Visão geral
- Compreenda o significado de particionamento e agrupamento no Hive em detalhes.
- Vamos ver, como criar partições e cubos no Hive.
Introdução
Você pode ter visto uma enciclopédia na biblioteca de sua escola ou universidade. É um conjunto de livros que fornecerá informações sobre quase tudo. Você sabe qual é o melhor da enciclopédia?

sim, você adivinhou corretamente. As palavras são organizadas em ordem alfabética. Por exemplo, tem uma palavra em mente “Pirâmides”. Você irá diretamente pegar o livro com o título "P". Você não precisa procurar por isso em outros livros. Você pode imaginar como seria difícil a tarefa de procurar um único livro se eles estivessem armazenados em nenhuma ordem?
Aqui, armazenar palavras em ordem alfabética representa indexação, mas usar uma localização diferente para palavras que começam com o mesmo caractere é conhecido como agrupamento.
Existem tipos semelhantes de técnicas de armazenamento, como partições e agrupamentos, sobre Apache Hive para que possamos obter resultados mais rápidos para consultas de pesquisa. Neste artigo, veremos o que é partição e agrupamento, e quando usar qual.
Tabela de conteúdo
- O que é particionamento?
- Quando usar particionamento?
- O que é agrupamento?
- Quando usar agrupamento?
O que é particionamento?
O Apache Hive nos permite organizar a tabela em várias partições onde podemos agrupar o mesmo tipo de dados. Usado para distribuir a carga horizontalmente. Vamos entender com um exemplo:
Suponha que tenhamos que criar uma tabela na colmeia contendo os detalhes do produto para uma empresa de comércio eletrônico de moda. Tem as seguintes colunas:
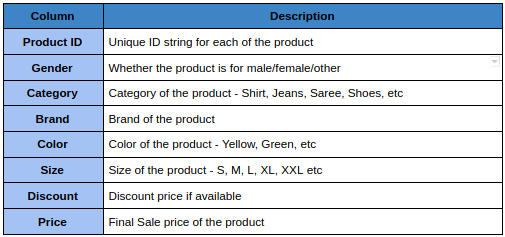
Agora, o primeiro filtro que a maioria dos clientes usa é gênero, em seguida, selecione categorias como Camisa, seu tamanho e cor. Vamos ver como criar as partições para este exemplo.
