Introdução
Especialmente bibliotecas Python para ciência de dados, modelos de aprendizado de máquina são muito interessantes, fácil de entender e absolutamente que você pode aplicar imediatamente e pode sentir a informação dos dados e perceber / visualize a natureza do conjunto de dados.
Mesmo algoritmos complexos podem ser implementados em duas ou três linhas de código, todos os principais conceitos matemáticos estão embutidos em pacotes para o ponto de vista da implementação.
Claro, isso é algo diferente e interessante do que outras bibliotecas de programação que eu vi até agora, Essa é a principal razão pela qual Python desempenha um papel vital no espaço de IA com sua simplicidade e robustez!! Eu acho que sim! eu percebi, Eu entendi completamente e gostei.
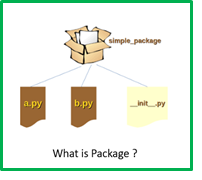
O que é um pacote em Python? UMA pacote é uma coleção de Piton módulos e conjuntos em um pacote. Uma vez que importa nas células do seu notebook, pode começar a usar as aulas, métodos, atributos, etc., mas antes disso, você deve precisar e usar o pacote e importá-lo para o seu arquivo / pacote.
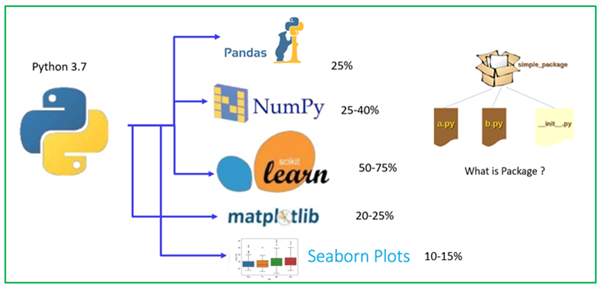
Vejamos os principais pacotes Python para ciência de dados e aprendizado de máquina.
- Pandas
- NumPy
- Aprender Scikit
- Matplotlib
- Seaborn
Pandas

Usado principalmente para operações e manipulações de dados estruturados. O Pandas oferece recursos poderosos de processamento de dados, Nunca vi recursos tão maravilhosos em minha jornada de TI. Oferece alto desempenho, fácil de usar e aplicado em estruturas de dados e para analisar os dados.
Como você poderia instalar a biblioteca Pandas? isso é muito simples, execute o seguinte comando em seu Jupiter Notebook.
!pip instalar pandas
A biblioteca Pandas será instalada com sucesso!! Que segue? brincar com esta biblioteca.
A sintaxe para importar Scikit para o seu Notebook
importar pandas como pd
Então, seu Notebook está pronto para extrair todas as funções do pandas. vamos fazer algumas coisas aqui.
Pandas têm os seguintes recursos.
UMA) Series y DataFrame
Os principais componentes dos pandas são Série e Quadro de dados. Vamos dar uma olhada rápida nisso.. A série nada mais é do que um dicionário e uma coleção de séries, poderíamos construir o quadro de dados mesclando séries, dar uma olhada na amostra a seguir. você entenderia melhor.
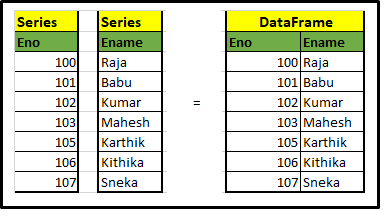
Código cria séries de dados e frameworks
import pandas as pd
Eno=[100, 101,102, 103, 104,105]
Empname= ['Raja', 'Babu', 'Kumar','Karthik','Rajesh','xxxxx']
Eno_Series = pd. Série(Eno)
Empname_Series = pd. Série(Empname)
df = { 'Eno': Eno_Series, 'Empname': Empname_Series }
empregado = pd. DataFrame(quadro)
empregado

B. Carregar dados em um objeto de quadro de dados
cereal_df = pd.read_csv("cereal.csv")
cereal_df.head(5)

C. Coluna de queda do objeto de quadro de dados
cereal_df.drop(["modelo"], eixo = 1, inplace = True)
cereal_df.head(5)

D. Selecione linhas do objeto de quadro de dados
cereal_df_filtered = cereal_df[cereal_df['Avaliação'] >= 68] cereal_df_filtered.head()
E. Coluna de grupo no quadro de dados
cereal_df_groupby = cereal_df.groupby('prateleira')
#print the first entries
cereal_df_groupby.first()

