Este artigo foi publicado como parte do Data Science Blogathon
Introdução
Python é uma linguagem versátil. Usado para programação geral e propósitos de desenvolvimento, e também para tarefas complexas como aprendizado de máquina, ciência de dados e análise de dados. Não só é fácil de aprender, também tem algumas bibliotecas maravilhosas, o que a torna a linguagem de programação de primeira escolha para muitas pessoas.
Neste artigo, veremos um desses casos de uso do Python. Usaremos Python para analisar o desempenho do jogador de críquete indiano MS Dhoni em sua carreira no One Day International (ODI).

Conjunto de dados
Se você está familiarizado com o conceito de web scraping, você pode extrair os dados deste Link ESPN Cricinfo. Se você não sabe sobre web scraping, não se preocupe! Você pode baixar os dados diretamente de aqui. Os dados estão disponíveis como um arquivo Excel para download.
Depois de ter o conjunto de dados com você, você precisará carregá-lo em Python. Você pode usar o snippet de código abaixo para carregar o conjunto de dados em Python:
# importar bibliotecas e pacotes essenciais
importar pandas como pd
importar numpy como np
importar data e hora
import matplotlib.pyplot as plt
importado do mar como sns
# lendo o conjunto de dados
df = pd.read_excel('MS_Dhoni_ODI_record.xlsx')
Assim que o conjunto de dados for lido, precisamos olhar o início e o fim do conjunto de dados para ter certeza de que ele foi importado corretamente. O cabeçalho do conjunto de dados deve ser semelhante a este:
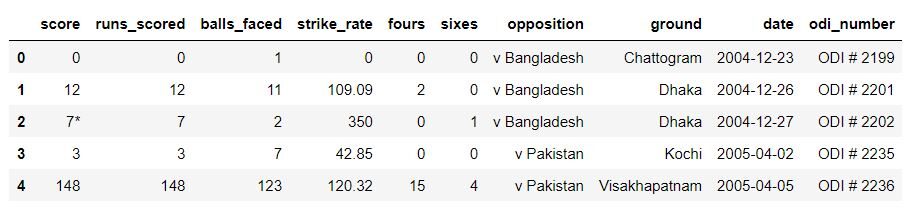
Se os dados forem carregados corretamente, podemos ir para a próxima etapa, limpeza e preparação de dados.
Limpeza e preparação de dados
Esses dados foram extraídos de uma página da web, então eles não são muito limpos. Começaremos removendo o primeiro 2 caracteres da string de oposição porque isso não é necessário.
# removendo o primeiro 2 caracteres na string de oposição df['oposição'] = df['oposição'].Aplique(lambda x: x[2:])
A seguir, vamos criar uma coluna para o ano em que o jogo foi jogado. Certifique-se de que a coluna de data esteja presente no formato DateTime em seu DataFrame. Pelo contrário, utilice pd.to_datetime () para convertê-lo para o formato DateTime.
# criando um recurso para o ano de jogo df['ano'] = df['encontro'].dt.ano.astype(int)
Também criaremos uma coluna que indica se Dhoni não estava nessa entrada ou não.
# criando um recurso para não estar de fora
df['pontuação'] = df['pontuação'].Aplique(str)
df['not_out'] = np.where(df['pontuação'].str.endswith('*'), 1, 0)
Agora vamos remover a coluna do número ODI porque não é necessário.
# descartando o recurso odi_number porque não adiciona valor à análise df.drop(colunas ="odi_number", inplace = True)
Também removeremos todas as correspondências de nossos registros em que Dhoni não acertou e armazenaremos essas informações em um novo DataFrame.
# abandonando as entradas em que Dhoni não bateu e armazenando em um novo DataFrame df_new = df.loc[((df['pontuação'] != 'DNB') & (df['pontuação'] != 'TDNB')), 'runs_scored':]
Finalmente, vamos corrigir os tipos de dados de todas as colunas presentes em nosso novo DataFrame.
