Introdução
Processamento de linguagem natural (PNL) é uma área de crescente atenção devido ao número crescente de aplicativos, como chatbots, tradução automática, etc. De alguma forma, Toda a revolução da máquina inteligente é baseada na capacidade de entender e interagir com os humanos.
Venho explorando PNL há algum tempo. Minha jornada começou com a biblioteca NLTK em Python, qual era a biblioteca recomendada para começar naquela época. NLTK é uma biblioteca perfeita para educação e pesquisa, torna-se muito pesado e tedioso para completar até as tarefas mais simples.
Mais tarde, Fui apresentado ao TextBlob, que é baseado em NLTK e padrão. Uma grande vantagem disso é que é fácil de aprender e oferece muitos recursos, como análise de sentimento., rotulagem pos, extração de frase nominal, etc. Agora se tornou minha biblioteca de referência para realizar tarefas de PNL.
Em uma nota lateral, Há espaço, que é amplamente reconhecida como uma das bibliotecas poderosas e avançadas usadas para implementar tarefas de PNL. Mas tendo encontrado spacy e TextBlob, Eu ainda sugeriria TextBlob para um iniciante por causa de sua interface simples.
Se for o seu primeiro passo na PNL, TextBlob é a biblioteca perfeita para você praticar. A melhor maneira de ler este artigo é seguir o código e fazer as tarefas você mesmo. Então vamos começar!
Observação : Este artigo não descreve as tarefas da PNL em detalhes. Se você quiser revisar o básico e voltar aqui, você sempre pode ler este artigo.
Tabela de conteúdo
- Sobre TextBlob?
- Configure o sistema
- Experimente tarefas de PNL com TextBlob
- Tokenización
- Extração de frase substantiva
- Rotulagem POS
- Inflexão e derivação de palavras
- N-gramas
- Análise de sentimentos
- Outras coisas legais para fazer com TextBlob
- Correção ortográfica
- Crie um breve resumo de um texto
- Tradução e detecção de idioma
- Classificação de texto usando TextBlob
- Prós e contras
- Notas finais
1. Sobre TextBlob?
TextBlob é uma biblioteca Python e oferece uma API simples para acessar seus métodos e realizar tarefas básicas de PNL.
O bom do TextBlob é que eles são como strings python. Então, você pode transformá-lo e brincar com ele da mesma forma que fizemos em python. A seguir, Mostrei abaixo algumas tarefas básicas. Não se preocupe com a sintaxe, é apenas para lhe dar uma ideia de como o TextBlob está relacionado às strings Python.
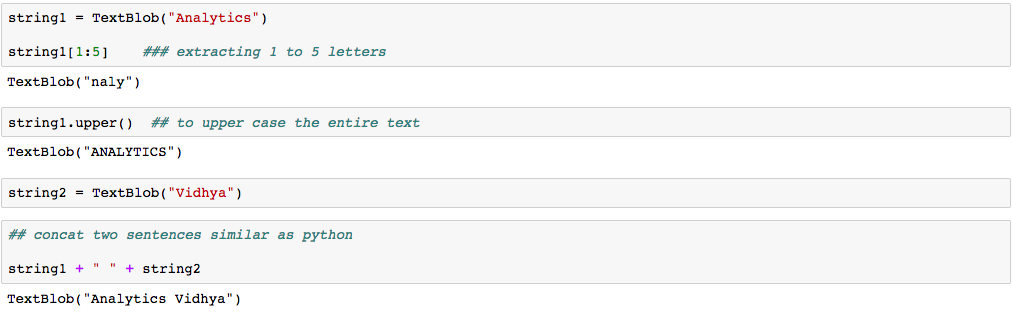 Então, fazer essas coisas por conta própria, vamos instalar e começar a codificar rapidamente.
Então, fazer essas coisas por conta própria, vamos instalar e começar a codificar rapidamente.
