Reflexos
- A tokenização é um aspecto fundamental (e obrigatório) trabalhar com dados de texto
- Discutiremos as várias nuances da tokenização, incluindo como lidar com palavras fora do vocabulário (OOV)
Introdução
a linguagem é uma coisa linda. Mas dominar um novo idioma do zero é uma perspectiva bastante assustadora.. Se você já aprendeu uma língua que não é sua língua materna, vai se identificar com isso! Há tantas camadas para remover e sintaxe para considerar, é um grande desafio.
E é exatamente assim com nossas máquinas.. Para o nosso computador entender qualquer texto, precisamos decompor essa palavra de uma forma que nossa máquina possa entender. É aí que entra o conceito de tokenização no processamento de linguagem natural. (PNL).
Em poucas palavras, não podemos trabalhar com dados de texto se não realizarmos a tokenização. sim, é realmente tão importante!

E aqui está a coisa intrigante sobre tokenização: não é só sobre quebrar o texto. A tokenização desempenha um papel importante no tratamento de dados de texto. Então, neste artigo, vamos explorar as profundezas da tokenização no processamento de linguagem natural e como você pode implementá-lo em Python.
Eu recomendo dedicar algum tempo para revisar o seguinte recurso se você for novo na PNL:
Tabela de conteúdo
- Uma visão geral rápida da tokenização
- As verdadeiras razões por trás da tokenização
- que tokenização (palavra, caractere ou subpalavra) devemos usar?
- Implementação de tokenização: codificação de pares de bytes em python
Uma visão geral rápida da tokenização
A tokenização é uma tarefa comum no processamento de linguagem natural (PNL). É um passo fundamental em métodos tradicionais de PNL, como Count Vectorizer e arquiteturas baseadas em Advanced Deep Learning, como Transformers..
Tokens são os blocos de construção da linguagem natural.
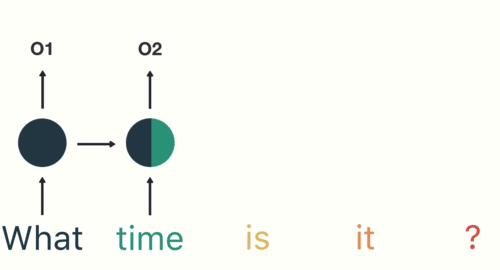
A tokenização é uma maneira de separar um pedaço de texto em unidades menores chamadas tokens.. Aqui, fichas podem ser palavras, caracteres o subpalabras. Portanto, A tokenização pode ser amplamente classificada em 3 tipos: tokenização de palavras, caractere e subpalavra (caracteres n-gram).
Por exemplo, considere a frase: “Nunca desista”.
A maneira mais comum de formar tokens é baseada no espaço. Assumindo que o espaço é um delimitador, tokenizar a frase resulta em 3 tokens: Nunca desista. Como cada token é uma palavra, torna-se um exemplo de tokenização de palavras.
de forma similar, tokens podem ser caracteres ou subpalavras. Por exemplo, vamos considerar “mais inteligente”:
- fichas de personagem: mais inteligente
- Tokens de subpalavra: mais inteligente
Mas então isso é necessário?? Nós realmente precisamos de tokenização para fazer tudo isso??
Observação: Se você é novo na PNL, verifique nosso curso online de PNL
As verdadeiras razões por trás da tokenização
Como os tokens são os blocos de construção da Linguagem Natural, a maneira mais comum de processar o texto simples ocorre no nível do token.
Por exemplo, Modelos baseados em transformador, las arquitecturas de aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde... de vanguardia (SOTA) e PNL, processar o texto bruto no nível do token. de forma similar, arquiteturas de aprendizado profundo mais populares para PNL, como RNN, GRU e LSTM também processam o texto bruto no nível do token.
Funcionamiento de la recorrente neuronal vermelhaRedes neurais recorrentes (RNN) são um tipo de arquitetura de rede neural projetada para processar fluxos de dados. Ao contrário das redes neurais tradicionais, As RNNs usam conexões internas que permitem que as informações de entradas anteriores sejam lembradas. Isso os torna especialmente úteis em tarefas como processamento de linguagem natural, Tradução automática e análise de séries temporais, onde o contexto e a sequência são centrais para o...
