Introdução
Os humanos não redefinem sua compreensão da linguagem toda vez que ouvimos uma frase. Recebeu uma postagem, entendemos o contexto com base em nosso entendimento prévio dessas palavras. Uma das características definidoras que temos é a nossa memória (ou segurando o poder).
Um algoritmo pode replicar isso? A primeira técnica que vem à mente é um neuronal vermelhoAs redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano. Eles usam estruturas conhecidas como neurônios artificiais para processar e aprender com os dados. Essas redes são fundamentais no campo da inteligência artificial, permitindo avanços significativos em tarefas como reconhecimento de imagem, Processamento de linguagem natural e previsão de séries temporais, entre outros. Sua capacidade de aprender padrões complexos os torna ferramentas poderosas.. (NN). Mas, tristemente, NNs tradicionais não podem fazer isso. Veja o exemplo de querer prever o que vem a seguir em um vídeo. Uma rede neural tradicional terá dificuldade em gerar resultados precisos.
É aí que o conceito de redes neurais recorrentes entra em jogo. (RNN). As RNNs tornaram-se extremamente populares no espaço de aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde..., o que torna o aprendizado ainda mais imperativo. Algumas aplicações do mundo real da RNN incluem:
- Acreditação de voz
- Máquina tradutora
- Composição musical
- Credenciamento de Caligrafia
- Aprendizagem de gramática
 Neste post, vamos primeiro revisar rapidamente os componentes principais de um modelo RNN típico. Posteriormente configuraremos a declaração do problema que, em conclusão, resolveremos implementando um modelo RNN do zero em Python.
Neste post, vamos primeiro revisar rapidamente os componentes principais de um modelo RNN típico. Posteriormente configuraremos a declaração do problema que, em conclusão, resolveremos implementando um modelo RNN do zero em Python.
Sempre podemos tirar proveito das bibliotecas Python de alto nível para codificar um RNN. Então, Por que codificar do zero? Acredito firmemente que a melhor maneira de aprender e realmente enraizar um conceito é aprendê-lo do zero.. E é isso que vou mostrar neste tutorial.
Esta postagem pressupõe uma compreensão básica de redes neurais recorrentes. Caso você precise de uma atualização rápida ou esteja procurando aprender o básico da RNN, Eu recomendo que você leia os posts abaixo primeiro:
Tabela de conteúdo
- Flashback: um resumo dos conceitos de rede neural recorrente
- Predição de sequência usando RNN
- Construindo um modelo RNN usando Python
Flashback: um resumo dos conceitos de rede neural recorrente
Vamos recapitular rapidamente o básico por trás das redes neurais recorrentes.
Faremos isso usando um exemplo de dados de sequência, digamos que as ações de uma determinada empresa. Um modelo simples de aprendizado de máquina, ou uma rede neural artificial, você pode aprender a prever o preço das ações com base em uma série de características, como o volume das ações, o valor de abertura, etc. Além destes, o preço também depende de como o estoque se saiu nas semanas anteriores e. Para um comerciante, esses dados históricos são, na verdade, um fator decisivo importante para fazer previsões.
Em redes neurais convencionais de feedforward, todos os casos de teste são considerados independentes. Você pode ver que isso não se encaixa bem ao prever os preços das ações?? O modelo NN não consideraria os valores de preço das ações acima, Não é uma boa ideia!
Há outro conceito no qual podemos confiar ao lidar com dados urgentes: redes neurais recorrentes (RNN).
Um RNN típico se parece com isto:

Isso pode parecer intimidante no início. Mas uma vez que o desenvolvemos, as coisas começam a parecer muito mais simples:
 Agora ficou mais fácil visualizar como essas redes estão considerando a evolução dos preços das ações. Isso nos ajuda a prever os preços do dia. Aqui, cada previsão no tempo t (h_t) depende de todas as previsões anteriores e das informações obtidas a partir delas. Bem direto, verdade?
Agora ficou mais fácil visualizar como essas redes estão considerando a evolução dos preços das ações. Isso nos ajuda a prever os preços do dia. Aqui, cada previsão no tempo t (h_t) depende de todas as previsões anteriores e das informações obtidas a partir delas. Bem direto, verdade?