# corrigir os tipos de dados de colunas numéricas df_new['runs_scored'] = df_new['runs_scored'].astype(int) df_new['balls_faced'] = df_new['balls_faced'].astype(int) df_new['taxa de greve'] = df_new['taxa de greve'].astype(flutuador) df_new['quatros'] = df_new['quatros'].astype(int) df_new['seis'] = df_new['seis'].astype(int)
Estatísticas de corrida
Vamos dar uma olhada no estatísticas descritivas da carreira ODI de MS Dhoni. Você pode usar o seguinte código para isso:
first_match_date = df['encontro'].dt.date.min().strftime('% B% d, %E') # primeira partida
imprimir('Primeira partida:', first_match_date)
last_match_date = df['encontro'].dt.date.max().strftime('% B% d, %E') # última partida
imprimir('nÚltima partida:', last_match_date)
number_of_matches = df.shape[0] # número de matemáticas jogadas na carreira
imprimir('nNúmero de partidas jogadas:', number_of_matches)
number_of_inns = df_new.shape[0] # número de entradas
imprimir('nNúmero de entradas jogadas:', numero_de_inns)
not_outs = df_new['not_out'].soma() # número de não eliminados na carreira
imprimir('nNão fora:', not_outs)
runs_scored = df_new['runs_scored'].soma() # corridas marcadas na carreira
imprimir('nRuns marcou na carreira:', runs_scored)
balls_faced = df_new['balls_faced'].soma() # bolas enfrentadas na carreira
imprimir('nBalls enfrentados na carreira:', balls_faced)
career_sr = (runs_scored / balls_faced)*100 # taxa de greve de carreira
imprimir(Taxa de acerto da nCareer: {:.2f}'.formato(career_sr))
career_avg = (runs_scored / (numero_de_inns - not_outs)) # média de carreira
imprimir('nCareer média: {:.2f}'.formato(career_avg))
maximum_score_date = df_new.loc[df_new.runs_scored == df_new.runs_scored.max(), 'encontro'].valores[0]
maior_score = df.loc[df.date == higher_score_date, 'pontuação'].valores[0] # maior pontuação
imprimir(Pontuação mais alta da carreira:', maior pontuação)
centenas = df_new.loc[df_new['runs_scored'] >= 100].forma[0] # número de 100s
imprimir('nNumber of 100s:', centenas)
cinquenta = df_new.loc[(df_new['runs_scored']>= 50)&(df_new['runs_scored']<100)].forma[0] #número de 50
imprimir('nNumber of 50s:', anos cinquenta)
quatros = df_new['quatros'].soma() # número de quatros na carreira
imprimir('nNúmero de 4s:', quatros)
sixes = df_new['seis'].soma() # número de seis na carreira
imprimir('nNúmero de 6s:', seis)
A saída deve ser semelhante a esta:
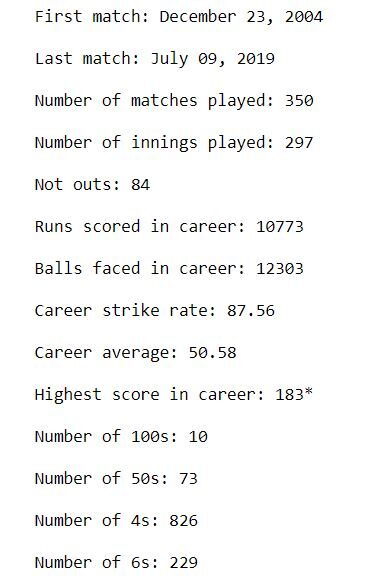
Isso nos dá uma boa ideia da carreira geral de MS Dhoni. Começou a jogar em 2004, e jogou pela última vez um ODI em 2019. Em uma carreira de mais de 15 anos, marcou 10 centenas e uma quantidade impressionante de 73 cinquenta. Marcou mais de 10,000 carreiras em sua carreira com uma média de 50.6 e uma taxa de ataque de 87.6. Sua maior pontuação é 183 *.