Como mostrado aqui, A RNN recebe e processa cada token em uma etapa de tempo específica.
Portanto, tokenização é a etapa mais importante ao modelar dados de texto. A tokenização é feita no corpus para obter tokens. Os seguintes cartões são então usados para preparar um vocabulário. O vocabulário refere-se ao conjunto de tokens únicos no corpus. Lembre-se que o vocabulário pode ser construído considerando cada token único no corpus ou considerando as K palavras mais frequentes.
A construção de vocabulário é o objetivo final da tokenização.
Um dos truques mais simples para melhorar o desempenho do modelo de PNL é criar um vocabulário a partir das K palavras mais frequentes..
Agora, vamos entender o uso do vocabulário em métodos tradicionais e avançados de PNL baseados em aprendizado profundo.
- Abordagens tradicionais de PNL, como Count Vectorizer e TF-IDF, usar vocabulário como recursos. Cada palavra do vocabulário é tratada como um recurso exclusivo:
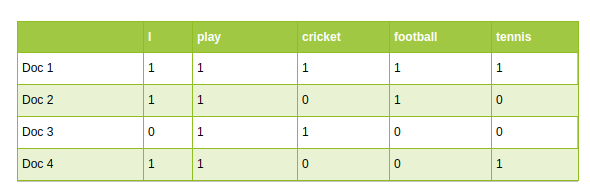
PNL tradicional: Vetorizador de contagem
- Em arquiteturas de PNL baseadas em aprendizado profundo avançado, o vocabulário é usado para criar as frases de entrada tokenizadas. Finalmente, os tokens dessas sentenças são passados como entradas para o modelo.
Que tokenização devo usar?
Como mencionado anteriormente, a tokenização pode ser feita no nível da palavra, caractere ou subpalavra. É uma pergunta comum: qual tokenização devemos usar ao resolver uma tarefa de PNL? Vamos resolver essa questão aqui.
Tokenização de palavras
A tokenização de palavras é o algoritmo de tokenização mais usado. Dividir um pedaço de texto em palavras individuais com base em um determinado delimitador. Dependendo dos delimitadores, diferentes tokens de nível de palavra são formados. Incorporações de palavras pré-treinadas, como Word2Vec e GloVe, estão incluídas na tokenização de palavras.
Mas isso tem algumas desvantagens.
Desvantagens da tokenização de palavras
Um dos principais problemas com tokens de palavras é lidar com palavras sem vocabulário (OOV). As palavras OOV referem-se às novas palavras encontradas nos testes. Essas novas palavras não existem no vocabulário. Portanto, esses métodos falham em lidar com palavras OOV.
Mas espera, Não tire conclusões precipitadas ainda!!
- Um pequeno truque pode resgatar tokenizers de palavras de palavras OOV. El truco consiste en formar el vocabulario con las K palabras frecuentes más frecuentes y reemplazar las palabras raras en los datos de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... com desconhecido tokens (UNK). Isso ajuda o modelo a aprender a representação de palavras OOV em termos de tokens UNK.
- Portanto, durante o tempo de prova, qualquer palavra não presente no vocabulário será mapeada para um token UNK. É assim que podemos resolver o problema OOV em tokenizers de palavras.
- O problema com essa abordagem é que todas as informações de palavras são perdidas quando estamos mapeando OOV para tokens UNK. A estrutura da palavra pode ser útil para representá-la com precisão. E outro problema é que cada palavra OOV tem a mesma representação

Outro problema com os tokens de palavras está relacionado ao tamanho do vocabulário. Geralmente, modelos pré-treinados são treinados em um grande volume do corpus de texto. Então, imagine construir o vocabulário com todas as palavras únicas em um corpus tão grande. Isso explode o vocabulário!