RNNs podem resolver nosso propósito de lidar com sequências em grandes mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática...., mas não exatamente.
O texto é outro bom exemplo de dados de sequência. Ser capaz de prever qual palavra ou frase vem depois de um determinado texto pode ser uma vantagem muito útil.. Queremos nossos modelos escrever sonetos de Shakespeare!
Agora, enfermeiras registradas são excelentes quando se trata de um contexto de natureza curta ou pequena. Mas ser capaz de construir uma história e lembrá-la, nossos modelos devem ser capazes de entender o contexto por trás das sequências, como um cérebro humano.
Predição de sequência usando RNN
Neste post, vamos trabalhar em um obstáculo de predição de sequência usando RNN. Uma das tarefas mais simples para isso é a previsão de ondas senoidais. A sequência contém uma tendência visível e é fácil de corrigir usando heurísticas. É assim que uma onda senoidal se parece:
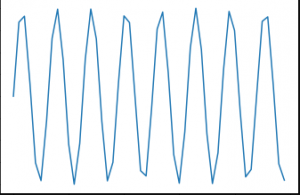
Primeiro, vamos projetar um recorrente neuronal vermelhaRedes neurais recorrentes (RNN) são um tipo de arquitetura de rede neural projetada para processar fluxos de dados. Ao contrário das redes neurais tradicionais, As RNNs usam conexões internas que permitem que as informações de entradas anteriores sejam lembradas. Isso os torna especialmente úteis em tarefas como processamento de linguagem natural, Tradução automática e análise de séries temporais, onde o contexto e a sequência são centrais para o... do zero para resolver este problema. Nosso modelo RNN também deve ser bem generalizável para que possamos aplicá-lo a outros problemas de sequência.
Vamos formular nosso problema desta forma: dada uma sequência de 50 números que pertencem a uma onda senoidal, prevê o número 51 da série. É hora de ligar seu laptop Jupyter! (ou seu IDE de escolha)!
Codificação RNN usando Python
Paso 0: preparação de dados
Ah, o primeiro passo inevitável em qualquer projeto de ciência de dados: prepare os dados antes de fazer qualquer outra coisa.
Como nosso modelo de rede espera que os dados sejam? Eu aceitaria uma sequência de comprimento único 50 como entrada. Então, a forma dos dados de entrada será:
(número_de_registros x comprimento_de_seqüência x tipos_de_seqüências)
Aqui, types_of_sequences es 1, porque temos apenas um tipo de sequência: la então sinusoidal.
Por outro lado, a saída teria apenas um valor para cada registro. Desde já, este será o valor 51 na sequência de entrada. Então sua forma seria:
(number_of_records x types_of_sequences) #onde tipos_de_sequências é 1
Vamos mergulhar no código. Primeiro, importar bibliotecas indispensáveis:
%pilab na linha importar matemática
Para criar uma onda senoidal como dados, vamos usar a função sinusoidal do Python Matemática Biblioteca:
sin_wave = por exemplo.variedade([matemática.sem(x) para x no por exemplo.arange(200)])
Visualizando a onda senoidal que acabamos de gerar:
plt.enredo(sin_wave[:50])

Vamos criar os dados agora no seguinte bloco de código:
X = [] E = [] seq_len = 50 num_records = len(sin_wave) - seq_len para eu no faixa(num_records - 50): X.acrescentar(sin_wave[eu:eu+seq_len]) E.acrescentar(sin_wave[eu+seq_len]) X = por exemplo.variedade(X) X = por exemplo.expand_dims(X, eixo=2) E = por exemplo.variedade(E) E = por exemplo.expand_dims(E, eixo=1)
Imprima o formulário de dados:
Observe que fizemos um loop para (num_records – 50) porque queremos reservar 50 registros como nossos dados de validação. Podemos criar esses dados de validação agora:
X_val = [] Y_val = [] para eu no faixa(num_records - 50, num_records): X_val.acrescentar(sin_wave[eu:eu+seq_len]) Y_val.acrescentar(sin_wave[eu+seq_len]) X_val = por exemplo.variedade(X_val) X_val = por exemplo.expand_dims(X_val, eixo=2) Y_val = por exemplo.variedade(Y_val) Y_val = por exemplo.expand_dims(Y_val, eixo=1)
Paso 1: Crie a arquitetura para nosso modelo RNN
Nossa próxima tarefa é estabelecer todas as variáveis e funções indispensáveis que usaremos no modelo RNN.. Nosso modelo pegará a sequência de entrada, irá processá-lo por meio de uma camada oculta de 100 unidades e produzirá uma saída de valor único:
taxa de Aprendizagem = 0.0001 nepoch = 25 T = 50 # comprimento da sequência oculto_dim = 100 output_dim = 1 bptt_truncate = 5 min_clip_value = -10 max_clip_value = 10
Posteriormente iremos definir os pesos da rede:
você = por exemplo.aleatória.uniforme(0, 1, (oculto_dim, T)) C = por exemplo.aleatória.uniforme(0, 1, (oculto_dim, oculto_dim)) V = por exemplo.aleatória.uniforme(0, 1, (output_dim, oculto_dim))
Aqui,
- U é a matriz de pesos para os pesos entre as camadas de entrada e ocultas
- V é a matriz de peso para pesos entre as camadas ocultas e de saída
- W é a matriz de peso para pesos compartilhados na camada RNN (camada escondida)
Em resumo, vamos definir o função de despertarA função de ativação é um componente chave em redes neurais, uma vez que determina a saída de um neurônio com base em sua entrada. Seu principal objetivo é introduzir não linearidades no modelo, permitindo que você aprenda padrões complexos em dados. Existem várias funções de ativação, como o sigmóide, ReLU e tanh, cada um com características particulares que afetam o desempenho do modelo em diferentes aplicações...., sigmoidea, para ser usado na camada oculta:
def sigmóide(x): Retorna 1 / (1 + por exemplo.exp(-x))
Paso 2: treinar o modelo
Agora que definimos nosso modelo, Em conclusão, podemos continuar com o TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... em nossos dados de sequência. Podemos subdividir o procedimento de treinamento em etapas menores, a saber:
Paso 2.1: Verifique se há perda de dados de treinamento
Paso 2.1.1: Passe adiante
Paso 2.1.2: Calcule o erro
Paso 2.2: Verifique se há perda de dados de validação
Paso 2.2.1: Passe adiante
Paso 2.2.2: Calcule o erro
Paso 2.3: Comece o treinamento real
Paso 2.3.1: Passe adiante
Paso 2.3.2: Erro de retropropagação
Paso 2.3.3: Atualize os pesos
Precisamos repetir essas etapas até a convergência. Se o modelo começar a super ajustar, Pare! Ou apenas predefinir o número de épocas.
Paso 2.1: Verifique se há perda de dados de treinamento
Faremos uma passagem direta pelo nosso modelo RNN e calcularemos o erro quadrático das previsões para todos os registros a fim de obter o valor da perda.
