Introdução
"Se você falar com um homem em uma língua que ele entenda, vai para a cabeça dele. Se você falar com ele em sua própria língua, alcançará seu coração “. – Nelson Mandela
A beleza da linguagem transcende fronteiras e culturas. Aprender uma língua diferente da nossa língua materna é uma grande vantagem. Mas o caminho para o bilinguismo, ou multilinguismo, muitas vezes pode ser longo e interminável.
São tantas pequenas nuances que nos perdemos no mar de palavras. Porém, as coisas ficaram muito mais fáceis com os serviços de tradução online (Estou olhando para você google tradutor!).
Sempre quis aprender uma língua diferente do inglês. Eu tentei aprender alemão (o alemão) sobre 2014. Foi divertido e desafiador. Eu finalmente tive que desistir, mas eu nutria o desejo de recomeçar.

Avançar para 2019, Tenho a sorte de ser capaz de construir um tradutor de idiomas para qualquer par de idiomas possível. Que grande benefício o processamento de linguagem natural tem sido!!
Neste artigo, Discutiremos as etapas para criar um modelo de tradução do alemão para o inglês usando Keras. Também daremos uma olhada rápida na história dos sistemas de tradução automática com o benefício de uma retrospectiva..
Este artigo pressupõe familiaridade com RNN, LSTM e Keras. Abaixo estão alguns artigos para ler mais sobre eles:
Tabela de conteúdo
- Tradução automática: Uma breve história
- Compreendendo a declaração do problema
- Introdução à previsão de sequência por sequência
- Implementação em Python usando Keras
Tradução automática: Uma breve história
A maioria de nós conheceu a tradução automática quando o Google lançou o serviço. Mas o conceito existe desde meados do século passado.
Trabalho de pesquisa em tradução automática (MT) começou já na década de 1950, principalmente nos Estados Unidos. Esses primeiros sistemas eram baseados em enormes dicionários bilíngues, regras codificadas manualmente e princípios universais subjacentes à linguagem natural.
Sobre 1954, IBM fez uma primeira demonstração pública de uma tradução automática. O sistema tinha um vocabulário bastante pequeno de apenas 250 palavras e só poderia traduzir 49 frases selecionadas do russo para o inglês. O número parece minúsculo agora, mas o sistema é amplamente considerado um marco importante no progresso da tradução automática.

Esta imagem foi tirada de trabalho de investigação descrevendo o sistema IBM
Duas escolas de pensamento logo surgiram:
- Abordagens de tentativa e erro empíricas, usando métodos estatísticos, e
- Abordagens teóricas envolvendo pesquisa lingüística fundamental
Sobre 1964, o governo dos Estados Unidos estabeleceu o Comitê Consultivo de Processamento Automático de Linguagem (ALPAC) para avaliar o progresso da tradução automática. ALPAC insistiu um pouco e publicou um relatório em novembro 1966 no status MT. Abaixo estão os destaques desse relatório:
- Ele levantou sérias dúvidas sobre a viabilidade da tradução automática, chamando-a de desesperada.
- O financiamento para a pesquisa da MT foi desencorajado
- Foi um relatório bastante deprimente para os pesquisadores que trabalham neste campo..
- A maioria deles deixou o campo e começou novas carreiras.
Não é exatamente uma recomendação brilhante!!
Um longo período de seca seguiu-se a este lamentável relatório. Finalmente, sobre 1981, um novo sistema chamado Sistema WEATHER implantado no Canadá para a tradução das previsões meteorológicas publicadas em francês para inglês. Foi um projeto bastante bem-sucedido que permaneceu em operação até 2001.
A primeira ferramenta de tradução da web do mundo, Peixe babel, foi lançado pelo motor de busca AltaVista em 1997.
E então veio a descoberta com a qual todos estamos familiarizados agora: Google Tradutor. Desde então, mudou a maneira como trabalhamos (e incluso aprendemos) com línguas diferentes.
Fonte: translate.google.com
Compreendendo a declaração do problema
Vamos voltar para onde paramos na seção de introdução, quer dizer, aprender alemão. Porém, desta vez vou fazer minha máquina fazer esta tarefa. O objetivo é converter uma frase em alemão em sua contraparte em inglês usando um sistema de tradução automática neural. (NMT).

