Este artigo foi publicado como parte do Data Science Blogathon
“Redes Adversariais Generativas é a ideia mais interessante dos últimos dez anos em Aprendizado de Máquina” – Yann LeCun
Introdução
compreensão matemática e prática disso, mas antes disso, se você quiser dar uma olhada nas noções básicas de GAN, você pode continuar com o seguinte link:
A maioria dos gigantes da tecnologia (como Google, Microsoft, Amazonas, etc.) estão trabalhando duro para aplicar GANs para uso prático, alguns desses casos de uso são:
- Adobe: usando GAN para o Photoshop de próxima geração.
- Google: usando GAN para geração de texto.
- IBM: uso de GAN para aumento de dados (para gerar imagens sintéticas para treinar seus modelos de classificação).
- Snap Chat / TikTok: para criar vários filtros de imagem (que você já deve ter visto).
- Disney: uso de GAN para súper resoluçãoo "resolução" refere-se à capacidade de tomar decisões firmes e atingir metas estabelecidas. Em contextos pessoais e profissionais, Envolve a definição de metas claras e o desenvolvimento de um plano de ação para alcançá-las. A resolução é fundamental para o crescimento pessoal e o sucesso em várias áreas da vida, pois permite superar obstáculos e manter o foco no que realmente importa.... (melhoria da qualidade do vídeo) para seus filmes.
Algo especial sobre os GANs é que essas empresas dependem deles para seu futuro., você não acha?
Então, O que está impedindo você de adquirir o conhecimento dessa tecnologia épica? Eu vou te responder, algum, você só precisa de uma vantagem e este artigo. Vamos primeiro discutir a matemática por trás do Gerador e Discriminador.
Operação matemática do discriminador:
O único objetivo do Discriminador é classificar imagens reais e falsas. Para classificação, utiliza una convolucional neuronal vermelhoRedes Neurais Convolucionais (CNN) são um tipo de arquitetura de rede neural projetada especialmente para processamento de dados com uma estrutura de grade, como fotos. Eles usam camadas de convolução para extrair recursos hierárquicos, o que os torna especialmente eficazes em tarefas de reconhecimento e classificação de padrões. Graças à sua capacidade de aprender com grandes volumes de dados, As CNNs revolucionaram campos como a visão computacional.. (CNN) tradicional com uma função de custo específica. O processo de treinamento do Discriminador funciona da seguinte maneira:
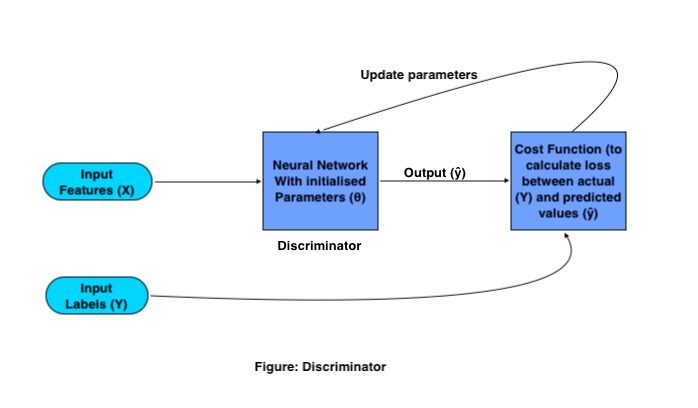
Onde X e Y são características de entrada e rótulos, respectivamente, a saída é representada por (ŷ) e os parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... de red se representan con (θ).
Los GAN de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... necesitan un conjunto de imágenes de entrenamiento y sus respectivas etiquetas, essas imagens como um recurso de entrada vão para a CNN, com um conjunto de parâmetros inicializados. Este CNN gera saída multiplicando a matriz de peso (C) com características de entrada (X) e adicionando um Bias (B) en ella y convirtiéndola en una matriz no lineal pasándola a una função de despertarA função de ativação é um componente chave em redes neurais, uma vez que determina a saída de um neurônio com base em sua entrada. Seu principal objetivo é introduzir não linearidades no modelo, permitindo que você aprenda padrões complexos em dados. Existem várias funções de ativação, como o sigmóide, ReLU e tanh, cada um com características particulares que afetam o desempenho do modelo em diferentes aplicações.....
Essa saída é conhecida como saída prevista., então a perda é calculada com base nos parâmetros de peso que são ajustados na rede para minimizar a perda.
