Este artigo foi publicado como parte do Data Science Blogathon
Assuma o trabalho de um engenheiro de dados, extração de dados de várias fontes de formatos de arquivo, transformá-los em tipos de dados específicos e carregá-los em uma única fonte para análise. Pouco depois de ler este artigo, com a ajuda de vários exemplos práticos, você poderá testar suas habilidades implementando web scraping e extração de dados com API. Com Python e engenharia de dados, você pode começar a coletar grandes conjuntos de dados de muitas fontes e transformá-los em uma única fonte primária ou começar a rastrear a web para obter insights úteis de negócios.
Sinopse:
- Por que a engenharia de dados é mais confiável?
- Processo de ciclo ETL
- Extrato passo a passo, transformar, função de carga
- Sobre engenharia de dados
- Sobre mim
- conclusão
Por que a engenharia de dados é mais confiável?
É uma ocupação tecnológica mais confiável e de crescimento mais rápido na geração atual, uma vez que se concentra mais em web scraping e rastreamento de conjunto de dados.
Processo (Ciclo ETL):
Você já se perguntou como os dados de muitas fontes foram integrados para criar uma única fonte de informações? Lote é uma maneira de coletar dados e aprender mais sobre “como explorar um tipo de lote” chamado Extract, Transformar e carregar.
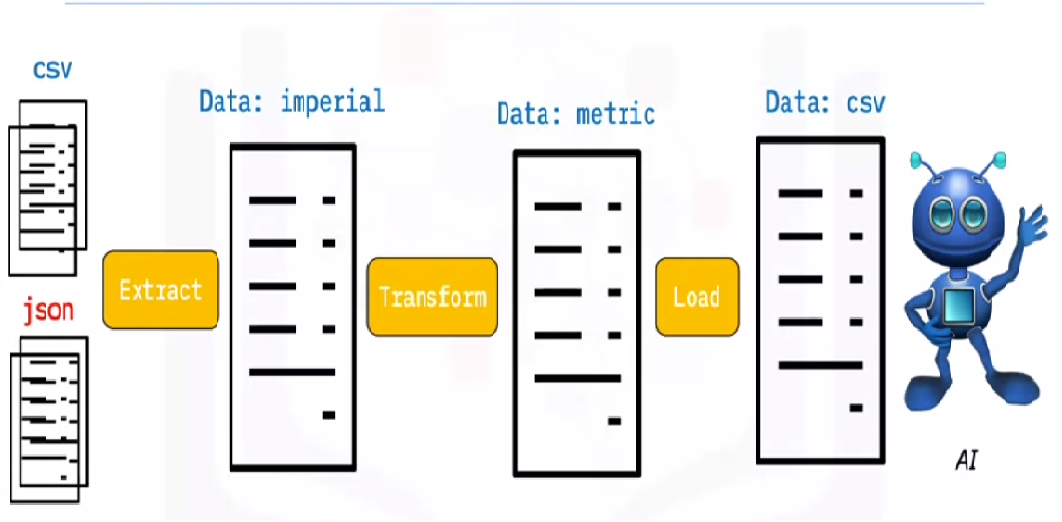
ETL é o processo de extrair grandes volumes de dados de uma variedade de fontes e formatos e convertê-los em um único formato antes de colocá-los em um base de dadosUm banco de dados é um conjunto organizado de informações que permite armazenar, Gerencie e recupere dados com eficiência. Usado em várias aplicações, De sistemas corporativos a plataformas online, Os bancos de dados podem ser relacionais ou não relacionais. O design adequado é fundamental para otimizar o desempenho e garantir a integridade das informações, facilitando assim a tomada de decisão informada em diferentes contextos.... ou em um arquivo de destino.
Alguns de seus dados são armazenados em arquivos CSV, enquanto outros são armazenados em arquivos JSONJSON, o Notação de objeto JavaScript, É um formato leve de troca de dados que é fácil para os humanos lerem e escreverem, e fácil para as máquinas analisarem e gerarem. É comumente usado em aplicativos da web para enviar e receber informações entre um servidor e um cliente. Sua estrutura é baseada em pares de valores-chave, tornando-o versátil e amplamente adotado no desenvolvimento de software... Você precisa coletar todas essas informações em um único arquivo para a IA ler. Porque seus dados estão em unidades imperiais, mas AI precisa de unidades métricas, deve convertê-los. Porque AI só pode ler dados CSV em um único arquivo grande, você deve carregá-lo primeiro. Se os dados estiverem no formato CSV, vamos colocar o seguinte ETL com python e dar uma olhada na etapa de extração com alguns exemplos simples.