Usaremos dados de pares de frases alemão-inglês de http://www.manythings.org/anki/. Você pode baixá-lo de aqui.
Introdução à modelagem sequência a sequência (Seq2Seq)
Modelos de sequência a sequência (seq2seq) são usados para uma variedade de tarefas de PNL, como um resumo de texto, reconhecimento de voz, Modelagem de sequência de DNA, entre outras. Nosso objetivo é traduzir determinadas frases de um idioma para outro.
Aqui, tanto a entrada quanto a saída são frases. Em outras palavras, essas frases são uma sequência de palavras que entram e saem de um padrão. Esta é a ideia básica da modelagem sequência por sequência.. A figura a seguir tenta explicar este método.
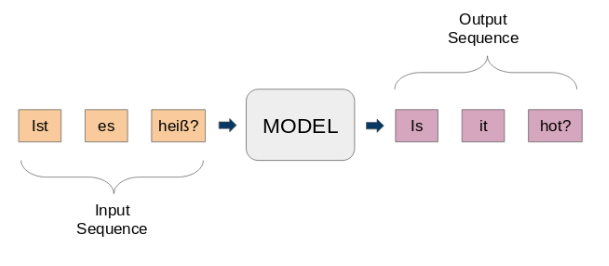
Um modelo típico seq2seq tem 2 componentes principais:
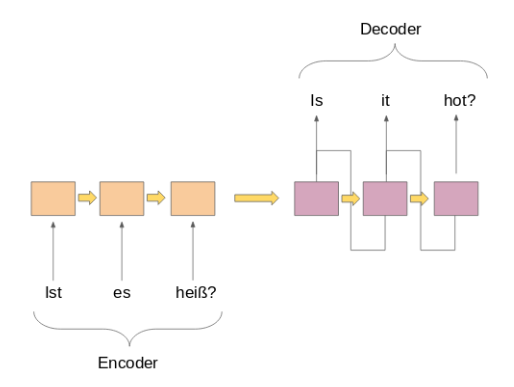
uma) um codificador
b) um decodificador
Ambas as partes são essencialmente dois modelos diferentes de redes neurais recorrentes (RNN) combinados em uma rede gigante:
Listei alguns casos de uso importantes de modelagem sequência por sequência abaixo (além da tradução automática, claro):
- Reconhecimento de voz
- Extração de entidade / assunto do nome para identificar o tópico principal de um corpo de texto
- Classificação de relacionamento para rotular relacionamentos entre várias entidades rotuladas na etapa anterior
- Habilidades de chatbot para ter capacidade de conversação e interagir com os clientes
- Resumo do texto para gerar um resumo conciso de uma grande quantidade de texto
- Sistemas de resposta de perguntas
Implementação em Python usando Keras
É hora de sujar as mãos!! Não há melhor sentimento do que aprender um tópico vendo os resultados em primeira mão. Vamos começar nosso ambiente Python favorito (Caderno Jupyter para mim) e vamos começar a trabalhar.
Importe as bibliotecas necessárias
import string import re from numpy import array, argmax, aleatória, take import pandas as pd from keras.models import Sequential from keras.layers import Dense, LSTM, Embedding, RepeatVector from keras.preprocessing.text import Tokenizer from keras.callbacks import ModelCheckpoint from keras.preprocessing.sequence import pad_sequences from keras.models import load_model from keras import optimizers import matplotlib.pyplot as plt %matplotlib inline pd.set_option('display.max_colwidth', 200)
Leia os dados em nosso IDE
Nossos dados são um arquivo de texto (.Txt) de pares de sentenças inglês-alemão. Primeiro, vamos ler o arquivo usando a função definida abaixo.
# function to read raw text file def read_text(nome do arquivo): # open the file file = open(nome do arquivo, modo="Rt", codificação = 'utf-8') # read all text text = file.read() file.close() texto de retorno
Vamos definir outra função para dividir o texto em pares inglês-alemão separados por ‘ n ’. Mais tarde, vamos dividir esses pares em frases inglesas e sentenças alemãs, respectivamente.
