Este artigo foi publicado como parte do Data Science Blogathon
Pré-processamento de dados
É também um passo importante na mineração de dados, pois não podemos trabalhar com dados brutos. A qualidade dos dados deve ser verificada antes de aplicar algoritmos de aprendizado de máquina ou mineração de dados.
Por que o pré-processamento de dados é importante??
O pré-processamento de dados é principalmente para verificar a qualidade dos dados. A qualidade pode ser verificada pelo seguinte
- Precisão: Para verificar se os dados inseridos estão corretos ou não.
- Eu completo: Para verificar se os dados estão disponíveis ou não registrados.
- Consistência: Para verificar se os mesmos dados são salvos em todos os locais correspondentes ou não.
- Oportunidade: Os dados devem ser atualizados corretamente.
- Credibilidade: Os dados devem ser confiáveis.
- Interpretabilidade: A compreenso dos dados.
- Limpeza de dados
- Integração de dados
- redução de dados
- Transformação de dados
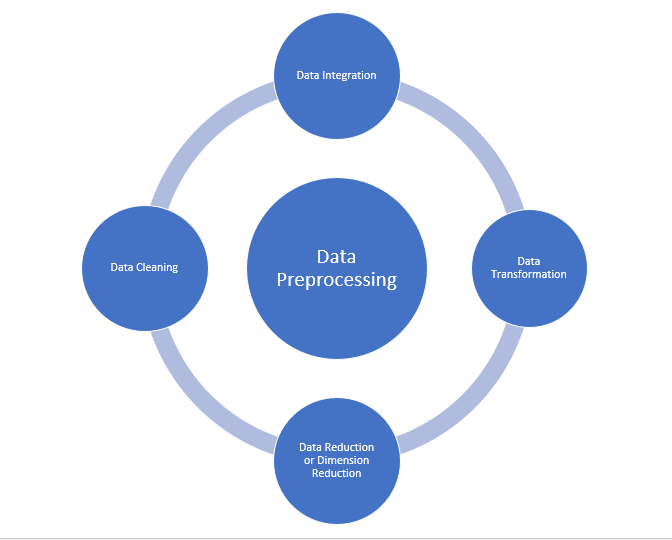
Fonte: por Jeff Atwood e Joel Spolsky e o site principal da Stack Exchange Network
Limpeza de dados:
A limpeza de dados é o processo de remoção de dados ruins, dados incompletos e dados imprecisos de conjuntos de dados, e também substituir valores ausentes. Existem algumas técnicas de limpeza de dados
Tratamento de valores ausentes:
- Você pode usar valores padrão como “Não disponível” o “N / D” para substituir valores ausentes.
- Os valores ausentes também podem ser preenchidos manualmente, mas não é recomendado quando o conjunto de dados é grande.
- O valor médio do atributo pode ser usado para substituir o valor ausente quando os dados são normalmente distribuídos.
em que, para uma distribuição não normal, o valor mediano do atributo pode ser usado. - Ao usar árvore de decisão ou algoritmos de regressão, o valor ausente pode ser substituído pelo valor mais provável.
valor.
Alto:
Barulhento geralmente significa erro aleatório ou contendo pontos de dados desnecessários. Aqui estão alguns dos métodos para lidar com dados ruidosos.
- Binning: Este método é usado para suavizar ou manipular dados ruidosos.. Primeiro, os dados são ordenados e então os valores ordenados são separados e armazenados na forma de bins. Existem três métodos para suavizar os dados do contêiner. Suavizado por método bin mean: Neste método, os valores do bin são substituídos pelo valor do meio do bin; Suavizado por medianaA mediana é uma medida estatística que representa o valor central de um conjunto de dados ordenados. Para calculá-lo, Os dados são organizados do menor para o maior e o número no meio é identificado. Se houver um número par de observações, Os dois valores principais são calculados em média. Este indicador é especialmente útil em distribuições assimétricas, uma vez que não é afetado por valores extremos.... Da lixeira: Neste método, os valores do contêiner são substituídos pelo valor mediano; Suavização do limite do contêiner: Neste método, os valores de uso mínimo e máximo são retirados dos valores de localização e os valores são substituídos pelo valor limite mais próximo.
