Introdução
Eu sou um grande fã de R, Não é segredo.. Eu confio nele desde que aprendi estatística na faculdade.. De fato, A ainda é a minha linguagem preferida para projetos de aprendizado de máquina.
Três coisas me atraíram principalmente para R:
- Sintaxe fácil de entender e de usar
- A incrível ferramenta RStudio
- Pacotes R!
O R oferece um grande número de pacotes para executar tarefas de aprendizado de máquina, que incluem 'dplyr’ para manipulação de dados, «ggplot2’ para visualização de dados, 'caret’ para a construção de modelos ML, etc.

Existem até pacotes R para funções específicas, que incluem pontuação de risco de crédito, Extraindo dados de sites, econometria, etc. Há uma razão pela qual R é amado entre os estatísticos de todo o mundo.: o grande número de pacotes R disponíveis torna a vida muito mais fácil.
Neste artigo, Mostrarei oito pacotes R que passaram despercebidos entre os cientistas de dados, mas eles são incrivelmente úteis para executar tarefas específicas de aprendizado de máquina. Para começar, Eu incluí um exemplo junto com o código para cada pacote.
Créame, seu amor por R está prestes a passar por outra revolução!!
Os pacotes R que abordaremos neste artigo
Eu dividi amplamente esses pacotes R em três categorias:
- Visualização de dados
- Aprendizado de máquina
- Outros pacotes diversos R
- Bono: Mais pacotes R!
Visualização de dados

R é uma ferramenta incrível para visualizar dados. A facilidade com que podemos gerar todos os tipos de gráficos com apenas uma ou duas linhas de código?? Verdadeiramente uma poupança de tempo.
O R fornece aparentemente inúmeras maneiras de visualizar seus dados. Mesmo quando estou usando Python para uma determinada tarefa, Volto ao R para explorar e visualizar meus dados. Tenho certeza de que a maioria dos usuários de R se sente da mesma maneira!!
Vejamos alguns pacotes R incríveis, mas menos conhecidos, para realizar análises exploratórias de dados.
Este é o meu pacote de referência para realizar análise exploratória de dados. Desde a plotagem da estrutura de dados até gráficos QQ e até mesmo a criação de relatórios para seu conjunto de dados, Este pacote faz tudo.
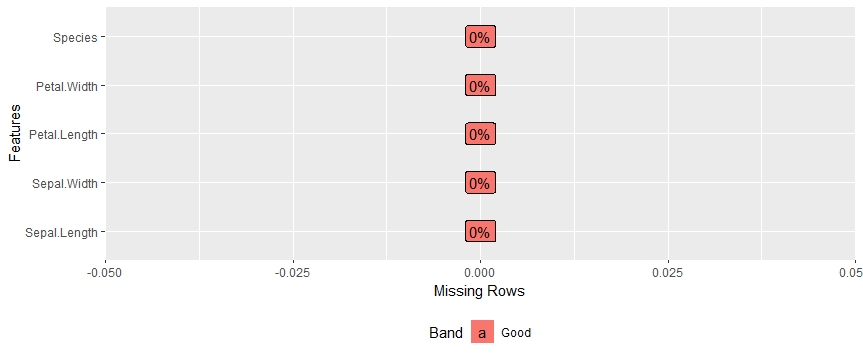
Vamos ver o que o DataExplorer pode fazer com um exemplo. Por favor, note que armazenamos os nossos dados no dados variável. Agora, Queremos descobrir a porcentagem de valores ausentes em cada recurso presente. Isso é extremamente útil ao trabalhar com conjuntos de dados massivos e calcular a soma dos valores ausentes pode ser demorado..
Você pode instalar o DataExplorer usando o código a seguir:
install.packages("Explorador de Dados")
Agora vamos ver o que o DataExplorer pode fazer por nós:
biblioteca(Explorador de Dados) dados(íris) plot_missing(íris)
Obtemos um gráfico realmente intuitivo para valores perdidos:
Um dos meus aspectos favoritos do DataExplorer é o relatório completo que podemos gerar usando apenas uma linha de código.:
create_report(íris)
Abaixo estão os diferentes tipos de fatores que obtemos neste relatório:

Você pode acessar o relatório completo via esse link. Um pacote MUITO útil.
Que tal um plugin de arrastar e soltar’ para gerar gráficos em R? Está correto – esquivar é um pacote que permite que você continue criando gráficos sem ter que codificá-los.
