Introdução
La mayoría de ustedes habría escuchado cosas emocionantes que suceden usando el aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde.... Você também teria ouvido falar que o Deep Learning precisa de muito hardware.. Eu vi pessoas treinarem um modelo simples de aprendizado profundo por dias em seus laptops. (geralmente sem GPU), o que dá a impressão de que o aprendizado profundo precisa de grandes sistemas para ser executado.
Apesar disto, Isso é apenas parcialmente verdade e cria um mito em torno do aprendizado profundo que cria um obstáculo para iniciantes.. Inúmeras pessoas me perguntaram que tipo de hardware seria melhor para o aprendizado profundo.. Com este post espero responder.
Observação: Eu acho que você tem uma compreensão fundamental dos conceitos de aprendizagem profunda.. Sim, não é assim, Você deve ler este post.
Tabela de conteúdo
- Feito # 101: Necessidades de DL
Muito dehardware - Treinando um modelo de aprendizado profundo
- Como treinar seu modelo mais rápido?
- CPU vs GPU
- Uma breve história das GPUs: Como chegamos até aqui??
- Qual GPU usar hoje?
- O futuro parece emocionante
Feito # 101: Necessidades de aprendizagem profunda Muito de hardware
Quando fui apresentado pela primeira vez ao aprendizado profundo, Eu pensei que o aprendizado profundo necessariamente precisa de um grande data center para ser executado., e os “Especialistas em Deep Learning” Eles se sentaram em suas salas de controle para operar esses sistemas..

Isso ocorre porque em todos os livros que mencionei ou em todas as palestras que ouvi., O autor ou palestrante sempre comenta que o aprendizado profundo precisa de muito poder computacional para ser executado.. Mas quando construí meu primeiro modelo de aprendizado profundo na minha pequena máquina, Fiquei aliviada!! Eu não tenho que assumir o Google para ser um especialista em aprendizado profundo 😀
Este é um erro comum que todos os iniciantes enfrentam ao mergulhar no aprendizado profundo.. Embora seja verdade que o aprendizado profundo precisa de hardware considerável para ser executado com eficiência., Você não precisa que ele seja infinito para executar sua tarefa. Você pode até mesmo executar modelos de aprendizado profundo em seu laptop!!
Apenas um pequeno aviso de isenção de responsabilidade; quanto menor o seu sistema, Mais tempo você precisará para obter um modelo treinado que funcione bem o suficiente. Simplesmente, Pode parecer assim:

Vamos nos fazer uma pergunta simples; Por que precisamos de mais hardware para aprendizado profundo?
A solução é simples, O aprendizado profundo é um algoritmo – uma construção de software. Definimos una neuronal vermelhoAs redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano. Eles usam estruturas conhecidas como neurônios artificiais para processar e aprender com os dados. Essas redes são fundamentais no campo da inteligência artificial, permitindo avanços significativos em tarefas como reconhecimento de imagem, Processamento de linguagem natural e previsão de séries temporais, entre outros. Sua capacidade de aprender padrões complexos os torna ferramentas poderosas.. artificial en nuestro lenguaje de programación favorito que posteriormente se convertiría en un conjunto de comandos que se ejecutan en la computadora.
Se você tivesse que adivinhar quais componentes da rede neural você acha que exigiriam recursos de hardware intensos, Qual seria a sua resposta??
Alguns dos candidatos que tenho em mente são:
- Pré-processamento de dados de entrada
- Treinando o modelo de aprendizagem profunda
- Armazenamento de modelo de aprendizado profundo treinado
- Implantação de modelo
Entre todos estes, Treinar o modelo de aprendizagem profunda é a tarefa mais intensiva. Vamos ver em detalhes por que esse é o caso.
Treinando um modelo de aprendizado profundo
Quando você treina um modelo de aprendizado profundo, Duas operações principais são realizadas:
- Passe Antecipado
- Rolar para trás
No passo em frente, a entrada é passada através da rede neural e, Depois de processar a entrada, Uma saída é gerada. Enquanto no passe para trás, Atualizamos os pesos da rede neural com base no erro que recebemos no passe para a frente.
