objetivo
- El impulso es una técnica de aprendizaje conjunto en la que cada modelo intenta corregir los errores del modelo anterior.
- Aprenda sobre el algoritmo de aumento de gradienteGradiente é um termo usado em vários campos, como matemática e ciência da computação, descrever uma variação contínua de valores. Na matemática, refere-se à taxa de variação de uma função, enquanto em design gráfico, Aplica-se à transição de cores. Esse conceito é essencial para entender fenômenos como otimização em algoritmos e representação visual de dados, permitindo uma melhor interpretação e análise em... y las matemáticas detrás de él.
Introdução
Neste artigo, vamos a discutir un algoritmo que funciona en la técnica de impulso, el algoritmo de aumento de gradiente. Es más conocido como Gradient Boosting Machine o GBM.
Observação: Se você está mais interessado em aprender conceitos em formato audiovisual, temos esse artigo completo explicado no vídeo abaixo. Sim, não é assim, você pode continuar lendo.
Los modelos en Gradient Boosting Machine se están construyendo secuencialmente y cada uno de estos modelos posteriores intenta reducir el error del modelo anterior. Pero la pregunta es ¿cómo cada modelo reduce el error del modelo anterior? Se hace construyendo el nuevo modelo sobre errores o residuales de las predicciones anteriores.
Esto se hace para determinar si hay algún patrón en el error que el modelo anterior pasa por alto. Vamos entender isso com um exemplo.
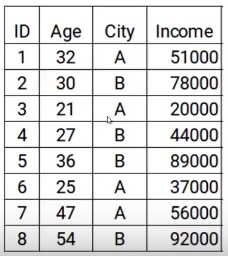
Aquí tenemos los datos con dos características: edad y ciudad, e o variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... objetivo es el ingreso. Então, según la ciudad y la edad de la persona, tenemos que predecir los ingresos. Tenga en cuenta que a lo largo del proceso de aumento de gradiente, actualizaremos lo siguiente: el objetivo del modelo, el residuo del modelo y la predicción.
Pasos para construir el modelo de máquina de aumento de gradiente
Para simplificar la comprensión de la máquina de aumento de gradiente, hemos dividido el proceso en cinco pasos simples.
Paso 1
El primer paso es construir un modelo y hacer predicciones sobre los datos dados. Volvamos a nuestros datos, para el primer modelo, el objetivo será el valor de Ingresos dado en los datos. Então, he establecido el objetivo como valores originales de Ingresos.
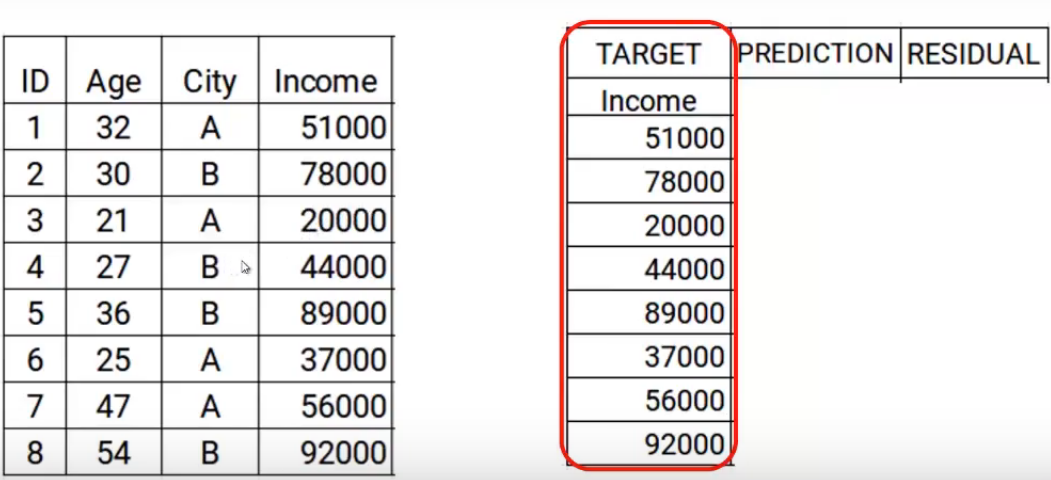
Ahora construiremos el modelo usando las características edad y ciudad con el ingreso objetivo. Este modelo entrenado podrá generar un conjunto de predicciones. Los cuales se suponen como sigue.