![]()
Esquisse é baseado no pacote ggplot2. Isso significa que você pode explorar seus dados interativamente no ambiente esquisse gerando gráficos ggplot2..
Use o código a seguir para instalar e carregar esquivar na sua máquina:
# From CRAN
install.packages("esquisse")
#Load the package in R
library(esquisse)
esquisse::esquisser() #helps in launching the add-inVocê também pode iniciar o plugin esquisse através do menu RStudio. A interface do usuário esquisse se parece com isso:
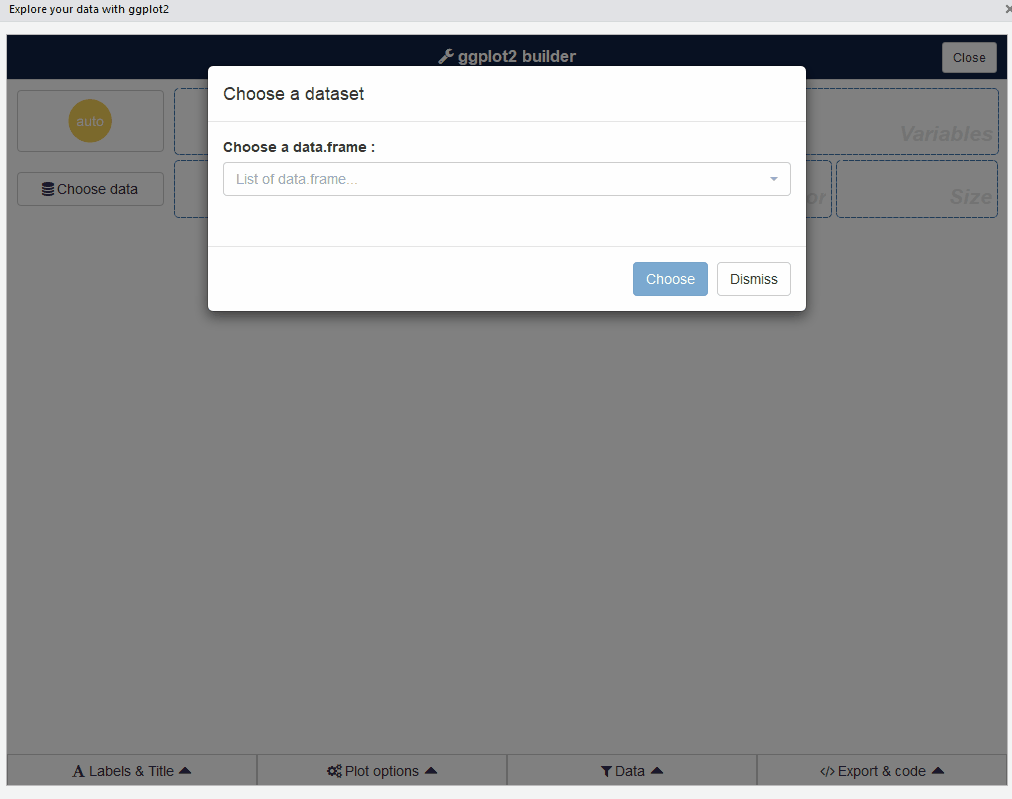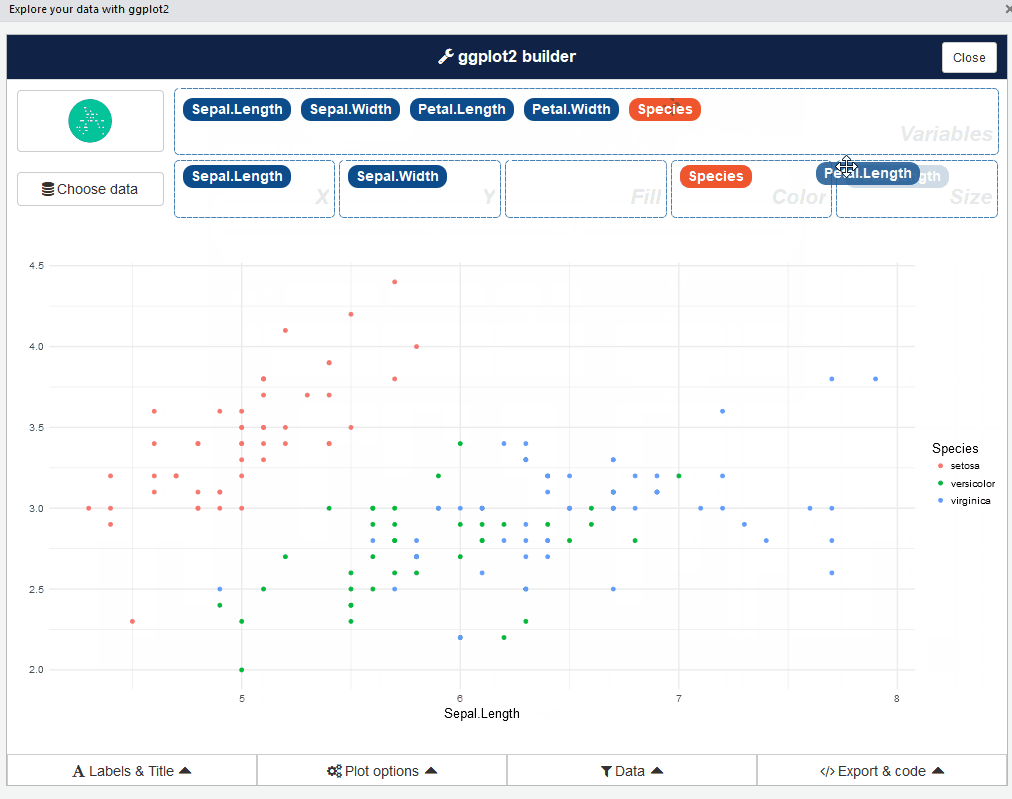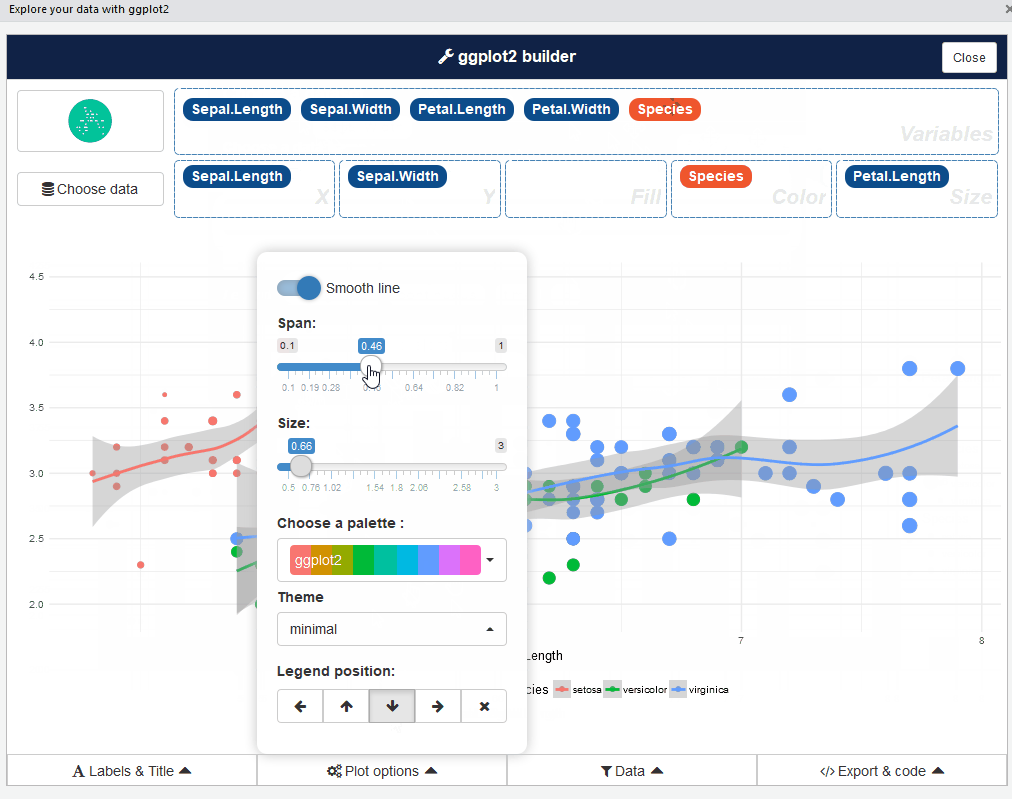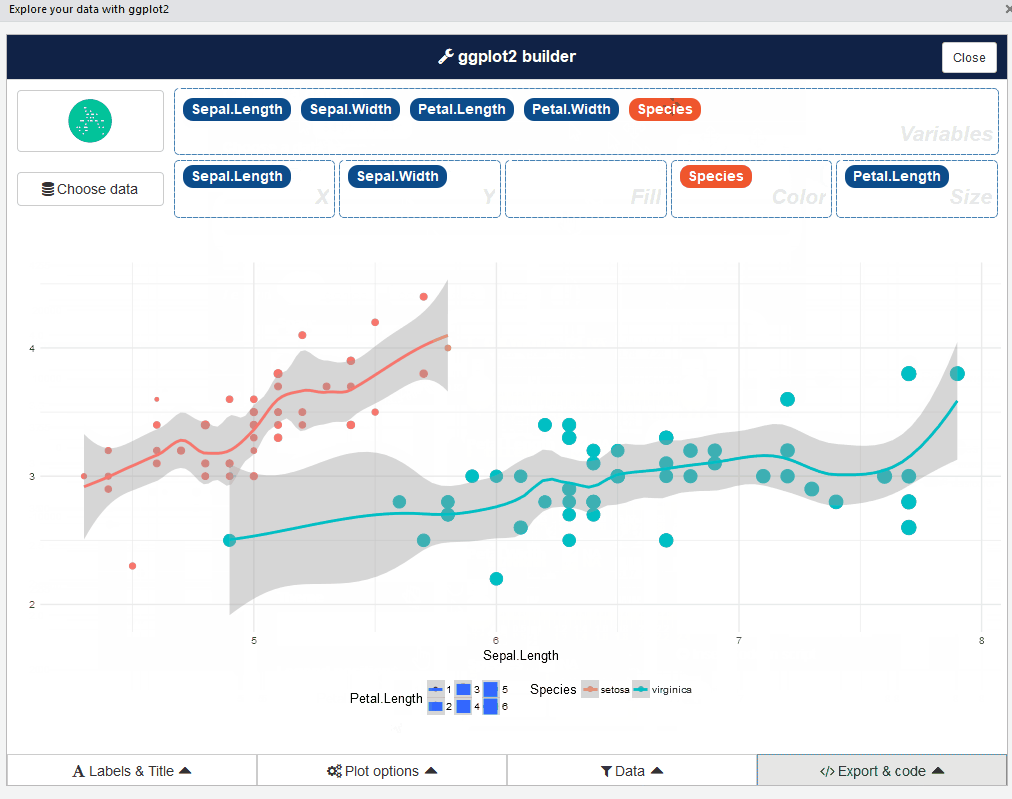
Bastante bem, verdade? Vá em frente e jogue com diferentes tipos de enredos: É uma experiência reveladora.
Aprendizado de máquina

Ah, criar modelos de aprendizado de máquina em R. Os cientistas de dados do Santo Graal se esforçam para realizar novos projetos de aprendizado de máquina. Você pode ter usado o pacote 'caret'’ para construir modelos mais cedo.
Agora, Deixe-me apresentá-lo a alguns pacotes R que podem mudar a maneira como você aborda o processo de construção do modelo.
Uma das principais razões pelas quais o Python ficou à frente do R foi graças às suas bibliotecas centradas em aprendizado de máquina. (como scikit-aprender). Por muito tempo, R não tinha essa habilidade. Claro que você poderia usar pacotes diferentes para executar diferentes tarefas de ML, Mas não havia um único pacote que pudesse fazer tudo.. Tivemos que chamar três bibliotecas diferentes para construir três modelos diferentes..
Não é o ideal.
E então veio o pacote MLR.. É um pacote incrível que nos permite executar todos os tipos de tarefas de aprendizado de máquina.. O MLR inclui todos os algoritmos populares de aprendizado de máquina que usamos em nossos projetos.
