Introdução
Todos os modelos estão errados, mas alguns são úteis – George Box
A análise de regressão marca a primeira etapa na modelagem preditiva. Com certeza, é muito fácil de implementar. Nem sua sintaxe nem seus parâmetros criam qualquer tipo de confusão. Mas, apenas execute apenas uma linha de código, não resolve o propósito. Não apenas olhando para os valores de R² ou MSE. A regressão diz muito mais do que isso!!
Um R, análise de regressão retorna 4 gráficos usando plot(model_name) Função. Cada um dos gráficos fornece informações significativas, ou melhor, uma história interessante sobre os dados. Lamentavelmente, muitos dos iniciantes não conseguem decifrar as informações ou não se importam com o que esses enredos dizem. Depois de entender esses gráficos, você pode trazer uma melhoria significativa em seu modelo de regressão.
Para melhorar o modelo, você também precisa entender as suposições de regressão e as maneiras de corrigi-las quando forem violadas.
Neste artigo, Eu expliquei as importantes premissas e gráficos de regressão (com correções e soluções) para ajudá-lo a entender o conceito de regressão em mais detalhes. Como afirmado acima, com esse conhecimento, você pode trazer melhorias drásticas aos seus modelos.
Observação: Para entender esses gráficos, você deve saber o básico da análise de regressão. Se você é completamente novo nisso, você pode começar aqui. Mais tarde, continue com este artigo.

Suposições de regressão
A regressão é uma abordagem paramétrica. ‘Paramétrico’ significa que você faz suposições sobre os dados para fins analíticos. Devido ao seu lado paramétrico, a regressão é restritiva por natureza. Não funciona bem com conjuntos de dados que não atendem às suas suposições. Portanto, para uma análise de regressão bem-sucedida, é essencial validar essas suposições.
Então, Como você verificaria (iria validar) se um conjunto de dados segue todas as suposições de regressão? Verifique usando gráficos de regressão (explicado abaixo) junto com alguma prova estatística.
Vejamos as suposições importantes na análise de regressão:
- Deve haver uma relação linear e aditiva entre a variável dependente (responder) e a variável independente (Predictora). Uma relação linear sugere que uma mudança na resposta Y devido a uma mudança de uma unidade em X¹ é constante, independentemente do valor de X¹. Uma relação aditiva sugere que o efeito de X¹ em Y é independente de outras variáveis.
- Não deve haver correlação entre os termos residuais (erro). A ausência desse fenômeno é conhecida como autocorrelação..
- As variáveis independentes não devem ser correlacionadas. A ausência desse fenômeno é conhecida como multicolinearidade..
- Os termos de erro devem ter uma variação constante. Esse fenômeno é conhecido como homocedasticidade.. A presença de variância não constante refere-se à heterocedasticidade.
- Os termos de erro devem ser distribuídos normalmente.
E se essas suposições forem violadas?
Vamos analisar suposições específicas e aprender sobre seus resultados (se eles são estuprados):
1. Linear e aditivo: Se você ajustar um modelo linear a um conjunto de dados não lineares não aditivos, o algoritmo de regressão não capturaria a tendência matematicamente, o que resultaria em um modelo ineficiente. O que mais, isso resultará em previsões erradas em um conjunto de dados invisível.
Como verificar: Procure gráficos de valor residual vs ajustado (explicado abaixo). O que mais, pode incluir termos polinomiais (X, X², X³) em seu modelo para capturar o efeito não linear.
2. Autocorrelação: A presença de correlação em termos de erro reduz drasticamente a precisão do modelo. Isso geralmente acontece em modelos de série temporal onde o próximo instante depende do instante anterior. Se os termos de erro estão correlacionados, erros padrão estimados tendem a subestimar o verdadeiro erro padrão.