- Regressão: Ele é usado para suavizar os dados e ajudará a lidar com os dados quando houver dados desnecessários. para análise, A regressão de propósito ajuda a decidir o variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... que é apropriado para nossa análise.
- Agrupamento: É usado para encontrar os outliers e também para agrupar os dados. O agrupamento é geralmente usado no Aprendizado não supervisionadoO aprendizado não supervisionado é uma técnica de aprendizado de máquina que permite que os modelos identifiquem padrões e estruturas em dados sem rótulos predefinidos. Por meio de algoritmos como k-means e análise de componentes principais, Essa abordagem é usada em uma variedade de aplicações, como segmentação de clientes, detecção de anomalias e compactação de dados. Sua capacidade de revelar informações ocultas o torna uma ferramenta valiosa no....
Integração de dados:
O processo de combinar várias fontes em um único conjunto de dados. O processo de integração de dados é um dos principais componentes no gerenciamento de dados. Existem alguns problemas que precisam ser considerados durante a integração de dados.
- Integração de esquema: Integrar metadados (um conjunto de dados que descreve outros dados) de diferentes fontes.
- Problema de identificação de entidade: Identificação de entidades de vários bancos de dados. Por exemplo, O sistema ou uso deve conhecer o aluno _id de um base de dadosUm banco de dados é um conjunto organizado de informações que permite armazenar, Gerencie e recupere dados com eficiência. Usado em várias aplicações, De sistemas corporativos a plataformas online, Os bancos de dados podem ser relacionais ou não relacionais. O design adequado é fundamental para otimizar o desempenho e garantir a integridade das informações, facilitando assim a tomada de decisão informada em diferentes contextos.... e o nome do aluno de outro banco de dados pertence à mesma entidade.
- Detectar e resolver conceitos de valor de dados: Os dados obtidos de diferentes bancos de dados durante a mesclagem podem diferir. Como os valores de atributo de um banco de dados podem diferir de outro banco de dados. Por exemplo, o formato da data pode diferir conforme “MILÍMETROS / DD / AAAA” o “DD / MILÍMETROS / AAAA”.
redução de dados:
Este processo ajuda a reduzir o volume de dados, que facilita a análise e produz o mesmo ou quase o mesmo resultado. Essa redução também ajuda a reduzir o espaço de armazenamento. Algumas das técnicas em redução de dados são Redução de Dimensionalidade, Redução de Numerosidade, Compressão de dados.
- Redução de dimensionalidade: Este processo é necessário para aplicações do mundo real, já que o tamanho dos dados é grande. Nesse processo, a redução de atributos ou variáveis aleatórias é feita para que a dimensionalidade do conjunto de dados possa ser reduzida. Combine e mescle os atributos dos dados sem perder suas características originais. Isso também ajuda a reduzir o espaço de armazenamento e o tempo de computação.. Quando os dados são altamente dimensionais, o problema chamado “A Maldição da Dimensionalidade”.
- Redução de numerosidade: Neste método, a representação de dados torna-se menor reduzindo o volume. Não haverá perda de dados nesta redução.
- Compressão de dados: A forma compactada de dados é chamada de compactação de dados. Essa compactação pode ser sem perdas ou com perdas.. Quando não há perda de informação durante a compressão, Chama-se compressão sem perdas.. Enquanto a compressão com perdas reduz a informação, mas só remove informações desnecessárias.
Transformação de dados:
A alteração feita no formato ou estrutura dos dados é chamada de transformação de dados.. Esta etapa pode ser simples ou complexa, dependendo dos requisitos. Existem alguns métodos na transformação de dados.
- suavizado: Com a ajuda de algoritmos, podemos remover o ruído do conjunto de dados e isso ajuda a conhecer os recursos importantes do conjunto de dados. Ao suavizar podemos encontrar até uma simples mudança que ajuda na previsão.
- Agregação: Neste método, os dados são armazenados e apresentados em forma de resumo. O conjunto de dados que vem de várias fontes é integrado à descrição da análise de dados. Este é um passo importante, pois a precisão dos dados depende da quantidade e da qualidade dos dados.. Quando a qualidade e a quantidade de dados são boas, os resultados são mais relevantes.