![]()
Eu recomendo a leitura do seguinte artigo para se aprofundar no MLR:
Vamos ver como instalar o MLR e criar um modelo de floresta aleatória no conjunto de dados da íris:
install.packages("Mir")
biblioteca(Mir)
# Load the dataset
data(íris)
# create task
task = makeClassifTask(id = "íris", íris, target = "Espécie")
# create learner
learner = makeLearner("classif.randomForest")
# build model and evaluate
holdout(Aluno, tarefa)
# measure accuracy
holdout(Aluno, tarefa, medidas = acc)
Produção:
Resample Result Task: iris Learner: classif.randomForest Aggr perf: acc.test.mean=0,9200000 # 92% precisão - Nada mau! Tempo de execução: 0.0239332
Um problema comum com as diferentes funções disponíveis em R (que fazem a mesma coisa) é que eles podem ter diferentes interfaces e argumentos. Vamos pegar o algoritmo de floresta aleatória, por exemplo. O código que você usaria no floresta aleatória e o pacote Ponto de agrupamento O pacote é diferente, verdade?
Como MLR, pastinaca Elimina o problema de referenciar vários pacotes para um determinado algoritmo de aprendizado de máquina. Imitar com sucesso o pacote scikit-learn do Python em R.
Vejamos o exemplo simples a seguir para lhe dar uma ideia de como pastinaca Funciona para um problema de regressão linear:
install.packages("Pastinaca")
biblioteca(Pastinaca)
#Load the dataset
data(mtcars)
#Build a linear regression model
fit <- linear_reg("Regressão") %>%
set_engine("lm") %>%
ajuste(mpg ~., dados = mtcars)
ajustar #extracts os valores do coeficiente
Produção:
parsnip model object
Call:
Estatísticas::lm(fórmula = fórmula, dados = dados)
Coeficientes:
(Interceptar) CyL Disp HP Drat WT QSEC
12.30337 -0.11144 0.01334 -0.02148 0.78711 -3.71530 0.82104
vs am engrenagem carb
0.31776 2.52023 0.65541 -0.19942
Ranger é um dos meus pacotes R favoritos. Eu uso regularmente florestas aleatórias para criar modelos de linha de base, Especialmente quando participo de hackathons de ciência de dados.
Aqui está uma pergunta: Quantas vezes você encontrou um cálculo de floresta aleatória lento para grandes conjuntos de dados em R? Isso acontece com muita frequência na minha máquina antiga.
Pacotes como o símbolo do acento circunflexo, Florestas aleatórias e de RF exigem muito tempo para calcular os resultados. O pacote 'Ranger'’ Acelera nosso processo de construção de modelos para o algoritmo de floresta aleatória. Ajuda a criar rapidamente um grande número de árvores em menos tempo.
Vamos codificar um modelo de floresta aleatória usando Ranger:
install.packages("Guarda-florestal")
#Load the Ranger package
require(Guarda-florestal)
Guarda-florestal(Espécie~ ., dados = íris,num.trees=100,mtry=3)
train.idx <- amostra(agora(íris), 2/3 * agora(íris))
iris.train <- íris[train.idx, ]
iris.test <- íris[-train.idx, ]
rg.íris <- Guarda-florestal(Espécie~ ., dados = iris.train)
pred.iris <- prever(rg.íris, dados = iris.test)
#Build a confusion matrix
table(iris.test$Species, pred.iris$previsões)
Produção:
setosa versicolor virginica
setosa 16 0 0
Versicolor 0 16 2
virginica 0 0 16
Um desempenho bastante impressionante. Você deve testar o Ranger em conjuntos de dados mais complexos e ver o quão mais rápido seus cálculos se tornam.
Exausto ao executar seu modelo de regressão linear em diferentes partes de dados e calcular as métricas de avaliação para cada modelo? a ronrom Pacote vem em seu socorro.
Você também pode criar modelos lineares generalizados (glm) para diferentes partes de dados e calcular valores-p para cada recurso em forma de lista. As vantagens de ronrom são infinitos!
Vamos ver um exemplo para entender sua funcionalidade. Vamos construir um modelo de regressão linear aqui e submontar os valores R-quadrado:
#Primeiro, read in the data mtcars data(mtcars) mtcars %>% dividir(.$Cyl) %>% #selecting cylinder to create three sets of data using the cyl values map(~Lm(mpg ~ wt, dados = .)) %>% mapa(resumo) %>% map_dbl("r.quadrado")
Produção
4 6 8 0.5086326 0.4645102 0.4229655
Então, Você observou? Este exemplo usa ronrom para resolver um problema bastante realista:
- Dividir um quadro de dados em partes
- Ajustar um modelo a cada peça
- Calcular o resumo
- Finalmente, extrai valores R-quadrados
Isso nos poupa muito tempo, verdade? Em vez de executar três modelos diferentes e três comandos para criar um subconjunto do valor R-quadrado, Usamos apenas uma linha de código.