Operação matemática do gerador:
O objetivo do Generator é gerar uma imagem falsa a partir da distribuição dada (conjunto de imagens), faz isso com o seguinte procedimento:
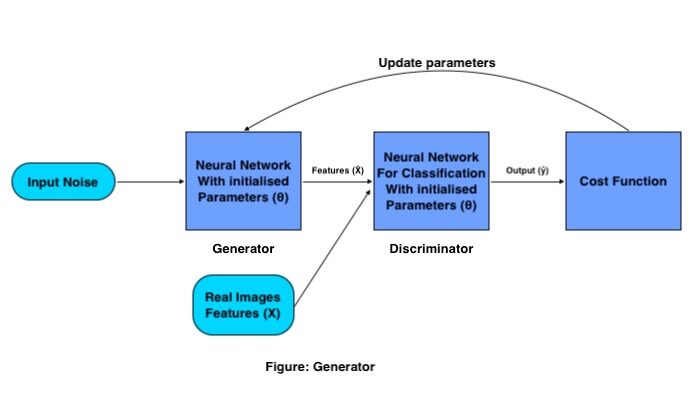
Um conjunto de vetores de entrada é passado (ruído aleatório) através da neuronal vermelhoAs redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano. Eles usam estruturas conhecidas como neurônios artificiais para processar e aprender com os dados. Essas redes são fundamentais no campo da inteligência artificial, permitindo avanços significativos em tarefas como reconhecimento de imagem, Processamento de linguagem natural e previsão de séries temporais, entre outros. Sua capacidade de aprender padrões complexos os torna ferramentas poderosas.. del generador, que cria uma imagem totalmente nova multiplicando a matriz de peso do gerador com o ruído de entrada.
Esta imagem gerada funciona como entrada para o discriminador que é treinado para classificar imagens falsas e reais.. Em seguida, a perda é calculada para as imagens geradas, com base em quais parâmetros são atualizados para o gerador até obtermos uma boa precisão.
Assim que estivermos satisfeitos com a precisão do Gerador, Economizamos os pesos do gerador e eliminamos o Discriminador da rede, e usamos essa matriz de peso para gerar mais imagens novas, passando uma matriz de ruído aleatório diferente a cada vez.
Perda de entropia cruzada binária para GAN:
Para otimizar os parâmetros GAN, precisamos de uma função de custo que diga à rede quanto ela precisa melhorar simplesmente calculando a diferença entre o valor real e o previsto. o Função de perdaA função de perda é uma ferramenta fundamental no aprendizado de máquina que quantifica a discrepância entre as previsões do modelo e os valores reais. Seu objetivo é orientar o processo de treinamento, minimizando essa diferença, permitindo assim que o modelo aprenda de forma mais eficaz. Existem diferentes tipos de funções de perda, como erro quadrático médio e entropia cruzada, cada um adequado para diferentes tarefas e... que se utiliza en las GAN se denomina entropía cruzada binaria y se representa como:
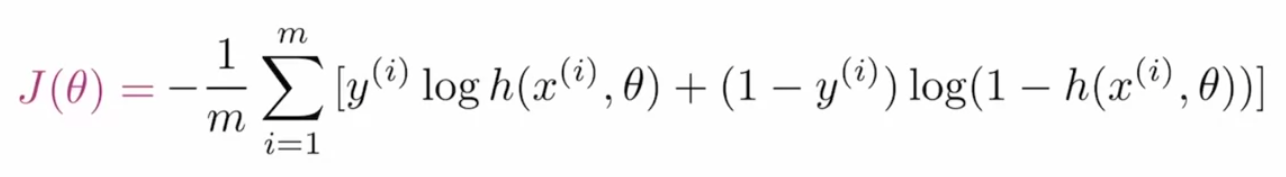
Onde m é o tamanho do lote, e(eu) é o valor real da tag, h é o valor do rótulo previsto, x(eu) é a característica de entrada e θ representa o parâmetro.
Vamos dividir esta função de custo em subpartes para entender melhor. A fórmula fornecida é a combinação de dois termos, onde um é usado quando é eficaz quando o rótulo é “0” e o outro é importante quando o rótulo é “1”. O primeiro termo é:
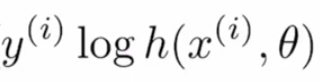
se o valor real é “1” e o valor previsto é “~ 0” neste caso, desde log (~ 0) tende a infinito negativo ou muito alto, e se o valor previsto também for “~ 1”, então o log ( ~ 1) seria perto de “0” ou muito menos, então, este termo ajuda a calcular a perda para os valores do rótulo “1”.
