Este artigo foi publicado como parte do Data Science Blogathon.
O guia é principalmente para iniciantes, e tentarei definir e enfatizar as questões o máximo que puder.. Dado que el aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde... es un tema muy grande, dividiria todo o tutorial em algumas partes. Certifique-se de ler as outras partes se você achar esta útil..
Contente
1. Introdução
- O que é aprendizado profundo?
- Por que o aprendizado profundo?
- Quantos dados são grandes?
- Campos onde o aprendizado profundo é usado
- Diferença entre Deep Learning e Machine Learning
2) Importe as bibliotecas necessárias
3) Resumo
4) Regressão logística
- Gráfico computacional
- Inicializando parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto....
- Propagação para a frente
- Otimização com Descida de Gradiente
5) Regressão logística com Sklearn
6) Notas finais
Introdução
O que é aprendizado profundo?
- É um subcampo de aprendizado de máquina, inspirado pelos neurônios biológicos do cérebro e traduzindo-o em redes neurais artificiais com aprendizado de representação.
Por que o aprendizado profundo?
- Quando o volume de dados aumenta, técnicas de aprendizagem de máquina, não importa o quão otimizados eles são, começam a se tornar ineficientes em termos de desempenho e precisão, enquanto o aprendizado profundo funciona muito melhor nesses casos.
Quantos dados são grandes?
- Nós vamos, você não pode quantificar um limiar para que os dados sejam considerados grandes, mas, Por intuição, vamos dizer que uma amostra de um milhão poderia ser suficiente para dizer “É grande.” (este é o lugar onde Michael Scott teria falado suas famosas palavras “Foi o que ela disse.”).
Campos onde o DL é usado
- Classificação de imagem, reconhecimento de voz, PNL (processamento de linguagem natural), sistemas de recomendação, etc.
Diferença entre deep learning e machine learning
- O deep learning é um subconjunto de aprendizado de máquina.
- Em Machine Learning, funções são fornecidas manualmente.
- Enquanto o Deep Learning aprende funções diretamente a partir dos dados.
Nós vamos usar o Conjunto de dados de dígitos da linguagem de sinais que está disponível em Kaggle aqui. Agora vamos começar.
Importação de bibliotecas necessárias
importar numpy como np # linear algebra import pandas as pd # processamento de dados, I/O do arquivo CSV (por exemplo. pd.read_csv) import matplotlib.pyplot as plt # Arquivos de dados de entrada estão disponíveis no "../entrada/" diretório. # import warnings import warnings # filter warnings warnings.filterwarnings('ignorar') from subprocess import check_output print(check_output(["ls", "../entrada"]).decodificar("utf8")) # Todos os resultados que você escrever para o diretório atual são salvos como saída.

Resumo dos dados
- Existem 2062 imagens de dígito de linguagem de sinais neste conjunto de dados.
- Já que há 10 dígitos do 0 al 9, existem 10 imagens de sinal únicas.
- No princípio, só vamos usar 0 e 1 (para tornar simples para os alunos)
- Nos dados, o sinal de mão para 0 está entre os índices 204 e 408. Existem 205 amostras para 0.
- O que mais, o sinal de mão para 1 está entre os índices 822 e 1027. Existem 206 amostras.
- Portanto, usaremos 205 amostras de cada classe (Observação: na realidade, 205 amostras são muito menos para um modelo adequado de Deep Learning, mas como é um tutorial, podemos ignorá-lo),
Agora vamos preparar nossas matrizes X e Y, onde X é nossa matriz de imagens (caracteristicas) e Y é nossa matriz de rótulos (0 e 1).