Isso abre a porta para a tokenização de personagens.
tokenização de caracteres
A tokenização de caracteres divide cada texto em um conjunto de caracteres. Supera as desvantagens que vimos anteriormente sobre a tokenização de palavras.
- Os tokenizadores de caracteres lidam com palavras OOV de forma consistente, preservando as informações das palavras. Divide a palavra OOV em caracteres e renderiza a palavra em termos desses caracteres.
- Também limita o tamanho do vocabulário. Você quer adivinhar o tamanho do vocabulário? 26 uma vez que o vocabulário contém um conjunto único de caracteres
Desvantagens da tokenização de caracteres
Os tokens de personagem resolvem o problema OOV, pero la longitud de las oraciones de entrada y salida aumenta rápidamente a mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... que representamos una oración como una secuencia de caracteres. Como resultado, torna-se um desafio aprender a relação entre os personagens para formar palavras significativas.
Isso nos leva a outra tokenização conhecida como tokenização de subpalavra, que se situa entre uma tokenização de palavras e caracteres.
Tokenização de subpalavras
A tokenização de subpalavras divide o fragmento de texto em subpalavras (o caracteres n-gramo). Por exemplo, palavras como inferior podem ser segmentadas como inferiores, mais inteligente quanto mais inteligente, etc.
Modelos baseados em transformações, o SOTA em PNL, contar com algoritmos de tokenização de subpalavras para preparar o vocabulário. Agora, Vou discutir um dos algoritmos de tokenização de subpalavras mais populares conhecido como Byte Pair Encoding (BPE).
Bienvenido uma Codificação de Par de Byte (BPE)
A codificação de pares de bytes (BPE) é um método de tokenização amplamente utilizado entre os modelos baseados em transformadores. BPE aborda problemas de caractere e tokenizador de palavras:
- BPE aborda OOV de forma eficaz. Segmente OOV como subpalavras e represente a palavra em termos dessas subpalavras.
- O comprimento das frases de entrada e saída após o BPE é menor em comparação com a tokenização de caracteres
BPE es un algoritmo de O desempenho é exibido como gráficos de dispersão e caixaA segmentação é uma técnica de marketing chave que envolve a divisão de um mercado amplo em grupos menores e mais homogêneos. Essa prática permite que as empresas adaptem suas estratégias e mensagens às características específicas de cada segmento, melhorando assim a eficácia de suas campanhas. A segmentação pode ser baseada em critérios demográficos, psicográfico, geográfico ou comportamental, facilitando uma comunicação mais relevante e personalizada com o público-alvo.... de palabras que fusiona los caracteres o secuencias de caracteres que ocurren con más frecuencia de forma iterativa. Aqui está um guia passo a passo para aprender BPE.
Passos para aprender BPE
- Divida as palavras do corpus em caracteres depois de adicionar
- Inicialize o vocabulário com caracteres únicos no corpus.
- Calcular a frequência de um par de caracteres ou sequências de caracteres no corpus
- Mesclar o par mais frequente no corpus
- Salve o melhor casal do vocabulário
- Repita as etapas 3 uma 5 para um certo número de iterações
Vamos entender os passos com um exemplo.