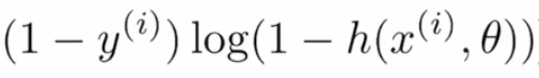
Se o valor real for “0” e o valor previsto é “~ 1”, então logar (1- (~ 1)) resultaria em infinito negativo ou muito alto, e se o valor previsto for “~ 0”, então o termo produziria resultados "~ 0" ou muito menos perda, portanto, este termo é usado para os valores reais da tag "0".
Qualquer um dos termos de perda retornaria valores negativos no caso de a previsão estar errada, a combinação desses termos é chamada Entropia (perda logarítmica). Mas como é negativo, para torná-lo maior que "1", aplicamos um sinal negativo (pode ser visto na fórmula principal), aplicar este sinal negativo é o que faz Entropia cruzada (perda logarítmica negativa).
Vamos treinar o primeiro modelo GAN:
Vamos criar um modelo GAN que pode gerar dígitos manuscritos da distribuição de dados MNIST usando o módulo PyTorch.
Primeiro, vamos importar os módulos necessários:
%matplotlib embutido importar numpy como np importar tocha import matplotlib.pyplot as plt
Em seguida, leríamos os dados do submódulo fornecido por PyTorch chamados conjuntos de dados.
# número de subprocessos a serem usados para carregamento de dados
num_workers = 0
# quantas amostras por lote carregar
batch_size = 64
# converter dados em tocha.FloatTensor
transform = transforms.ToTensor()
# obter os conjuntos de dados de treinamento
train_data = datasets.MNIST(root ="dados", train = True,
download = True, transformar = transformar)
# preparar carregador de dados
train_loader = torch.utils.data.DataLoader(train_data, batch_size = batch_size,
num_workers = num_workers)
Visualize os dados
Como estaríamos criando nosso modelo no framework PyTorch que usa tensores, estaríamos transformando nossos dados em tensores de tocha. Se você quiser ver os dados, você pode ir em frente e usar o seguinte snippet de código:
# obter um lote de imagens de treinamento dataiter = iter(train_loader) imagens, labels = dataiter.next() images = images.numpy() # pegue uma imagem do lote img = np.squeeze(imagens[0]) fig = plt.figure(figsize = (3,3)) ax = fig.add_subplot(111) ax.imshow(img, cmap = 'cinza')

Discriminado
Agora é a hora de definir a rede do Discriminador, que é a combinação de várias camadas da CNN.
import torch.nn as nn
import torch.nn.functional as F
classe Discriminador(nn.Module):
def __init__(auto, input_size, oculto_dim, output_size):
super(Discriminador, auto).__iniciar__()
# definir camadas lineares ocultas
self.fc1 = nn.Linear(input_size, oculto_dim * 4)
self.fc2 = nn.Linear(oculto_dim * 4, oculto_dim * 2)
self.fc3 = nn.Linear(oculto_dim * 2, oculto_dim)
# camada final totalmente conectada
self.fc4 = nn.Linear(oculto_dim, output_size)
# camada de eliminação
self.dropout = nn.Dropout(0.3)
def frente(auto, x):
# achatar imagem
x = x.view(-1, 28*28)
# todas as camadas escondidas
x = F.leaky_relu(self.fc1(x), 0.2) # (entrada, inclinação_ negativa = 0,2)
x = self.dropout(x)
x = F.leaky_relu(self.fc2(x), 0.2)
x = self.dropout(x)
x = F.leaky_relu(self.fc3(x), 0.2)
x = self.dropout(x)
# camada final
out = self.fc4(x)
voltar para fora
O código acima segue a arquitetura Python tradicional orientada a objetos. fc1, fc2, fc3, fc3 são as camadas totalmente conectadas. Quando passamos nossas entidades de entrada, passa por todas essas camadas a partir de fc1, e ao final, temos uma camada de abandono que é usada para resolver o problema de overfitting.
No mesmo código, você verá uma função chamada forward (auto, x), esta função é a implementação do mecanismo real de propagação direta, onde cada camada (fc1, fc2, fc3 e fc4) é seguido por uma função de gatilho (leaping_relu ) para converter a saída do liner em não linear.