Olhando para a lista de arquivos .json e .csv. A extensão do arquivo glob é precedida por uma estrela e um ponto na entrada. Uma lista de arquivos .csv é devolvida. Para arquivos .json, podemos fazer o mesmo. Podemos criar um arquivo que extrai nomes, alturas e pesos no formato CSV. o nome do arquivo do arquivo .csv é a entrada e a saída é um quadro de dados. Para formatos JSON, podemos fazer o mesmo.
Paso 1:
Abra o notebook e importe as funções e módulos necessários
import glob
import pandas as pd
import xml.etree.ElementTree as ET
from datetime import datetime
Dados usados:
Os arquivos dealership_data contêm arquivos CSV, JSON e XML para dados de carros usados que contenham recursos chamados car_model, year_of_manufacture, price, e fuel. Então vamos extrair o arquivo dos dados brutos e transformá-lo em um arquivo de destino e carregá-lo na saída.
Baixe o arquivo de origem da nuvem:
!wget https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0221EN-SkillsNetwork/labs/module 6/Lab - Extract Transform Load/data/datasource.zip
Extrair o arquivo zip:
nzip datasource.zip -d dealership_data
Defina o caminho dos arquivos de destino:
tmpfile = "dealership_temp.tmp" # store all extracted data logfile = "dealership_logfile.txt" # all event logs will be stored targetfile = "dealership_transformed_data.csv" # dados transformados são armazenados
Paso 2 (EXTRAIRO extrato é uma substância obtida pela concentração de compostos de origem vegetal, animal ou mineral. Usado em uma variedade de aplicações, como a indústria alimentícia, Farmacêutica e Cosmética. Os extratos podem ser apresentados na forma líquida, em pó ou sob a forma de tinturas, e sua produção envolve técnicas como maceração, Destilação ou extração por solvente. Seu uso permite aproveitar as propriedades benéficas dos ingredientes originais de uma maneira mais adequada..):
Extrato de função extrairá grandes quantidades de dados de várias fontes em lotes. Ao adicionar esse recurso, agora ele vai descobrir e carregar todos os nomes de arquivo CSV, e os arquivos CSV serão adicionados ao quadro de data com cada iteração do loop, com a primeira iteração anexando primeiro, seguido pela segunda iteração, resultando em uma lista de dados extraídos. Depois de coletar os dados, vamos passar para o passo “Transformar” de processo.
Observação: Se ele “índiceo "Índice" É uma ferramenta fundamental em livros e documentos, que permite localizar rapidamente as informações desejadas. Geralmente, é apresentado no início de um trabalho e organiza os conteúdos de forma hierárquica, incluindo capítulos e seções. Sua correta preparação facilita a navegação e melhora a compreensão do material, tornando-se um recurso essencial para estudantes e profissionais de várias áreas.... De ignorar” está definido como verdadeiro, a ordem de cada linha será a mesma que a ordem em que as linhas foram adicionadas ao quadro de dados.
Função de extração CSV
def extract_from_csv(file_to_process):
dataframe = pd.read_csv(file_to_process)
retornar dataframe
Função de extração JSON
def extract_from_json(file_to_process):
dataframe = pd.read_json(file_to_process,linhas = Verdadeiro)
retornar dataframe
Função de extração XML
def extract_from_xml(file_to_process):
dataframe = pd.DataFrame(colunas =['car_model','ano de produção','preço', 'combustível'])
árvore = ET.parse(file_to_process)
raiz = árvore.getroot()
para pessoa na raiz:
car_model = pessoa.encontrar("car_model").text
year_of_manufacture = int(pessoa.encontrar("year_of_manufacture").texto)
preço = flutuar(pessoa.encontrar("preço").texto)
combustível = pessoa.encontrar("combustível").text
dataframe = dataframe.append({"car_model":car_model, "year_of_manufacture":year_of_manufacture, "preço":preço, "combustível":combustível}, ignore_index=True)
retornar dataframe
Función de extracción ():
Ahora llame a la función de extracción usando su llamada de función para CSV, JSON, XML.
extrato def():
extracted_data = pd. DataFrame(colunas =['car_model','ano de produção','preço', 'combustível'])
#for csv files
for csvfile in glob.glob("dealership_data/*.csv"):
extracted_data = extracted_data.append(extract_from_csv(csvfile), ignore_index=True)
#for json files
for jsonfile in glob.glob("dealership_data/*.json"):
extracted_data = extracted_data.append(extract_from_json(jsonfile), ignore_index=True)
#for xml files
for xmlfile in glob.glob("dealership_data/*.xml"):
extracted_data = extracted_data.append(extract_from_xml(xmlfile), ignore_index=True)
voltar extracted_data
Paso 3 (Transformar):
Depois de coletar os dados, pasaremos a la fase “Transformar” de processo. Esta função irá converter a altura da coluna, que está em polegadas, a milímetros e a coluna de libra, que está em libras, para quilograma, e ele retornará os resultados nos dados variáveis. No quadro de dados de entrada, a altura da coluna está em pés. Converta a coluna em metros e arredonde para duas casas decimais.