# load data set
x_l = np.load('.. /input/--language-digits-dataset/X.npy')
Y_l = np.load('.. /input/Sign-language-digits-dataset/Y.npy')
img_size = 64
plt.subplot(1, 2, 1)
plt.imshow(x_l[260].remodelar(img_size, img_size))
plt.axis('desligado')
plt.subplot(1, 2, 2)
plt.imshow(x_l[900].remodelar(img_size, img_size))
plt.axis('desligado')
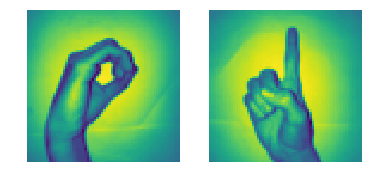
# Junte-se a uma sequência de matrizes ao longo de uma linha de eixo.
# a partir de 0 para 204 é zero sinal e de 205 para 410 is one sign
X = np.concatenate((x_l[204:409], x_l[822:1027] ), eixo = 0)
z = np.zeros(205)
o = np.ones(205)
Y = np.concatenato((Com, o), eixo = 0).remodelar(Forma X[0],1)
imprimir("Forma X: " , Forma X)
imprimir("E forma: " , Y.shape)

Para criar nossa matriz X, primeiro dividimos e concatenamos nossos segmentos de imagem de sinal de mão de 0 e 1 do conjunto de dados para a matriz X. A seguir, fazemos algo semelhante com Y, mas usamos os rótulos em vez.
1) Então vemos que a forma de nossa matriz X é (410, 64, 64)
- o 410 Isso significa 205 Imagens de 0, 205 Imagens de 1.
- a 64 significa que o tamanho de nossas imagens é 64 x 64 píxeis.
2) A forma Y é (410,1), portanto, 410 uns e zeros.
3) Agora dividimos X e Y em trens e jogos de teste.
- trem = 75%, trem = 15%
- random_state = Usa uma determinada semente ao randomizar, portanto, se a célula é executada várias vezes, o número aleatório gerado não muda toda vez. O mesmo teste e distribuição de trens é criado sempre que.
# Então vamos criar x_train, y_train, x_test, y_test arrays
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, E, test_size=0,15, random_state=42)
number_of_train = X_train.shape[0]
number_of_test = X_test.shape[0]
Temos uma matriz de entrada tridimensional, então temos que achatá-lo para 2D para alimentar nosso primeiro modelo de aprendizagem profunda. Como e já é 2D, deixamos como é.
X_train_flatten = X_train.remodele(number_of_train,X_train.shape[1]*X_train.shape[2])
X_test_flatten = .remodelar X_test(number_of_test,X_test.shape[1]*X_test.shape[2])
imprimir("X trem achatado",X_train_flatten.forma)
imprimir("X teste de achatado",X_test_flatten.forma)

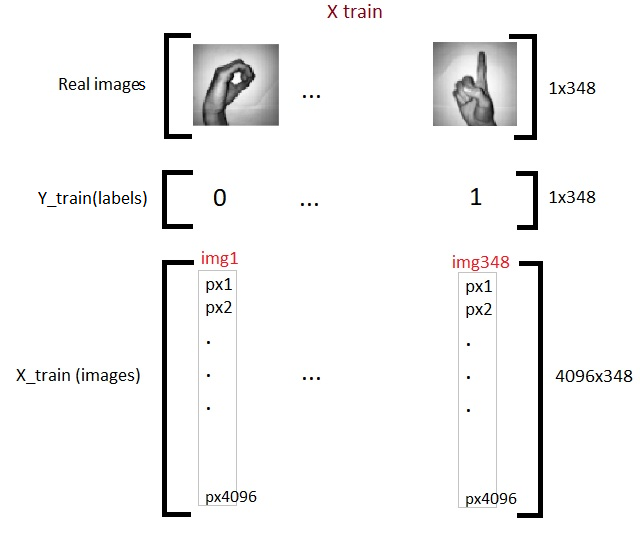
Agora temos um total de 348 imagens, cada um com 4096 píxeles en la matriz de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... X. E 62 imagens da mesma densidade de pixels 4096 na matriz de teste. Agora nós transpomos as matrizes. Esta é apenas uma escolha pessoal e você vai ver nos próximos códigos por que eu digo isso.
x_train = X_train_flatten.T
x_test = X_test_flatten.T
y_train = Y_train.T
y_test = Y_test.T
print("x_train: ",x_train.forma)
imprimir("x_test: ",x_test.forma)
imprimir("y_train: ",y_train.shape)
imprimir("y_test: ",y_test.shape)

Então agora terminamos com a preparação de nossos dados necessários.. Aqui está o que parece:
Agora vamos nos familiarizar com um dos modelos básicos de DL, chamada Regressão Logística.
