Esta postagem foi lançada como parte do Data Science Blogathon
Introdução
Em Estatística Aplicada e Aprendizado de Máquina, Visualização de dados é uma das habilidades mais importantes.
A visualização de dados fornece um conjunto importante de ferramentas para identificar a compreensão qualitativa. Isso pode ser útil ao tentar explorar o conjunto de dados e extrair insights para aprender sobre um conjunto de dados e pode ajudar com identificação de padrão, dados corrompidos, Valores atípicos, e muito mais.
Se tivermos algum conhecimento de domínio, as visualizações de dados podem ser usadas para expressar e identificar relacionamentos-chave em tabelas e gráficos que são mais úteis para você e seus stakeholders do que medidas de associação ou relevância.
Neste post, Discutiremos alguns dos gráficos básicos o parcelas que você pode usar para entender e visualizar melhor seus dados.
Tabela de conteúdo
1. O que é visualização de dados?
2. Benefícios de uma boa visualização de dados
3. Diferentes tipos de análise para visualização de dados
4. Técnicas de análise univariada para visualização de dados
- Parcela de distribuição
- Plotagem de caixa e bigode
- Moldura de violino
5. Técnicas de análise bivariada para visualização de dados
- Gráfico de linha
- Gráfico de barras
- Gráfico de dispersão
O que é visualização de dados?
A visualização de dados é definida como representação gráfica que contém o em formação e ele dados.
Usando itens visuais como gráficos, gráficos, e mapas, técnicas de visualização de dados fornecem uma maneira viável de ver e entender as tendências, outliers e padrões nos dados.
Atualmente, temos muitos dados em nossas mãos, Em outras palavras, no mundo de Big Data, ferramentas e tecnologias de visualização de dados são cruciais para analisar grandes quantidades de informações e tomar decisões baseadas em dados.
É usado em muitas áreas, como:
- Modelar eventos complexos.
- Visualize fenômenos que não podem ser observados diretamente, O que Padrões climáticos, condições médicas, o relações matemáticas.
Benefícios de uma boa visualização de dados
Já que nossos olhos podem capturar as cores e padrões, por isso, podemos identificar rapidamente a parte vermelha do azul, o quadrado do círculo, nossa cultura é visual, isso inclui tudo, da arte e propagandas à televisão e filmes.
Então, a visualização de dados é outra técnica de arte visual que capta nosso interesse e mantém nosso foco principal na mensagem capturada com a ajuda dos olhos.
Sempre que visualizamos um gráfico, identificamos rapidamente tendências e discrepâncias presentes no conjunto de dados.
Os usos básicos da técnica de visualização de dados são os seguintes:
- É uma técnica poderosa para explorar dados com apresentável e interpretável resultados.
- No procedimento de mineração de dados, atua como uma etapa principal na parte de pré-processamento.
- É compatível com procedimento de limpeza de dados encontrar dados incorretos e valores corrompidos ou ausentes.
- Além disso ajuda construir e escolher variáveis, o que significa que temos que determinar qual variável incluir e descartar na análise.
- No procedimento de declínio de dados, também desempenha um papel crucial na combinação das categorias.

Fonte da imagem: Imagens do google
Diferentes tipos de análise para visualização de dados
Principalmente, existem três tipos diferentes de análise para visualização de dados:
Análise univariada: Na análise univariada, usaremos um único recurso para analisar quase todas as suas propriedades.
Análise bivariada: Quando comparamos os dados entre exatamente 2 caracteristicas, é conhecido como análise bivariada.
Analisis multivariável: Na análise multivariada, Vai estar comparando mais de 2 variáveis.
NOTA:
Neste post, Nosso principal objetivo é entender os seguintes conceitos:
- Como encontrar algumas inferências de técnicas de visualização de dados?
- em que condição, qual técnica é mais útil do que outras?
Não vamos nos aprofundar na parte de codificação / implementação de diferentes técnicas em um determinado conjunto de dados, mas tentamos encontrar a solução para as perguntas acima e entender apenas o código no trecho com a ajuda de diagramas de amostra para cada uma das técnicas de visualização de dados. .
Agora, vamos começar com as diferentes técnicas de visualização de dados:
Técnicas de análise univariada para visualização de dados
1. Parcela de distribuição
- É um dos melhores gráficos univariados para conhecer a distribuição dos dados.
- Quando queremos analisar o impacto na variável alvo (Saída) em relação a uma variável independente (entrada), usamos muito gráficos de distribuição.
- Este gráfico nos dá uma combinação de funções de densidade de probabilidade (pdf) e histograma em um único gráfico.
Implementação:
- O gráfico de distribuição está presente no Seaborn pacote.
O trecho de código é o seguinte:
sns.FacetGrid(hb,matiz ="SurvStat",tamanho=5).mapa(sns.distplot,'era').add_legend()
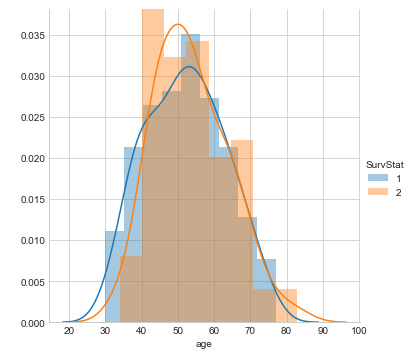
Algumas conclusões tiradas do diagrama de distribuição acima:
A partir do gráfico de distribuição acima, podemos concluir as seguintes observações:
- Vimos que criamos um gráfico de distribuição na característica 'Idade’(variável de entrada) e usamos cores diferentes para o Estado de sobrevivência(variável de saída) uma vez que é a classe para prever.
- Há uma grande área de sobreposição entre os PDFs para diferentes combinações.
- Neste gráfico, as estruturas em blocos afiadas são chamadas de histogramas e a curva suave é conhecida como função de densidade de probabilidade (PDF).
NOTA:
A função de densidade de probabilidade (PDF) de uma curva pode nos ajudar a capturar a distribuição subjacente dessa característica, que é uma das principais conclusões da visualização de dados ou análise exploratória de dados (EDA).
2. Plotagem de caixa e bigode
- Este gráfico pode ser usado para obter mais detalhes estatísticos sobre os dados.
- As linhas no máximo e no mínimo também são chamadas bigodes.
- Pontos que estão fora dos bigodes serão considerados outliers.
- O box plot também nos dá uma descrição do Quartis 25, 50, 75.
- Com a ajuda de um gráfico de caixa, Além disso, podemos determinar a Intervalo interquartil (IQR) onde os detalhes máximos dos dados estarão presentes. Por isso, também pode nos dar uma ideia clara sobre os valores discrepantes no conjunto de dados.
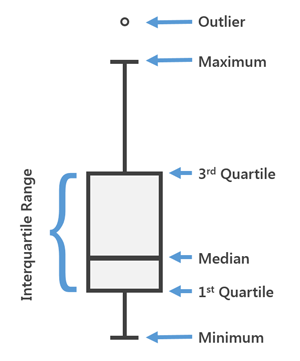
FIG. Diagrama geral para um gráfico de caixa
Implementação:
- O boxplot está ativado Seaborn Biblioteca.
- Aqui x é considerado como a variável dependente e y é considerado como a variável independente. Aqui x é considerado como a variável dependente e y é considerado como a variável independente Aqui x é considerado como a variável dependente e y é considerado como a variável independente, Aqui x é considerado como a variável dependente e y é considerado como a variável independente.
- Aqui x é considerado como a variável dependente e y é considerado como a variável independente “Aqui x é considerado como a variável dependente e y é considerado como a variável independente” Aqui x é considerado como a variável dependente e y é considerado como a variável independente “Estado de sobrevivência” Aqui x é considerado como a variável dependente e y é considerado como a variável independente.
O trecho de código é o seguinte:
sns.boxplot(Aqui x é considerado como a variável dependente e y é considerado como a variável independente,Aqui x é considerado como a variável dependente e y é considerado como a variável independente,Aqui x é considerado como a variável dependente e y é considerado como a variável independente)
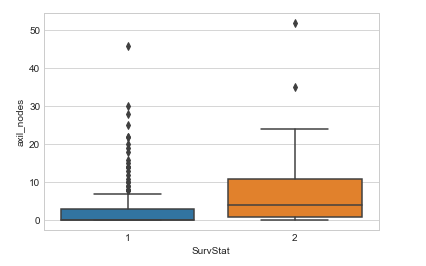
Aqui x é considerado como a variável dependente e y é considerado como a variável independente:
Aqui x é considerado como a variável dependente e y é considerado como a variável independente:
- Aqui x é considerado como a variável dependente e y é considerado como a variável independente, etc.
- Aqui x é considerado como a variável dependente e y é considerado como a variável independente 1, Aqui x é considerado como a variável dependente e y é considerado como a variável independente.
