Introdução
Um desafio comum que encontrei enquanto aprender processamento de linguagem natural (PNL) – Podemos construir modelos para outros idiomas além do inglês? A resposta tem sido não há algum tempo. Cada idioma tem seus próprios padrões gramaticais e nuances linguísticas. E simplesmente não existem muitos conjuntos de dados disponíveis em outros idiomas.
É aí que entra a mais recente biblioteca de PNL de Stanford.: StanfordNLP.
Eu mal pude conter minha empolgação quando li as notícias da semana passada. Os autores afirmaram que StanfordNLP poderia apoiar mais do que 53 linguagens humanas. sim, Eu tive que verificar aquele número.
Eu decidi verificar sozinho. Ainda não existe um tutorial oficial para a biblioteca, então eu tive a chance de experimentar e brincar com ele. E descobri que abre um mundo de possibilidades infinitas. StanfordNLP contém modelos pré-treinados para línguas asiáticas raras como o hindi, Chinês e japonês em seus scripts originais.

A capacidade de trabalhar com vários idiomas é uma maravilha que todos os entusiastas da PNL desejam. Neste artigo, vamos analisar o que é StanfordNLP, Por que isso é tão importante, e então vamos ativar o Python para vê-lo ao vivo em ação. Também faremos um estudo de caso em hindi para mostrar como o StanfordNLP funciona, Você não quer perder isso!
Tabela de conteúdo
- O que é StanfordNLP e por que você deve usá-lo?
- Configuração StanfordNLP em Python
- Usando StanfordNLP para realizar tarefas básicas de PNL
- Implementação StanfordNLP em hindi
- Usando a API CoreNLP para análise de texto
O que é StanfordNLP e por que você deve usá-lo?
Aqui está a descrição do StanfordNLP feita pelos próprios autores:
StanfordNLP é a combinação do pacote de software usado pela equipe de Stanford na tarefa compartilhada CoNLL 2018 sobre a análise de dependência universal e a interface Python oficial do grupo para o Software Stanford CoreNLP.
É muita informação de uma vez!! Vamos decompô-lo:
- CoNLL é uma conferência anual sobre aprendizagem de línguas naturais. Equipes que representam institutos de pesquisa em todo o mundo estão tentando resolver um PNL baseado em tarefas
- Uma das tarefas do ano passado foi “Análise multilíngue de texto simples para dependências universais”. Em termos simples, significa analisar dados de texto não estruturados de vários idiomas em anotações úteis de dependências universais.
- Dependências universais é uma estrutura que mantém a consistência nas anotações. Essas anotações são geradas para o texto, independentemente do idioma que está sendo analisado.
- A apresentação de Stanford ficou em primeiro lugar em 2017. Eles perderam a primeira posição em 2018 devido a um bug de software (terminou em quarto lugar)
StanfordNLP é uma coleção de modelos de última geração pré-treinados. Esses modelos foram usados pelos pesquisadores nas competições CoNLL. 2017 e 2018. Todos os modelos são baseados em PyTorch e podem ser treinados e avaliados com seus próprios dados anotados. Impressionante!
 avançar, StanfordNLP também contém um contêiner oficial para a popular biblioteca PNL gigante: CoreNLP. Isso havia sido um tanto limitado ao ecossistema Java até agora. Você deve verificar este tutorial para aprender mais sobre CoreNLP e como ele funciona em Python.
avançar, StanfordNLP também contém um contêiner oficial para a popular biblioteca PNL gigante: CoreNLP. Isso havia sido um tanto limitado ao ecossistema Java até agora. Você deve verificar este tutorial para aprender mais sobre CoreNLP e como ele funciona em Python.
Aqui estão mais alguns motivos pelos quais você deve verificar esta biblioteca:
- Implementação nativa de Python que requer esforço mínimo para configurar
- Canalización de neuronal vermelhoAs redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano. Eles usam estruturas conhecidas como neurônios artificiais para processar e aprender com os dados. Essas redes são fundamentais no campo da inteligência artificial, permitindo avanços significativos em tarefas como reconhecimento de imagem, Processamento de linguagem natural e previsão de séries temporais, entre outros. Sua capacidade de aprender padrões complexos os torna ferramentas poderosas.. completa para un análisis de texto sólido, que inclui:
- Tokenización
- Expansão de token de várias palavras (MWT)
- Lematización
- Rotulando classes gramaticais (POS) e características morfológicas
- Análise de dependência
- Modelos neurais pré-treinados que suportam 53 expressões idiomáticas (humanos) apresentado em 73 bancos de árvores
- Uma interface Python estável e mantida oficialmente para CoreNLP
O que mais um entusiasta da PNL poderia pedir?? Agora que temos uma ideia do que esta biblioteca faz, Vamos dar uma volta no python!