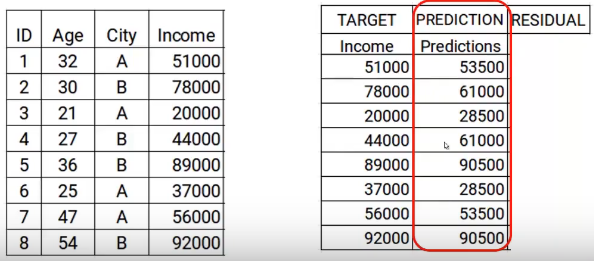
Ahora almacenaré estas predicciones con mis datos. Aquí es donde completo el primer paso.
Paso 2
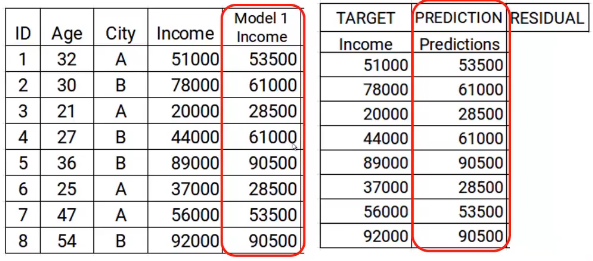
El siguiente paso es utilizar estas predicciones para obtener el error, que se utilizará más adelante como objetivo. Por el momento tenemos los valores de Ingresos reales y las predicciones del modelo1. Usando estas columnas, calcularemos el error simplemente restando los ingresos reales y las predicciones de ingresos. A se muestra a continuación.
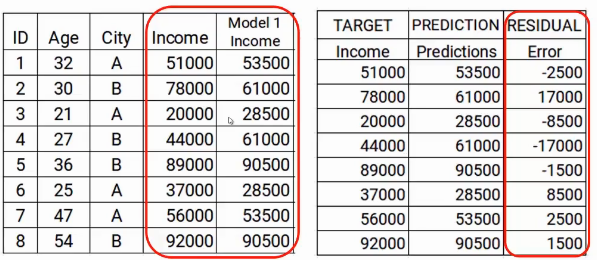
Como mencionamos anteriormente, los modelos sucesivos se centran en el error. Então, los errores aquí serán nuestro nuevo objetivo. Eso cubre el paso dos.
Paso 3
Na próxima etapa, crearemos un modelo sobre estos errores y realizaremos las predicciones. Aquí la idea es determinar si hay algún patrón oculto en el error.
Então, usando el error como objetivo y las características originales Edad y Ciudad, generaremos nuevas predicciones. Tenga en cuenta que las predicciones, neste caso, serán los valores de error, no los valores de ingresos previstos, ya que nuestro objetivo es el error. Digamos que el modelo da las siguientes predicciones
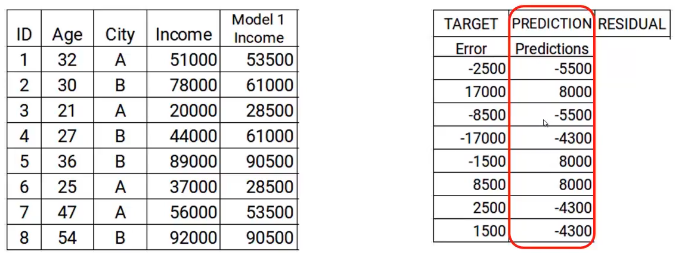
Paso 4
Ahora tenemos que actualizar las predicciones de model1. Agregaremos la predicción del paso anterior y la agregaremos a la predicción de model1 y la llamaremos Model2 Income.