- Há mais outliers para a classe 1 no recurso chamado axil_nodes.
NOTA:
Podemos obter detalhes sobre os outliers que nos ajudarão a preparar bem os dados antes de enviá-los para um modelo, já que os outliers influenciam muitos modelos de aprendizado de máquina.
3. Moldura de violino
- Os gráficos de violino podem ser pensados como uma combinação de gráficos de caixa intermediária e gráficos de distribuição.(Estimativa de densidade de grão) em ambos os lados dos dados.
- Isso pode nos dar a descrição da distribuição do conjunto de dados como se a distribuição fosse multimodal, Obliquidadeetc.
- Ele também nos fornece informações úteis, como Intervalo de confiança de 95%.
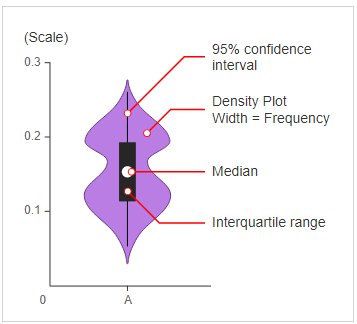
FIG. Diagrama geral para um gráfico de violino
Implementação:
- A trama do violino está presente na Seaborn pacote.
O trecho de código é o seguinte:
sns.violinplot(Aqui x é considerado como a variável dependente e y é considerado como a variável independente,y='em_ano',Aqui x é considerado como a variável dependente e y é considerado como a variável independente,tamanho=6)
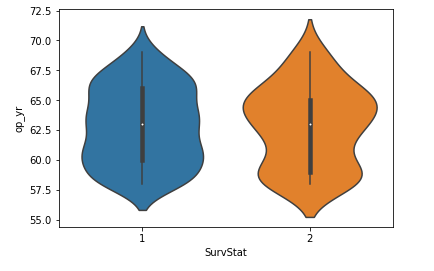
Algumas conclusões inferidas do gráfico de violino acima:
A partir do gráfico de violino acima, podemos concluir as seguintes observações:
- A mediana de ambas as classes está próxima de 63.
- O número máximo de pessoas com classe 2 tem um ano operacional valor de 65 enquanto que, para as pessoas da classe 1, o valor máximo é em torno 60.
- Ao mesmo tempo, o terceiro quartil para a mediana tem menos pontos de dados do que a mediana para o primeiro quartil.
Técnicas de análise bivariada para visualização de dados
1. Gráfico de linha
- Este é o gráfico que pode ser visto nos cantos de qualquer tipo de análise entre 2 variáveis.
- Os gráficos de linhas nada mais são do que os valores de uma série de pontos de dados a serem conectados com linhas retas.
- O enredo pode parecer muito simples, mas tem mais aplicações não apenas em aprendizado de máquina, mas em muitas outras áreas..
Implementação:
- O gráfico de linhas está presente no Matplotlib pacote.
O trecho de código é o seguinte:
plt.plot(x,e)
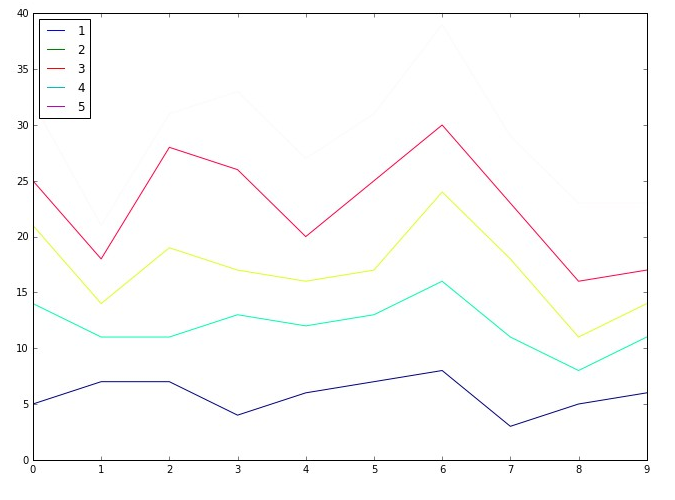
Algumas conclusões tiradas do diagrama de linhas acima:
A partir do gráfico de linhas acima, podemos concluir as seguintes observações:
- Eles são usados diretamente da execução da comparação de distribuição usando Parcelas QQ para ajustar CV usando o método do cotovelo.
- É usado para analisar o desempenho de um modelo usando o Curva ROC- AUC.
