O desafio de fazer as máquinas entenderem o texto
“A linguagem é um excelente meio de comunicação”
Você e eu teríamos entendido essa frase em uma fração de segundo. Mas as máquinas simplesmente não podem processar dados de texto em formato bruto. Eles precisam de nós para decompor o texto em um formato numérico que a máquina possa ler facilmente (a ideia por trás Processamento de linguagem natural!).
É aqui que os conceitos do Bag-of-Words entram em jogo. (Arco) y TF-IDF. BoW e TF-IDF são técnicas que nos ajudam a converter sentenças de texto em vetores numéricos.
Vou falar sobre Bag-of-Words e TF-IDF neste artigo. Usaremos um exemplo intuitivo e geral para entender cada conceito em detalhes.
Novo no processamento de linguagem natural (PNL)? Temos os cursos perfeitos para você começar:
Vamos dar um exemplo para entender o saco de palavras (Arco) y TF-IDF
Vou dar um exemplo popular para explicar Bag-of-Words (Arco) e TF-DF neste artigo.
Todos nós amamos assistir filmes (em vários graus). Sempre leio as críticas de um filme antes de me comprometer a vê-lo.. Eu sei que muitos de vocês fazem o mesmo! Então, vou usar este exemplo aqui.

Aqui está uma amostra de críticas sobre um determinado filme de terror:
- Revisão 1: este filme é muito assustador e longo
- Revisão 2: este filme não é assustador e é lento
- Revisão 3: este filme é assustador e bom
Você pode ver que há algumas críticas contrastantes sobre o filme, bem como a duração e ritmo do filme. Imagine ver milhares de comentários como esses. Claramente, há muitos insights interessantes que podemos extrair e desenvolver para avaliar o desempenho do filme.
Porém, como vimos anteriormente, não podemos simplesmente dar essas frases a um modelo de aprendizado de máquina e pedir que ele nos diga se uma avaliação foi positiva ou negativa. Precisamos realizar certas etapas de pré-processamento de texto.
Bag-of-Words e TF-IDF são dois exemplos de como fazer isso. Vamos entender em detalhes.
Crie vetores a partir de texto
Você pode pensar em algumas técnicas que poderíamos usar para vetorizar uma frase no início? Os requisitos básicos seriam:
- Não deve resultar em uma matriz esparsa, pois matrizes esparsas resultam em alto custo computacional
- Devemos ser capazes de reter a maior parte das informações linguísticas presentes na frase.
A incorporação de palavras é uma daquelas técnicas em que podemos representar texto usando vetores. As formas mais populares de incrustações de palavras são:
- Arco, o que significa saco de palavras
- TF-IDF, O que significa Freqüência do Termo - Freqüência Inversa do Documento?
Agora, vamos ver como podemos renderizar resenhas de filmes anteriores como incrustações e prepará-las para um modelo de aprendizado de máquina.
Modelo de bolsa de palavras (Arco)
El modelo Saco de Palavras (Arco) é a maneira mais simples de representar texto em números. Como o próprio termo, podemos representar uma frase como um vetor de saco de palavras (uma seqüência de números).
Lembre-se dos três tipos de resenhas de filmes que vimos antes:
- Revisão 1: este filme é muito assustador e longo
- Revisão 2: este filme não é assustador e é lento
- Revisão 3: este filme é assustador e bom
Vamos primeiro construir um vocabulário a partir de todas as palavras únicas nas três revisões anteriores. O vocabulário consiste nestes 11 palavras: 'Está', 'filme', 'isto é', 'muito', 'apavorante', 'e', 'grande', 'não', 'devagar', 'Arrepiante', 'Nós vamos '.