Considere um corpus: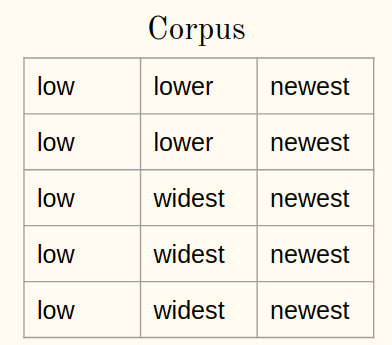
1uma) Adicione o símbolo de finalização da palavra (diga ) a cada palavra do corpus:
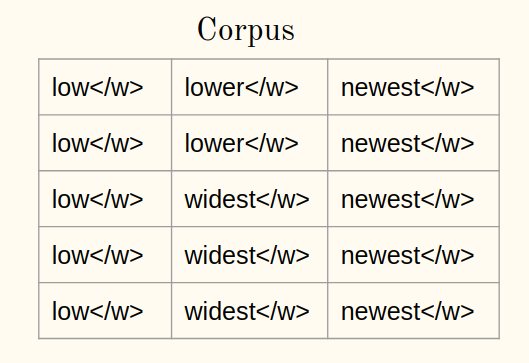
1b) Tokenize as palavras de um corpus em caracteres:
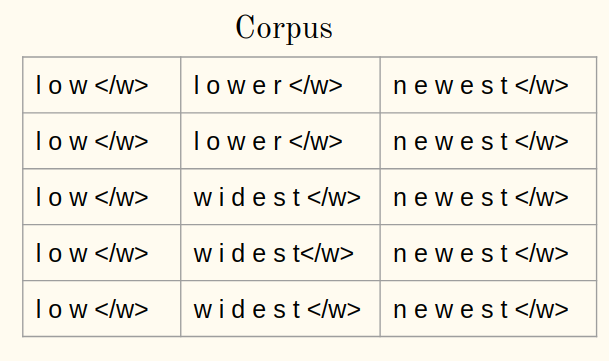
2. Inicialize o vocabulário:

Iteração 1:
3. Calcule a frequência:

4. Mesclar o par mais frequente:
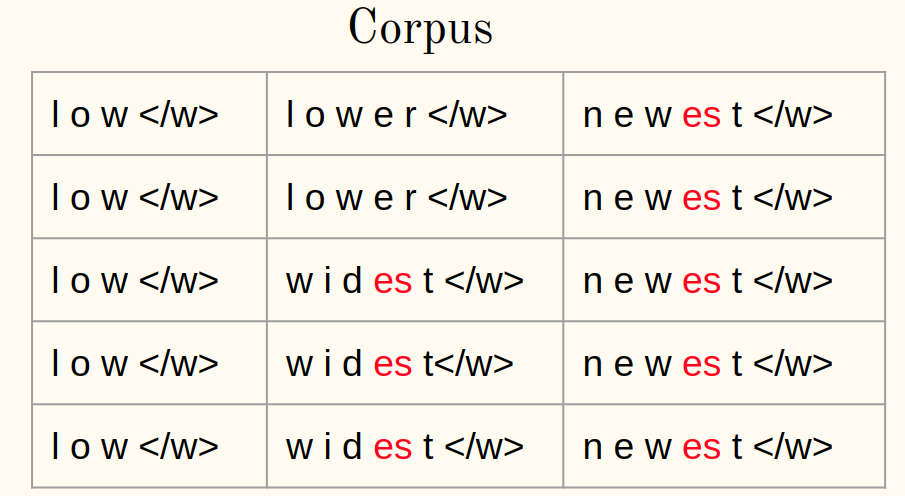
5. Salve o melhor par:

Repita as etapas 3-5 para cada iteração a partir de agora. Deixe-me ilustrar mais uma iteração.
Iteração 2:
3. Calcule a frequência:

4. Mesclar o par mais frequente:
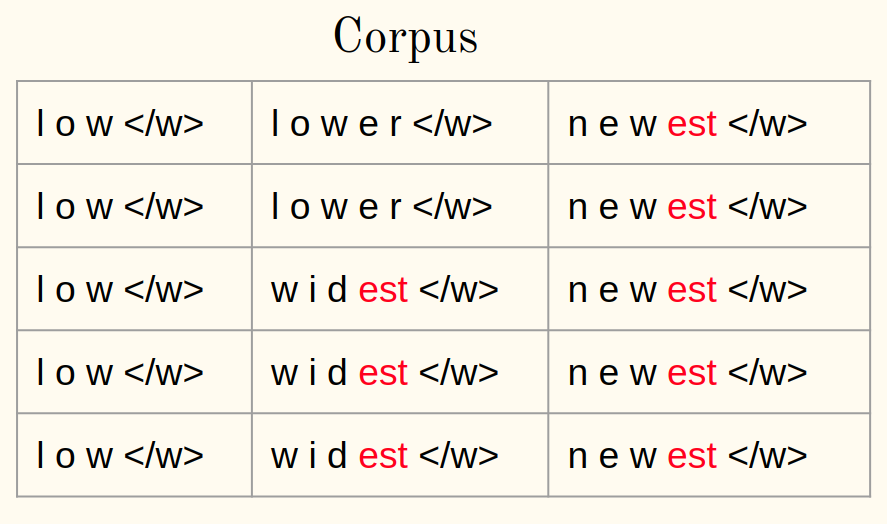
5. Salve o melhor par:

Depois de 10 iterações, As operações de mesclagem do BPE são assim:

Bem direto, verdade?