Regressão logística
Quando se fala em classificação binária, o primeiro modelo que vem à mente é a regressão logística. Mas pode-se perguntar qual é o uso da regressão logística no aprendizado profundo?? A resposta é simples, ya que la regresión logística es una neuronal vermelhoAs redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano. Eles usam estruturas conhecidas como neurônios artificiais para processar e aprender com os dados. Essas redes são fundamentais no campo da inteligência artificial, permitindo avanços significativos em tarefas como reconhecimento de imagem, Processamento de linguagem natural e previsão de séries temporais, entre outros. Sua capacidade de aprender padrões complexos os torna ferramentas poderosas.. simples. Os termos rede neural e aprendizado profundo andam lado a lado. Para entender a regressão logística, primeiro temos que aprender sobre computação gráfica.
Gráfico de cálculo
Computação gráfica pode ser considerada uma forma pictórica de representar expressões matemáticas. Vamos entender isso com um exemplo.. Suponha que temos uma simples expressão matemática, como:
c = ( uma2 + b2 ) 1/2
Seu gráfico de computador será:
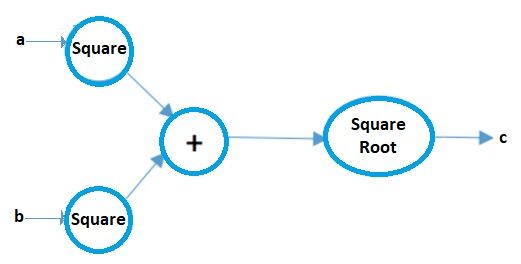
Fonte da imagem: Autor
Agora vamos olhar para um gráfico computacional de regressão logística:
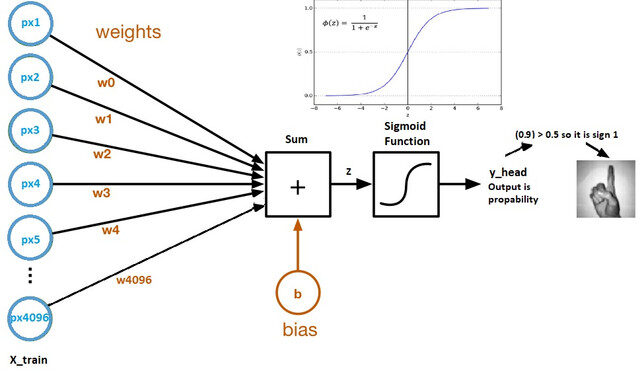
Fonte da imagem: Conjunto de dados Kaggle
- Pesos e viés são chamados parâmetros de modelo.
- Pesos representam os coeficientes de cada pixel.
- Viés é a intersecção da curva formada ao traçar parâmetros contra rótulos.
- Z = (px1 * wx1) + (px2 * wx2) +…. + (px4096 * wx4096)
- y_head = sigmoid_funtion (COM)
- O que a função sigmoid faz é essencialmente escalar o valor de Z entre 0 e 1, por isso se torna uma probabilidade.
Por que usar a função sigmoid?
- Isso nos dá um resultado probabilístico.
- Uma vez que é uma derivada, podemos usarlo en el algoritmo de descenso de gradienteGradiente é um termo usado em vários campos, como matemática e ciência da computação, descrever uma variação contínua de valores. Na matemática, refere-se à taxa de variação de uma função, enquanto em design gráfico, Aplica-se à transição de cores. Esse conceito é essencial para entender fenômenos como otimização em algoritmos e representação visual de dados, permitindo uma melhor interpretação e análise em....
Examinaremos em detalhes cada um dos componentes do gráfico do computador acima..
