Este artigo foi publicado como parte do Data Science Blogathon
Introdução
Apache Spark é uma estrutura usada em ambientes de computação em cluster para analisar big data. O Apache Spark pode trabalhar em um ambiente distribuído em um grupo de computadores em um cluster para processar grandes conjuntos de dados com mais eficiência. Este mecanismo de código aberto do Spark oferece suporte a uma ampla variedade de linguagens de programação, incluindo Scala, Java, R y Python.
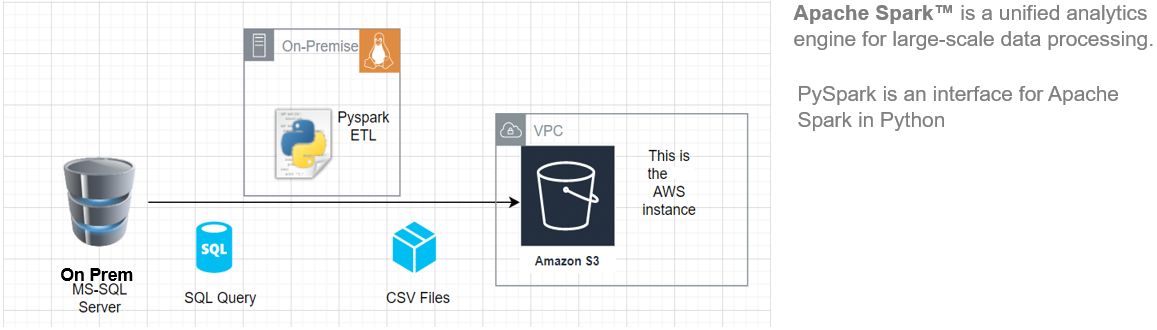
Neste artigo, Vou mostrar como começar a instalar o Pyspark em seu Ubuntu máquina e, em seguida, construir um pipeline ETL básico para extrair dados de transferência de carga de um sistema RDBMS remoto para um AWS S3 Balde.
Esta arquitetura ETL pode ser usada para transferir centenas de Gigabytes de dados de qualquer servidor de banco de dados RDBMS. (neste artigo, usamos o MS SQL Server) tem um bucket do Amazon S3.
Principais benefícios do uso do Apache Spark:
- Executar cargas de trabalho 100 vezes mais rápido que o Hadoop
- Compatível com Java, Scala, Pitão, R y SQL
Fonte: Esta é uma imagem original.
Requisitos
Para iniciar, devemos ter os seguintes pré-requisitos:
- Um sistema rodando Ubuntu 18.04 o Ubuntu 20.04
- Uma conta de usuário com privilégios sudo
- Uma conta AWS com acesso de upload ao bucket S3
Antes de baixar e configurar o Spark, você deve instalar as dependências de pacote necessárias. Certifique-se de que os seguintes pacotes já estão configurados em seu sistema.
Para confirmar as dependências instaladas executando estes comandos:
java -version; git --version; python --version

Instale o PySpark
Baixe a versão do Spark que você deseja do site oficial da Apache. Vamos baixar o Spark 3.0.3 con Hadoop 2.7 uma vez que é a versão atual. A seguir, use o comando wget e url direto para baixar o pacote Spark.
Mude seu diretório de trabalho para / optar / fagulha.
cd / opt / spark
sudo wget https://downloads.apache.org/spark/spark-3.0.3/spark-3.0.3-bin-hadoop2.7.tgz

Extraia o pacote salvo usando o comando tar. Assim que o processo de espalhamento estiver concluído, a saída mostra os arquivos que foram descompactados do arquivo.