def transformar(dados):
dados['preço'] = redondo(data.price, 2)
dados de retorno
Paso 4 (carregamento e registro):
É hora de carregar os dados no arquivo de destino, agora que os coletamos e especificamos. Salvamos o quadro de dados do pandas como um CSV neste cenário. Agora, passamos pelas etapas de extração, transformar e carregar dados de várias fontes em um único arquivo de destino. Precisamos configurar uma entrada de log antes de terminarmos nosso trabalho. Vamos conseguir isso digitando uma função de registro.
Função de carregamento:
carga def(arquivo alvo,data_to_load):
data_to_load.to_csv(arquivo alvo)
Função de registro:
Todos os dados inseridos serão adicionados às informações atuais quando o “uma”. Podemos então anexar um estamp de tempo a cada fase do processo, indicando quando começa e quando termina, gerando esse tipo de entrada. Uma vez definidos todos os códigos necessários para executar o processo ETL sobre os dados, o último passo é chamar todas as funções.
def log(mensagem):
timestamp_format="%H:%M:%S-%h-%d-%Y"
#Hour-Minute-Second-MonthName-Day-Year
now = datetime.now() # get current timestamp
timestamp = now.strftime(timestamp_format)
com aberto("dealership_logfile.txt","uma") como f: f.escrever(timestamp + ',' + mensagem + 'n')
Paso 5 (Executando o processo ETL):
Primeiro, começamos chamando a função extract_data. Os dados recebidos nesta etapa serão então transferidos para a segunda etapa de transformação dos dados. Assim que terminar, os dados são carregados no arquivo de destino. O que mais, observe que antes e depois de cada etapa, a hora e a data de início e término foram adicionadas.
O registro de que o processo ETL foi iniciado:
registro("Trabalho ETL iniciado")
O registro que iniciou e concluiu a etapa de extração:
registro("Fase de extração iniciada")
extract_data = extract()
registro("Fase de extração finalizada")
O registro que iniciou e encerrou a Etapa de Transformação:
registro (“Fase de transformação iniciada”)
data_transformed = transform (dados_extraídos)
registro("Fase de transformação finalizada")
O registro que iniciou e encerrou a fase de upload:
registro("Fase de carga iniciada")
carga(arquivo alvo,transform_data)
registro("Fase de carga encerrada")
O registro de conclusão do ciclo ETL:
registro("Trabalho ETL finalizado")
Através deste processo, discutimos algumas funções básicas de extração, transformação e carregamento
- Como escrever uma função de extração simples.
- Como escrever uma função de transformação simples.
- Como escrever uma função de carregamento simples.
- Como escrever uma função de registro simples.
“Não é grande dados, você é cego e surdo e está no meio de uma rodovia “. – Geoffrey Moore.
No máximo, discutimos todos os processos ETL. O que mais, vamos ver, “Quais são os benefícios do trabalho de engenharia de dados?”.
Sobre engenharia de dados:
Engenharia de dados é um vasto campo com muitos nomes. Você pode nem ter um diploma formal em muitas instituições. Como resultado, geralmente é melhor começar definindo os objetivos do trabalho de engenharia de dados que levam aos resultados esperados. Os usuários que confiam em engenheiros de dados são tão diversos quanto os talentos e resultados das equipes de engenharia de dados. Seus consumidores sempre definirão quais problemas você lida e como você os resolve, independentemente do setor a que se dedica.
Sobre mim:
Olá, meu nome é Lavanya e sou de Chennai. Eu sou um escritor apaixonado e criador de conteúdo entusiasmado. Os problemas mais difíceis sempre me excitam. Atualmente estou estudando meu B. Técnico em Engenharia Química e tenho grande interesse nas áreas de engenharia de dados, aprendizado de máquina, ciência de dados e inteligência artificial, e estou constantemente procurando maneiras de integrar esses campos com outras disciplinas, como ciências. e química para promover meus objetivos de pesquisa.
conclusão:
Espero que você tenha gostado do meu artigo e tenha entendido o que é Python em poucas palavras, que fornecerá algumas orientações para você começar sua jornada para aprender engenharia de dados. Esta é apenas a ponta do iceberg em termos de possibilidades.. Existem muitos tópicos mais sofisticados em engenharia de dados, por exemplo, para aprender. Porém, antes que possamos compreender tais noções, Vou expandir no próximo artigo. Obrigado!
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