Parâmetros de inicialização
Fonte da imagem: Documentos da Microsoft
Cada pixel tem seu próprio peso. Mas a questão é qual serão seus pesos iniciais?? Há várias técnicas para fazer isso que eu vou cobrir na parte 2 a partir deste artigo, Mas para agora, podemos inicialmente inizá-los usando qualquer valor aleatório, Digamos 0.01.
A forma da matriz de peso será (4096, 1), uma vez que há um total de 4096 pixels por imagem, e deixar o viés inicial ser 0.
# permite inicializar parâmetros
# Então o que precisamos é de dimensão 4096 que é o número de pixels como parâmetro para o nosso método inicialização(def)
def initialize_weights_and_bias(dimensão):
w = np.full((dimensão,1),0.01)
b = 0.0
retorno w, b
C,b = initialize_weights_and_bias(4096)
Propagação para a frente
Todos os passos dos pixels ao custo são chamados de propagação para a frente.
Para calcular Z usamos a fórmula: Z = (Wt) x + b. onde x é a matriz de pixels, w pesos e b é o viés. Após o cálculo de Z, introduzimos na função sigmoid que retorna y_head (probabilidade). Depois disso, calculamos la Função de perdaA função de perda é uma ferramenta fundamental no aprendizado de máquina que quantifica a discrepância entre as previsões do modelo e os valores reais. Seu objetivo é orientar o processo de treinamento, minimizando essa diferença, permitindo assim que o modelo aprenda de forma mais eficaz. Existem diferentes tipos de funções de perda, como erro quadrático médio e entropia cruzada, cada um adequado para diferentes tarefas e... (erro).
A função de custo é a soma de todas as perdas e penaliza o modelo por previsões incorretas.. É assim que nosso modelo aprende os parâmetros.
# calculation of z #z = np.dot(w.T.,x_train)+b def sigmoid(Com): y_head = 1/(1+np.exp(-Com)) y_head de retorno
y_head = sigmoid(0) y_head > 0.5
A expressão matemática da função de perda (registro) isto é:
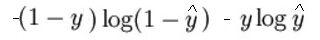
Como disse anteriormente, o que a função de perda essencialmente faz é penalizar previsões incorretas. aqui é o código para a propagação para a frente:
# Etapas de propagação para a frente:
# encontrar z = w.T*x+b
# y_head = sigmoid(Com)
# perda(erro) = perda(e,y_head)
# custo = soma(perda)
def forward_propagation(C,b,x_train,y_train):
z = np.dot(w.T.,x_train) + b
y_head = sigmoid(Com) # probabilístico 0-1
perda = -y_train*np.log(y_head)-(1-y_train)*np.log(1-y_head)
custo = (np.sum(perda))/x_train.forma[1] # x_train.forma[1] is for scaling
return cost
Otimização com Descida de Gradiente
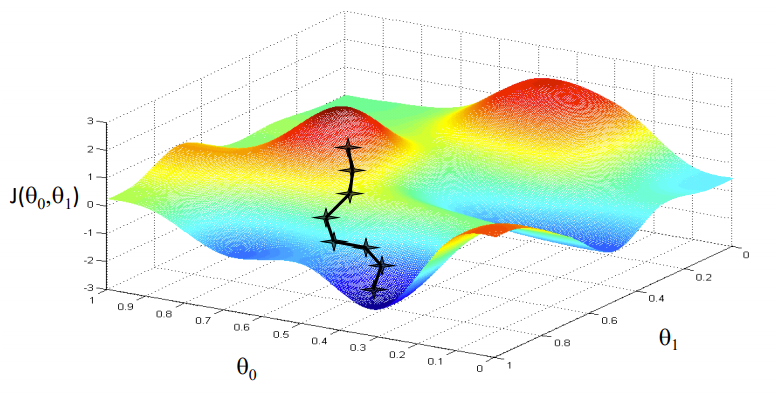
Fonte da imagem: Coursera
Nosso objetivo é encontrar os valores de nossos parâmetros para os quais, a função de perda é o mínimo. A equação para descida gradiente é:
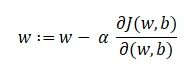
Onde w é o peso ou parâmetro. A letra grega alfa é algo chamado tamanho escalonado. O que significa é o tamanho das iterações que tomaremos quando descermos a encosta para encontrar os mínimos locais.. E o resto é a derivada da função de perda, também conhecido como gradiente. O algoritmo para descida gradiente é simples:
- Primeiro, pegamos um ponto de dados aleatório em nosso gráfico e encontramos sua inclinação.