Configuração StanfordNLP em Python
Existem algumas coisas peculiares sobre a biblioteca que me intrigaram no início. Por exemplo, você precisa Pitão 3.6.8 / 3.7.2 ou mais tarde para usar StanfordNLP. Para ter certeza, Eu configurei um ambiente separado no Anaconda para Pitão 3.7.1. É assim que você pode fazer:
1. Abra o prompt do conda e digite isso:
conda create -n stanfordnlp python = 3.7.1
2. Agora ative o ambiente:
fonte ativar stanfordnlp
3. Instale a Biblioteca StanfordNLP:
pip install stanfordnlp
4. Precisamos baixar o modelo específico de uma linguagem para trabalhar com isso. Inicie um shell Python e importe StanfordNLP:
import stanfordnlp
então baixe o modelo de idioma para inglês (“sobre”):
stanfordnlp.download('sobre')
Isso pode demorar um pouco, dependendo da sua conexão com a Internet.. Esses modelos de linguagem são bastante grandes (Inglês é de 1,96 GB).
Algumas notas importantes
- StanfordNLP é baseado em PyTorch 1.0.0. Pode falhar se você tiver uma versão mais antiga. A seguir, Mostramos como você pode verificar a versão instalada em sua máquina:
pip freeze | grep torch
que deve dar uma saída como torch==1.0.0
- Tentei usar a biblioteca sem GPU no meu Lenovo Thinkpad E470 (8GB RAM, Intel Graphics). Recebi um erro de memória em Python muito rápido. Portanto, eu mudei para uma máquina habilitada para GPU e aconselho você a fazer o mesmo também. Podes tentar Google Colab que vem com suporte gratuito para GPU
Isso é tudo! Vamos mergulhar em alguns processos básicos da PNL imediatamente..
Usando StanfordNLP para realizar tarefas básicas de PNL
StanfordNLP vem com processadores integrados para realizar cinco tarefas básicas de PNL:
- Tokenización
- Expansão de token de várias palavras
- Lematización
- Rotulagem de partes da fala
- Análise de dependência
Vamos começar criando um pipeline de texto:
nlp = stanfordnlp.Pipeline(processadores = "tokenizar,mwt,lema,pos")
doc = nlp("""As perspectivas de uma retirada ordenada da Grã-Bretanha da União Europeia em março 29 recuaram ainda mais, mesmo quando os parlamentares se reuniram para impedir um cenário sem acordo. Uma emenda ao projeto de lei sobre a rescisão da adesão de Londres ao bloco obriga a primeira-ministra Theresa May a renegociar seu acordo de retirada com Bruxelas. A proposta de um backbencher conservador pede ao governo que apresente alternativas para o backstop irlandês, um princípio central do acordo que a Grã-Bretanha concordou com o resto da UE.""")
a processadores = “” O argumento é usado para especificar a tarefa. Todos os cinco processadores são usados por padrão se nenhum argumento for passado. Aqui está uma visão geral rápida dos processadores e o que eles podem fazer:

Vamos ver cada um deles em ação.
Tokenización
Este processo ocorre implicitamente quando o processador de token está em execução. De fato, é bem rápido. Você pode dar uma olhada nos tokens usando print_tokens ():
doc.sentences[0].print_tokens()
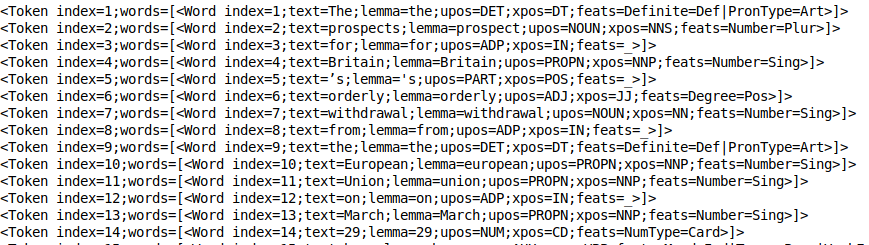
El objeto token contiene el índiceo "Índice" É uma ferramenta fundamental em livros e documentos, que permite localizar rapidamente as informações desejadas. Geralmente, é apresentado no início de um trabalho e organiza os conteúdos de forma hierárquica, incluindo capítulos e seções. Sua correta preparação facilita a navegação e melhora a compreensão do material, tornando-se um recurso essencial para estudantes e profissionais de várias áreas.... del token en la oración y una lista de objetos de palabra (no caso de um token de várias palavras). Cada objeto de palavra contém informações úteis, como o índice da palavra, o lema do texto, tag pos (partes do discurso) e o talento (características morfológicas).