Agora faremos uma análise mais exaustiva de seu desempenho em diferentes equipes. Também veremos seu desempenho ano após ano. Teremos a ajuda de visualizações para este.
Análise
Em primeiro lugar, veremos quantos jogos que você jogou contra diferentes oposições. Você pode usar o seguinte código para esta finalidade:
# número de partidas disputadas contra diferentes oposições df['oposição'].valor_contas().enredo(kind = 'bar', título ="Número de partidas contra diferentes oposições", figsize =(8, 5));
A saída deve ser semelhante a esta:
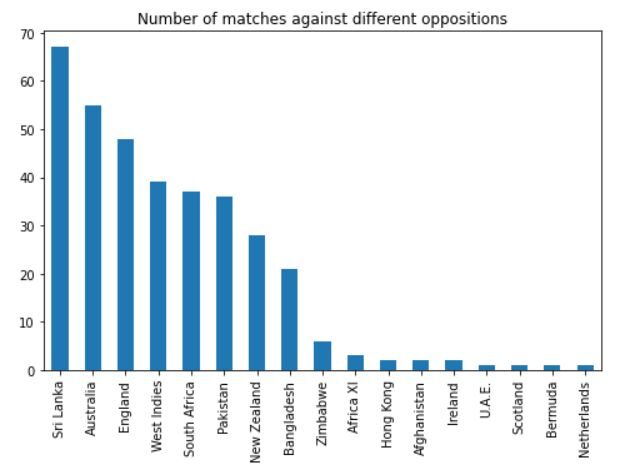
Podemos ver que ele jogou a maioria de suas partidas contra o Sri Lanka, Austrália, Inglaterra, Índias Ocidentais, África do sul e paquistão.
Vamos ver quantos carreiras que você marcou contra diferentes oposições. Você pode usar o seguinte snippet de código para gerar o resultado:
runs_scored_by_opposition = pd.DataFrame(df_new.groupby('oposição')['runs_scored'].soma())
runs_scored_by_opposition.plot(kind = 'bar', título ="Corridas marcadas contra diferentes oposições", figsize =(8, 5))
plt.xlabel(Nenhum);
A saída ficará assim:
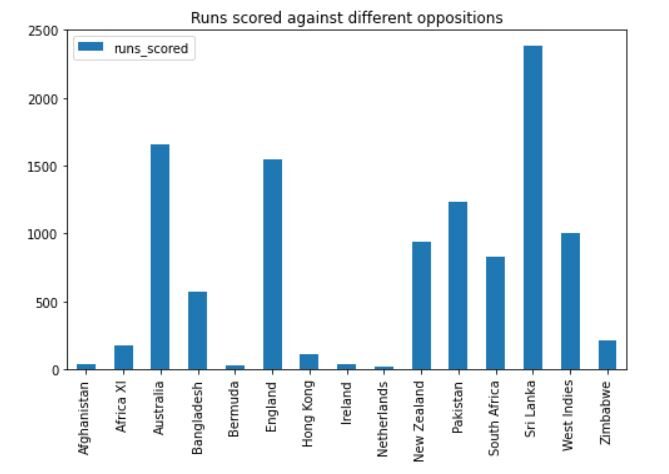
Podemos ver que Dhoni marcou o maior número de corridas contra o Sri Lanka, seguido pela austrália, Inglaterra e Paquistão. Ele também jogou muitos jogos contra essas equipes, então faz sentido.