Aplicar BPE a palabras OOV
Mas, como podemos representar a palavra OOV no tempo de teste usando as operações aprendidas do BPE? Alguma ideia? Vamos responder a esta pergunta agora.
Na hora do teste, a palavra OOV é dividida em sequências de caracteres. Mais tarde, operações aprendidas são aplicadas para mesclar os caracteres em símbolos conhecidos maiores.
– Tradução automática neural de palavras raras com unidades de subpalavras, 2016
A seguir, um procedimento passo a passo para representar palavras OOV é mostrado:
- Divida a palavra OOV em caracteres depois de adicionar
- Calcular um par de caracteres ou sequências de caracteres em uma palavra
- Selecione os pares presentes nas operações aprendidas
- Mesclar o par mais frequente
- Repita as etapas 2 e 3 até que seja possível unir
Vamos ver tudo isso em ação abaixo!!
Implementação de tokenização: codificação de pares de bytes em python
Agora estamos cientes de como o BPE funciona: aprender e aplicar palavras OOV. Então, é hora de implementar nosso conhecimento em Python.
O código Python para BPE já está disponível no documento original (Tradução automática neural de palavras raras com unidades de subpalavras, 2016)
lendo corpus
Consideraremos um corpus simples para ilustrar a ideia de BPE. Porém, a mesma ideia também se aplica a outro corpus:
Elaboração de textos
Tokenize palavras em caracteres no corpus e anexe ao final de cada palavra:
aprendendo BPE
Calcule a frequência de cada palavra no corpus:
Produção:
![]()
Vamos definir uma função para calcular a frequência de um par de caracteres ou sequências de caracteres. Aceita o corpus e retorna o par com sua frequência:
Agora, a próxima tarefa é mesclar o par mais frequente do corpus. Vamos definir uma função que aceita o corpus, melhor par e retorna o corpus modificado:
A seguir, tempo para aprender as operações BPE. Como o BPE é um procedimento iterativo, executar e entender as etapas para uma iteração. Vamos calcular a frequência dos bigramas:
Produção:
Encontre o par mais frequente:
Produção: ('e', 'S')
Finalmente, combine o melhor par e salve-o no vocabulário:
Produção:![]()
Seguiremos etapas semelhantes para determinadas iterações:
Produção:![]()
A parte mais interessante ainda está por vir! Isso é aplicar BPE a palavras OOV.
Aplique BPE à palavra OOV
Agora, veremos como segmentar a palavra OOV em subpalavras usando operações aprendidas. Considere a palavra OOV como “baixar”:
Aplicar BPE a uma palavra OOV também é um processo iterativo. Implementaremos as etapas discutidas anteriormente no artigo:
Produção:
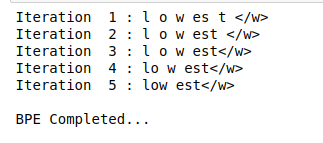
Como você pode ver aqui, a palavra desconhecida “baixar” é segmentado como inferior.
Notas finais
A tokenização é uma maneira poderosa de lidar com dados de texto. Demos uma olhada nisso neste artigo e também implementamos tokenização usando Python.
Vá em frente e tente isso em qualquer conjunto de dados baseado em texto que você tenha. quanto mais você pratica, melhor será sua compreensão de como funciona a tokenização (e por que é um conceito tão crítico de PNL). Sinta-se à vontade para entrar em contato comigo nos comentários abaixo se tiver alguma dúvida ou ideia sobre este item..