2. Configuração do sistema
Instalando TextBlob em seu sistema em uma tarefa simples, tudo que você precisa fazer é abrir o indicador anaconda (o terminal si usa Mac OS o Ubuntu) e digite os seguintes comandos:
pip install -U textblob
Isso irá instalar o TextBlob. Para os não iniciados: trabalho prático em processamento de linguagem natural geralmente usa grandes quantidades de dados linguísticos, o corpora. Para baixar o corpus necessário, você pode executar o seguinte comando
python -m textblob.download_corpora
3. Tarefas de PNL com TextBlob
3.1 Tokenización
A tokenização se refere à divisão do texto ou uma frase em uma sequência de tokens, que correspondem aproximadamente a “palavras”. Esta é uma das tarefas básicas da PNL. Para fazer isso usando TextBlob, siga os dois passos:
- Criar uma textblob objeto e passe uma corda com ele.
- Lama funções de textblob para realizar uma tarefa específica.
Então, vamos criar rapidamente um objeto textblob para jogar.
from textblob import TextBlob
blob = TextBlob("DataPeaker é uma ótima plataforma para aprender ciência de dados. n Ajuda a comunidade por meio de blogs, hackathons, discussões,etc.")
Agora, este bloco de texto pode ser convertido em uma frase e então em palavras. Vamos ver o código mostrado abaixo.
3.2 Extração de frase substantiva
Como extraímos as palavras da seção anterior, no lugar disso, podemos simplesmente extrair as frases nominais do bloco de texto. A extração de sintagmas nominais é particularmente importante quando você deseja analisar o “quem” em uma frase. Vamos ver um exemplo abaixo.
blob = TextBlob("DataPeaker é uma ótima plataforma para aprender ciência de dados.")
para np em blob.noun_phrases:
imprimir (por exemplo)
>> analítica vidhya
grande plataforma
ciência de dados
Como vemos, os resultados não estão totalmente corretos, mas devemos estar cientes de que estamos trabalhando com máquinas.
3.3 Rotulando parte da voz
A marcação gramatical ou gramatical é um método de marcar palavras presentes em um texto com base em sua definição e contexto. Em palavras simples, diz se uma palavra é um substantivo, Um adjetivo, um verbo, etc. Esta é apenas uma versão completa da extração de sintagmas nominais, onde queremos encontrar todas as classes gramaticais em uma frase.
Vamos verificar os rótulos do nosso bloco de texto.
Por palavras, tag em blob.tags:
imprimir (palavras, marcação)
>> Analytics NNS
Vidhya NNP
é VBZ
um DT
ótimo JJ
plataforma NN
para TO
aprender VB
dados NNS
ciência NN
Aqui, NN representa um substantivo, DT representa um determinante, etc. Você pode verificar a lista completa de rótulos em aqui para saber mas.
3.4 Inflexão e derivação de palavras
Inflexão é um processo de palavra formação na qual os caracteres são adicionados à forma de base de um palavra para expressar significados gramaticais. A inflexão de palavras no TextBlob é muito simples, quer dizer, as palavras que tokenizamos de um textblob podem ser facilmente alteradas para o singular ou plural.
blob = TextBlob("DataPeaker é uma ótima plataforma para aprender ciência de dados. n Ajuda a comunidade por meio de blogs, hackathons, discussões,etc.")
imprimir (blob.sentences[1].palavras[1])
imprimir (blob.sentences[1].palavras[1].singularizar())
>> ajuda
ajuda
A biblioteca TextBlob também oferece um objeto integrado conhecido como Palavra. Precisamos apenas criar um objeto de palavra e, em seguida, aplicar uma função a ele diretamente como mostrado abaixo.
from textblob import Word
w = palavra('Plataforma')
w.pluralize()
>>'Plataformas'
Também podemos usar as tags para flexionar um tipo específico de palavras, conforme mostrado abaixo.
## usando tags por palavra,pos em blob.tags: se pos == 'NN': imprimir (word.pluralize()) >> plataformas ciências
As palavras podem ser derivadas usando o lematizar Função.