# split a text into sentences
def to_lines(texto):
sents = text.strip().dividir('n')
enviados = [i.split('t') para i em enviados]
enviar retorno
Agora podemos usar essas funções para ler o texto em uma matriz em nosso formato desejado.
data = read_text("deu.txt")
deu_eng = to_lines(dados)
deu_eng = array(deu_eng)
Os dados reais contêm mais de 150.000 pares de frases. Porém, vamos usar apenas o primeiro 50,000 pares de frases para reduzir o tempo de treinamento do modelo. Você pode alterar este número de acordo com o poder de computação do seu sistema (Ou se você se sentir com sorte!).
deu_eng = deu_eng[:50000,:]
Pré-processamento de texto
Uma etapa muito importante em qualquer projeto, especialmente em PNL. Os dados com os quais trabalhamos geralmente não são estruturados, então, há certas coisas que precisamos cuidar antes de passar para a parte de construção do modelo.
(uma) Limpeza de texto
Vamos dar uma olhada em nossos dados primeiro. Isso nos ajudará a decidir quais etapas de pré-processamento tomar.
deu_eng
variedade([['Oi.', 'Olá!'],
['Oi.', 'Dia bom!'],
['Corre!', 'Corre!'],
...,
['Mary tem cabelo muito comprido.', "Maria tem cabelo muito comprido."],
["Mary é a secretária de Tom.", "Maria é a secretária de Tom."],
['Mary é uma mulher casada.', "Maria é uma mulher casada."]],
dtype ="<U380")
Nos desharemos de los signos de puntuación y luego convertiremos todo el texto a minúsculas.
# Remove punctuation
deu_eng[:,0] = [s.traduzir(str.maketrans('', '', string.punctuation)) para s em deu_eng[:,0]]
deu_eng[:,1] = [s.traduzir(str.maketrans('', '', string.punctuation)) para s em deu_eng[:,1]]
deu_eng
variedade([['Oi', 'Hallo'],
['Oi', 'Grüß Gott'],
['Corra', 'Lauf'],
...,
['Mary tem cabelo muito comprido', 'Maria hat sehr langes Haar'],
[Mary é secretária de Toms., 'Maria ist Toms Sekretärin'],
[Mary é uma mulher casada., 'Maria ist eine verheiratete Frau']],
dtype ="<U380")
# convert text to lowercase
for i in range(len(deu_eng)):
deu_eng[eu,0] deu_eng[eu,0].diminuir()
deu_eng[eu,1] deu_eng[eu,1].diminuir()
deu_eng
variedade([['Oi', 'hallo'],
['Oi', 'grüß gott'],
['correr', 'lauf'],
...,
['Mary tem cabelo muito comprido', 'maria hat sehr langes haar'],
['Mary é secretária toms', 'maria ist toms sekretärin'],
['Mary é uma mulher casada', 'maria ist eine verheiratete frau']],
dtype ="<U380")
(b) Conversión de texto a secuencia
Um modelo Seq2Seq requer que convertamos sentenças de entrada e saída em sequências de inteiros de comprimento fixo.
Mas antes de fazer isso., vamos visualizar o comprimento das frases. Vamos capturar o comprimento de todas as frases em duas listas separadas para inglês e alemão, respectivamente.
# empty lists eng_l = [] deu_l = [] # populate the lists with sentence lengths for i in deu_eng[:,0]: eng_l.append(len(i.split())) para i em deu_eng[:,1]: deu_l.append(len(i.split())) length_df = pd. DataFrame({'eng':eng_l, 'deu':deu_l}) length_df.hist(bins = 30) plt.show()
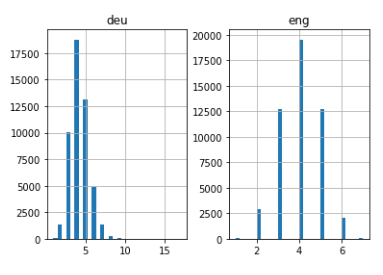
Bastante intuitivo: o comprimento máximo das sentenças em alemão é 11 e a das frases em inglês é 8.
A seguir, vetorizar nossos dados de texto usando Keras Tokenizador () classe. Converta nossas frases em sequências de inteiros. Então podemos preencher essas sequências com zeros para fazer todas as sequências do mesmo comprimento..