Agora podemos pegar cada uma dessas palavras e marcar sua aparição nas três resenhas de filmes anteriores com 1 e 0. Isso vai nos dar 3 vetores para 3 avaliações:
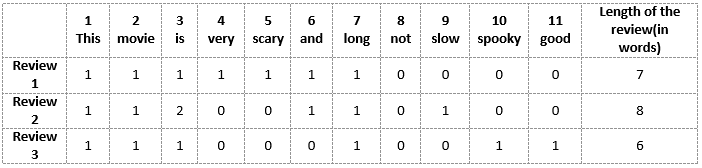
Vetor de revisão 1: [1 1 1 1 1 1 1 0 0 0 0]
Vetor de revisão 2: [1 1 2 0 0 1 1 0 1 0 0]
Vetor de revisão 3: [1 1 1 0 0 0 1 0 0 1 1]
E essa é a ideia central por trás do modelo do Saco de Palavras. (Arco).
Desvantagens de usar um modelo de saco de palavras (Arco)
No exemplo acima, podemos ter vetores de comprimento 11. Porém, começamos a enfrentar problemas quando encontramos novas frases:
- Se as novas frases contiverem novas palavras, então o tamanho do nosso vocabulário aumentaria e, portanto, o comprimento dos vetores também aumentaria.
- O que mais, os vetores também conteriam muitos zeros, o que resultaria em uma matriz esparsa (o que gostaríamos de evitar)
- Não retemos informações sobre a gramática das frases ou a ordem das palavras no texto.
Frequência do termo - frequência inversa dos documentos (TF-IDF)
Vamos primeiro colocar uma definição formal em torno do TF-IDF. É assim que a Wikipedia coloca:
“A frequência dos termos, a frequência inversa de documentos, é uma estatística numérica que tenta refletir a importância de uma palavra para um documento em uma coleção ou corpus”.
Frequência do termo (TF)
Primeiro, vamos entender o termo frequente (TF). Es una mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... de la frecuencia con la que aparece un término, t, em um documento, d:
![]()
Aqui, no numerador, n é o número de vezes que o termo aparece “t” no documento “d”. Portanto, cada documento e termo teria seu próprio valor TF.
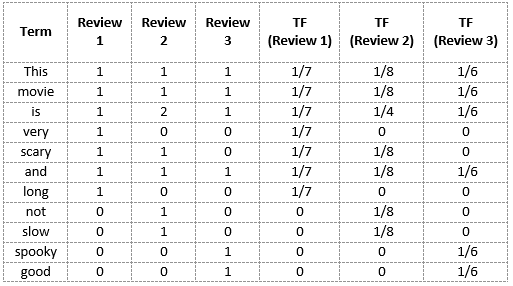
Mais uma vez, usaremos o mesmo vocabulário que construímos no modelo Bag-of-Words para mostrar como calcular o TF para a revisão # 2:
Revisão 2: este filme não é assustador e é lento
Aqui,
- Vocabulário: 'Está', 'filme', 'isto é', 'muito', ‘Aterrorizante’, 'e', 'Grande', 'não', 'devagar', 'Arrepiante', 'Boa’
- Número de palavras na revisão 2 = 8
- TF para a palavra 'isto’ = (número de vezes 'isso aparece’ em revisão 2) / (número de termos na revisão 2) = 1/8
Semelhante,
- TF ('filme') = 1/8
- TF ('isto é') = 2/8 = 1/4
- TF ('muito') = 0/8 = 0
- TF ('apavorante') = 1/8
- TF ('e') = 1/8
- TF ('grande') = 0/8 = 0
- TF ('não') = 1/8
- TF ('devagar') = 1/8
- TF ('Arrepiante') = 0/8 = 0
- TF ('Nós vamos') = 0/8 = 0
Podemos calcular as frequências de termo para todos os termos e todas as revisões desta forma:
Reverter a frequência do documento (IDF)
IDF é uma medida da importância de um termo. Precisamos do valor IDF porque calcular o TF sozinho não é suficiente para entender a importância das palavras:
![]()
Podemos calcular os valores IDF para todas as palavras na revisão 2:
IDF ('isto') = log (número de documentos / número de documentos contendo a palavra 'este') = log (3/3) = log (1) = 0
Semelhante,
- IDF ('filme',) = log (3/3) = 0
- IDF ('isto é') = log (3/3) = 0
- IDF ('não') = log (3/1) = log (3) = 0.48
- IDF ('apavorante') = log (3/2) = 0.18
- IDF ('e') = log (3/3) = 0
- IDF ('devagar') = log (3/1) = 0.48
Podemos calcular os valores IDF para cada palavra desta forma. Portanto, os valores IDF para todo o vocabulário seriam:
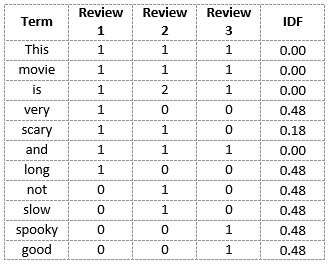
Por tanto, vemos que palavras como "es", "isto", "e", etc., eles são reduzidos a 0 e eles têm pouca importância; enquanto palavras como "assustador", "grande", "Nós vamos", etc. são palavras com mais importância e, portanto, têm maior valor.
