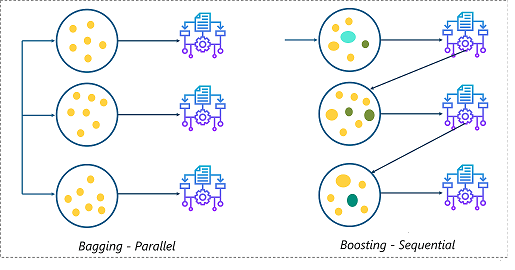
Para maiores informações, veja o link abaixo: aumentar
Completamente
É uma biblioteca de gráficos que cria gráficos interativos. É uma interface de alto nível para plotly.js, baseado em d3.js. Fornece uma interface de usuário fácil de usar para gerar gráficos D3 interativos elegantes. Esses gráficos interativos fornecem muitas funcionalidades, como a capacidade de aumentar e diminuir o zoom de gráficos, passe o mouse sobre um ponto para obter informações adicionais, filtrar dados e muito mais.

Fornece um exemplo de gráficos, como gráficos de dispersão, diagramas de linha, gráficos de barra, carrinhos circulares, diagramas de bolhas, plotagens de caixa, histogramas, Barras de erro, diagramas de violino e muito mais.
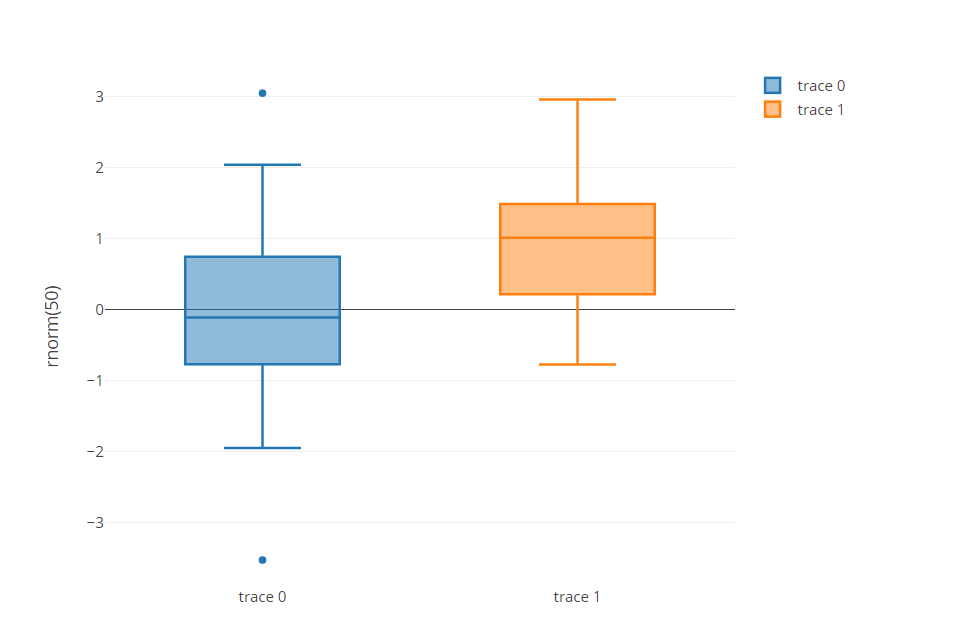
Para maiores informações, veja o link abaixo: Completamente
SuperML
Superml é um dos famosos pacotes R para IA que fornece uma interface padrão para clientes que usam dialetos de programação Python e R para construir modelos de IA.. Este pacote essencialmente fornece os destaques do Scikit Learn e a interface de previsão para preparar modelos de IA em R. Além de construir modelos de IA, existem funcionalidades convenientes para executar a engenharia de funções.
Para instalar este pacote, use o seguinte código:
install.packages('superml')
Para maiores informações, veja o link abaixo: SuperML
Obrigado por ler este artigo e por sua paciência.. Deixe-me na seção de comentários sobre comentários. Compartilhe este artigo, isso me motivará a escrever mais blogs para a comunidade de ciência de dados.
Obrigado por ler isso. se você gosta deste item, Compartilhe com seus amigos. Em caso de alguma sugestão / dúvida, Comente abaixo.
Identificação de e-mail: [e-mail protegido]
Me siga no LinkedIn: LinkedIn
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