F.Extrair uma linha do quadro de dados
# return the value
result = cereal_df.loc[0,'nome']
resultado
Até agora, discutimos múltiplas funcionalidades na biblioteca panda. Há muitos mais.
NumPy
NumPy é considerado uma das bibliotecas de aprendizado de máquina mais populares em Python, a melhor e mais importante característica do numpy é a interface e manipulações de matriz.
Você tem medo da matemática enquanto implementa seu modelo de ciência de dados / aprendizado de máquina? Não se preocupe, NumPy torna implementações matemáticas complexas funções muito simples. Mas lembre-se de entender os requisitos e usar o pacote de acordo.
A sintaxe para importar o NumPy no seu NoteBook
importar numpy como np
Vamos discutir algumas coisas aqui., como o NumPy faz mágica com dados dados dados.
UMA. Formação de matriz simples usando NumPy (1-D, 2-D e 3D)
import numpy as np #1-D arrays arr1 = np.array([1, 2, 3, 4, 5]) imprimir("1-Matriz D") imprimir(arr1) imprimir("===================") #2-D arrays print("2-Matriz D") arr2 = np.array([[1, 2, 3], [4, 5, 6]]) imprimir(arr2) imprimir("===================") #3-D arrays print("3-Matriz D") arr3 = np.array([[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]]]) imprimir(arr3) imprimir("===================")
Produção
1-Matriz D [1 2 3 4 5] =================== 2-D Array [[1 2 3] [4 5 6]] =================== 3-D Array [[[1 2 3] [4 5 6]] [[1 2 3] [4 5 6]]] ===================
B. Corte de matriz usando NumPy
#Cortar em python significa tirar elementos de determinada faixa de índice [começar:fim-1] /[começar:fim:Passo].
arr = np.array([1, 2, 3, 4, 5, 6, 7])
imprimir("Fatiamento no índice 1 para 5")
imprimir(arr[1:5])
Produção
Fatiamento no índice 1 para 5 [2 3 4 5]
arr = np.array([1, 2, 3, 4, 5, 6, 7]) imprimir(arr[4:]) Saída [5 6 7]
También tenemos Rebanado Negativo :). Eso es bronzeado simples, solo tenemos que mencionar [-x:-e],
¿Por qué no pruebas el tuyo propio?
C. Forma de matriz y remodelación usando NumPy
arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8]])
imprimir("================================")
imprimir("Forma da matriz")
imprimir(arr.shape)
imprimir("================================")
Output
================================
Shape of the array
(2, 4)
================================
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
imprimir("Antes de remodelar a matriz")
imprimir(arr)
imprimir("================================")
newarr = arr.reshape(4, 3)
imprimir("Depois de remodelar a matriz")
imprimir(newarr)
imprimir("================================")
output
Before Reshape the array
[ 1 2 3 4 5 6 7 8 9 10 11 12]
================================
After Reshape the array
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
================================
D. Divisão matrix usando NumPy
arr = np.array([1, 2, 3, 4, 5, 6])
imprimir("Dividindo o NumPy Arrays em 3 Matrizes")
imprimir("================================")
newarr = np.array_split(arr, 3)
imprimir(newarr[0])
imprimir(newarr[1])
imprimir(newarr[2])
imprimir("================================")
output
Splitting NumPy Arrays into 3 Arrays
================================
[1 2]
[3 4]
[5 6]
E.Sorting Array usando NumPy
arr = np.array(['banana', 'cereja', 'maçã'])
imprimir("Dividindo o NumPy Arrays em 3 Matrizes")
imprimir("================================")
imprimir(np.sort(arr))
imprimir("================================")
output
Splitting NumPy Arrays into 3 Arrays
================================
['maçã' 'banana' 'cereja']
================================
Se você começou a jogar com dados usando NumPy....
Certamente, precisa de mais e mais tempo … para entender os conceitos, todos são
extremamente organizado neste pacote. Acredite em mim!
Aprender Scikit

Scikit A biblioteca Learn é uma das bibliotecas mais ricas da família Python, contém um grande número de algoritmos de aprendizado de máquina e outras bibliotecas importantes relacionadas ao desempenho. O Python Scikit-learn permite que os usuários realizem várias tarefas específicas de aprendizado de máquina. Trabalhar, deve trabalhar em conjunto com as bibliotecas SciPy e NumPy, isso é algo interno, de qualquer forma, Tenha isso em mente. Alguns algoritmos aqui para suas opiniões.
- Regressão
- Classificação
- Agrupamento
- Seleção de modelo
- Redução de dimensionalidade
A sintaxe para importar Scikit para o seu Notebook
de sklearn.linear_model import LinearRegression de sklearn.model_selection import train_test_split
Pacotes de exibição Python
Bibliotecas Matplotlib e Seaborn