Modelo Gerador
Depois disso, vamos verificar o segmento Gerador de GAN:
classe Generator(nn.Module):
def __init__(auto, input_size, oculto_dim, output_size):
super(Gerador, auto).__iniciar__()
# definir camadas lineares ocultas
self.fc1 = nn.Linear(input_size, oculto_dim)
self.fc2 = nn.Linear(oculto_dim, oculto_dim * 2)
self.fc3 = nn.Linear(oculto_dim * 2, oculto_dim * 4)
# camada final totalmente conectada
self.fc4 = nn.Linear(oculto_dim * 4, output_size)
# camada de eliminação
self.dropout = nn.Dropout(0.3)
def frente(auto, x):
# todas as camadas escondidas
x = F.leaky_relu(self.fc1(x), 0.2) # (entrada, inclinação_ negativa = 0,2)
x = self.dropout(x)
x = F.leaky_relu(self.fc2(x), 0.2)
x = self.dropout(x)
x = F.leaky_relu(self.fc3(x), 0.2)
x = self.dropout(x)
# camada final com tanh aplicado
out = F.tanh(self.fc4(x))
voltar para fora
A rede do gerador também é construída a partir de camadas totalmente conectadas, las funciones de activación de retomarA função de ativação do ReLU (Unidade linear retificada) É amplamente utilizado em redes neurais devido à sua simplicidade e eficácia. Definido como ( f(x) = máx.(0, x) ), O ReLU permite que os neurônios disparem apenas quando a entrada é positiva, o que ajuda a mitigar o problema do desbotamento do gradiente. Seu uso demonstrou melhorar o desempenho em várias tarefas de aprendizado profundo, tornando o ReLU uma opção... con fugas y la deserción. A única coisa que o torna diferente do Discriminator é que ele produz dependendo do parâmetro output_size (qual o tamanho da imagem a ser gerada).
Ajuste de hiperparâmetros
Os hiperparâmetros que vamos usar para treinar os GANs são:
# Hiperparama discriminador # Tamanho da imagem de entrada para discriminador (28*28) input_size = 784 # Tamanho da saída do discriminador (real ou falso) d_output_size = 1 # Tamanho da última camada oculta no discriminador d_hidden_size = 32 # Hiperparâmetros do gerador # Tamanho do vetor latente para dar ao gerador z_size = 100 # Tamanho da saída do discriminador (imagem gerada) g_output_size = 784 # Tamanho da primeira camada oculta no gerador g_hidden_size = 32
Crie uma instância dos modelos
E finalmente, toda a rede ficaria assim:
# instanciar discriminador e gerador D = Discriminador(input_size, d_hidden_size, d_output_size) G = Gerador(z_size, g_hidden_size, g_output_size) # verifique se eles estão como você espera imprimir(D) imprimir( ) imprimir(G)

Calcular perdas
Definimos o Gerador e o Discriminador, agora é hora de definir suas perdas para que essas redes melhorem com o tempo. Para o GAN teríamos duas perdas reais de função de perda e perda falsa que seriam definidas assim:
# Calcular perdas
def real_loss(D_out, suave = falso):
batch_size = D_out.size(0)
# alisamento de etiqueta
se suave:
# suave, rótulos reais = 0.9
labels = torch.ones(tamanho do batch)*0.9
outro:
labels = torch.ones(tamanho do batch) # rótulos reais = 1
# perda numericamente estável
criterion = nn.BCEWithLogitsLoss()
# calcular perda
perda = critério(D_out.squeeze(), rótulos)
perda de retorno
def fake_loss(D_out):
batch_size = D_out.size(0)
labels = torch.zeros(tamanho do batch) # rótulos falsos = 0
criterion = nn.BCEWithLogitsLoss()
# calcular perda
perda = critério(D_out.squeeze(), rótulos)
perda de retorno
Otimizadores
Assim que as perdas forem definidas, escolheríamos um otimizador adequado para o treinamento:
import torch.optim as optim # Otimizadores lr = 0.002 # Crie otimizadores para o discriminador e gerador d_optimizer = optim.Adam(D.parameters(), lr) g_optimizer = optim.Adam(G.parameters(), lr)
Treinamento de modelo
Uma vez que definimos Gerador e Discriminador, ambas as redes, sua perda funciona como otimizador, agora usaríamos os tempos e outras características para treinar toda a rede.
