O que são anomalias e como detectá-las? Que impacto isso tem sobre os dados?
Introdução
As anomalias são os diferentes pontos do estado normal de existência. Isso é algo que pode surgir devido a diferentes circunstâncias com base nos vários fatores que afetam você.. Por exemplo, tumores que se desenvolvem devido a algumas doenças, como quando uma pessoa é diagnosticada com câncer, mais células se desenvolvem sem qualquer limite.
Da mesma forma, Ao obtermos esses dados, devemos analisar e detectar essas anomalias para que o tratamento seja mais fácil e saibamos quais ações tomar. Quando tais anomalias ocorrem na indústria automotiva, como quando as vendas de um determinado carro ou outros veículos de transporte são altas ou baixas. Portanto, é uma anomalia de todos os dados. As anomalias nada mais são do que outliers nos dados.
Como você detecta outliers ou quais são os métodos usados para detectar anomalias?
1. Use a visualização de dados (Como fazer uso de plotagens de caixaDiagramas de caixa, Também conhecido como diagramas de caixa e bigode, são ferramentas estatísticas que representam a distribuição de um conjunto de dados. Esses diagramas mostram a mediana, Quartis e outliers, permitindo que a variabilidade e a simetria dos dados sejam visualizadas. Eles são úteis na comparação entre diferentes grupos e na análise exploratória, facilitando a identificação de tendências e padrões nos dados...., diagramas de violino, etc.)
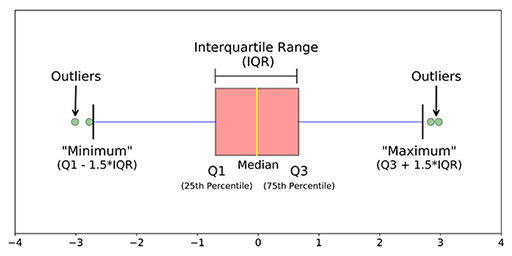
2. Use métodos estatísticos, como métodos de quantis (IQR, T1, 3º T), encontre o mínimo, o máximo e o medianaA mediana é uma medida estatística que representa o valor central de um conjunto de dados ordenados. Para calculá-lo, Os dados são organizados do menor para o maior e o número no meio é identificado. Se houver um número par de observações, Os dois valores principais são calculados em média. Este indicador é especialmente útil em distribuições assimétricas, uma vez que não é afetado por valores extremos.... dos dados, a pontuação Z, etc.
3. Algoritmos ML como IsolationForest, LocalOutlierFactor, OneClassSVM, Envelope elíptico ... etc.
1. Visualização de dados: Quando um recurso é plotado usando ferramentas de visualização como o mar, matplotlib, plotly ou outro software como Tableau, PowerBI, Qlik Sense, Excel, Palavra, … etc., temos uma ideia dos dados e sua contagem nos dados e também conhecemos as anomalias principalmente usando gráficos de caixa, diagramas de violino, diagramas de dispersão.
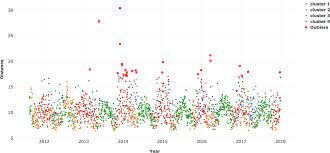
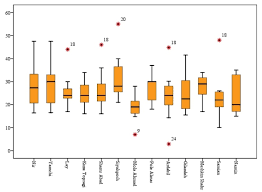
2. Métodos estatísticos: Quando você encontra a média dos dados, pode não fornecer o valor médio correto quando há anomalias nos dados. Quando há anomalias nos dados, a mediana dá um valor correto do que a média porque a mediana ordena os valores e encontra a posição do meio nos dados, enquanto a média apenas calcula a média dos valores nos dados. Para descobrir outliers no lado esquerdo e direito dos dados, use Q3 + 1.5 (IQR), T1-1.5 (IQR). O que mais, ao encontrar o máximo, o mínimo e a mediana dos dados, pode dizer se anomalias estão presentes nos dados ou não.
3. Algoritmos ML: O benefício de usar algoritmos não supervisionados para detecção de anomalias é que podemos encontrar anomalias para várias variáveis ou características ou preditores nos dados ao mesmo tempo, em vez de separadamente para variáveis individuais.. Também pode ser feito de ambas as maneiras, chamado detecção de anormalidade univariada e detecção de anormalidade multivariada.
uma. Floresta de isolamento: Esta é uma técnica não supervisionada para detectar anomalias quando não há rótulos ou valores verdadeiros. Seria uma tarefa complexa verificar cada linha dos dados para detectar aquelas linhas que podem ser consideradas anomalias.