- Discretização: Os dados contínuos aqui são divididos em intervalos. A discretização reduz o tamanho dos dados. Por exemplo, em vez de especificar o horário da aula, podemos definir um intervalo como (3 pm-5 pm, 6 pm-20:00).
- NormalizaçãoA padronização é um processo fundamental em várias disciplinas, que busca estabelecer padrões e critérios uniformes para melhorar a qualidade e a eficiência. Em contextos como engenharia, Educação e administração, A padronização facilita a comparação, Interoperabilidade e compreensão mútua. Ao implementar normas, a coesão é promovida e os recursos são otimizados, que contribui para o desenvolvimento sustentável e a melhoria contínua dos processos....: É o método de dimensionamento dos dados para que possam ser representados em uma faixa menor. Exemplo que vai de -1.0 uma 1.0.
Etapas de pré-processamento de dados no aprendizado de máquina
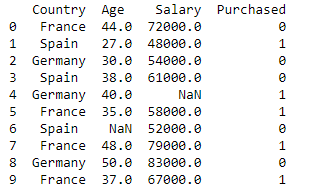
Bibliotecas de importação e conjunto de dados
import pandas as pd
import numpy as np
dataset = pd.read_csv('Conjuntos de dados.csv')
imprimir (data_set)
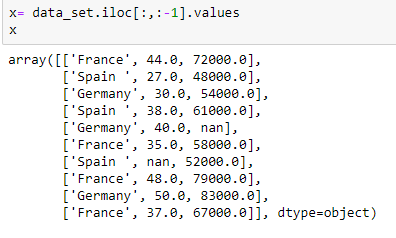
Extração de variável independente:
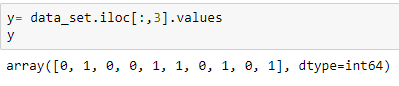
Extração de variável dependente:
Preencha o conjunto de dados com o valor médio do atributo
from sklearn.preprocessing import Imputer
imputer= Imputer(missing_values="Nan", estratégia='média', eixo = 0)
imputerimputer= imputer.fit(x[:, 1:3])
x[:, 1:3]= imputer.transform(x[:, 1:3])
x
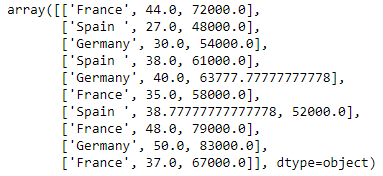
Codificação da variável país
Modelos de aprendizagem de máquina usam equações matemáticas. Então, dados categóricos não são aceitos, então nós os convertemos em forma numérica.
from sklearn.preprocessing import LabelEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
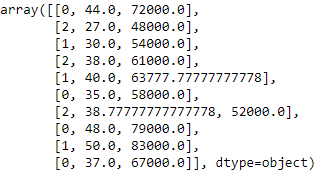
Codificação fictícia
Essas variáveis manequim substituem dados categóricos, como 0 e 1 na ausência ou presença de dados categóricos específicos.
Codificação da variável comprada
labelencoder_y= LabelEncoder() y= labelencoder_y.fit_transform(e)
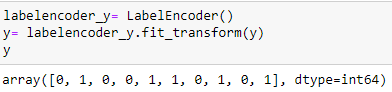
Divida o conjunto de dados em um conjunto de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... e teste:
de sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test= train_test_split(x, e, test_size= 0.2, random_state = 0)
Escala de recursos
de sklearn.preprocessando importação StandardScaler
st_x= StandardScaler() x_train= st_x.fit_transform(x_train)

x_test= st_x.transform(x_test)
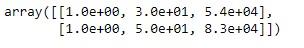
conclusão:
Neste artigo, Eu expliquei sobre o passo mais crucial no aprendizado de máquina é o pré-processamento de dados. Espero que este artigo ajude você a entender melhor o conceito.
Referência:
https://www.javatpoint.com/data-preprocessing-machine-learning
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