CREATE TABLE products ( string product_id,
string da marca,
string de tamanho,
desconto flutuante,
flutuação de preço )
PARTICIONADO POR (corda de gênero,
string de categoria,
string de cor);
Agora, o hive irá armazenar os dados na estrutura do diretório como:
/user/hive/warehouse/mytable/gender=male/category=shoes/color=black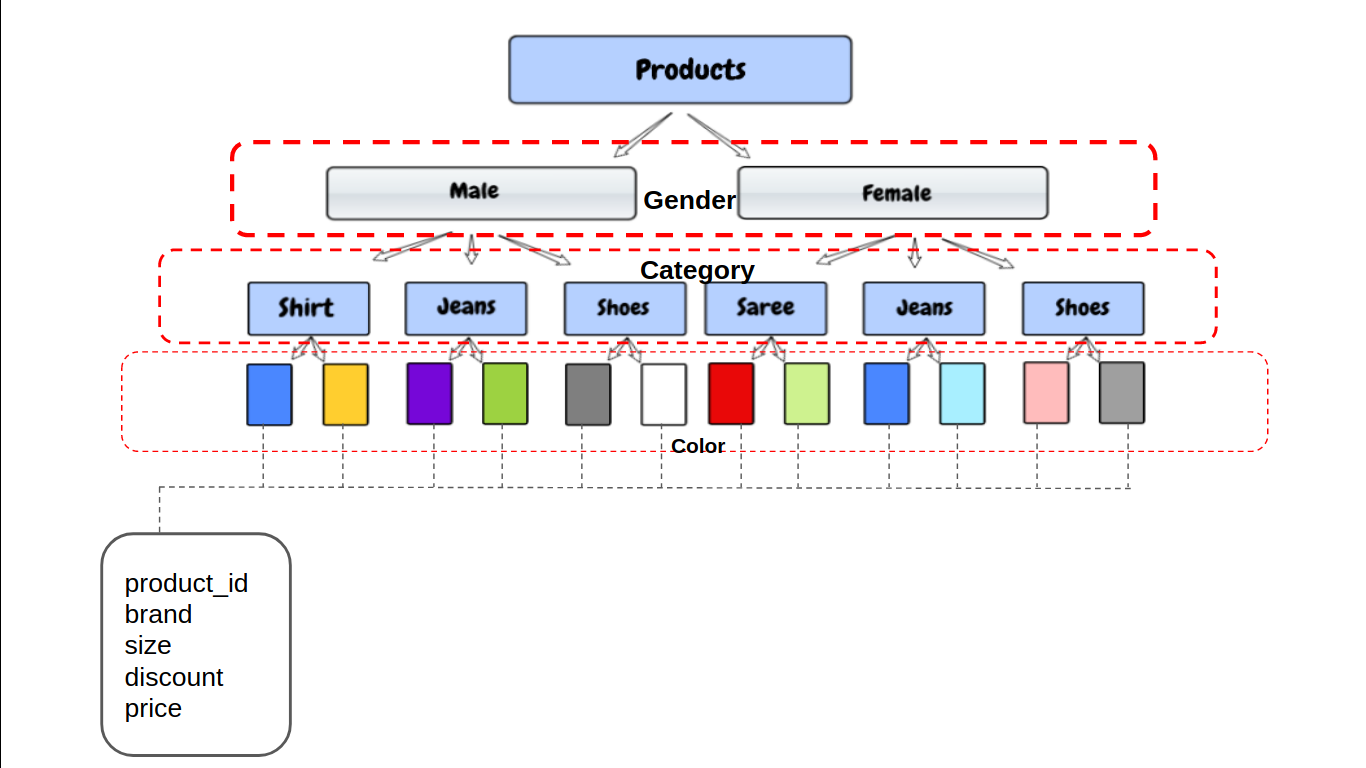
O particionamento de dados nos dá benefícios de desempenho e também nos ajuda a organizar os dados. Agora, vamos ver quando usar partição no hive.
Quando usar particionamento?
- Quando a coluna com uma consulta de pesquisa alta tem uma cardinalidade baixa. Por exemplo, se você criar uma partição com o nome do país, um máximo de 195 partições e o hive serão capazes de gerenciar tantos diretórios.
- Por outro lado, não particione colunas com cardinalidade muito alta. Por exemplo, ID do produto, data e hora e preço, porque criará milhões de diretórios que serão impossíveis de serem gerenciados pela colmeia.
- É eficaz quando o volume de dados em cada partição não é muito alto. Por exemplo, se você tem os dados da companhia aérea e deseja calcular o número total de voos em um dia. Nesse caso, o resultado vai demorar mais para calcular sobre a partição “Dubai”, já que tem um dos aeroportos mais movimentados do mundo, enquanto para um país como “Albânia” retornará resultados mais rápido.
O que é agrupamento?
No exemplo acima, sabemos que não podemos particionar com base no preço da coluna porque seu tipo de dados é flutuante e há um número infinito de preços únicos possíveis.
O Hive terá que gerar um diretório separado para cada um dos preços exclusivos e será muito difícil para o Hive gerenciá-los. Em vez disso, podemos definir manualmente o número de depósitos que queremos para essas colunas.