Agora podemos calcular a pontuação TF-IDF para cada palavra do corpus. Palavras com uma pontuação mais alta são mais importantes e aquelas com uma pontuação mais baixa são menos importantes:
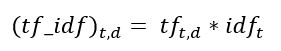
Agora podemos calcular a pontuação TF-IDF para cada palavra na revisão 2:
TF-IDF ('isto', Revisão 2) = TF ('isto', Revisão 2) * IDF ('isto') = 1/8 * 0 = 0
Semelhante,
- TF-IDF ('filme', Revisão 2) = 1/8 * 0 = 0
- TF-IDF ('isto é', Revisão 2) = 1/4 * 0 = 0
- TF-IDF ('não', Revisão 2) = 1/8 * 0.48 = 0.06
- TF-IDF ('apavorante', Revisão 2) = 1/8 * 0.18 = 0.023
- TF-IDF ('e', Revisão 2) = 1/8 * 0 = 0
- TF-IDF ('devagar', Revisão 2) = 1/8 * 0.48 = 0.06
Do mesmo modo, podemos calcular as pontuações do TF-IDF para todas as palavras em relação a todas as avaliações:
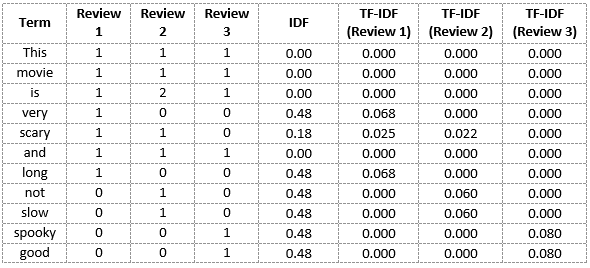
Obtivemos agora as pontuações do TF-IDF para o nosso vocabulário. TF-IDF também fornece valores maiores para palavras menos frequentes e é alto quando os valores IDF e TF são altos, quer dizer, a palavra é rara em todos os documentos combinados, mas frequente em um único documento.
Notas finais
Deixe-me resumir o que abordamos no artigo:
- Bag of Words simplesmente cria um conjunto de vetores contendo a contagem de ocorrências de palavras no documento (avaliações), enquanto o modelo TF-IDF contém informações sobre as palavras mais importantes e menos importantes também.
- Os vetores do saco de palavras são fáceis de interpretar. Porém, TF-IDF geralmente funciona melhor em modelos de aprendizado de máquina.
Embora Bag-of-Words e TF-IDF tenham sido populares em seu próprio sentido, ainda havia uma lacuna na compreensão do contexto das palavras. Detecte a semelhança entre as palavras 'assustador’ e 'assustador', ou traduzir nossos documentos fornecidos para outro idioma, requer muito mais informações nos documentos.
É aqui que as técnicas de incorporação de palavras, como o Word2Vec, entram em ação., Saco contínuo de palavras (CBOW), Skipgram, etc. Você pode encontrar um guia detalhado para essas técnicas aqui:





