Introdução
Hoje em dia, organizações lidam com uma grande quantidade e uma ampla variedade de dados: ligações de clientes, seus e-mails, tweets, dados de aplicativos móveis e muito mais. É preciso muito esforço e tempo para que esses dados sejam úteis. Uma das habilidades básicas para extrair informações de dados de texto é o processamento de linguagem natural (PNL).
Processamento de linguagem natural (PNL) é a arte e a ciência que nos ajuda a extrair informações do texto e usá-las em nossos cálculos e algoritmos. Dado o aumento do conteúdo na Internet e nas redes sociais, é um dos itens indispensáveis para todos os cientistas de dados.
Quer você conheça PNL ou não, este guia deve ajudá-lo como uma referência pronta para você. Por meio deste guia, Eu forneci a você recursos e códigos para executar as tarefas mais comuns em PNL.
Depois de ler este guia, sinta-se à vontade para dar uma olhada em nosso curso de vídeo sobre processamento de linguagem natural (PNL).

Por que eu criei este guia?
Depois de trabalhar em problemas de PNL por algum tempo, Eu me deparei com várias situações em que precisei consultar centenas de fontes diferentes para estudar os últimos desenvolvimentos na forma de artigos de pesquisa, blogs e concursos para algumas das tarefas comuns da PNL. .
Então, Decidi reunir todos esses recursos em um só lugar e torná-lo uma solução completa para os recursos mais recentes e importantes para essas tarefas comuns da PNL.. Abaixo está a lista de tarefas abordadas neste artigo, juntamente com seus recursos relevantes.. Comecemos.
Tabela de conteúdo
- Derivado
- Lematización
- Embeddings de palavras
- Rotulando classes gramaticais
- Desambiguação de entidade nomeada
- Reconhecimento de entidade nomeada
- Análise de sentimentos
- Similaridade de texto semântico
- Identificação de linguagem
- Resumo do texto
1. Derivado
O que é Stemming ?: Derivação é o processo de redução de palavras (geralmente modificado ou derivado) à sua raiz ou raiz da palavra. O objetivo da raiz é reduzir as palavras relacionadas à mesma raiz, mesmo que a raiz não seja uma palavra do dicionário. Por exemplo, na lingua inglesa-
- Hermosa e belas são derivados de linda
- Melhor e Melhor são derivados de Melhor e Melhor respectivamente
Papel: a artigo original de Martin Porter no algoritmo de Porter para derivar.
Algoritmo: Aqui está a implementação Python do algoritmo de derivação Porter2.
Implementação: É assim que você pode derivar uma palavra usando o algoritmo Porter2 do à deriva Biblioteca.
2. Lematización
O que está começando ?: Stemming é o processo de reduzir um grupo de palavras ao seu lema ou forma de dicionário. Leva em consideração coisas como PDV (Partes do discurso), o significado da palavra na frase, o significado da palavra em frases fechadas, etc. antes de reduzir a palavra ao seu lema. Por exemplo, na lingua inglesa-
- Hermosa e belas são slogan para Hermosa e belas respectivamente.
- Boa, Melhor e Melhor são slogan para Boa, Boa e Boa respectivamente.
Documento 1: Este papel discute os diferentes métodos de lematização em grande detalhe. Uma leitura obrigatória se você quiser saber como funcionam os lematizadores tradicionais.
Documento 2: Este é um excelente trabalho que aborda o problema de derivação para idiomas ricos em variações usando Deep Learning.
Conjunto de dados: Este é o link para o conjunto de dados Treebank-3 que você pode usar se quiser criar seu próprio Lemmatiser.
Implementação: Abaixo está uma implementação de um Lemmatizer Inglês usando spacy.
#!pip install spacy#python -m spacy download enimport spacynlp=spacy.load("en")doc="good better best"
for token in nlp(doc): print(token,token.lemma_)
3. Embeddings de palavras
O que são embeddings de palavras ?: Word Embeddings é o nome das técnicas usadas para representar a linguagem natural na forma vetorial de números reais. Eles são úteis devido à incapacidade dos computadores de processar a linguagem natural. Então, esses embutidos de palavras capturam a essência e a relação entre palavras em linguagem natural usando números reais. E Word Embedding, una palabra o frase se representa en un vector de dimensão"Dimensão" É um termo usado em várias disciplinas, como a física, Matemática e filosofia. Refere-se à extensão em que um objeto ou fenômeno pode ser analisado ou descrito. Em física, por exemplo, fala-se de dimensões espaciais e temporais, enquanto em matemática pode se referir ao número de coordenadas necessárias para representar um espaço. Compreendê-lo é fundamental para o estudo e... fija de longitud, Digamos 100.