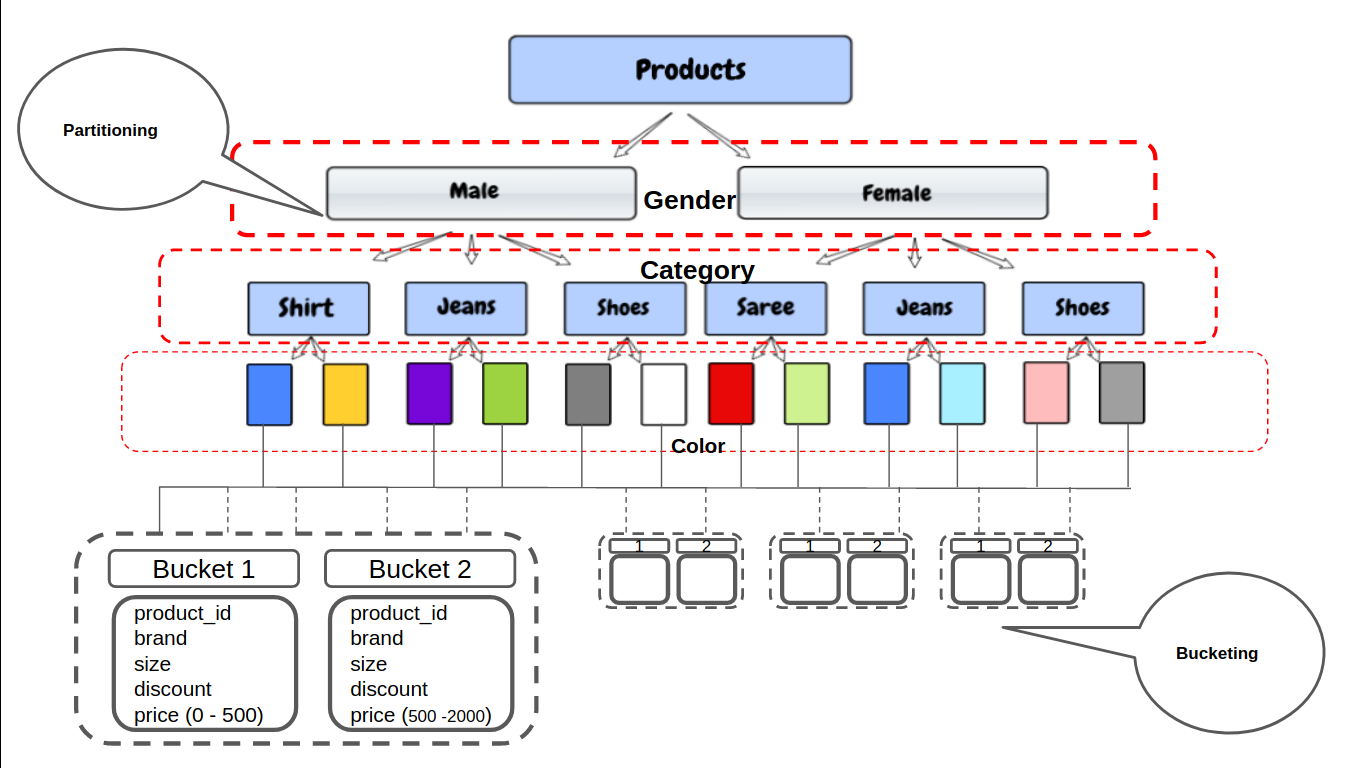
Em agrupamento, as partições podem ser subdivididas em grupos com base na função hash de uma coluna. Fornece estrutura adicional para os dados que podem ser usados para consultas mais eficientes.
CREATE TABLE products ( string product_id,
string de marca,
string de tamanho,
desconto flutuante,
flutuação de preço )
PARTICIONADO POR (corda de gênero,
string de categoria,
string de cor)
ENCERRADO POR (preço) EM 50 BALDES;
Agora, só será criado 50 depósitos, não importa quantos valores únicos estejam na coluna de preço. Por exemplo, no primeiro cubo, todos os produtos com um preço [ 0 - 500 ] Irã, e no próximo grupo de produtos com um preço [ 500 - 200 ] e assim por diante.
Quando usar agrupamento?
- Não podemos nos dividir em uma coluna com cardinalidade muito alta. Muitas partições resultarão em vários arquivos Hadoop, o que aumentará a carga no mesmo nó, uma vez que tem que transportar os metadados de cada uma das partições.
- Se algumas combinações do lado do mapa estão envolvidas em suas consultas, tabelas agrupadas são uma boa opção. A junção do lado do mapa é um processo onde duas tabelas são unidas usando a função de mapa sozinha, sem qualquer função reduzida. Recomendo que você leia este artigo para entender melhor as combinações das laterais do mapa: O lado do mapa se junta ao Hive
Notas finais
Neste artigo, vimos o que é partição e agrupamento, como criá-los e quais são seus prós e contras.
Eu recomendo fortemente que você verifique os seguintes recursos para aprender mais sobre o Apache Hive:
Se você tiver alguma dúvida relacionada a este artigo, Me avise na seção de comentários abaixo.