## lematização
w = palavra('correndo')
w.lemmatizar("v") ## v aqui representa o verbo
>> 'correr'
3,5 N-gramas
Uma combinação de várias palavras é chamada de N-Gramas. Os N gramas (N> 1) são geralmente mais informativos em comparação com palavras e podem ser usados como recursos para modelagem de linguagem. N-gramas podem ser facilmente acessados no TextBlob usando o ngramas Função, que retorna uma tupla de n palavras sucessivas.
para ngram em blob.ngrams(2):
imprimir (ngram)
>> ['Analytics', 'Vidhya']
['Vidhya', 'é']
['é', 'uma']
['uma', 'excelente']
['excelente', 'plataforma']
['plataforma', 'para']
['para', 'aprender']
['aprender', 'dados']
['dados', 'Ciência']
3.6 Análise de sentimentos
A análise de sentimento é basicamente o processo de determinar a atitude ou emoção do escritor, quer dizer, sim é positivo, negativa o neutral.
a sentindo-me função textblob retorna duas propriedades, polaridade, e subjetividade.
A polaridade é flutuante, que está na faixa de [-1,1] Onde 1 significa declaração positiva e -1 significa declaração negativa. Frases subjetivas geralmente se referem a opiniões, emoções ou julgamentos pessoais, enquanto os objetivos referem-se a informações factuais. A subjetividade também é uma flutuação que está na faixa de [0,1].
Vamos revisar o sentimento de nosso blob.
imprimir (bolha) blob.sentiment >> DataPeaker é uma ótima plataforma para aprender ciência de dados. Sentimento(polaridade = 0,8, subjetividade = 0,75)
Podemos ver que a polaridade é 0,8, o que significa que a afirmação é positiva e 0,75 subjetividade refere-se ao fato de ser principalmente uma opinião pública e não uma informação factual.
4. Outras coisas legais para fazer
4.1 Correção ortográfica
A verificação ortográfica é um recurso interessante que o TextBlob oferece, você pode nos acessar usando o Direito trabalhe como mostrado abaixo.
blob = TextBlob('DataPeaker é uma plataforma perfeita para aprender dados scence')
blob.correct()
>> TextBlob("DataPeaker é uma ótima plataforma para aprender ciência de dados")
Também podemos verificar a lista de palavras sugeridas e sua confiança usando o corretor ortografico Função.
blob.words[4].verificação ortográfica()
>> [('excelente', 0.5351351351351351),
('pegue', 0.3162162162162162),
('cresceu', 0.11216216216216217),
('cinza', 0.026351351351351353),
('saudar', 0.006081081081081081),
('fret', 0.002702702702702703),
('grão', 0.0006756756756756757),
('encaracolado', 0.0006756756756756757)]
4.2 Crie um breve resumo de um texto
Este é um truque simples que usaremos as coisas que aprendemos anteriormente. Primeiro, dê uma olhada no código mostrado abaixo e entenda-se.
importar aleatório
blob = TextBlob('DataPeaker é uma comunidade próspera para a indústria orientada a dados. Esta plataforma permite
que as pessoas saibam mais sobre análises a partir de seus artigos, Q&Um fórum, e caminhos de aprendizagem. Também, nós ajudamos
profissionais & amadores para aprimorar suas habilidades, fornecendo uma plataforma para participar de Hackathons. ')
substantivos = lista()
por palavra, tag em blob.tags:
if tag == 'NN':
substantivos.append(word.lemmatize())
imprimir ("Esse texto é sobre...")
para item em random.sample(substantivos, 5):
palavra = palavra(item)
imprimir (word.pluralize())
>> Esse texto é sobre...
comunidades
plataformas
fóruns
plataformas
indústrias
Simples, não é assim? O que fizemos anteriormente foi extrair uma lista de substantivos do texto para dar ao leitor uma ideia geral sobre as coisas a que o texto se refere..
4.3 Tradução e detecção de idioma
Você consegue adivinhar o que está escrito na seguinte linha?