Se isso acontecer, torna os intervalos de confiança e os intervalos de previsão mais estreitos. Um intervalo de confiança mais estreito significa que um intervalo de confiança do 95% teria uma probabilidade menor que 0,95 para conter o valor real dos coeficientes. Vamos entender intervalos de predição estreitos com um exemplo:
Por exemplo, o coeficiente de mínimos quadrados de X¹ é 15.02 e seu erro padrão é 2.08 (sem autocorrelação). Mas na presença de autocorrelação, o erro padrão é reduzido a 1,20. Como resultado, o intervalo de predição é reduzido para (13.82, 16.22) a partir de (12.94, 17.10).
O que mais, erros padrão mais baixos tornariam os valores p associados mais baixos do que os reais. Isso nos levará a concluir incorretamente que um parâmetro é estatisticamente significativo..
Como verificar: Procure a estatística Durbin-Watson (DW). Deve ser entre 0 e 4. Se DW = 2, não implica autocorrelação, 0 <DW <2 implica autocorrelação positiva enquanto 2 <DW <4 indica autocorrelação negativa. O que mais, você pode ver o gráfico residual em função do tempo e procurar o padrão sazonal ou correlacionado nos resíduos.
3. Multicolinearidade: Este fenômeno existe quando as variáveis independentes são encontradas para ter uma correlação moderada ou alta. Em um modelo com variáveis correlacionadas, torna-se uma tarefa difícil descobrir a verdadeira relação de um preditor com uma variável de resposta. Em outras palavras, difícil descobrir qual variável realmente contribui para prever a variável de resposta.
Outro ponto, com a presença de preditores correlacionados, erros padrão tendem a aumentar. E, com grandes erros padrão, o intervalo de confiança torna-se maior, levando a estimativas menos precisas dos parâmetros de inclinação.
O que mais, quando os preditores são correlacionados, o coeficiente de regressão estimado de uma variável correlacionada depende de quais outros preditores estão disponíveis no modelo. Se isso acontecer, você vai acabar com uma conclusão incorreta de que uma variável afeta fortemente / fracamente para a variável alvo. Dado que, mesmo se você remover uma variável correlacionada do modelo, seus coeficientes de regressão estimados mudariam. Isso não é bom!
Como verificar: Você pode usar o gráfico de dispersão para visualizar o efeito de correlação entre as variáveis. O que mais, você também pode usar o fator VIF. O valor de VIF = 10 implica séria multicolinearidade. Sobre tudo, uma tabela de correlação também deve resolver o propósito.
4. Heteroscedasticidade: A presença de variância não constante nos termos de erro resulta em heterocedasticidade. Geralmente, a variância não constante surge na presença de outliers ou valores de alavancagem extremos. Esses valores parecem ter muito peso, então eles influenciam desproporcionalmente o desempenho do modelo. Quando esse fenômeno ocorre, o intervalo de confiança para previsão fora da amostra tende a ser irrealisticamente amplo ou estreito.
Como verificar: Você pode ver o gráfico de resíduos vs ajustados. Se houver heterocedasticidade, o gráfico exibirá um padrão em forma de funil (mostrado na próxima seção). O que mais, você pode usar o teste Breusch-Pagan / cozinhar – Teste geral de Weisberg ou White para detectar este fenômeno.
5. Distribuição normal de termos de erro: Se os termos de erro não forem distribuídos normalmente, os intervalos de confiança podem se tornar muito largos ou muito estreitos. Uma vez que o intervalo de confiança se torna instável, a estimativa de coeficientes com base na minimização de mínimos quadrados é difícil. A presença de uma distribuição anormal sugere que existem alguns pontos de dados incomuns que precisam ser estudados de perto para fazer um modelo melhor..
Como verificar: Você pode ver o gráfico QQ (mostrado abaixo). Você também pode realizar testes estatísticos de normalidade, como o teste de Kolmogorov-Smirnov., o teste de Shapiro-Wilk.
Interpretação de gráficos de regressão
Até aqui, Aprendemos sobre importantes suposições de regressão e métodos para empreender, se essas suposições forem violadas.
Mas isso não é o fim. Agora, você deve conhecer as soluções também para lidar com a violação dessas suposições. Nesta secção, Eu expliquei o 4 gráficos de regressão junto com métodos para superar as limitações das suposições.