Isolation Forest é um modelo baseado em árvore. As árvores formadas para isso não são as mesmas feitas nas árvores de decisão. Árvores de decisão e florestas de isolamento são diferentes formas de construção. O que mais, Mais uma diferença principal é que a árvore de decisão é um algoritmo de aprendizagem supervisionadaO aprendizado supervisionado é uma abordagem de aprendizado de máquina em que um modelo é treinado usando um conjunto de dados rotulados. Cada entrada no conjunto de dados está associada a uma saída conhecida, permitindo que o modelo aprenda a prever resultados para novas entradas. Este método é amplamente utilizado em aplicações como classificação de imagens, Reconhecimento de fala e previsão de tendências, destacando sua importância em... e a floresta de isolamento é um algoritmo de Aprendizado não supervisionadoO aprendizado não supervisionado é uma técnica de aprendizado de máquina que permite que os modelos identifiquem padrões e estruturas em dados sem rótulos predefinidos. Por meio de algoritmos como k-means e análise de componentes principais, Essa abordagem é usada em uma variedade de aplicações, como segmentação de clientes, detecção de anomalias e compactação de dados. Sua capacidade de revelar informações ocultas o torna uma ferramenta valiosa no....
Nessas árvores de isolamento, As partições são criadas selecionando primeiro aleatoriamente um recurso ou variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... e, em seguida, selecionando um valor de divisão aleatória entre o valor mínimo e máximo do recurso selecionado. Novamente, a nóO Nodo é uma plataforma digital que facilita a conexão entre profissionais e empresas em busca de talentos. Através de um sistema intuitivo, permite que os usuários criem perfis, Compartilhar experiências e acessar oportunidades de trabalho. Seu foco em colaboração e networking torna o Nodo uma ferramenta valiosa para quem deseja expandir sua rede profissional e encontrar projetos que se alinhem com suas habilidades e objetivos.... root é selecionado aleatoriamente sem quaisquer condições para ser um nó raiz como acontece na árvore de decisão. O nó raiz é selecionado aleatoriamente a partir das variáveis nos dados, então algum valor aleatório é tomado que está entre o máximo e o mínimo daquela característica particular.
A pontuação de anomalia de uma amostra de entrada é calculada como a pontuação de anomalia média das árvores na floresta de isolamento. Mais tarde, a pontuação de anomalia é calculada para cada variável após ajustar todos os dados ao modelo. Quando a pontuação da anomalia aumenta, há uma grande probabilidade de que seja uma anomalia do que a linha com a pontuação de anomalia mais baixa. Existem três funções neste algoritmo que facilitam a exibição e o armazenamento de pontuações usando as poucas linhas de código fornecidas abaixo.:
from sklearn.ensemble import IsolationForest
isolation_forest = IsolationForest(n_estimators=1000, contaminação=0,08)
isolation_forest.fit(df['Taxa'].values.reshape(-1, 1))
df['anomaly_score_rate'] = isolation_forest.decision_function(df['taxa'].values.reshape(-1, 1))
df['outlier_univariate_rate'] = isolation_forest.predict(df['taxa'].values.reshape(-1, 1))
Aqui, o parâmetro de contaminação desempenha um papel importante na detecção de mais anomalias. Contaminação é a porcentagem de valores que você está dando ao algoritmo que há tanta porcentagem de anomalias nos dados. Por exemplo: quando ele deu 0,10 como um valor de poluição, os algoritmos consideram que existe um 10% de anomalias de dados. Encontrando a contaminação ideal, você será capaz de detectar anomalias com um bom número.
Quando você deseja realizar a detecção de anomalias multivariadas, você deve primeiro normalizar os valores nos dados para que o algoritmo possa fornecer previsões corretas. o padronizaçãoA padronização é um processo fundamental em várias disciplinas, que busca estabelecer padrões e critérios uniformes para melhorar a qualidade e a eficiência. Em contextos como engenharia, Educação e administração, A padronização facilita a comparação, Interoperabilidade e compreensão mútua. Ao implementar normas, a coesão é promovida e os recursos são otimizados, que contribui para o desenvolvimento sustentável e a melhoria contínua dos processos.... o A padronização é essencial quando se trata de valores contínuos.
minmax = MinMaxScaler(feature_range =(0, 1)) X = minmax.fit_transform(df[['taxa','pontuações']]) clf = IsolationForest(n_estimators = 100, contaminação = 0,01, random_state = 0) clf.fit(X) df['multivariate_anomaly_score'] = clf.decision_function(X) df['multivariate_outlier'] = clf.predict(X)
Para saber mais vá para floresta de isolamento sklearn
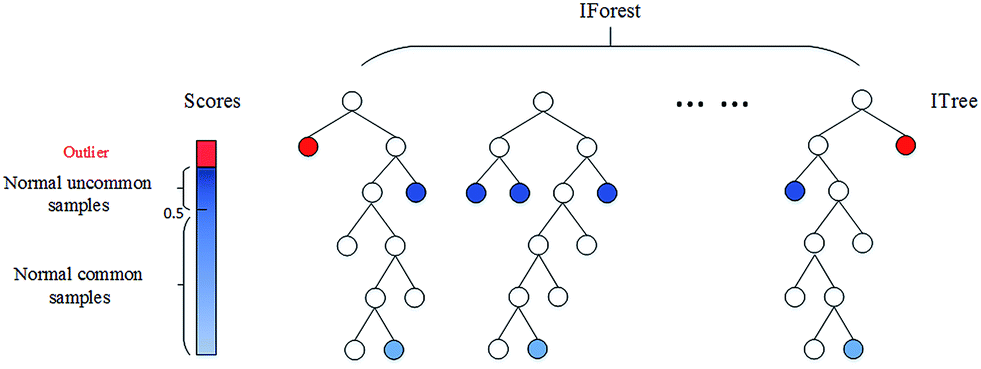
A imagem acima corresponde a: https://pubs.rsc.org/en/content/articlelanding/2016/ay/c6ay01574c#!divAbstract
B. LocalOutlierFactor: Este também é um algoritmo não supervisionado e não é baseado em árvore, mas algoritmo baseado em densidade como KNN, Kmeans. Quando qualquer ponto de dados é considerado um outlier dependendo da sua vizinhança local, é um outlier local. LOF irá identificar um outlier considerando a densidade do vizinho. LOF funciona bem quando a densidade do ponto de dados não é constante em todo o conjunto de dados.