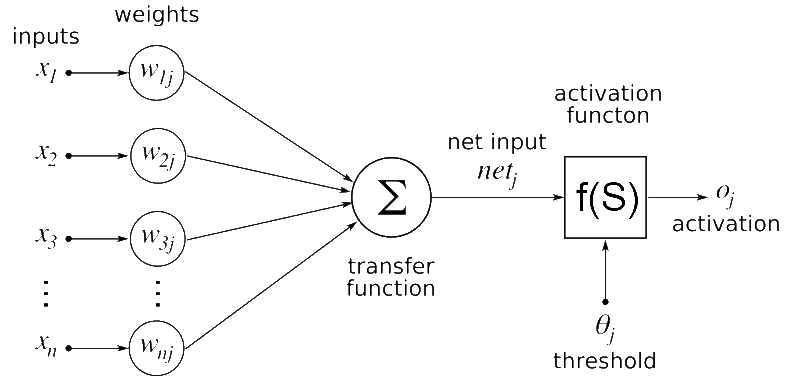
Ambas as operações são essencialmente multiplicações de matrizes. Uma multiplicação simples de matrizes pode ser representada com a próxima imagem
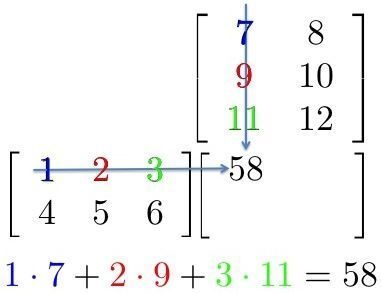
Aqui, Podemos ver que cada elemento em uma linha da primeira matriz é multiplicado por uma coluna da segunda matriz.. Então, em uma rede neural, Podemos considerar a primeira matriz como entrada para a rede neural, e a segunda matriz pode ser considerada como pesos de rede.
Esta parece ser uma tarefa simples. Agora, apenas para lhe dar uma ideia de que tipo de escalas de aprendizagem profunda: VGG16 (uma convolucional neuronal vermelhoRedes Neurais Convolucionais (CNN) são um tipo de arquitetura de rede neural projetada especialmente para processamento de dados com uma estrutura de grade, como fotos. Eles usam camadas de convolução para extrair recursos hierárquicos, o que os torna especialmente eficazes em tarefas de reconhecimento e classificação de padrões. Graças à sua capacidade de aprender com grandes volumes de dados, As CNNs revolucionaram campos como a visão computacional.. a partir de 16 camadas ocultas frequentemente usadas em aplicativos de aprendizado profundo) Tem~ 140 millones de parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto....; Também conhecido como pesos e vieses. Agora pense em todas as multiplicações de matriz que você teria que fazer para passar apenas uma entrada para esta rede!! Levaria anos para treinar esses tipos de sistemas se adotássemos abordagens tradicionais..
Como treinar sua rede neural mais rápido?
Vimos que a parte computacionalmente intensiva da rede neural é composta de multiplicações de múltiplas matrizes.. Então, Como podemos fazer isso mais rápido??
Podemos simplesmente fazer isso fazendo todas as operações ao mesmo tempo, em vez de uma após a outra.. Resumidamente, é por isso que usamos GPUs (Unidades de processamento gráfico) em vez de uma CPU (Unidade Central de Processamento) Para treinar uma rede neural.
Para lhe dar alguma intuição, voltamos à história quando provamos que as GPUs eram melhores do que as CPUs para a tarefa.
Antes do boom do aprendizado profundo, O Google tinha um sistema extremamente poderoso para fazer seu processamento, que eles tinham construído especialmente para treinar redes enormes. Este sistema era monstruoso e tinha um custo total de $ 5 mil milhões, com vários grupos de CPU.