Por exemplo-
Uma palavra “cara” pode ser representado em um vetor de 5 dimensões como
![]()
onde cada um desses números é a magnitude da palavra em uma direção particular.
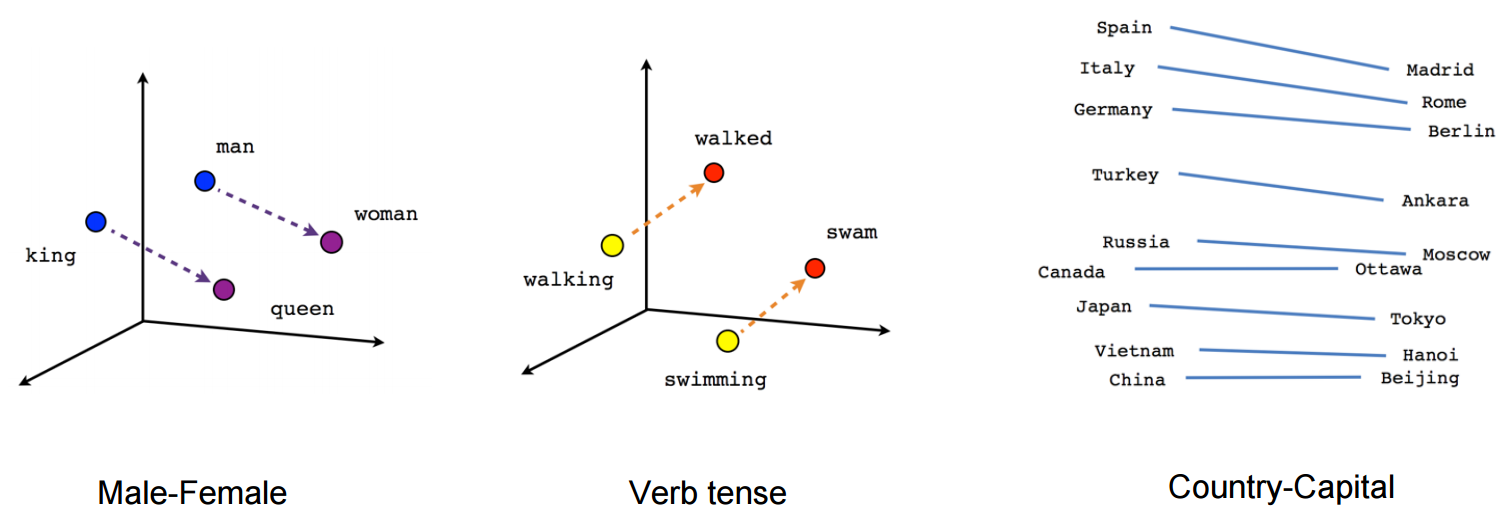
Blog: Aqui está um artigo que explica os embeddings do Word em detalhes.
Papel: Um papel muito bom que explica os vetores de palavras em detalhes. Uma leitura obrigatória para uma compreensão profunda dos vetores de palavras.
Ferramenta: Um navegador baseado ferramenta para visualizar vetores de palavras.
Vetores de palavras pré-treinados: Aqui está uma lista exaustiva de Vetores de palavras pré-treinados sobre 294 idiomas pelo facebook.
Implementação: É assim que você pode obter Word Vector pré-treinado de uma palavra usando o pacote gensim.
Faça o download do Vetores de palavras previamente treinados aqui no Google Notícias.
#!pip install gensimfrom gensim.models.keyedvectors import KeyedVectorsword_vectors=KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin',binary=True)word_vectors['human']
Implementação: É assim que você pode treinar seus próprios vetores de palavras usando gensim
sentence=[['first','sentence'],['second','sentence']]model = gensim.models.Word2Vec(sentence, min_count=1,size=300,workers=4)
4. Rotulando classes gramaticais
O que é marcação parcial de fala ?: Em termos simplistas, A marcação de parte do discurso é o processo de marcar palavras em uma frase como substantivos, verbos, adjetivos, advérbios, etc.. Por exemplo, na frase-
“Ashok matou a cobra com um pedaço de pau”
Partes do discurso são identificadas como:
Ashok PROPN
delicado VERBO
a A
cobra SUBSTANTIVO
com ADP
uma A
Palo SUBSTANTIVO
. APONTAR
Teste 1: Está apropriadamente intitulado papel de choi A última essência do estado da arte apresenta um novo método chamado Indução de Recurso Dinâmico que atinge o estado da arte na tarefa de marcação de POS
Documento 2: Este papel Apresenta etiquetagem de PDV autônomo usando modelos de Markov ocultos de âncora.