- Então encontramos a direção em que a função de perda de valor diminui.
- Atualize os pesos usando a fórmula acima. (Este método também é chamado de backpropagation)
- Selecione o próximo ponto tomando um tamanho α.
- Repetir.
# Na propagação retrógrada usaremos y_head que foram encontradas na progation dianteira # Portanto, em vez de escrever método de propagação para trás, lets combine forward propagation and backward propagation def forward_backward_propagation(C,b,x_train,y_train): # forward propagation z = np.dot(w.T.,x_train) + b y_head = sigmoid(Com) perda = -y_train*np.log(y_head)-(1-y_train)*np.log(1-y_head) custo = (np.sum(perda))/x_train.forma[1] # x_train.forma[1] é para escalar # backward propagation derivative_weight = (np.dot(x_train,((y_head-y_train).T)))/x_train.forma[1] # x_train.forma[1] is for scaling derivative_bias = np.sum(y_head-y_train)/x_train.forma[1] # x_train.forma[1] is for scaling gradients = {"derivative_weight": derivative_weight,"derivative_bias": derivative_bias} custo de retorno,gradientes
Ahora actualizamos los parametros de aprendizaje:
# Atualização(aprendizagem) parameters def update(C, b, x_train, y_train, taxa de Aprendizagem,number_of_iterarion): cost_list = [] cost_list2 = [] índice = [] # atualização(aprendizagem) parameters is number_of_iterarion times for i in range(number_of_iterarion): # make forward and backward propagation and find cost and gradients cost,gradientes = forward_backward_propagation(C,b,x_train,y_train) cost_list.append(custar) # lets update w = w - taxa de Aprendizagem * gradientes["derivative_weight"] b = b - taxa de Aprendizagem * gradientes["derivative_bias"] se eu % 10 == 0: cost_list2.append(custar) index.append(eu) imprimir ("Custo após iteração %i: %f" %(eu, custar)) # atualizamos(aprender) parameters weights and bias parameters = {"peso": C,"viés": b} plt.plot(índice,cost_list2) plt.xticks(índice,rotação='vertical') plt.xlabel("Número de Iterarion") plt.ylabel("Custo") plt.show() parâmetros de retorno, gradientes, cost_list
parametros, gradientes, cost_list = atualização(C, b, x_train, y_train, learning_rate = 0,009 number_of_iterarion = 200)
Até aqui, aprendimos nuestros parametros. Significa que estamos ajustando los datos. En el paso de predicción, tenemos x_test como entrada y usándolo, hacemos predicciones hacia adelante.