tar xvf spark- *
ls -lrt spark- *

Configure o ambiente Spark
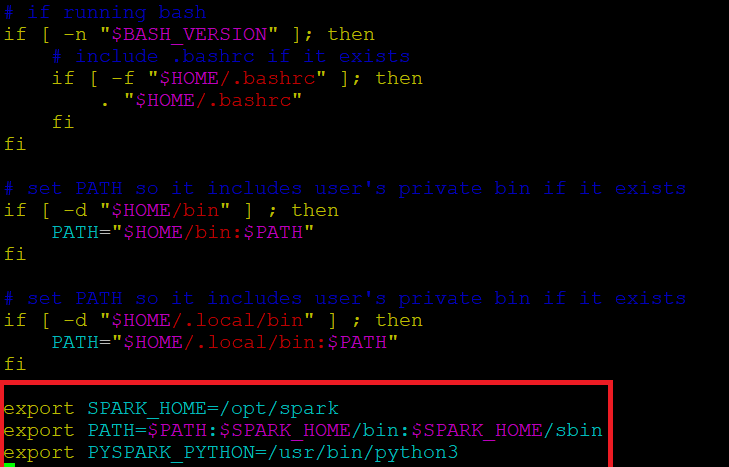
Antes de iniciar um servidor Spark, precisamos definir algumas variáveis de ambiente. Existem alguns diretórios do Spark que precisamos adicionar ao perfil padrão. Use o editor vi ou qualquer outro editor para adicionar essas três linhas ao .profile:
vi ~ / .profile
Insira estes 3 linhas no final do arquivo .profile.
export SPARK_HOME = / opt / spark exportar PATH = $ PATH:$SPARK_HOME / bin:$SPARK_HOME / sbin export PYSPARK_PYTHON = / usr / bin / python3
Salve as alterações e saia do editor. Quando você terminar de editar o arquivo, carregue o .perfil arquivo na linha de comando digitando. alternativamente, podemos sair do servidor e entrar novamente para que as alterações tenham efeito.
fonte ~ / .profile
Começar / Parar Spark Master & Trabalhador
Vá para o diretório de instalação do Spark / optar / fagulha / fagulha *. Tem todos os scripts necessários para começar / parar os serviços Spark.
Execute este comando para iniciar o Spark Master.
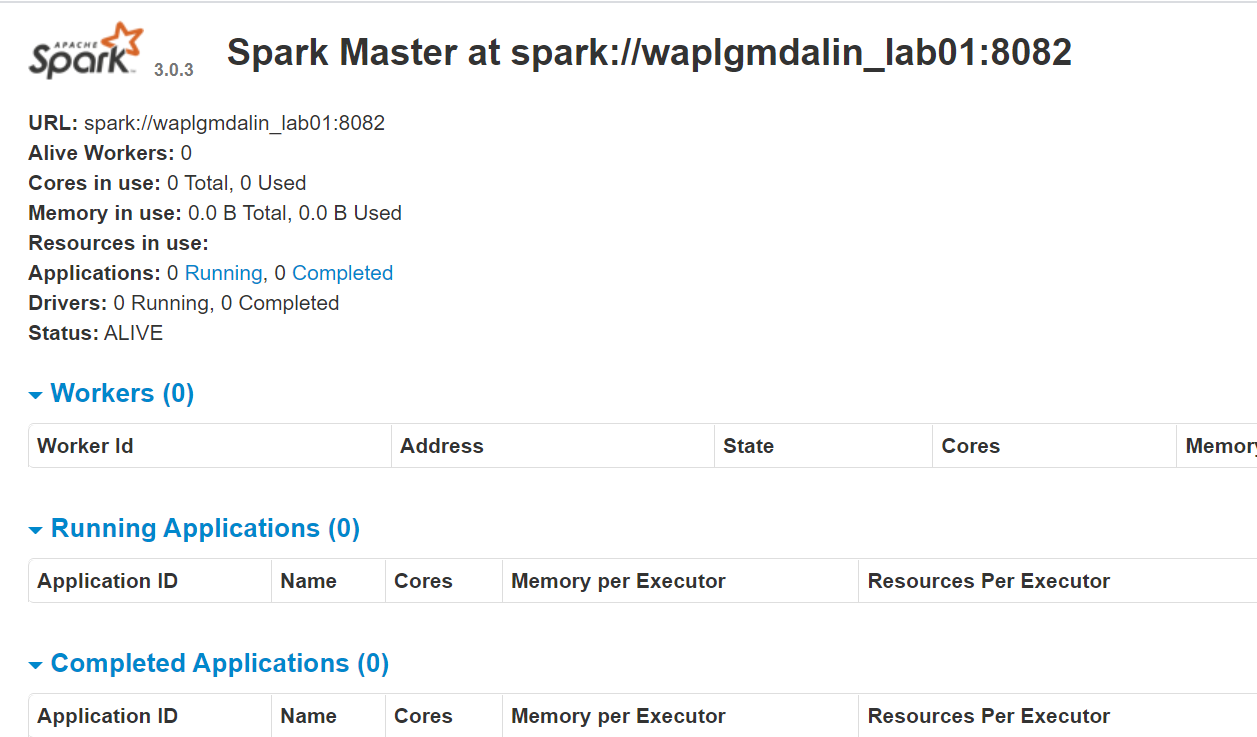
start-master.shPara visualizar a interface da web do Spark, abra um navegador da web e digite o endereço IP do host local na porta 8080. (Esta é a porta padrão que o Spark usa se você precisar alterá-la, faça isso no script start-master.sh). alternativamente, pode substituir 127.0.0.1 com o endereço IP de rede real de sua máquina host.