Serviços de utilidade pública: Outros pacotes R incríveis
Vejamos alguns outros pacotes que não necessariamente se enquadram no guarda-chuva do "aprendizado de máquina". Eu os achei úteis em termos de trabalhar com R em geral..
A análise de sentimentos é uma das aplicações mais populares do aprendizado de máquina. É uma realidade inescapável no mundo digital de hoje.. E o Twitter é um alvo principal para extrair tweets e criar modelos para entender e prever sentimentos..
Agora, existem alguns pacotes R para extrair / raspar Tweets e realizar análise de sentimento. O pacote 'rtweet'’ faz o mesmo. Então, Como é diferente dos outros pacotes que existem?
![]()
'rtweet’ também ajuda você a verificar as tendências dos próprios tweets da própria R.. Impressionante!
# instalar rtweet de CRAN install.packages("rtweet") # pacote rtweet de carregamento biblioteca(rtweet)
Todos os usuários devem estar autorizados a interagir com a API do Twitter. Para obter autorização, Siga as instruções abaixo:
1.Criar um aplicativo do Twitter
2. Criar e salvar seu token de acesso
Para obter um procedimento detalhado passo a passo para obter a autenticação do Twitter, Siga este link aqui.
Você pode procurar por tweets com certas hashtags simplesmente pela linha de código mencionada abaixo. Vamos tentar procurar todos os tweets com a hashtag #avengers já que Guerra Infinita está pronto para o lançamento..
#1000 Tweets com hashtag Vingadores tweets <- search_tweets( "#Vingadores", n = 1000, include_rts = FALSO)
Você pode até acessar os IDs de usuário de pessoas que seguem uma determinada página. Vamos ver um exemplo:
## obter IDs de usuário de contas seguindo marvel marvel_flw <- get_followers("maravilha", n = 20000)
Você pode fazer muito mais com este pacote. Experimente e não se esqueça de atualizar a comunidade se você encontrar algo emocionante.
Adoro codificar em R e Python, mas você quer continuar com RStudio? Reticular é a resposta!! O pacote resolve esse problema importante fornecendo uma interface Python em R. Você pode facilmente usar as principais bibliotecas Python como numpy!, pandas e matplotlib dentro de R!
Você também pode transferir seu progresso com dados facilmente de Python para R e de R para Python com apenas uma linha de código. Não é incrível? Confira o bloco de código abaixo para ver como é fácil executar Python em R.