1. Valores residuais vs. valores ajustados
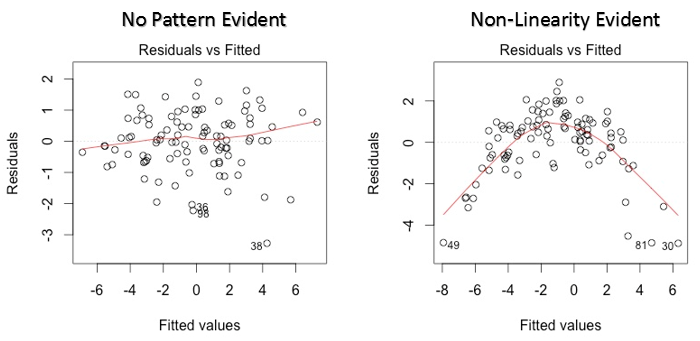
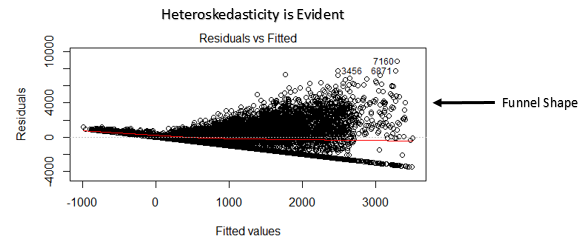
Este gráfico de dispersão mostra a distribuição dos resíduos (erros) versus valores ajustados (valores preditos). É uma das tramas mais importantes que todos deveriam aprender. Revela vários insights úteis, incluindo outliers. Os outliers neste gráfico são rotulados por seu número de observação, o que os torna fáceis de identificar.
Existem duas coisas importantes que você deve aprender:
- Se houver algum padrão (pode ser, uma forma parabólica) neste gráfico, considerá-lo como sinais de não linearidade nos dados. Isso significa que o modelo não captura efeitos não lineares.
- Se a forma de um funil é evidente no gráfico, considere isso como um sinal de variância não constante, quer dizer, heterocedasticidade.
Solução: Para superar o problema da não linearidade, você pode fazer uma transformação não linear de preditores como log (X), √X ou X² transformam a variável dependente. Para superar a heterocedasticidade, uma maneira possível é transformar a variável de resposta em log (E) o √Y. O que mais, você pode usar o método dos mínimos quadrados ponderados para lidar com a heterocedasticidade.
2. Gráfico QQ normal
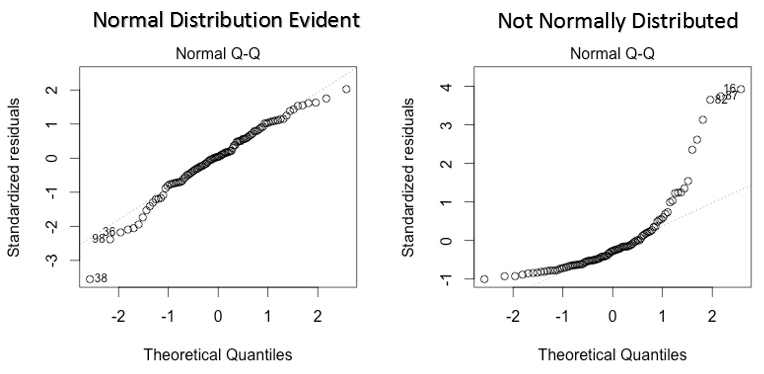
Este qq ou quantil-quantil é um diagrama de dispersão que nos ajuda a validar a suposição de distribuição normal em um conjunto de dados. Usando este gráfico, podemos inferir se os dados vêm de uma distribuição normal. Em caso afirmativo, o gráfico mostraria uma linha bastante reta. Há ausência de normalidade nos erros com desvio em linha reta.
Se você quer saber o que é um 'quantil', aqui está uma definição simples: pense em quantis como pontos em seus dados abaixo dos quais uma certa proporção de dados cai. O quantil é frequentemente chamado de percentis. Por exemplo: quando dizemos que o valor percentual 50 isto é 120, significa que metade dos dados está abaixo 120.