http://127.0.0.1:8080/A página da web mostra o URL do Spark Master, nós de trabalho, Utilização de recursos da CPU, memória, executando aplicativos, etc.
Agora, execute este comando para iniciar uma instância de trabalhador Spark.
start-slave.sh spark://0.0.0.0:8082
o
start-slave.sh spark://waplgmdalin_lab01:8082
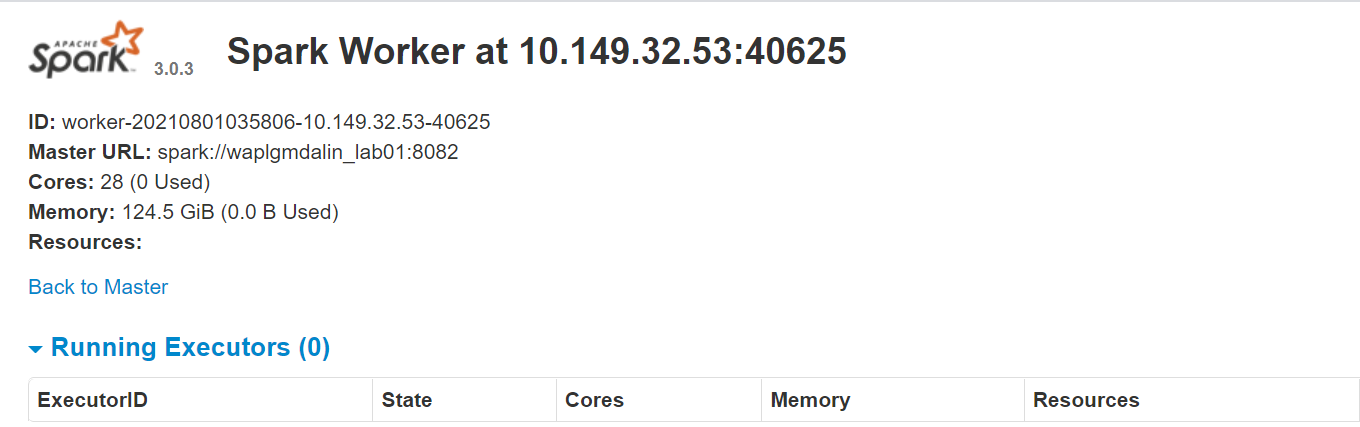
O próprio site do trabalhador é executado em http://127.0.0.1:8084/ mas deve estar ligado ao professor. É por isso que passamos o URL mestre do Spark como um parâmetro para o script start-slave.sh. Para confirmar se o trabalhador está corretamente vinculado ao mestre, abra o link em um navegador.
Atribuição de recursos ao trabalhador do Spark
Por padrão, quando você inicia uma instância de trabalho, usa todos os núcleos disponíveis na máquina. Porém, por razões práticas, você pode querer limitar o número de núcleos e a quantidade de RAM alocada para cada trabalhador.
start-slave.sh spark://0.0.0.0:8082 -c 4 -m 512M
Aqui, nós atribuímos 4 núcleos e 512 MB RAM para trabalhador. Vamos confirmar isso reiniciando a instância do trabalhador.
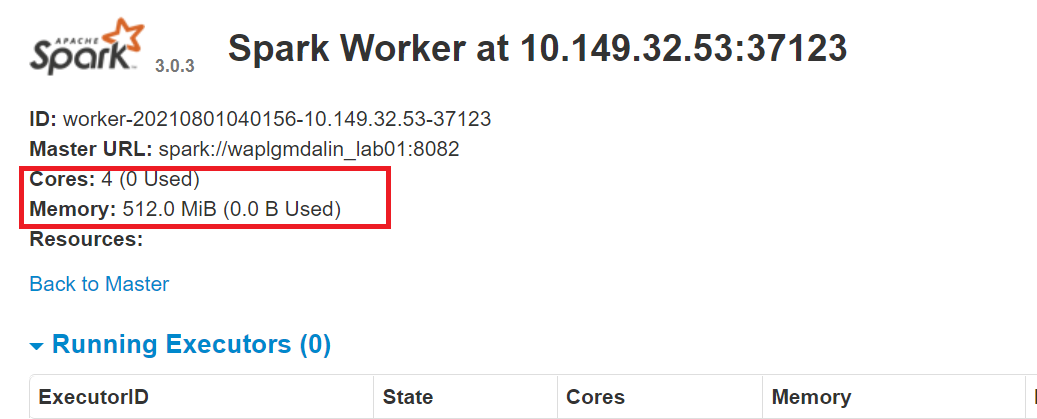
Para parar o mestre instância iniciada executando o script acima, corre:
stop-master.shPara parar um trabalhador em execução processo, digite este comando:
stop-slave.shConfigurar conexão MS SQL
Neste PySpark ETL, vamos nos conectar a uma instância do servidor MS SQL como sistema de origem e executar consultas SQL para obter dados. Então, primeiro temos que baixar as dependências necessárias.
Baixe o arquivo jar do MS-SQL (mssql-jdbc-9.2.1.jre8) do site da Microsoft e copie-o para o diretório “/ optar / fagulha / jarras”.
https://www.microsoft.com/en-us/download/details.aspx?id=11774
Baixe o arquivo jar do Spark SQL (chispa-sql_2.12-3.0.3.jar) do site de download do Apache e copie-o para o diretório ‘/ opt / fagulha / jarras ”.
https://jar-download.com/?search_box=org.apache.spark+spark.sql
Edite o .profile, adicionar classes PySpark e Py4J ao caminho Python:
exportar PYTHONPATH = $ SPARK_HOME / python /:$PYTHONPATH export PYTHONPATH = $ SPARK_HOME / python / lib / py4j-0.10.9-src.zip:$PYTHONPATH
Configure a conexão AWS S3
Para se conectar a uma instância AWS, precisamos baixar os três arquivos jar e copiá-los para o diretório “/ optar / fagulha / jarras”. Verifique a versão do Hadoop que você está usando atualmente. Você pode obtê-lo em qualquer jar presente na instalação do Spark. Se a versão do Hadoop for 2.7.4, baixe o arquivo jar para a mesma versão. Para Java SDK, você deve baixar a mesma versão que foi usada para gerar o pacote Hadoop-aws.
Certifique-se de que as versões são as mais recentes.
- hadoop-aws-2.7.4.jar
- aws-java-sdk-1.7.4.jar
- jets3t-0.9.4.jarra
sudo wget https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk/1.11.30/aws-java-sdk-1.7.4.jar sudo wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/2.7.3/hadoop-aws-2.7.4.jar sudo wget https://repo1.maven.org/maven2/net/java/dev/jets3t/jets3t/0.9.4/jets3t-0.9.4.jar
Desenvolvimento Python
Crie um diretório de trabalho chamado 'scripts’ para armazenar todos os scripts Python e arquivos de configuração. Crie um arquivo chamado “sqlfile.py” que conterá as consultas SQL que queremos executar no servidor de banco de dados remoto.
vi sqlfile.py
Insira a seguinte consulta SQL no arquivo sqlfile.py que irá extrair os dados. Antes desta etapa, recomenda-se fazer um teste de execução desta consulta SQL no servidor para ter uma ideia do número de registros retornados.
consulta1 = """(selecionar * de dados de vendas onde data >= '2021-01-01' e status ="Concluído")"""
Salve e saia do arquivo.
Crie um arquivo de configuração chamado “config.ini” que irá armazenar credenciais de login e parâmetros de banco de dados.
vi config.ini
Insira os seguintes parâmetros de conexão AWS e MSSQL no arquivo. Observe que criamos seções separadas para armazenar os parâmetros de conexão AWS e MSSQL. Você pode criar quantas instâncias de conexão de banco de dados forem necessárias, contanto que cada um seja mantido em sua própria seção (mssql1, mssql2, aws1, aws2, etc.).
[aws]
ACCESS_KEY = BBIYYTU6L4U47BGGG&^ CF SECRET_KEY = Uy76BBJabczF7h6vv + BFssqTVLDVkKYN / f31puYHtG BUCKET_NAME = s3-bucket-name DIRETÓRIO = diretório de dados de vendas [mssql] url = jdbc:servidor SQL://PPOP24888S08YTA.APAC.PAD.COMPANY-DSN.COM:1433;databaseName = Transações banco de dados = transações usuário = MSSQL-USER senha = MSSQL-senha dbtable = sales-data filename = data_extract.csv
Salve e saia do arquivo.
Crie um script Python chamado “Data-Extraction.py”.
Importar bibliotecas para Spark e Boto3
Spark é implementado em Scala, uma linguagem que roda na JVM, mas como estamos trabalhando com Python, usaremos PySpark. A versão atual do PySpark é 2.4.3 e funciona com python 2.7, 3.3 e mais alto. Você pode pensar no PySpark como um contêiner baseado em Python no topo da API Scala.
Aqui, SDK da AWS para Python (Boto3) para criar, configurar e gerenciar serviços AWS, como Amazon EC2 e Amazon S3. O SDK fornece uma API orientada a objetos, bem como acesso de baixo nível aos serviços AWS.
Importe as bibliotecas Python para iniciar uma sessão Spark, query1 de sqlfile.py e boto3.
from pyspark.sql import SparkSession import Shutil importar os import glob importar boto3 de sqlfile import query1 from configparser import ConfigParser
Crie uma SparkSession
SparkSession fornece um único ponto de entrada para interagir com o mecanismo Spark subjacente e permite a programação do Spark com APIs DataFrame e Dataset. Mais importante ainda, ele restringe o número de conceitos e compilações com os quais um desenvolvedor deve trabalhar enquanto interage com o Spark.. Neste ponto, você pode usar o ‘Fagulha – fagulha’ variável como seu objeto de instância para acessar seus métodos públicos e instâncias durante o trabalho do Spark. Dê um nome ao aplicativo.
appName = "Exemplo de PySpark ETL - via MS-SQL JDBC"
mestre = "local"
spark = SparkSession
.construtor
.mestre(mestre)
.nome do aplicativo(nome do aplicativo)
.config("spark.driver.extraClassPath","/opt / spark / jars / mssql-jdbc-9.2.1.jre8.jar")
.getOrCreate()
Leia o arquivo de configuração
Nós armazenamos os parâmetros em um arquivo “config.ini” separar parâmetros estáticos do código Python. Isso ajuda a escrever um código mais limpo, sem qualquer codificação. Módulo Este implementa uma linguagem de configuração básica que fornece uma estrutura semelhante à que vemos nos arquivos .ini do Microsoft Windows.