2. Gráfico de barras
- Este é um dos gráficos mais usados, que teríamos visto várias vezes não só na análise de dados, mas também usamos este gráfico sempre que há análise de tendências em muitos campos.
- Mesmo quando parece simples, é poderoso para analisar dados como números de vendas a cada semana, renda de um produto, Número de visitantes de um site a cada dia da semanaetc.
Implementação:
- O gráfico de barras está presente na Matplotlib pacote.
O trecho de código é o seguinte:
plt.bar(x,e)
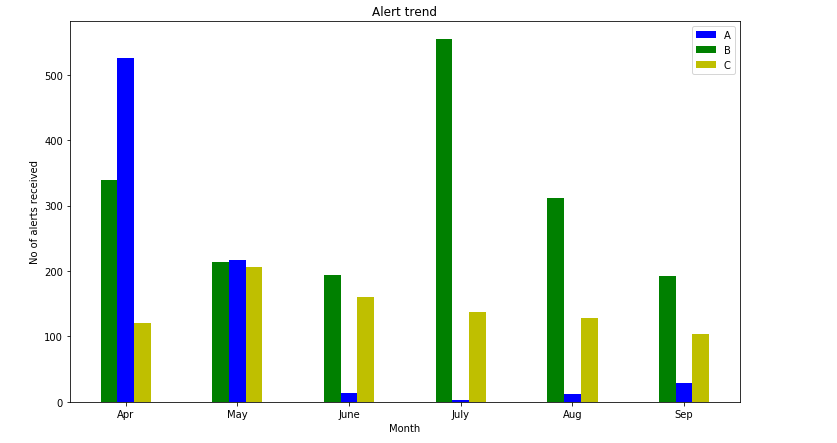
Algumas conclusões tiradas do gráfico de barras acima:
Do gráfico de barras acima podemos concluir as seguintes observações:
- Podemos visualizar os dados em um quadro legal e podemos transmitir os detalhes diretamente para outras pessoas.
- Este gráfico pode ser simples e claro, mas não é usado com muita frequência em aplicativos de ciência de dados.
3. Diagrama de dispersão
- É um dos gráficos mais usados para visualizar dados simples em aprendizado de máquina e ciência de dados..
- Este gráfico nos descreve como uma representação, onde cada ponto no conjunto de dados completo está presente em relação a 2 o 3 caracteristicas (colunas).
- Os gráficos de dispersão estão disponíveis em 2-D e 3-D. O gráfico de dispersão 2-D é o mais comum, onde tentaremos principalmente encontrar os padrões, grupos e separabilidade de dados.
Implementação:
- O gráfico de dispersão está presente na Matplotlib pacote.
O trecho de código é o seguinte:
plt.scatter(x,e)
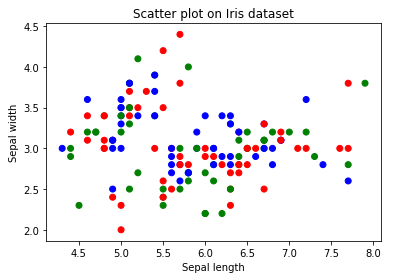
Algumas conclusões inferidas do gráfico de dispersão acima:
A partir do gráfico de dispersão acima, podemos concluir as seguintes observações:
- As cores são atribuídas a diferentes pontos de dados com base em como eles estavam presentes no conjunto de dados. Em outras palavras, renderização da coluna de destino.
- Podemos colorir os pontos de dados com base no rótulo de classe fornecido no conjunto de dados.
Isso completa a discussão de hoje!!
Notas finais
Obrigado pela leitura!
Espero que tenha gostado do post e aumentado seus conhecimentos sobre técnicas de visualização de dados..
Por favor sinta-se à vontade para me contactar sobre Correio eletrônico
Qualquer coisa não mencionada ou você deseja compartilhar suas idéias? Sinta-se à vontade para comentar abaixo e eu entrarei em contato com você.
Para os restantes cargos, Pedir ao Ligação.
Sobre o autor
Aashi Goyal
Neste momento, Estou cursando bacharelado em tecnologia (B.Tech) em Engenharia Eletrônica e de Comunicação pela Universidad Guru Jambheshwar (GJU), Hisar. Estou muito animado com as estatísticas, aprendizado de máquina e aprendizado profundo.
Suas sugestões e dúvidas são bem-vindas aqui na seção de comentários. Obrigado por ler meu post!!