Lematización
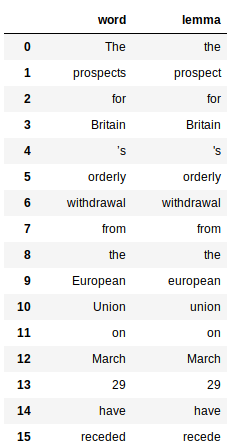
Isso envolve o uso da propriedade “lema” das palavras geradas pelo processador de slogan. Aqui está o código para obter o lema de todas as palavras:
Isso retorna um pandas quadro de dados para cada palavra e seu respectivo lema:
Rotulando classes gramaticais (PoS)
O tagger PoS é bastante rápido e funciona muito bem em todos os idiomas. Como os slogans, As tags PoS também são fáceis de remover:
Observe o grande dicionário no código acima? É apenas um mapeamento entre as tags PoS e seu significado. Isso ajuda a entender melhor a estrutura sintática do nosso documento.
A saída seria um quadro de dados com três colunas: palavra, pos e exp (Explicação). A coluna de explicação nos dá mais informações sobre o texto (e, portanto, é bastante útil).
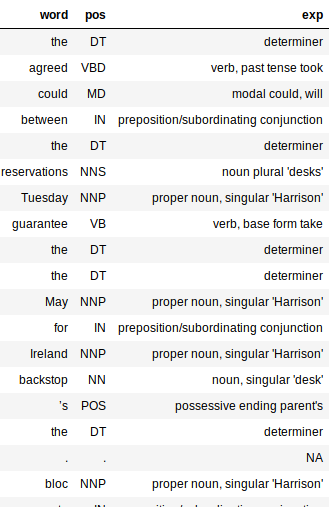
Adicionar a coluna de explicação torna muito mais fácil avaliar o quão preciso é o nosso processador. Eu gosto do fato de que o tagger é preciso para a maioria das palavras. Ele até captura o tempo de uma palavra e se está na forma básica ou plural.
Extração de dependência
Extração de dependência é outro recurso out-of-the-box do StanfordNLP. Você pode apenas ligar print_dependencies () em uma frase para obter as taxas de dependência de todas as suas palavras:
doc.sentences[0].print_dependencies()

A biblioteca calcula todos os itens acima durante uma única execução de pipeline. Isso levará apenas alguns minutos em uma máquina habilitada para GPU.
Agora descobrimos uma maneira de fazer processamento de texto básico com StanfordNLP. É hora de aproveitar o fato de que podemos fazer o mesmo pelos outros! 51 línguas!
Implementação StanfordNLP em hindi
StanfordNLP realmente se destaca por seu suporte e desempenho de análise de texto multilíngue. Vamos nos aprofundar neste último aspecto.
Processamento de texto em hindi (escrita devanágari)
Primeiro, temos que baixar o modelo da língua hindi (Comparativamente menor!):
stanfordnlp.download('Oi')
Agora, pegue um trecho de texto em hindi como nosso documento de texto:
hindi_doc = nlp("""O governo Modi no Centro apresentou seu orçamento provisório na sexta-feira.. Ministro das Finanças em exercício, Piyush Goyal, em seu orçamento, Trabalho, contribuinte, Bumpers anunciados para todos, incluindo mulheres. Embora, Mesmo depois do orçamento, houve muita confusão sobre o imposto.. O que havia de especial neste orçamento provisório do governo central e quem recebia o quê, entenda aqui em uma linguagem fácil""")
Isso deve ser o suficiente para gerar todos os rótulos. Vamos verificar as tags para hindi:
extract_pos(hindi_doc)
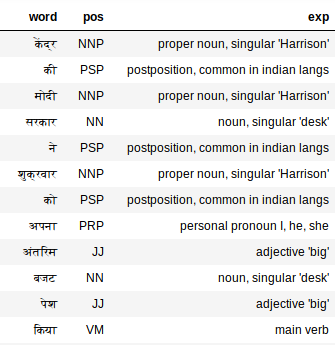
O tagger PoS funciona surpreendentemente bem em textos em hindi também. Visão “Meu”, por exemplo. O tagger PoS o rotula como um pronome, mim, ele, ela, o que é exato.