url = config.get('mssql-onprem', 'url')
user = config.get('mssql-onprem', 'do utilizador')
senha = config.get('mssql-onprem', 'senha')
dbtable = config.get('mssql-onprem', 'dbtable')
filename = config.get('mssql-onprem', 'nome do arquivo')
ACCESS_KEY = config.get('aws', 'CHAVE DE ACESSO')
SECRET_KEY = config.get('aws', 'CHAVE SECRETA')
BUCKET_NAME = config.get('aws', 'BUCKET_NAME')
DIRETÓRIO = config.get('aws', 'DIRETÓRIO')
Executar extração de dados
O Spark inclui uma fonte de dados que pode ler dados de outros bancos de dados usando JDBC. Execute o SQL no banco de dados remoto conectando-se usando o driver JDBC do Microsoft SQL Server e os parâmetros de conexão. Em opção “consulta”, se você quiser ler uma tabela inteira, forneça o nome da mesa; pelo contrário, se você deseja executar a consulta selecionada, especifique o mesmo. Os dados retornados pelo SQL são armazenados em um quadro de dados Spark.
jdbcDF = spark.read.format("jdbc")
.opção("url", url)
.opção("consulta", consulta2)
.opção("do utilizador", do utilizador)
.opção("senha", senha)
.opção("motorista", "com.microsoft.sqlserver.jdbc.SQLServerDriver")
.carga()
jdbcDF.show(5)
Salvar quadro de dados como arquivo CSV
O quadro de dados pode ser armazenado no servidor como um arquivo. Arquivo CSV. Algo, esta etapa é opcional caso você queira gravar o quadro de dados diretamente em um balde S3, esta etapa pode ser ignorada. PySpark, por padrão, criar múltiplas partições, para evitar isso, podemos salvá-lo como um único arquivo usando a função de coalescência (1). A seguir, movemos o arquivo para a pasta de saída designada. Opcionalmente, remova o diretório de saída criado se você quiser apenas salvar o dataframe no balde S3.
caminho ="saída"
jdbcDF.coalesce(1).write.option("cabeçalho","verdade").opção("set",",").modo("sobrescrever").csv(caminho)
shutil.move(glob.glob(os.getcwd() + '/' + caminho + '/' + r '*. csv')[0], os.getcwd()+ '/' + nome do arquivo )
shutil.rmtree(os.getcwd() + '/' + caminho)
Copie o quadro de dados para o bucket S3
Primeiro, criar uma sessão 'boto3’ usando o acesso AWS e valores de chave secreta. Recupere os valores do depósito S3 e do subdiretório onde deseja fazer o upload do arquivo. a Subir arquivo() aceita um nome de arquivo, um nome de intervalo e um nome de objeto. O método lida com arquivos grandes, dividindo-os em pedaços menores e carregando cada pedaço em paralelo.
session = boto3.Session(
aws_access_key_id = ACCESS_KEY,
aws_secret_access_key = SECRET_KEY,
)
bucket_name = BUCKET_NAME
s3_output_key = DIRETÓRIO + nome do arquivo
s3 = session.resource('s3')
# Nome do arquivo - Arquivo para upload
# Balde - Bucket para fazer upload para (o diretório de nível superior sob AWS S3)
# Chave - Nome do objeto S3 (pode conter subdiretórios). Se não for especificado, file_name é usado
s3.meta.client.upload_file(Nome do arquivo = nome do arquivo, Bucket = bucket_name, Key = s3_output_key)
Limpando arquivos
Depois de fazer o upload do arquivo para o balde S3, exclua todos os arquivos deixados no servidor; pelo contrário, Eu joguei um erro.
if os.path.isfile(nome do arquivo):
os.remove(nome do arquivo)
outro:
imprimir("Erro: %s arquivo não encontrado" % nome do arquivo)
conclusão
Apache Spark é uma estrutura de computação em cluster de código aberto com recursos de processamento na memória. Foi desenvolvido na linguagem de programação Scala. Spark oferece muitos recursos e capacidades que o tornam uma estrutura de Big Data eficiente. Desempenho e velocidade são os principais benefícios do Spark. Você pode carregar os terabytes de dados e processá-los sem problemas, configurando um cluster de vários nós. Este artigo dá uma ideia de como escrever um ETL baseado em Python.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