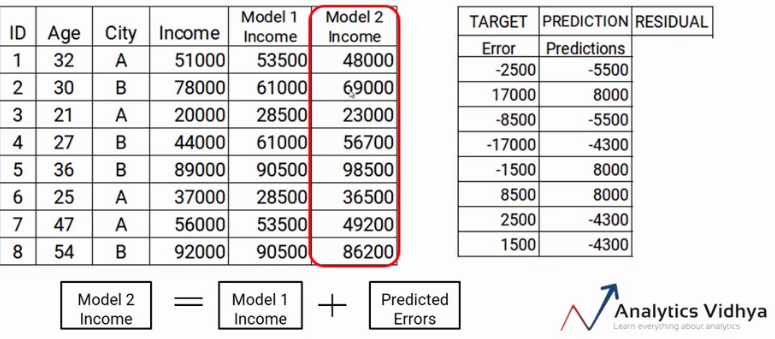
Como você pode ver, mis nuevas predicciones se acercan más a los valores reales de mis ingresos.
Finalmente, repetiremos los pasos 2 uma 4, lo que significa que estaremos calculando nuevos errores y estableciendo este nuevo error como objetivo. Repetiremos este proceso hasta que el error sea cero o hayamos alcanzado el criterio de detención, que dice la cantidad de modelos que queremos construir. Ese es el proceso paso a paso de construir un modelo de aumento de gradiente.
Em poucas palavras, construimos nuestro primer modelo que tiene características xy objetivo y, llamémosle a este modelo H0 que es una función de xey. Luego construimos el siguiente modelo sobre los errores del último modelo y un tercer modelo sobre los errores del modelo anterior y así sucesivamente. Hasta que construyamos n modelos.
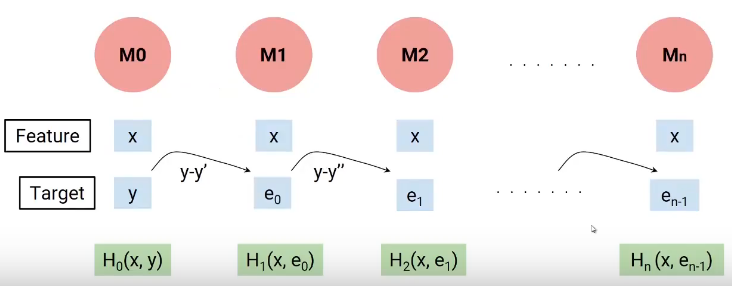
Cada modelo sucesivo trabaja sobre los errores de todos los modelos anteriores para intentar identificar cualquier patrón en el error. Efectivamente, puedo decir que cada uno de estos modelos son funciones individuales que tienen la variable independiente x como característica y el objetivo es el error del modelo combinado anterior.
Então, para determinar la ecuación final de nuestro modelo, construimos nuestro primer modelo H0, que me dio algunas predicciones y generó algunos errores. Llamemos a este resultado combinado F0 (X).
Ahora creamos nuestro segundo modelo y agregamos nuevos errores predichos a F0 (X), esta nueva función será F1 (X). de forma similar, construiremos el siguiente modelo y así sucesivamente, hasta que tengamos n modelos como se muestra a continuación.
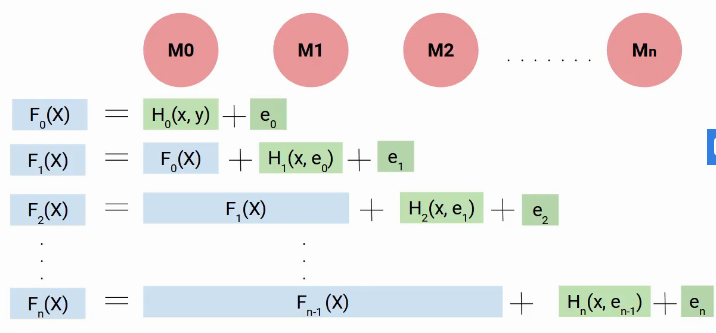
Então, em cada passo, intentamos modelar los errores, lo que nos ayuda a reducir el error general. Idealmente, queremos que este ‘en’ sea cero. Como você pode ver, cada modelo aquí está tratando de aumentar el rendimiento del modelo, portanto, usamos el término impulso.