Agora, los investigadores de Stanford construyeron el mismo sistema en términos de computación para entrenar sus redes profundasLas redes profundas, también conocidas como redes neuronales profundas, son estructuras computacionales inspiradas en el funcionamiento del cerebro humano. Estas redes están compuestas por múltiples capas de nodos interconectados que permiten aprender representaciones complejas de datos. Son fundamentales en el ámbito de la inteligencia artificial, especialmente en tareas como el reconocimiento de imágenes, procesamiento de lenguaje natural y conducción autónoma, mejorando así la capacidad de las máquinas para comprender y... usando GPU. E adivinhe o que; Eles reduziram os custos para apenas $ 33K! Este sistema foi construído com GPUs e forneceu o mesmo poder de processamento que o sistema do Google.. Bem impressionante, verdade?
| Stanford | ||
| Número de núcleos | 1K CPU = 16K núcleos | 3GPU = 18K núcleos |
| Custo | $ 5 mil milhões | $ 33 mil |
| Tiempo de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... | semana | semana |
Podemos ver que as GPUs governam. Mas, Qual é exatamente a diferença entre uma CPU e uma GPU?
Diferença entre CPU e GPU
Para entender a diferença, Tomamos uma analogia clássica que explica a diferença intuitivamente..
Suponha que você tenha que transferir mercadorias de um lugar para outro. Você tem a opção de selecionar entre uma Ferrari e um caminhão de carga.
Ferrari seria extremamente rápido e ajudá-lo a transferir um lote de mercadorias em nenhum momento.. Mas a quantidade de mercadorias que pode transportar é pequena e o uso de combustível seria muito alto..
Um caminhão de carga seria lento e demorado para transferir mercadorias.. Mas a quantidade de mercadorias que pode transportar é maior em comparação com a Ferrari.. Ao mesmo tempo, é mais eficiente em termos de combustível, para que o uso seja menor.
Então, Qual você escolheria para o seu trabalho??
Evidentemente, Primeiro você verá qual é a tarefa; Se você tiver que pegar sua namorada com urgência, definitivamente escolheria uma Ferrari em vez de um caminhão de carga. Mas se você está mudando sua casa, usaria um caminhão de carga para transferir os móveis.
Veja como você diferenciaria tecnicamente os dois:

Aqui está outro vídeo que esclareceria ainda mais o seu conceito..
Observação: A GPU é usada principalmente para jogos complexos e simulações. Estas tarefas e principalmente cálculos gráficos, portanto, a GPU é uma unidade de processamento gráfico. Se a GPU for usada para processamento não gráfico, são chamados de GPGPU: Unidade de Processamento Gráfico de Uso Geral
Uma breve história das GPUs: Como chegamos até aqui??
Agora, você pode estar se perguntando por que as GPUs estão tão quentes agora. Vamos viajar por uma breve história do desenvolvimento de GPUs.
Simplesmente, Uma GPGPU é uma configuração de programação paralela envolvendo GPUs e CPUs que podem processar e analisar dados de maneira equivalente a uma imagem ou outra maneira gráfica. GPGPUs foram construídas para um processamento gráfico melhor e mais geral, Mas mais tarde descobriu-se que eles eram bem adequados para a computação científica.. Isso ocorre porque a maioria dos processamentos gráficos envolve a aplicação de operações em matrizes grandes..
O uso do GPGPU para computação científica começou em 2001 com a implementação da multiplicação matricial. Um dos primeiros algoritmos comuns a ser implementado em GPUs mais rapidamente foi a fatoração LU em 2005. Mas, neste momento, os pesquisadores tiveram que codificar todos os algoritmos em uma GPU e tiveram que entender o processamento gráfico de baixo nível..
Sobre 2006, Nvidia introduziu uma linguagem CUDA de alto nível, que ajuda você a escrever programas a partir de processadores gráficos em uma linguagem de alto nível. Esta foi provavelmente uma das mudanças mais significativas na forma como os pesquisadores interagem com as GPUs..