Por favor, note que vamos preparar tokenizadores para frases em alemão e inglês:
# function to build a tokenizer
def tokenization(linhas):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(linhas)
tokenizador de retorno
# prepare english tokenizer
eng_tokenizer = tokenization(deu_eng[:, 0])
eng_vocab_size = len(eng_tokenizer.word_index) + 1
eng_length = 8
imprimir('Tamanho do vocabulário español: %d ' % eng_vocab_size)
Tamanho do vocabulário español: 6453
# prepare Deutch tokenizer
deu_tokenizer = tokenization(deu_eng[:, 1])
deu_vocab_size = len(deu_tokenizer.word_index) + 1
deu_length = 8
imprimir('Deutch Tamanho do vocabulário: %d ' % deu_vocab_size)
Tamanho do vocabulário deutch: 10998
o seguinte bloco de código contém uma função para preparar as sequências. Ele também executará sequência preenchendo até um comprimento máximo de sentença como mencionado acima.
# encode and pad sequences def encode_sequences(tokenizer, comprimento, linhas): # integer encode sequences seq = tokenizer.texts_to_sequences(linhas) # sequências de almofada com 0 values seq = pad_sequences(seq, maxlen=comprimento, padding = 'post') retorno seq
Construção do modelo
Agora dividiremos os dados em treinamento e teste definido para treinamento e avaliação de modelos, respectivamente.
de sklearn.model_selection import train_test_split
# split data into train and test set
train, test = train_test_split(deu_eng, test_size = 0.2, random_state = 12)
É hora de codificar frases. Vamos codificar Frases alemãs como sequências de entrada e Frases em inglês como sequências de destino. isso deve ser feito tanto para o trem e os conjuntos de dados de teste.
# prepare training data trainX = encode_sequences(deu_tokenizer, deu_length, Comboio[:, 1]) trainY = encode_sequences(eng_tokenizer, eng_length, Comboio[:, 0]) # prepare validation data testX = encode_sequences(deu_tokenizer, deu_length, teste[:, 1]) testY = encode_sequences(eng_tokenizer, eng_length, teste[:, 0])
Agora vem a parte emocionante!!
Começaremos definindo nossa arquitetura de modelo Seq2Seq:
- Para o codificador, usaremos uma camada de incorporação e uma camada LSTM
- Para o set-top box, usaremos outra camada LSTM seguida por uma camada densa

Arquitetura de modelos
# build NMT model
def define_model(in_vocab,out_vocab, in_timesteps,out_timesteps,Unidades):
modelo = Sequencial()
model.add(Embedding(in_vocab, Unidades, input_length=in_timesteps, mask_zero=True))
model.add(LSTM(Unidades))
model.add(Repetitivo(out_timesteps))
model.add(LSTM(Unidades, return_sequences = True))
model.add(Denso(out_vocab, ativação = 'softmax'))
modelo de retorno
Estamos usando o otimizador RMSprop neste modelo, como geralmente é uma boa opção ao trabalhar com redes neurais recorrentes.
# model compilation
model = define_model(deu_vocab_size, eng_vocab_size, deu_length, eng_length, 512)
rms = otimizadores. RMSprop(lr=0,001) model.compile(otimizador=rms, perda ="sparse_categorical_crossentropy")
Solicitamos atenção no uso das informações fornecidas. ‘sparse_categorical_crossentropy'como a função de perda. Isso ocorre porque a função nos permite usar a sequência de destino como ela é., em vez do formato de código quente. Codificar as sequências alvo usando um vocabulário tão grande pode consumir toda a memória do nosso sistema.
Estamos prontos para começar a treinar nosso modelo!
Vamos treiná-lo durante 30 vezes e com um tamanho de lote de 512 com uma divisão de validação do 20%. o 80% dos dados serão usados para treinar o modelo e o resto para avaliá-lo. Você pode alterar e brincar com esses hiperparâmetros.