Pero por qué usamos el término gradiente, aquí está el truco. En lugar de agregar directamente estos modelos, los agregamos con peso o coeficiente, y el valor correcto de este coeficiente se decide utilizando la técnica de aumento de gradiente.
Por tanto, una forma más generalizada de nuestra ecuación será la siguiente.
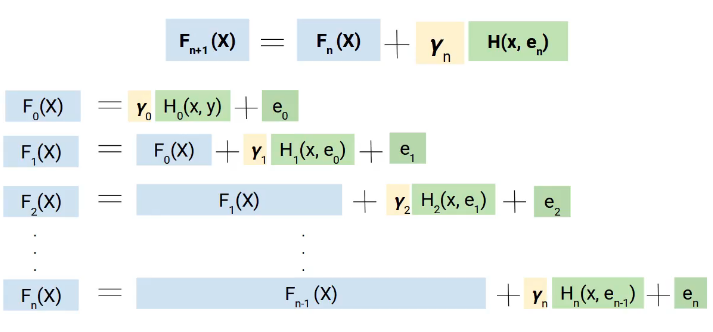
Las matemáticas detrás de Gradient Boosting Machine
Espero que ahora tengas una idea amplia de cómo funciona el aumento de gradiente. De aquí en adelante, nos centraremos en cómo se calcula el valor de Yn.
Usaremos la técnica de descenso de gradiente para obtener los valores de estos coeficientes gamma (E), de manera que minimicemos la Função de perdaA função de perda é uma ferramenta fundamental no aprendizado de máquina que quantifica a discrepância entre as previsões do modelo e os valores reais. Seu objetivo é orientar o processo de treinamento, minimizando essa diferença, permitindo assim que o modelo aprenda de forma mais eficaz. Existem diferentes tipos de funções de perda, como erro quadrático médio e entropia cruzada, cada um adequado para diferentes tarefas e.... Ahora profundicemos en esta ecuación y comprendamos el papel de la función de pérdida y gamma.
Aqui, la función de pérdida que estamos usando es (y-y ‘) 2. y es el valor real e y ‘es el valor final predicho por el último modelo. Então, podemos reemplazar y ‘con Fn (X) que representa el objetivo real menos las predicciones actualizadas de todos los modelos que hemos construido hasta ahora.
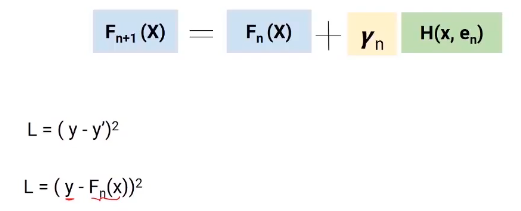
Diferenciación parcial
Creo que estará familiarizado con el proceso de descenso de gradientes, ya que vamos a utilizar el mismo concepto. Diferenciaremos la ecuación de L con respecto a Fn (X), obtendrás la siguiente ecuación, que también se conoce como pseudo residual. Cuál es el gradiente negativo de la función de pérdida.
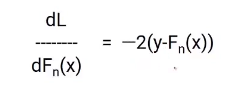
Para simplificar esto, multiplicaremos ambos lados por -1. El resultado será algo como esto.