para época no faixa(nepoch): # verificar perda no trem perda = 0.0 # faça um passe para frente para obter a previsão para eu no faixa(E.forma[0]): x, e = X[eu], E[eu] # obter entrada, valores de saída de cada registro prev_s = por exemplo.zeros((oculto_dim, 1)) # aqui, prev-s é o valor da ativação anterior da camada oculta; que é inicializado como todos zeros para t no faixa(T): new_input = por exemplo.zeros(x.forma) # então fazemos um passe para frente para cada passo de tempo na sequência new_input[t] = x[t] # por esta, nós estabelecemos uma única entrada para esse intervalo de tempo mulu = por exemplo.ponto(você, new_input) mulw = por exemplo.ponto(C, prev_s) adicionar = mulw + mulu s = sigmóide(adicionar) mulv = por exemplo.ponto(V, s) prev_s = s # calcular erro loss_per_record = (e - mulv)**2 / 2 perda += loss_per_record perda = perda / flutuador(e.forma[0])
Paso 2.2: Verifique se há perda de dados de validação
Faremos o mesmo para calcular a perda nos dados de validação (no mesmo ciclo):
# verificar perda em val val_loss = 0.0 para eu no faixa(Y_val.forma[0]): x, e = X_val[eu], Y_val[eu] prev_s = por exemplo.zeros((oculto_dim, 1)) para t no faixa(T): new_input = por exemplo.zeros(x.forma) new_input[t] = x[t] mulu = por exemplo.ponto(você, new_input) mulw = por exemplo.ponto(C, prev_s) adicionar = mulw + mulu s = sigmóide(adicionar) mulv = por exemplo.ponto(V, s) prev_s = s loss_per_record = (e - mulv)**2 / 2 val_loss += loss_per_record val_loss = val_loss / flutuador(e.forma[0]) imprimir('Época: ', época + 1, ', Perda: ', perda, ', Val Loss: ', val_loss)
Você deve obter o seguinte resultado:
Época: 1 , Perda: [[101185.61756671]] , Val Loss: [[50591.0340148]] ... ...
Paso 2.3: Comece o treinamento real
Agora vamos começar com o treinamento real da rede. Neste, primeiro faremos um passe para frente para calcular os erros e um passe para trás para calcular os gradientes e atualizá-los. Deixe-me mostrar isso passo a passo para que você possa visualizar como isso funciona em sua mente.
Paso 2.3.1: Passe adiante
No passe de avanço:
- Primeiro, multiplicamos a entrada com os pesos entre a entrada e as camadas ocultas.
- Adicione isso com a multiplicação de pesos na camada RNN. Isso ocorre porque queremos capturar o conhecimento da etapa de tempo anterior.
- Passe por uma função de ativação sigmóide.
- Multiplique isso com os pesos entre as camadas ocultas e de saída.
- No Camada de saídao "Camada de saída" é um conceito utilizado no campo da tecnologia da informação e design de sistemas. Refere-se à última camada de um modelo ou arquitetura de software que é responsável por apresentar os resultados ao usuário final. Essa camada é crucial para a experiência do usuário, uma vez que permite a interação direta com o sistema e a visualização dos dados processados...., temos uma ativação linear dos valores, portanto, não passamos explicitamente o valor por meio de uma camada de gatilho.
- Salve o estado na camada atual e também o estado na etapa de tempo anterior em um dicionário
Aqui está o código para realizar uma passagem para frente (note que é uma continuação do ciclo anterior):
# modelo de trem para eu no faixa(E.forma[0]): x, e = X[eu], E[eu] camadas = [] prev_s = por exemplo.zeros((oculto_dim, 1)) do = por exemplo.zeros(você.forma) dV = por exemplo.zeros(V.forma) dW = por exemplo.zeros(C.forma) dU_t = por exemplo.zeros(você.forma) dV_t = por exemplo.zeros(V.forma) dW_t = por exemplo.zeros(C.forma) dU_i = por exemplo.zeros(você.forma) dW_i = por exemplo.zeros(C.forma) # Passar para a frente para t no faixa(T): new_input = por exemplo.zeros(x.forma) new_input[t] = x[t] mulu = por exemplo.ponto(você, new_input) mulw = por exemplo.ponto(C, prev_s) adicionar = mulw + mulu s = sigmóide(adicionar) mulv = por exemplo.ponto(V, s) camadas.acrescentar({'s':s, 'prev_s':prev_s}) prev_s = s
Paso 2.3.2: Erro de retropropagação
Após a etapa de propagação direta, calculamos os gradientes em cada camada e propagamos de volta os erros. Usaremos a propagação retrógrada truncada ao longo do tempo (TBPTT), em vez de retropropagar baunilha. Pode parecer complexo, mas na verdade é bem simples.
A diferença central em BPTT versus backprop é que a etapa de retropropagação é realizada para todas as etapas de tempo na camada RNN. Então, se o comprimento da nossa sequência é 50, vamos retropropagar todas as etapas de tempo antes da etapa de tempo atual.