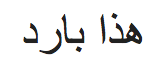
E e! Você consegue adivinhar que idioma é este? Não te preocupes, detectémoslo usando textblob…
blob.detect_language() >> 'Com'
Então, É árabe. Agora, vamos tentar traduzi-lo para o inglês para que possamos saber o que está escrito usando o TextBlob.
blob.translate(from_lang = 'ar', to = 'en')
>> TextBlob("isso é legal")
Mesmo se você não definir explicitamente o idioma de origem, O TextBlob detectará automaticamente o idioma e o traduzirá para o idioma desejado.
blob.translate(to = 'en') ## ou você pode fazer diretamente assim
>> TextBlob("isso é legal")
Isso é muito legal !!! 😀
5. Classificação de texto usando TextBlob
Vamos construir um modelo de classificação de texto simples usando TextBlob. Para isto, primeiro, precisamos preparar um treinamento e dados de teste.
treinamento = [
("Tom Holland é um homem-aranha terrível.",'pos'),
('um terrível Javert (Russell Crowe) arruinou Os miseráveis para mim ... ','pos'),
('The Dark Knight Rises é o maior filme de super-heróis de todos os tempos!','neg'),
('O Quarteto Fantástico nunca deveria ter sido feito.','pos'),
('Wes Anderson é meu diretor favorito!','neg'),
('Capitão América 2 é muito legal. ','neg'),
('Vamos fingir "Batman e Robin" nunca aconteceu..','pos'),
]
testando = [
('Superman nunca foi um personagem interessante.','pos'),
('Fantástico Sr. Fox é um filme incrível!','neg'),
('Dragonball Evolution é simplesmente terrível!!','pos')
]
Textblob fornece um módulo de classificadores embutido para criar um classificador personalizado. Então, vamos importá-lo rapidamente e criar um classificador básico.
de classificadores de importação textblob classifier = classifiers.NaiveBayesClassifier(Treinamento)
Como você pode ver acima, passamos os dados de treinamento para o classificador.
Observe que aqui usamos o classificador Naive Bayes, mas TextBlob também oferece classificador de árvore de decisão mostrado abaixo.
## classificador de árvore de decisão dt_classifier = classifiers.DecisionTreeClassifier(Treinamento)
Agora, vamos verificar a precisão deste classificador no conjunto de dados de teste e também o TextBlob nos fornece para verificar os recursos mais informativos.
imprimir (classifier.accuracy(testando))
classifier.show_informative_features(3)
>> 1.0
Recursos mais informativos
contém(é) = Neg verdadeiro : pos = 2.9 : 1.0
contém(Terrível) = Falso neg : pos = 1.8 : 1.0
contém(nunca) = Falso neg : pos = 1.8 : 1.0
O que, podemos ver que se o texto contém “isto é”, então há uma grande probabilidade de que a afirmação seja negativa.
Para dar um pouco mais de ideia, vamos verificar nosso classificador em um texto aleatório.
blob = TextBlob('o tempo está terrível!', classificador = classificador)
imprimir (blob.classify())
>> neg
Então, com base no treinamento no conjunto de dados acima, nosso classificador nos deu o resultado correto.
Observe que aqui poderíamos ter feito algum pré-processamento e limpeza de dados, mas aqui meu objetivo era dar uma ideia de como podemos fazer a classificação de texto usando TextBlob.
6. Prós e contras
Prós:
- Dado que, é construído sobre os ombros de NLTK e Padrão, portanto, torna mais simples para iniciantes, fornecendo uma interface intuitiva para NLTK.
- Fornece tradução e detecção de idioma que funciona com o Google Tradutor (não fornecido com o Spacy).
Contras:
- É um pouco mais lento em comparação com o espaço, mas mais rápido que NLTK. (Espaço> TextBlob> NLTK)
- Não fornece recursos como análise de dependência, vetores de palavras, etc. que fornece espaço.
7. Notas finais
Espero que você se divirta aprendendo sobre esta biblioteca. TextBlob, na realidade, forneceu uma interface muito fácil para iniciantes aprenderem tarefas básicas de PNL.
Eu recomendaria a todos os iniciantes que começassem com esta biblioteca e então, para fazer trabalho avançado, eles também podem aprender a ser espaçados. Continuaremos a usar TextBlob para prototipagem inicial em quase todos os projetos de PNL.
Você pode encontrar o código completo deste artigo em meu github repositório.
O que mais, Você achou este artigo útil? Compartilhe suas opiniões / pensamentos na seção de comentários abaixo.