importar pickle como pkl
# hiperparams de treinamento
num_epochs = 100
# manter o controle de perdas e geradas, "falso" amostras
amostras = []
perdas = []
print_every = 400
# Obtenha alguns dados fixos para amostragem. Estas são imagens que são mantidas
# constante durante o treinamento, e nos permitem inspecionar o desempenho do modelo
sample_size = 16
fixed_z = np.random.uniform(-1, 1, tamanho =(sample_size, z_size))
fixed_z = torch.from_numpy(fixed_z).flutuador()
# treinar a rede
D.train()
G.train()
para época no intervalo(num_epochs):
para batch_i, (imagens_real, _) em enumerar(train_loader):
batch_size = real_images.size(0)
## Passo de reescalonamento importante ##
imagens_real = imagens_real * 2 - 1 # redimensionar imagens de entrada de [0,1) para [-1, 1)
# ==================================================
# TREINE O DISCRIMINADOR
# ==================================================
d_optimizer.zero_grad()
# 1. Treine com imagens reais
# Calcule as perdas discriminatórias em imagens reais
# suavizar os rótulos reais
D_real = D(imagens_real)
d_real_loss = real_loss(D_real, suave = verdadeiro)
# 2. Treine com imagens falsas
# Gerar imagens falsas
# gradientes não precisam fluir durante esta etapa
com torch.no_grad():
z = np.random.uniform(-1, 1, tamanho =(tamanho do batch, z_size))
z = torch.from_numpy(Com).flutuador()
fake_images = G(Com)
# Calcule as perdas discriminatórias em imagens falsas
D_fake = D(fake_images)
d_fake_loss = fake_loss(D_fake)
# some a perda e execute backprop
d_loss = d_real_loss + d_fake_loss
d_loss.backward()
d_optimizer.step()
# =================================================
# TREINE O GERADOR
# =================================================
g_optimizer.zero_grad()
# 1. Treine com imagens falsas e rótulos invertidos
# Gerar imagens falsas
z = np.random.uniform(-1, 1, tamanho =(tamanho do batch, z_size))
z = torch.from_numpy(Com).flutuador()
fake_images = G(Com)
# Calcule as perdas discriminatórias em imagens falsas
# usando etiquetas invertidas!
D_fake = D(fake_images)
g_loss = real_loss(D_fake) # use a perda real para virar rótulos
# executar backprop
g_loss.backward()
g_optimizer.step()
# Imprima algumas estatísticas de perda
se batch_i % print_every == 0:
# discriminador de impressão e perda de gerador
imprimir('Época [{:5d}/{:5d}] | d_loss: {:6.4f} | lustro: {:6.4f}'.formato(
época + 1, num_epochs, d_loss.item(), g_loss.item()))
## APÓS CADA ÉPOCA ##
# acrescentar perda de discriminador e perda de gerador
perdas.append((d_loss.item(), g_loss.item()))
# gerar e salvar amostra, imagens falsas
G.eval() # modo de avaliação para gerar amostras
samples_z = G(fixed_z)
samples.append(samples_z)
G.train() # de volta ao modo de trem
# Salvar amostras do gerador de treinamento
com aberto('train_samples.pkl', 'wb') como f:
pkl.dump(amostras, f)
Depois de executar o snippet de código acima, o processo de treinamento começaria assim:

Gerar imagens
Finalmente, quando o modelo é treinado, você pode usar o gerador treinado para produzir as novas imagens manuscritas.
# gerado aleatoriamente, novos vetores latentes sample_size = 16 rand_z = np.random.uniform(-1, 1, tamanho =(sample_size, z_size)) rand_z = torch.from_numpy(rand_z).flutuador() G.eval() # modo de avaliação # amostras geradas rand_images = G(rand_z) # 0 indica o primeiro conjunto de amostras na lista aprovada # e temos apenas um lote de amostras, aqui view_samples(0, [rand_images])
A saída gerada com o código a seguir seria algo assim:

Então, agora que você tem seu próprio modelo GAN treinado, você pode usar este modelo para treiná-lo em um conjunto diferente de imagens, para produzir novas imagens invisíveis.
Referências:
1. Aprendizagem profundaAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde... de Udacity: https://www.udacity.com/
2. Inteligência artificial de aprendizagem profunda: https://www.deeplearning.ai/
Obrigado por ler este artigo. Se você aprendeu algo novo, fique à vontade para comentar! Até a próxima! !!! ❤️
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