Para ter uma imagem mais clara, vamos dar uma olhada no seu média de rebatidas contra cada equipe. O seguinte snippet de código nos ajudará a obter o resultado desejado:
innings_by_opposition = pd.DataFrame(df_new.groupby('oposição')['encontro'].contar())
not_outs_by_opposition = pd.DataFrame(df_new.groupby('oposição')['not_out'].soma())
temp = runs_scored_by_opposition.merge(innings_by_opposition, left_index = True, right_index = True)
média_por_opposição = temp.merge(not_outs_by_opposition, left_index = True, right_index = True)
average_by_opposition.rename(colunas = {'encontro': 'innings'}, inplace = True)
média_por_opposição['eff_num_of_inns'] = média_por_opposição['innings'] - média_por_opposição['not_out']
média_por_opposição['média'] = média_por_opposição['runs_scored'] / média_por_opposição['eff_num_of_inns']
average_by_opposition.replace(por exemplo, inf, np.nan, inplace = True)
major_nations = ['Austrália', 'Inglaterra', 'Nova Zelândia', 'Paquistão', 'África do Sul', 'Sri Lanka', 'Índias Ocidentais']
Para gerar o gráfico, use o trecho de código abaixo:
plt.figure(figsize = (8, 5))
plt.plot(média_por_opposição.loc[major_nations, 'média'].valores, marcador ="o")
plt.plot([career_avg]*len(major_nations), '-')
plt.title('Média contra times principais')
plt.xticks(faixa(0, 7), major_nations)
plt.ylim(20, 70)
plt.legend(['Média contra oposição', 'Média de carreira']);
A saída ficará assim:
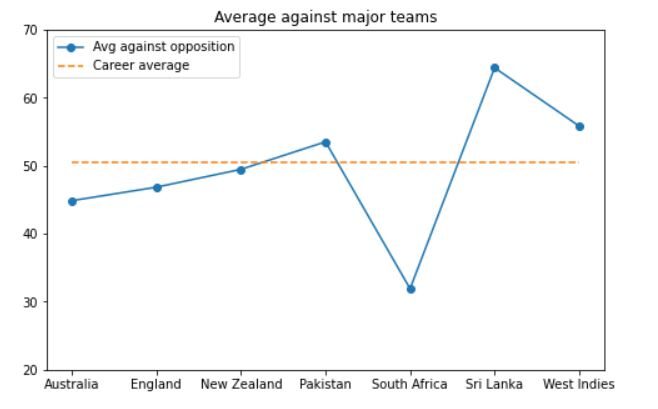
Como podemos ver, Dhoni teve um desempenho notável contra times difíceis como a Austrália, Inglaterra e Sri Lanka. Sua média contra essas equipes é próxima à média de sua carreira ou ligeiramente superior.. O único time contra o qual ele não teve um bom desempenho é a África do Sul.
Vamos agora ver suas estatísticas anuais. Começaremos procurando quantos jogos você jogou a cada ano depois de sua estreia. O código para isso será:
df['ano'].valor_contas().sort_index().enredo(kind = 'bar', título ="Partidas jogadas por ano", figsize =(8, 5)) plt.xticks(rotação = 0);
O enredo ficará assim:
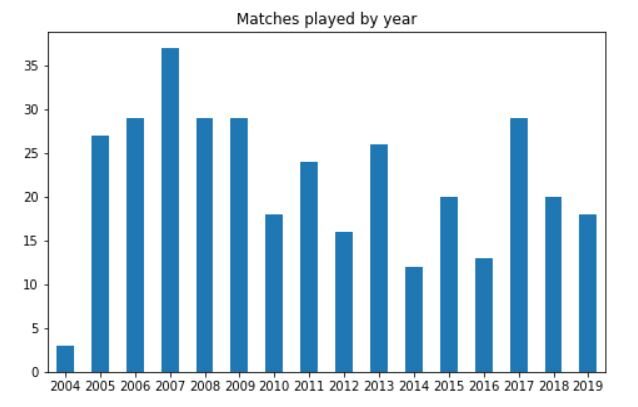
Podemos ver isso em 2012, 2014 e 2016, Dhoni jogou muito poucas partidas ODI pela Índia. Em geral, depois de 2005-2009, o número médio de partidas jogadas diminuiu ligeiramente.