Implementação: É assim que podemos realizar a marcação de PDV usando spacy.
#!pip install spacy#!python -m spacy download en nlp=spacy.load('en')sentence="Ashok killed the snake with a stick"for token in nlp(sentence): print(token,token.pos_)
5. Desambiguação de entidade nomeada
O que é desambiguação de entidade nomeada ?: A desambiguação de entidades nomeadas é o processo de identificação de menções a entidades em uma frase. Por exemplo, na frase-
“A Apple obteve receita de 200 bilhões de dólares em 2016”
É tarefa da Designação de Entidades Nomeadas inferir que a Apple na frase é a empresa Apple e não uma fruta..
Entidade nomeada, em geral, requer uma base de conhecimento de entidade que você pode usar para vincular entidades na frase à base de conhecimento.
Documento 1: Este artigo de Huang faz uso de modelos de relacionamento semântico profundo baseados em redes neurais profundas em conjunto com a base de conhecimento para obter resultados de última geração na desambiguação de entidades nomeadas.
Documento 2: Este artigo de Ganea e Hofmann fazer uso da atenção neural local junto com embeddings do Word e sem funções criadas manualmente.
6. Reconhecimento de entidade nomeada
O que é reconhecimento de entidade nomeada ?: O reconhecimento de entidade nomeada é a tarefa de identificar entidades em uma frase e classificá-las em categorias como uma pessoa, organização, encontro, Localização, hora, etc. Por exemplo, um NER levaria uma frase como:
“Ram of Apple Inc. viajou para Sydney em 5 Outubro de 2017”
e retorna algo como
RAM
a partir de
maçã ORG
C ª. ORG
viajei
para
Sydney GPE
sobre
Quinto ENCONTRO
Outubro ENCONTRO
2017 ENCONTRO
Aqui, ORG significa Organização e GPE significa Localização.
O problema com os NERs atuais é que mesmo os NERs da próxima geração tendem a apresentar desempenho inferior quando usados em um domínio de dados diferente dos dados em que o NER foi treinado..

Papel: Este excelente papel usa LSTMs bidirecionais e combina métodos de aprendizagem supervisionados e não supervisionados para alcançar um resultado de última geração no reconhecimento de entidades nomeadas em 4 línguas.
Implementação: A seguir, explica como você pode realizar o reconhecimento de entidade nomeada usando spacy.
import spacynlp=spacy.load('en')sentence="Ram of Apple Inc. travelled to Sydney on 5th October 2017"for token in nlp(sentence): print(token, token.ent_type_)
7. Análise de sentimentos
O que é análise de sentimento ?: A análise de sentimento é uma ampla gama de análises subjetivas que usa técnicas de processamento de linguagem natural para realizar tarefas como identificar o sentimento de uma avaliação do cliente., sentimento positivo ou negativo em uma frase, julgar o humor usando análise de discurso ou análise de texto escrito, etc. Por exemplo:
"Não gostei do sorvete de chocolate" – é uma experiência negativa com sorvete.
“Eu não odiava sorvete de chocolate”: pode ser considerada uma experiência neutra
Há uma grande variedade de métodos usados para realizar a análise de sentimento, desde a contagem de palavras negativas e positivas em uma frase até o uso de LSTM com incrustações de palavras.
Blog 1: Este artigo se concentra na realização de análises de sentimento em tweets de filmes
Blog 2: Este artigo se concentra na realização de análises de sentimento de tweets durante o dilúvio de Chennai.
Documento 1: Este papel adopta el enfoque del método de aprendizagem supervisionadaO aprendizado supervisionado é uma abordagem de aprendizado de máquina em que um modelo é treinado usando um conjunto de dados rotulados. Cada entrada no conjunto de dados está associada a uma saída conhecida, permitindo que o modelo aprenda a prever resultados para novas entradas. Este método é amplamente utilizado em aplicações como classificação de imagens, Reconhecimento de fala e previsão de tendências, destacando sua importância em... con el método Naive Bayes para clasificar las revisiones de IMDB.
Documento 2: Este papel utiliza el método de Aprendizado não supervisionadoO aprendizado não supervisionado é uma técnica de aprendizado de máquina que permite que os modelos identifiquem padrões e estruturas em dados sem rótulos predefinidos. Por meio de algoritmos como k-means e análise de componentes principais, Essa abordagem é usada em uma variedade de aplicações, como segmentação de clientes, detecção de anomalias e compactação de dados. Sua capacidade de revelar informações ocultas o torna uma ferramenta valiosa no... con LDA para identificar aspectos y sentimientos de las opiniones generadas por los usuarios. Este documento se destaca por abordar o problema da escassez de resenhas comentadas..