Existem dois tipos de detecção que são realizados com este algoritmo. Eles são detecção de outlier e detecção de novidade, onde a detecção de outlier não é supervisionada e a detecção de novidade é semi-supervisionada, uma vez que usa os dados do trem para fazer suas previsões sobre os dados de teste, embora os dados do trem não contenham previsões exatas.
Até LocalOutlierFactor usa o mesmo código, portanto, o código é usado apenas para detecção de novidade quando o parâmetro novidade é True neste modelo. Quando seu valor padrão é False, a detecção de outlier seria usada onde o único fit_predict funcionasse. Quando a novidade = Verdadeira, esta função está desabilitada.
Abaixo está o código para encontrar anomalias usando o algoritmo de outlier local
minmax = MinMaxScaler(feature_range =(0, 1)) X = minmax.fit_transform(df[['taxa','pontuações']]) # Novelty detection clf = LocalOutlierFactor(n_neighbors=100, contaminação=0,01,novidade=True) #when novelty = True clf.fit(X_train) df['multivariate_anomaly_score'] = clf.decision_function(X_test) df['multivariate_outlier'] = clf.predict(X_test) # Outlier detection local_outlier_factor_multi=LocalOutlierFactor(n_neighbors=15,contaminação=0.20.n_jobs=-1) # when novelty = False multi_pred=local_outlier_factor_multi.fit_predict(X) df1['Multivariate_pred']=multi_pred
Para saber mais sobre isso, consulte Fator outlier local de Sklearn
C. SVM de uma classe: Existe um SVM supervisionado que lida com tarefas de regressão e classificação. Aqui está um SVM de classe única não supervisionado, já que os rótulos são desconhecidos. SVMs de uma classe são um tipo especial de máquina de vetores de suporte. Primeiro, os dados são modelados e o algoritmo é treinado. Mais tarde, quando novos dados são encontrados, sua posição em relação aos dados normais (o inliers) o treinamento pode ser usado para determinar se você está fora da classe ou não. Como eles podem ser treinados com dados não rotulados ou sem variáveis de destino, são um exemplo de Sem supervisão aprendizado de máquina.
Ele tem apenas algumas linhas de código como outros algoritmos:
from sklearn.svm import OneClassSVM
pred=clf.predict(X)
anomaly_score=clf.score_samples(X)
clf = OneClassSVM(gama="auto",nu=0,04,gama=0,0004).ajuste(X)
Saiba mais, ver este site de sklearn para SVMs de classe única
D. Algoritmo de envelope elíptico: Este algoritmo é usado quando os dados têm uma distribuição gaussiana. É assim que este modelo converte os dados em forma elíptica e os pontos que estão longe das coordenadas desta forma são considerados outliers e para este determinante de covariância mínimo é encontrado. É como quando a covariância é encontrada no conjunto de dados, então o mínimo é excluído e que é maior, esses pontos são considerados anomalias. A imagem a seguir mostra a explicação dessa detecção de algoritmo.
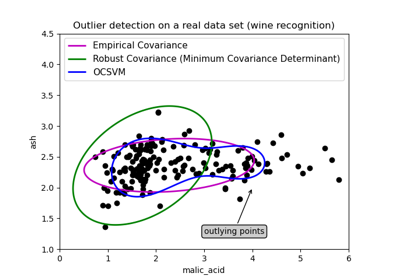
Ele tem a mesma linha de código que apenas para ajustar os dados e prever nele que identifica anomalias nos dados onde são atribuídos. -1 para anomalias e +1 para dados normais ou in-liers.
from sklearn.covariance import EllipticEnvelope model1 = EllipticEnvelope(contaminação = 0.1) # fit model model1.fit(X_train) model1.predict(X_test)
Para obtener más información sobre los parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... y la tabla de comparación, consulte Sobre elíptico sklearn
Essas são algumas das técnicas utilizadas na detecção de anomalias que ajudam a conhecer os pontos que estão longe do normal e que trazem muitas mudanças inesperadas nos dados.. Dependendo do local ou tipo de dados, Ele tem vários efeitos e é usado em muitos lugares e indústrias, como a indústria médica, a indústria automotiva, a indústria de construção, a indústria de alimentos (anormalidades que são diferentes dos padrões prescritos), indústria de defesa, etc.
Deixe-me saber se você tiver alguma dúvida.. Obrigado pela leitura. 👩🕵️♀️👩🎓 Tenha um bom dia.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