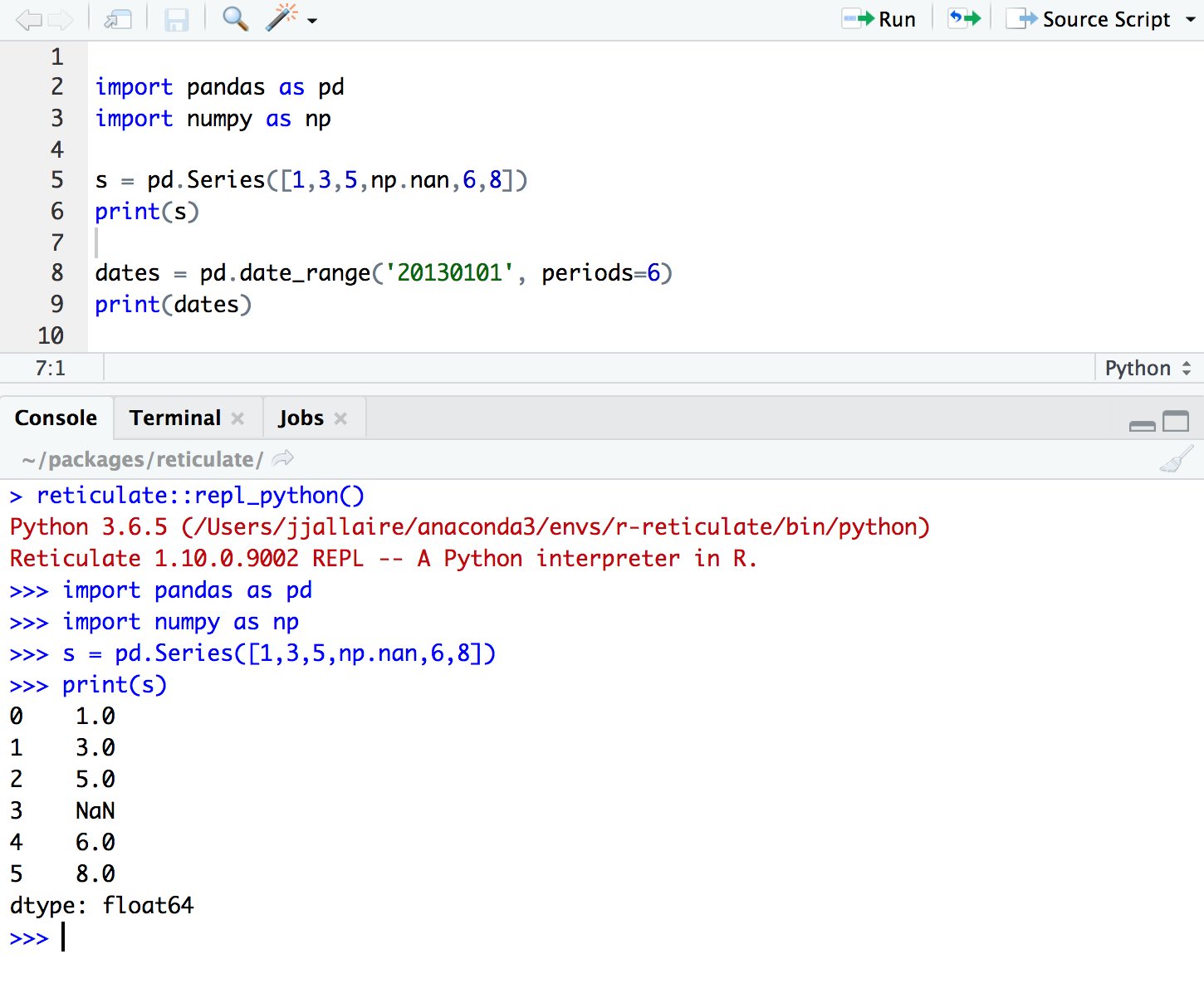
Antes de prosseguir com a instalação direta de reticulado em R, você precisará instalar o TensorFlow e o Keras primeiro.
install.packages("tensorflow")
install.packages("duro")
biblioteca(tensorflow)
biblioteca(duro)
install_keras()
install.packages("Reticulado")
biblioteca(Reticulado)
E você está pronto para ir!! Execute os comandos que forneci anteriormente na captura de tela e teste seus projetos de ciência de dados de forma semelhante.
PRIMEIRO
Aqui estão dois outros pacotes de utilitários R para todos os seus nerds de programação!!
Você atualiza seus pacotes R individualmente? Pode ser uma tarefa tediosa, especialmente quando há vários pacotes em jogo.
O pacote 'InstallR'’ permite que você atualize o R e todos os seus pacotes usando um único comando! Em vez de verificar a versão mais recente de cada pacote, podemos usar o InstallR para atualizar todos os pacotes de uma só vez.
# instalando/carregando o pacote:
E se(!Requer(instalador)) {
install.packages("instalador"); Requer(instalador)} #carga / instalar+carregar instalador
# usando o pacote:
Atualizador() # isso iniciará o processo de atualização da instalação do R.
# Ele verificará se há versões mais recentes, e se um estiver disponível, irá guiá-lo através das decisões que você precisa tomar
Qual pacote você usa para instalar bibliotecas do GitHub? A maioria de nós confia no pacote 'devtools'’ por um longo tempo. Parecia ser o único caminho. Mas havia uma ressalva.: Precisávamos lembrar o nome do desenvolvedor para instalar um pacote:
Com o pacote 'githubinstall', O nome do desenvolvedor não é mais necessário.
install.packages("githubinstall")
#Install any GitHub package by supplying the name
githubinstall("Nome do pacote")
#githubinstall("Detecção de anomalias")
Notas finais
Esta não é de maneira alguma uma lista exaustiva. Existem muitos outros pacotes R que têm recursos úteis, Mas a maioria os ignorou..
Você sabe de algum pacote que eu perdi neste artigo? Ou você já usou algum dos mencionados acima para o seu projeto?? Eu adoraria ouvir de você!! Conecte-se comigo na seção de comentários abaixo e vamos falar sobre R!!