Solução: Se os erros não forem distribuídos normalmente, a transformação não linear das variáveis (resposta ou preditores) pode trazer uma melhoria no modelo.
3. Gráfico de localização da escala
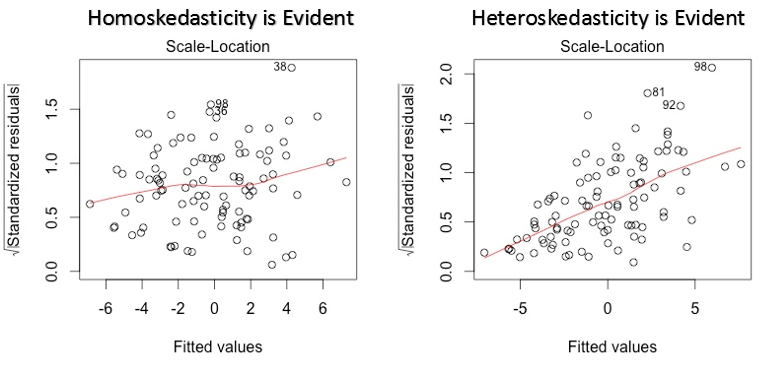
Este gráfico também é usado para detectar homocedasticidade (suposição de variância igual). Mostra como os resíduos são distribuídos em todo o intervalo de preditores.. É semelhante ao gráfico de valor residual vs ajustado, exceto que usa valores residuais padronizados. Idealmente, não deve haver nenhum padrão discernível no gráfico. Isso implicaria que os erros são normalmente distribuídos. Mas, caso o gráfico mostre algum padrão discernível (provavelmente em forma de funil), implicaria em uma distribuição de erro não normal.
Solução: Siga a solução para heterocedasticidade dada no gráfico 1.
4. Gráfico residual x alavancagem
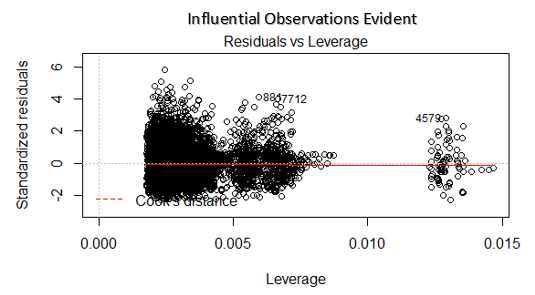
Também conhecido como diagrama de distância de Cook. A distância de Cook tenta identificar os pontos que têm mais influência do que outros pontos. Esses pontos de influência tendem a ter um impacto considerável na linha de regressão.. Em outras palavras, adicionar ou remover tais pontos do modelo pode mudar completamente as estatísticas do modelo.
Mas, Essas observações influentes podem ser tratadas como discrepantes?? Esta pergunta só pode ser respondida depois de olhar os dados. Portanto, neste gráfico, grandes valores marcados pela distância de cozimento podem exigir uma investigação mais aprofundada.
Solução: Para influenciar observações que nada mais são do que outliers, sim não muitos, você pode deletar essas linhas. alternativamente, você pode reduzir a observação de outliers com o valor máximo nos dados ou tratar esses valores como valores ausentes.
Caso de estudo: Como melhorei meu modelo de regressão usando transformação logarítmica
Notas finais
Você pode aproveitar o verdadeiro poder da análise de regressão aplicando as soluções descritas acima.. Implementar essas correções no R é muito fácil. Se você quiser saber alguma solução específica em R, Você pode deixar um comentário, Terei todo o gosto em ajudá-lo com as respostas..
O objetivo deste artigo foi ajudá-lo a obter uma visão e perspectiva subjacentes das suposições e diagramas de regressão.. Desta maneira, você terá mais controle sobre sua análise e pode modificar a análise de acordo com suas necessidades.
Você achou este artigo útil? Você usou essas correções para melhorar o desempenho do modelo? Compartilhe sua experiência / sugestões nos comentários.