Python fornece funções de gráficos 2D com a biblioteca Matplotlib. isso é muito simples e fácil de entender. você pode alcançá-lo com 1 o 2 linhas. Até a visualização 3D está lá também.
A sintaxe para importar Scikit para o seu notebook
import matplotlib.pyplot as plt importado do mar como sns
Espero que você tenha trabalhado em vários gráficos em planilhas do Excel e outras ferramentas de BI. Mas em python, pacotes de visualização interna fornecem gráficos e tabelas de alta qualidade.
Matplotlib y Seaborn
Matplotlib é um dos pacotes de visualização principais e básicos, que fornece histogramasHistogramas são representações gráficas que mostram a distribuição de um conjunto de dados. Eles são construídos dividindo o intervalo de valores em intervalos, o "Caixas", e contando quantos dados caem em cada intervalo. Essa visualização permite identificar padrões, tendências e variabilidade de dados de forma eficaz, facilitando a análise estatística e a tomada de decisões informadas em várias disciplinas.... (Nível de freqüência), Gráfico de barras (Plotagem univariada e bivariada), Gráfico de dispersãoUm gráfico de dispersão é uma representação visual que mostra a relação entre duas variáveis numéricas usando pontos em um plano cartesiano. Cada eixo representa uma variável, e a localização de cada ponto indica seu valor em relação a ambos. Esse tipo de gráfico é útil para identificar padrões, Correlações e tendências nos dados, facilitando a análise e interpretação de relações quantitativas.... (Agrupamento), etc.,
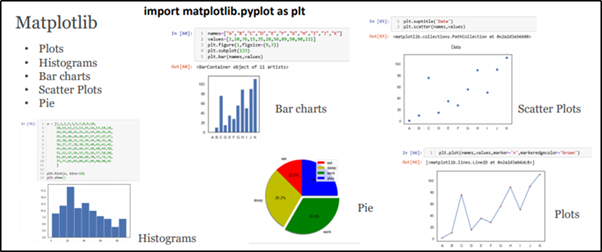
Biblioteca de visualização de dados rica e luxuosa de Seaborn. Fornece uma interface de alto nível para desenhar gráficos estatísticos atraentes e informativos. Plotagens de caixaDiagramas de caixa, Também conhecido como diagramas de caixa e bigode, são ferramentas estatísticas que representam a distribuição de um conjunto de dados. Esses diagramas mostram a mediana, Quartis e outliers, permitindo que a variabilidade e a simetria dos dados sejam visualizadas. Eles são úteis na comparação entre diferentes grupos e na análise exploratória, facilitando a identificação de tendências e padrões nos dados.... (Distribuição de dados com quartis diferentes), Tramas de violino (Distribuição de dados e Densidade de probabilidade), Gráficos de barra (Comparações entre características categóricas), Mapa de caloruma "mapa de calor" é uma representação gráfica que usa cores para mostrar a densidade de dados em uma área específica. Comumente usado em análise de dados, Estudos de marketing e comportamentais, Esse tipo de visualização permite identificar padrões e tendências rapidamente. Através de variações cromáticas, Os mapas de calor facilitam a interpretação de grandes volumes de informações, ajudando a tomar decisões informadas.... (Mapeamento de recursos em termos de representação de matriz), Palavra nuvem (Representação visual de dados de texto)
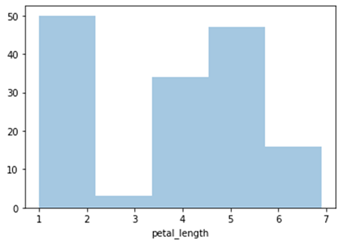
Seaborn – Histograma
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('íris')
sb.distplot(df['petal_length'],kde = Falso)
plt.show()
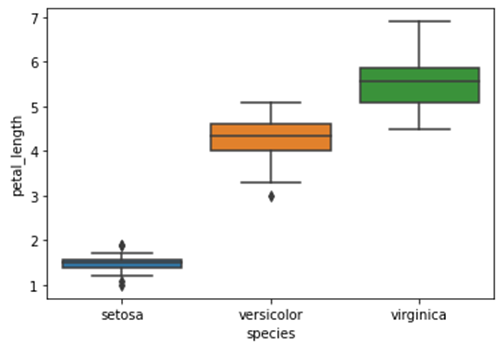
Seaborn – Box plot
df = sb.load_dataset('íris')
sb.boxplot(x = "espécie", y = "petal_length", dados = df)
plt.show()
Seaborn – Violino
sdf = sb.load_dataset('dicas')
sb.violinplot(x = "dia", y = "total_bill", data = df)
plt.show()
Então, todas essas bibliotecas estão nos ajudando a construir um bom modelo e brincar com os dados!!
Mas lembre-se sempre, antes do uso dos pacotes induual, você precisa entender a necessidade e os requisitos do pacote e, em seguida, importá-lo em seu arquivo / pacote e jogar com isso.

Espero que agora você tenha a sensação e algum nível de detalhes sobre pacotes Python para ciência de dados. Veremos conceitos mais detalhados nos próximos dias! Obrigado pelo seu tempo!
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