Repositório: Este é um repositório incrível de trabalho de pesquisa e implementação de análise de sentimento em várias línguas.
Conjunto de dados 1: Conjunto de dados de opinião de vários domínios, versão 2.0
Conjunto de dados 2: Conjunto de dados de análise de sentimento do Twitter
Faça você mesmo a análise de sentimento do Twitter.
8. Similaridade de texto semântico
O que é similaridade semântica de texto ?: Similaridade semântica de texto é o processo de analisar a similaridade entre duas partes do texto no que diz respeito ao significado e substância do texto em vez de analisar a sintaxe das duas partes do texto. O que mais, a semelhança é diferente do relacionamento.
Por exemplo –
O carro e o ônibus são semelhantes, mas o carro e o combustível estão relacionados.
Documento 1: Este papel apresenta as diferentes abordagens para medir a similaridade do texto em detalhes. Um artigo de leitura obrigatória para aprender sobre as abordagens existentes em um só lugar.
Documento 2: Este papel apresenta a CNN para classificar um par de dois textos curtos
Documento 3: Este papel faz uso do Tree-LSTM que alcança um resultado de ponta na relação semântica dos textos e na classificação semântica.
9. Identificação de linguagem
O que é identificação de linguagem ?: A identificação da linguagem é a tarefa de identificar a linguagem em que o conteúdo é encontrado. Ele faz uso das propriedades estatísticas e sintáticas da linguagem para realizar esta tarefa. Também pode ser considerado um caso especial de classificação de texto.
Blog: Nesta postagem do blog fastText, apresentar uma nova ferramenta que pode identificar 170 línguas com 1 MB de uso de memória.
Documento 1: Este papel analisar 7 métodos de identificação de linguagem de 285 línguas.
Documento 2: Este papel descreve como as redes neurais profundas podem ser usadas para obter resultados de ponta na identificação automática de linguagem.
10. Resumo do texto
O que é o resumo do texto ?: O resumo de texto é o processo de encurtar um texto, identificando os pontos importantes do texto e criando um resumo usando esses pontos. O objetivo do resumo do texto é reter o máximo de informações junto com o encurtamento máximo do texto, sem alterar o significado do texto.
Documento 1: Este papel descreve uma abordagem baseada em modelo de atenção neural para resumo de frases abstratas.
Documento 2: Este papel descreve como RNNs sequência por sequência podem ser usados para obter resultados de ponta em resumo de texto.
Repositório: Este repositório do Google Brain A equipe tem os códigos para usar um modelo personalizado de sequência por sequência para o resumo do texto. O modelo é treinado em um conjunto de dados Gigaword.
Aplicativo: O robô autotldr no Reddit use o resumo do texto para resumir os artigos nos comentários de uma postagem. Este recurso tornou-se muito famoso entre os usuários do Reddit..
Implementação: é assim que você pode resumir rapidamente seu texto usando o pacote gensim.
from gensim.summarization import summarizesentence="Automatic summarization is the process of shortening a text document with software, in order to create a summary with the major points of the original document. Technologies that can make a coherent summary take into account variables such as length, writing style and syntax.Automatic data summarization is part of machine learning and data mining. The main idea of summarization is to find a subset of data which contains the information of the entire set. Such techniques are widely used in industry today. Search engines are an example; others include summarization of documents, image collections and videos. Document summarization tries to create a representative summary or abstract of the entire document, by finding the most informative sentences, while in image summarization the system finds the most representative and important (i.e. salient) images. For surveillance videos, one might want to extract the important events from the uneventful context.There are two general approaches to automatic summarization: extraction and abstraction. Extractive methods work by selecting a subset of existing words, phrases, or sentences in the original text to form the summary. In contrast, abstractive methods build an internal semantic representation and then use natural language generation techniques to create a summary that is closer to what a human might express. Such a summary might include verbal innovations. Research to date has focused primarily on extractive methods, which are appropriate for image collection summarization and video summarization."summarize(sentence)
Notas finais
Portanto, tratava-se das tarefas mais comuns da PNL junto com seus recursos relevantes na forma de blogs., artigos de pesquisa, repositórios e aplicativos, etc. Se você acredita nisso, há um grande recurso sobre qualquer um desses 10 tarefas que perdi ou você deseja sugerir a adição de outra tarefa, então sinta-se à vontade para comentar suas sugestões e comentários.
Nós também temos um ótimo curso, PNL usando Python, para você, se você quiser se tornar um praticante de PNL.
Boa aprendizagem!