Se você adivinhou corretamente, BPTT parece muito caro computacionalmente. Então, em vez de se propagar para trás por todas as etapas de tempo anteriores, nós propagamos de volta até x passos de tempo para economizar poder computacional. Considere isso ideologicamente semelhante ao declínio de gradienteGradiente é um termo usado em vários campos, como matemática e ciência da computação, descrever uma variação contínua de valores. Na matemática, refere-se à taxa de variação de uma função, enquanto em design gráfico, Aplica-se à transição de cores. Esse conceito é essencial para entender fenômenos como otimização em algoritmos e representação visual de dados, permitindo uma melhor interpretação e análise em... estocástico, onde incluímos um lote de pontos de dados em vez de todos os pontos de dados.
Aqui está o código para propagar os erros para trás:
# derivado de pred dmulv = (mulv - e) # passe para trás para t no faixa(T): dV_t = por exemplo.ponto(dmulv, por exemplo.transpor(camadas[t]['s'])) dsv = por exemplo.ponto(por exemplo.transpor(V), dmulv) ds = dsv papai = adicionar * (1 - adicionar) * ds dmulw = papai * por exemplo.ones_like(mulw) dprev_s = por exemplo.ponto(por exemplo.transpor(C), dmulw) para eu no faixa(t-1, max(-1, t-bptt_truncate-1), -1): ds = dsv + dprev_s papai = adicionar * (1 - adicionar) * ds dmulw = papai * por exemplo.ones_like(mulw) dmulu = papai * por exemplo.ones_like(mulu) dW_i = por exemplo.ponto(C, camadas[t]['prev_s']) dprev_s = por exemplo.ponto(por exemplo.transpor(C), dmulw) new_input = por exemplo.zeros(x.forma) new_input[t] = x[t] dU_i = por exemplo.ponto(você, new_input) dx = por exemplo.ponto(por exemplo.transpor(você), dmulu) dU_t += dU_i dW_t += dW_i dV += dV_t do += dU_t dW += dW_t
Paso 2.3.3: Atualize os pesos
Por último, nós atualizamos os pesos com os gradientes dos pesos calculados. Uma coisa que precisamos prestar atenção é que os gradientes tendem a explodir se você não os manter sob controle.. Este é um tópico fundamental no treinamento de redes neurais., chamado de problema do gradiente explosivo. Portanto, temos que mantê-los em um intervalo para que não explodam. Nós podemos fazer assim
E se do.max() > max_clip_value: do[do > max_clip_value] = max_clip_value E se dV.max() > max_clip_value: dV[dV > max_clip_value] = max_clip_value E se dW.max() > max_clip_value: dW[dW > max_clip_value] = max_clip_value E se do.min() < min_clip_value: do[do < min_clip_value] = min_clip_value E se dV.min() < min_clip_value: dV[dV < min_clip_value] = min_clip_value E se dW.min() < min_clip_value: dW[dW < min_clip_value] = min_clip_value # atualizar você -= taxa de Aprendizagem * do V -= taxa de Aprendizagem * dV C -= taxa de Aprendizagem * dW
Ao treinar o modelo anterior, nós obtemos este resultado:
Época: 1 , Perda: [[101185.61756671]] , Val Loss: [[50591.0340148]] Época: 2 , Perda: [[61205.46869629]] , Val Loss: [[30601.34535365]] Época: 3 , Perda: [[31225.3198258]] , Val Loss: [[15611.65669247]] Época: 4 , Perda: [[11245.17049551]] , Val Loss: [[5621.96780111]] Época: 5 , Perda: [[1264.5157739]] , Val Loss: [[632.02563908]] Época: 6 , Perda: [[20.15654115]] , Val Loss: [[10.05477285]] Época: 7 , Perda: [[17.13622839]] , Val Loss: [[8.55190426]] Época: 8 , Perda: [[17.38870495]] , Val Loss: [[8.68196484]] Época: 9 , Perda: [[17.181681]] , Val Loss: [[8.57837827]] Época: 10 , Perda: [[17.31275313]] , Val Loss: [[8.64199652]] Época: 11 , Perda: [[17.12960034]] , Val Loss: [[8.54768294]] Época: 12 , Perda: [[17.09020065]] , Val Loss: [[8.52993502]] Época: 13 , Perda: [[17.17370113]] , Val Loss: [[8.57517454]] Época: 14 , Perda: [[17.04906914]] , Val Loss: [[8.50658127]] Época: 15 , Perda: [[16.96420184]] , Val Loss: [[8.46794248]] Época: 16 , Perda: [[17.017519]] , Val Loss: [[8.49241316]] Época: 17 , Perda: [[16.94199493]] , Val Loss: [[8.45748739]] Época: 18 , Perda: [[16.99796892]] , Val Loss: [[8.48242177]] Época: 19 , Perda: [[17.24817035]] , Val Loss: [[8.6126231]] Época: 20 , Perda: [[17.00844599]] , Val Loss: [[8.48682234]] Época: 21 , Perda: [[17.03943262]] , Val Loss: [[8.50437328]] Época: 22 , Perda: [[17.01417255]] , Val Loss: [[8.49409597]] Época: 23 , Perda: [[17.20918888]] , Val Loss: [[8.5854792]] Época: 24 , Perda: [[16.92068017]] , Val Loss: [[8.44794633]] Época: 25 , Perda: [[16.76856238]] , Val Loss: [[8.37295808]]
Parece bom! É hora de obter as previsões e representá-las para ter uma ideia visual do que projetamos.
Paso 3: obter previsões
Faremos um passe para frente pelos pesos treinados para obter nossas previsões:
preds = [] para eu no faixa(E.forma[0]): x, e = X[eu], E[eu] prev_s = por exemplo.zeros((oculto_dim, 1)) # Passar para a frente para t no faixa(T): mulu = por exemplo.ponto(você, x) mulw = por exemplo.ponto(C, prev_s) adicionar = mulw + mulu s = sigmóide(adicionar) mulv = por exemplo.ponto(V, s) prev_s = s preds.acrescentar(mulv) preds = por exemplo.variedade(preds)
Traçando essas previsões junto com os valores reais:
plt.enredo(preds[:, 0, 0], 'g') plt.enredo(E[:, 0], 'r') plt.exposição()

Isso estava nos dados de treinamento. Como sabemos se nosso modelo não era muito apertado? É aqui que entra o conjunto de validação., que criamos anteriormente:
preds = [] para eu no faixa(Y_val.forma[0]): x, e = X_val[eu], Y_val[eu] prev_s = por exemplo.zeros((oculto_dim, 1)) # Para cada passo de tempo ... para t no faixa(T): mulu = por exemplo.ponto(você, x) mulw = por exemplo.ponto(C, prev_s) adicionar = mulw + mulu s = sigmóide(adicionar) mulv = por exemplo.ponto(V, s) prev_s = s preds.acrescentar(mulv) preds = por exemplo.variedade(preds) plt.enredo(preds[:, 0, 0], 'g') plt.enredo(Y_val[:, 0], 'r') plt.exposição()

Nada mal. As previsões parecem impressionantes. A pontuação RMSE nos dados de validação também é respeitável:
a partir de sklearn.metrics importar mean_squared_error matemática.sqrt(mean_squared_error(Y_val[:, 0] * max_val, preds[:, 0, 0] * max_val))
0.127191931509431
Notas finais
Não consigo enfatizar o quanto os RNNs são úteis ao trabalhar com dados de sequência. Imploro a todos que usem esse aprendizado e o apliquem a um conjunto de dados. Aceite um obstáculo da PNL e veja se consegue encontrar uma solução. Você sempre pode me encontrar na seção de comentários abaixo se tiver alguma dúvida.
Neste post, aprendemos como criar um modelo de rede neural recorrente do zero usando apenas a biblioteca numpy. Desde já, você pode usar uma biblioteca de alto nível como Keras ou Caffe, mas é essencial saber o conceito que você está implementando.
Compartilhe seus pensamentos, perguntas e comentários sobre este post abaixo. Boa aprendizagem!