# prediction def predict(C,b,x_test): # x_test is a input for forward propagation z = sigmoid(np.dot(w.T.,x_test)+b) Y_prediction = np.zeros((1,x_test.forma[1])) # se z é maior do que 0.5, nossa previsão é assinar um (y_head=1), # se z é menor do que 0.5, nossa previsão é sinal zero (y_head=0), para eu no alcance(z.shape[1]): se z[0,eu]<= 0.5: Y_prediction[0,eu] = 0 outro: Y_prediction[0,eu] = 1 Y_prediction de retorno
prever(parametros["peso"],parametros["viés"],x_test)
Ahora hacemos nuestras predicciones. Pongámoslo todo junto:
def logistic_regression(x_train, y_train, x_test, y_test, taxa de Aprendizagem , num_iterations):
# initialize
dimension = x_train.shape[0] # isso é 4096
C,b = initialize_weights_and_bias(dimensão)
# do not change learning rate
parameters, gradientes, cost_list = atualização(C, b, x_train, y_train, taxa de Aprendizagem,num_iterations)
y_prediction_test = prever(parametros["peso"],parametros["viés"],x_test)
y_prediction_train = prever(parametros["peso"],parametros["viés"],x_train)
# Print train/test Errors
print("precisão do trem: {} %".formato(100 - np.mean(np.abs(y_prediction_train - y_train)) * 100))
imprimir("precisão de teste: {} %".formato(100 - np.mean(np.abs(y_prediction_test - y_test)) * 100))
logistic_regression(x_train, y_train, x_test, y_test,learning_rate = 0.01, num_iterations = 150)
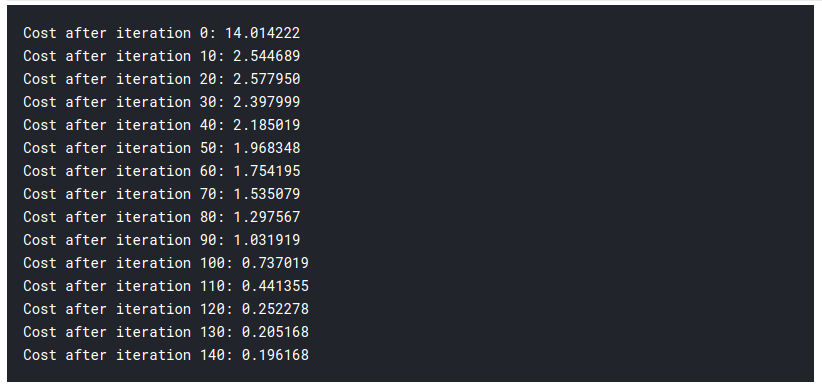
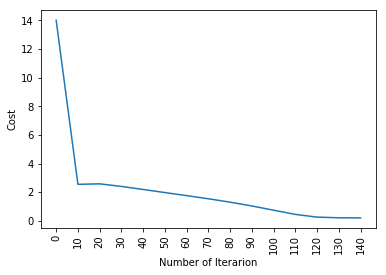

Então, como você pode ver, mesmo o modelo de aprendizagem profunda mais fundamental é bastante difícil. Não é fácil para você aprender., e iniciantes às vezes podem se sentir sobrecarregados estudando tudo isso de uma vez.. Mas a coisa é, nós não tocamos em aprendizado profundo ainda., isso é como a superfície. Há muito mais eu vou adicionar na parte 2 a partir deste artigo.
Desde que aprendemos a lógica por trás da regressão logística, podemos usar uma biblioteca chamada SKlearn que já tem muitos dos modelos e algoritmos embutidos, para que você não tem que começar tudo do zero.
Regressão logística com Sklearn

Não vou explicar muito nesta seção, já que você conhece quase toda a lógica e intuição por trás da regressão logística.. Se você estiver interessado em ler sobre a biblioteca Sklearn, você pode ler a documentação oficial aqui. Aqui está o código, e eu tenho certeza que você vai ficar atordoado para ver o pouco esforço que é preciso:
from sklearn import linear_model
logreg = linear_model.LogisticRegression(random_state = 42.max_iter= 150)
imprimir("precisão de teste: {} ".formato(logreg.fit(x_train. T, y_train. T).pontuação(x_test. T, y_test. T)))
imprimir("precisão do trem: {} ".formato(logreg.fit(x_train. T, y_train. T).pontuação(x_train. T, y_train. T)))

sim! isso é tudo o que levou, só 1 linha de código!
Notas finais
Aprendemos muito hoje.. Mas isso é só o começo.. Certifique-se de verificar a parte 2 a partir deste artigo. Você pode encontrá-lo no link a seguir. Se você gosta do que lê, você pode ler alguns dos outros artigos interessantes que eu escrevi.
Sion | Autor na DataPeaker
Espero que tenha se divertido lendo meu artigo.. Saúde!!
A mídia mostrada neste artigo sobre as principais bibliotecas de aprendizado de máquina em Julia não é propriedade da DataPeaker e é usada a critério do autor.