Usando a API CoreNLP para análise de texto
CoreNLP é um kit de ferramentas de PNL de nível industrial testado pelo tempo que é conhecido por seu desempenho e precisão. StanfordNLP foi declarado como uma interface Python oficial para CoreNLP. É uma GRANDE vitória para esta biblioteca.
Houve esforços antes de criar pacotes de wrapper Python para CoreNLP, mas nada supera uma implementação oficial dos próprios autores. Isso significa que a biblioteca terá atualizações e melhorias regulares..
StanfordNLP requer três linhas de código para começar a usar a sofisticada API CoreNLP. Literalmente, Apenas três linhas de código para configurá-lo!!
1. Baixe o pacote CoreNLP. Abra seu terminal Linux e digite o seguinte comando:
wget http://nlp.stanford.edu/software/stanford-corenlp-full-2018-10-05.zip
2. Descompacte o pacote baixado:
descompacte stanford-corenlp-full-2018-10-05.zip
3. Inicie o servidor CoreNLP:
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 -tempo esgotado 15000
Observação: CoreNLP requer Java8 para rodar. Certifique-se de ter JDK e JRE 1.8.x instalados.
Agora, certifique-se de que StanfordNLP saiba onde CoreNLP está presente. Para isso, deve exportar $ CORENLP_HOME como o local da sua pasta. No meu caso, esta pasta estava em casa em si mesmo para que meu caminho seja como
export CORENLP_HOME = stanford-corenlp-full-2018-10-05 /
Assim que as etapas acima forem realizadas, você pode iniciar o servidor e fazer solicitações em código python. Abaixo está um exemplo completo de como iniciar um servidor, fazer solicitações e acessar os dados do objeto retornado.
uma. Configuração CoreNLPClient
B. Análise de dependência e POS
C. Reconhecimento de entidades nomeadas e strings de co-referência
Os exemplos acima mal arranham a superfície do que CoreNLP pode fazer e, porém, é muito interessante, fomos capazes de realizar tudo, desde tarefas básicas de PNL, como rotular partes do discurso, até coisas como reconhecer entidades nomeadas, extrair strings de co-referência e descobrir quem escreveu o que. em uma frase em algumas linhas de código Python.
O que eu mais gosto aqui é a facilidade de uso e a maior acessibilidade que isso traz quando se trata de usar CoreNLP em Python.
Meus pensamentos sobre como usar StanfordNLP – Prós e contras
Explorar uma biblioteca recém-lançada foi certamente um desafio. Quase não existe documentação sobre StanfordNLP! Porém, foi uma experiência de aprendizagem bastante agradável.
Algumas coisas que me entusiasmam em relação ao futuro de StanfordNLP:
- Seu suporte out-of-the-box para vários idiomas
- O fato de que será uma interface oficial Python para CoreNLP. Isso significa que ele só melhorará a funcionalidade e a facilidade de uso no futuro..
- É bem rápido (exceto a enorme pegada de memória)
- Configuração simples em Python
Porém, existem algumas rachaduras para resolver. Abaixo estão minhas idéias sobre as áreas em que StanfordNLP poderia melhorar:
- O tamanho dos modelos de linguagem é muito grande (Inglês é de 1,9 GB, Chinês ~ 1,8 GB)
- A biblioteca requer muito código para produzir funções. Compare isso com NLTK, onde você pode escrever um protótipo rapidamente; isso pode não ser possível para StanfordNLP
- Recursos de exibição ausentes no momento. É útil tê-lo para funções como análise de dependência. StanfordNLP fica aquém aqui em comparação com bibliotecas como SpaCy
Certifique-se de verificar Documentação oficial StanfordNLP.
Notas finais
Ainda existe uma função que ainda não experimentei. StanfordNLP permite que você treine modelos em seus próprios dados anotados usando incorporações de Word2Vec / FastText. Eu gostaria de explorá-lo no futuro e ver como essa funcionalidade é eficaz.. Vou atualizar o artigo quando a biblioteca amadurecer um pouco.
Claramente, StanfordNLP está em fase beta. Só vai ficar melhor a partir daqui, então este é um bom momento para começar a usá-lo: obter uma vantagem sobre todos os outros.
Por agora, o fato de que esses incríveis kits de ferramentas (CoreNLP) estão alcançando o ecossistema Python e gigantes da pesquisa como Stanford estão fazendo um esforço para abrir seu software de código aberto, Estou otimista com o futuro.