Qual GPU usar hoje?
Aqui eu vou rapidamente dar-lhe algum conhecimento técnico antes de comprar uma GPU para aprendizagem profunda..
Estágio 1:
A primeira coisa que você precisa determinar é que tipo de recurso suas tarefas exigem.. Se suas tarefas serão pequenas ou se podem caber em processamento sequencial complexo, Você não precisa de um ótimo sistema para trabalhar com. Você pode até ignorar o uso de GPUs completamente. Por isso, Se você planeja trabalhar principalmente em "outras" áreas / Algoritmos de ML, não precisa necessariamente de uma GPU.
Estágio 2:
Se a sua tarefa é um pouco intensiva e você tem dados gerenciáveis, uma GPU razoável seria uma escolha melhor para você. Eu geralmente uso meu laptop para trabalhar em problemas de brinquedos, que tem uma GPU ligeiramente desatualizada (um 2GB Nvidia GT 740M). Ter um laptop com GPUs me ajuda a executar as coisas onde quer que eu vá.. Existem alguns laptops high-end (e espera-se que sejam pesados) com Nvidia GTX 1080 (uma VRAM de 8 GB) que você pode consultar no final.
Estágio 3:
Se você trabalha regularmente em problemas complexos ou é uma empresa que aproveita o aprendizado profundo, probablemente sería mejor que creara un sistema de aprendizaje profundo o utilizara un Serviço de nuvemo "Serviço de nuvem" refere-se à entrega de recursos de computação pela Internet, Permitindo que os usuários acessem o armazenamento, Processamento e aplicativos sem a necessidade de infraestrutura física local. Este modelo oferece flexibilidade, Escalabilidade e economia de custos, já que as empresas pagam apenas pelo que usam. O que mais, Facilita a colaboração e o acesso aos dados de qualquer lugar, melhorando a eficiência operacional em vários setores.. como AWS o FloydHub. Na DataPeaker, criamos um sistema de aprendizado profundo para nós mesmos, para o qual compartilhamos nossas especificações. Aqui está o post.
Estágio 4:
Se você é o Google, Você provavelmente precisará de outro data center para manter. Brincadeiras à parte., se a sua tarefa é de uma escala maior do que o habitual e você tem dinheiro de bolso suficiente para cobrir os custos; puede elegir por un cachoUm cluster é um conjunto de empresas e organizações interconectadas que operam no mesmo setor ou área geográfica, e que colaboram para melhorar sua competitividade. Esses agrupamentos permitem o compartilhamento de recursos, Conhecimentos e tecnologias, Promover a inovação e o crescimento económico. Os clusters podem abranger uma variedade de setores, Da tecnologia à agricultura, e são fundamentais para o desenvolvimento regional e a criação de empregos.... de GPU y hacer computación con múltiples GPU. Além disso, existem algumas opções que podem estar disponíveis em um futuro próximo., TPU e FPGA tão rápidos, que tornaria a sua vida mais fácil.
O futuro parece emocionante
como dito anteriormente, Há muita pesquisa e trabalho ativo para pensar em alternativas para acelerar a computação.. Espera-se que o Google introduza as unidades de processamento do Tensorflow (TPU) ainda este ano, que promete aceleração acima das GPUs atuais.
Equivalentemente, Intel está trabalhando para criar FPGAs mais rápidos, que pode conceder maior flexibilidade nos próximos dias. Ao mesmo tempo, Ofertas de provedores de serviços em nuvem (como um exemplo, AWS) Eles também estão aumentando. Veremos cada um deles emergir nos próximos meses..
Notas finais
Neste post, cobrimos as motivações de usar uma GPU para aplicativos de aprendizado profundo e vimos como escolhê-las para sua tarefa. Espero que este post tenha sido útil para você.. Se você tiver alguma dúvida específica sobre o assunto, Sinta-se à vontade para comentar abaixo ou perguntar em portal de discussão.