Devemos também ver quantos carreiras que ele marcou todos os anos. O código para isso será:
df_new.groupby('ano')['runs_scored'].soma().enredo(kind = 'linha', marcador ="o", título ="Corridas marcadas por ano", figsize =(8, 5))
anos = df['ano'].exclusivo().listar()
plt.xticks(anos)
plt.xlabel(Nenhum);
A saída deve ser semelhante a esta:
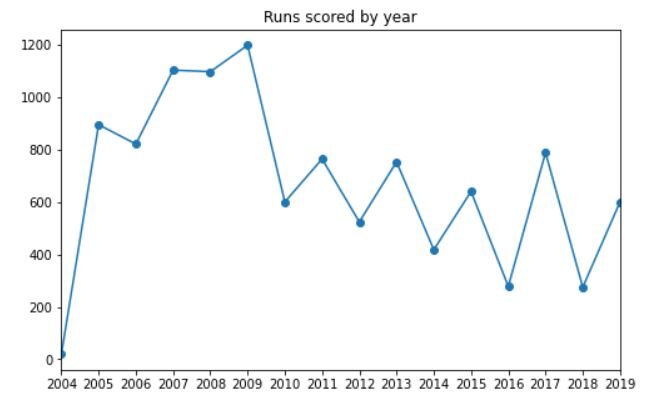
Você pode ver claramente que Dhoni marcou o maior número de corridas do ano 2009, seguido de 2007 e 2008. O número de corridas começou a diminuir após 2010 (porque o número de jogos jogados também começou a diminuir).
Finalmente, vamos ver o dele Progressão média de rebatidas na carreira por entrada. Estes são dados de série temporal e foram plotados em um diagrama de linha. O código para isso será:
df_new.reset_index(drop = True, inplace = True) career_average = pd.DataFrame() career_average['runs_scored_in_career'] = df_new['runs_scored'].cumsum() career_average['innings'] = df_new.index.tolist() career_average['innings'] = career_average['innings'].Aplique(lambda x: x + 1) career_average['not_outs_in_career'] = df_new['not_out'].cumsum() career_average['eff_num_of_inns'] = career_average['innings'] - career_average['not_outs_in_career'] career_average['média'] = career_average['runs_scored_in_career'] / career_average['eff_num_of_inns']
O trecho de código para o gráfico será:
plt.figure(figsize = (8, 5))
plt.plot(career_average['média'])
plt.plot([career_avg]*career_average.shape[0], '-')
plt.title('Progressão média da carreira por turnos')
plt.xlabel('Número de entradas')
plt.legend(['Progressão média', 'Média de carreira']);
O gráfico de saída ficará assim:
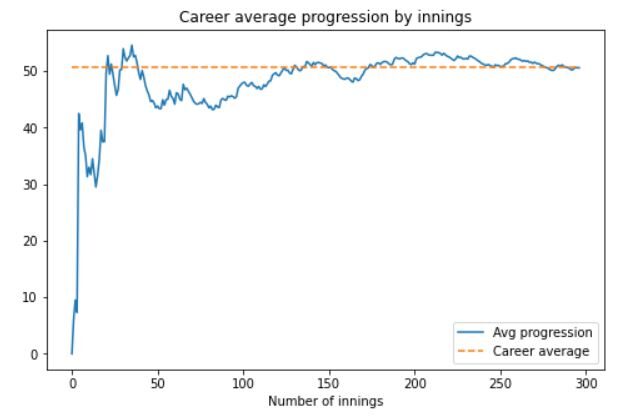
Podemos ver que após um início lento e uma queda no desempenho do número de entrada 50, O desempenho de Dhoni recuperou substancialmente. Perto do final de sua carreira, consistentemente em média acima 50.
EndNote
Neste artigo, analisamos o desempenho de rebatidas do jogador de críquete indiano MS Dhoni. Nós olhamos as estatísticas gerais de sua carreira, seu desempenho contra oponentes diferentes e seu desempenho ano após ano.
Este artigo foi escrito por Vishesh Arora. Você pode se conectar comigo em LinkedIn.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