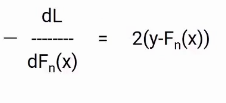
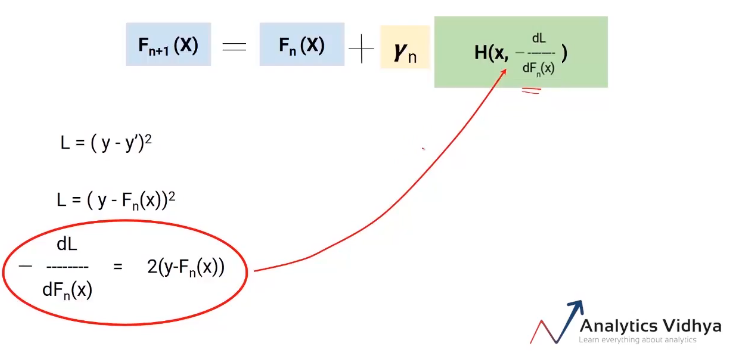
Agora, sabemos que el error en nuestra ecuación de Fn + 1 (X) es el valor real menos las predicciones actualizadas de todos los modelos. Portanto, podemos reemplazar el en en nuestra ecuación final con estos pseudo residuos como se muestra en la imagen a continuación.
Entonces esta es nuestra ecuación final. La mejor parte de este algoritmo es que le da la libertad de decidir la función de pérdida. La única condición es que la función de pérdida sea diferenciable. Para facilitar a compreensão, usamos una función de pérdida muy simple (y-y ‘) 2 pero puede cambiarla a una pérdida de bisagra o una pérdida logit o cualquier cosa.
El objetivo es minimizar la pérdida total. Veamos cuál sería la pérdida total aquí, será la pérdida hasta el modelo n más la pérdida del modelo actual que estamos construyendo. Aquí está la ecuación.
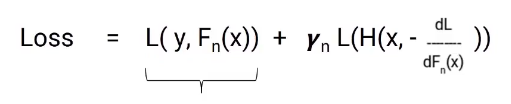
En esta ecuación, la primera parte es fija, pero la segunda parte es la pérdida del modelo en el que estamos trabajando actualmente. La pérdida de este modelo aún no se puede cambiar, pero podemos cambiar el valor de gamma. Ahora tenemos que seleccionar el valor de gamma de modo que la pérdida total se minimice y este valor se seleccione mediante el proceso de descenso de gradiente.
Então, la idea es reducir la pérdida general al decidir el valor óptimo de gamma para cada modelo que construimos.
Árbol de decisión de aumento de gradiente
Hablo de un caso especial de aumento de gradiente, quer dizer, árbol de decisión de aumento de gradiente (GBDT). Aqui, cada modelo sería un árbol y el valor de gamma se decidirá en cada nivel de hoja, no en el nivel general del modelo. Então, como mostrado na imagem a seguir, cada hoja tendría un valor gamma.
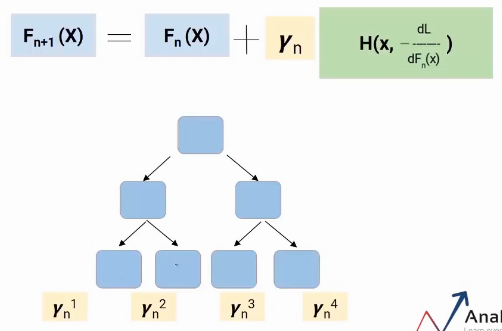
Así es como funciona Gradient Boosting Decision Tree.
Notas finais
Impulsar es un tipo de aprendizaje conjunto. Es un proceso secuencial donde cada modelo intenta corregir los errores del modelo anterior. Esto significa que cada modelo sucesivo depende de sus predecesores. Neste artigo, vimos el algoritmo de aumento de gradiente y las matemáticas detrás de él.
Como tenemos una idea clara del algoritmo, intente construir los modelos y obtenga algo de experiencia práctica con él.
Se você está procurando iniciar sua jornada de ciência de dados e deseja todos os tópicos sob o mesmo teto, sua busca para aqui. Dê uma olhada no AI e ML BlackBelt certificados da DataPeaker Mais Programa
Se você tiver alguma dúvida, deixe-me saber na seção de comentários!
Se você tem alguma dúvida, Deixe-me saber nos comentários abaixo.