Também usaremos o ModelCheckpoint () função para salvar o modelo com a menor perda de validação. Eu pessoalmente prefiro este método para a parada inicial.
nome do arquivo ="model.h1.24_jan_19"
ponto de verificação de ponto de verificação de modelo(nome do arquivo, monitor="val_loss", verbose = 1, save_best_only = True, modo="min")
# train model
history = model.fit(trainX, trainY.remodele(trainY.shape[0], trainY.shape[1], 1),
épocas=30, batch_size=512, validation_split = 0,2,retornos de chamada=[Ponto de verificação],
verbose = 1)
Vamos comparar a perda de treinamento e a perda de validação.
plt.plot(história.história['perda']) plt.plot(história.história['val_loss']) plt.legend(['Comboio','validação']) plt.show()
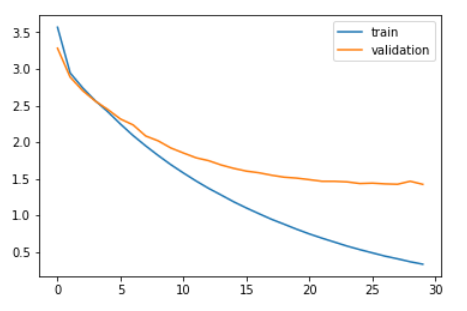
Como você pode ver no gráfico acima, a perda de validação parou de diminuir depois 20 épocas.
Finalmente, podemos carregar o modelo salvo e fazer previsões sobre os dados invisíveis: testX.
modelo = load_model('model.h1.24_jan_19')
preds = model.predict_classes(testX.remodele((testX.shape[0],testX.shape[1])))
Estas previsões são sequências de inteiros. Precisamos converter esses inteiros em suas palavras correspondentes. Vamos definir uma função para fazer isso:
def get_word(n, tokenizer):
por palavra, índice em tokenizer.word_index.itens():
se índice == n:
return word
return None
Converter previsões em texto (inglês):
preds_text = []
para i em preds:
temp = []
para j no intervalo(len(eu)):
t = get_word(eu[j], eng_tokenizer)
se j > 0:
E se (t == get_word(eu[j-1], eng_tokenizer)) ou (t == Nenhum):
temp.append('')
outro:
temp.append else:
E se(t == Nenhum):
temp.append('')
outro:
temp.append
preds_text.append(' '.Junte(temp))
Vamos colocar as frases originais em inglês no conjunto de dados do teste e as frases previstas em um quadro de dados:
pred_df = pd. DataFrame({'atual' : teste[:,0], 'previsto' : preds_text})
Podemos imprimir aleatoriamente algumas instâncias reais versus as planejadas para ver como nosso modelo funciona:
# imprimir 15 rows randomly
pred_df.sample(15)
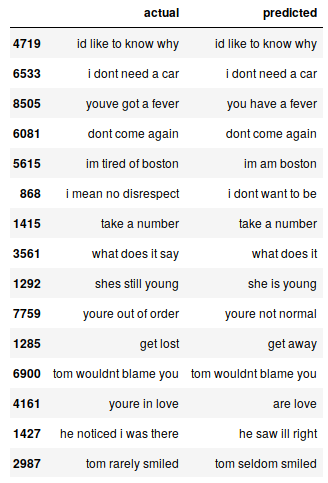
Nosso modelo Seq2Seq faz um trabalho decente. Mas há vários casos em que você perde o entendimento sobre palavras-chave. Por exemplo, isso traduz “estou cansado de boston” por “eu sou de boston”.
Estes são os desafios que você enfrentará regularmente na PNL. Mas estes não são obstáculos imóveis. Podemos mitigar esses desafios usando mais dados de treinamento e construindo um modelo melhor. (ou mais complexo).
Você pode acessar o código completo neste Github repositório.
Notas finais
Mesmo com um modelo Seq2Seq muito simples, Os resultados são bastante encorajadores. Podemos melhorar facilmente esse desempenho usando um modelo de codec mais sofisticado em um conjunto de dados maior..
Outro experimento em que posso pensar é testar a abordagem seq2seq em um conjunto de dados que contém frases mais longas. Quanto mais eu experimento, mais você aprenderá sobre este vasto e complexo espaço.
Se você tiver algum comentário sobre este artigo ou perguntas / pergunta, por favor, compartilhe na seção de comentários abaixo.





