Visão geral
- Aprendendo sobre o modelo de ponta que são os Transformers.
- Por favor, entenda como podemos implementar Transformers no problema de legenda de imagem já visto usando Tensorflow
- Comparando os resultados de Transformers vs. Modelos de Atenção.
Introdução
Vimos que os mecanismos de atenção (no artigo anterior) tornaram-se parte integrante da modelagem de sequência convincente e modelos de transdução em várias tarefas (como a legenda das fotos), permitindo a modelagem de dependências independentemente de sua distância nas sequências de entrada ou saída.
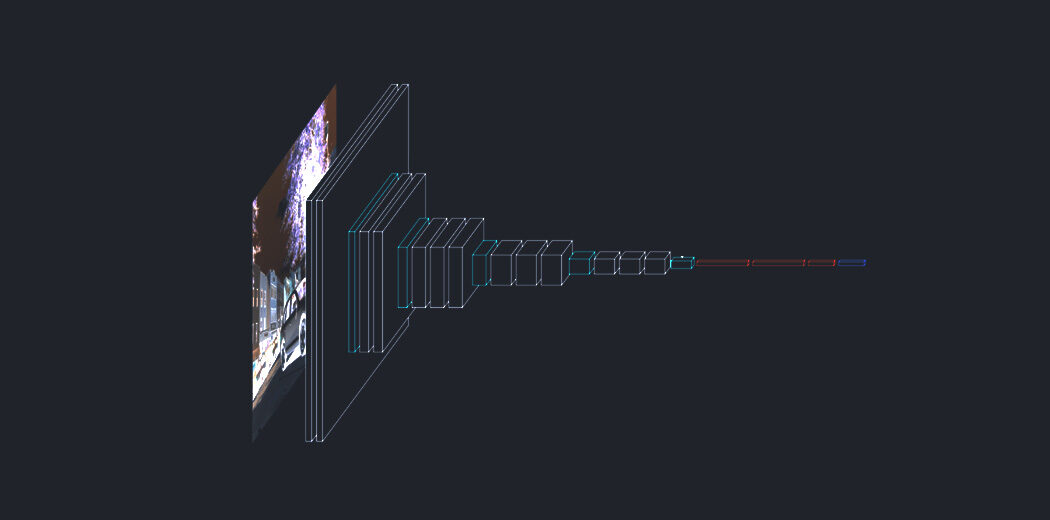
O transformador, uma arquitetura modelo que evita a recorrência e, em vez de, depende inteiramente de um mecanismo de cuidado para estabelecer dependências globais entre a entrada e a saída. A arquitetura do Transformer permite uma paralelização significativamente maior e pode alcançar novos resultados de ponta em qualidade de tradução.
Neste artigo, vamos ver como pode Implementar o mecanismo de atenção para gerar legendas com Transformers usando TensorFlow.
Pré-requisitos antes de começar: –
Eu recomendo que você leia este artigo antes de começar:
Tabela de conteúdo
- Arquitetura de transformador
- Implementação do mecanismo de atenção para geração de legendas com Transformers usando Tensorflow
- Importar bibliotecas necessárias
- Carregamento e pré-processamento de dados
- Definição de modelo
- Codificação posicional
- Cuidado multi-cabeça
- Camada codificador-decodificador
- Transformador
- Hiperparâmetros do modelo
- Treinamento de modelo
- Avaliação BLEU
- Comparação
- Que segue?
- Notas finais
Arquitetura de transformador
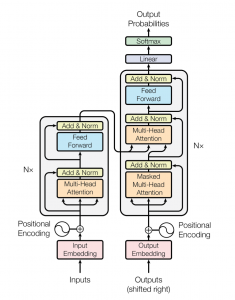
A rede do transformador emprega uma arquitetura de codificador-decodificador semelhante à de um RNN. A principal diferença é que os transformadores podem receber a oração / sequência de entrada paralela, quer dizer, não há intervalo de tempo associado à entrada e todas as palavras da frase podem ser passadas simultaneamente.
Vamos começar entendendo a entrada para o transformador.
Considere uma tradução do inglês para o alemão. Alimentamos a frase inteira em inglês para a inserção de entrada. Uma camada de inserção de entrada pode ser considerada como um ponto no espaço onde palavras semelhantes em significado estão fisicamente mais próximas umas das outras., quer dizer, cada palavra é atribuída a um vetor com valores contínuos para representar aquela palavra.
Agora, um problema com isso é que a mesma palavra em frases diferentes pode ter significados diferentes, é aqui que entra a codificação de posição. Uma vez que os transformadores não contêm recorrência ou convolução, para o modelo usar a ordem da sequência, deve fazer uso de algumas informações sobre a posição relativa ou absoluta das palavras em uma sequência. A ideia é usar pesos fixos ou aprendidos que codificam informações relacionadas a uma posição específica de um token em uma frase.
de forma similar, a palavra alemã alvo é alimentada para a codificação de saída e seu vetor de codificação posicional é passado para o bloco decodificador.
O bloco codificador tem duas subcamadas. O primeiro é um mecanismo de autocuidado com várias cabeças, e a segunda é uma rede de alimentação direta simples, totalmente conectado dependendo da posição. Para cada palavra, podemos gerar um vetor de atenção que captura as relações contextuais entre as palavras em uma frase. A atenção com várias cabeças no codificador aplica um mecanismo de atenção específico chamado autoatenção. A autoatenção permite que os modelos associem cada palavra da entrada a outras palavras.
Além das duas subcamadas em cada camada do codificador, o decodificador insere uma terceira subcamada, que executa a atenção de várias cabeças na saída da pilha do codificador. Semelhante ao codificador, usamos conexões residuais em torno de cada uma das subcamadas, seguido pela normalização da camada. Os vetores de atenção das palavras alemãs e os vetores de atenção das frases em inglês do codificador são passados para a segunda atenção com várias cabeças.
Este bloco de atenção determinará quão intimamente cada vetor de palavras está relacionado entre si.. É aqui que o mapeamento de palavras do inglês para o alemão é feito. O decodificador é coberto com uma camada linear que atua como um classificador e um softmax para obter as probabilidades da palavra.
Agora que você tem uma visão geral básica de como os transformadores funcionam, vamos ver como podemos implementá-lo para tarefa de legenda de imagem usando Tensorflow e comparar nossos resultados com outros métodos.
Implementação do mecanismo de atenção para a geração de legendas com Transformers usando TensorFlow
Você pode encontrar o código-fonte completo em meu Github perfil.
Paso 1: – Importe as bibliotecas necessárias
Aqui, usaremos o Tensorflow para criar nosso modelo e treiná-lo. A maior parte do crédito do código vai para o TensorFlow tutoriais. Você pode usar os notebooks Google Colab ou Kaggle se quiser que uma GPU o treine.
importar string importar numpy como np importar pandas como pd from numpy import array da imagem de importação PIL importar picles import matplotlib.pyplot as plt import sys, Tempo, os, advertências warnings.filterwarnings("ignorar") importar re importação difícil importar tensorflow como tf from tqdm import tqdm de nltk.translate.bleu_score import frase_bleu de keras.preprocessing.sequence import pad_sequences from keras.utils import to_categorical de keras.utils import plot_model de keras.models import Model de keras.layers import Input de keras.layers import Dense, BatchNormalization de keras.layers import LSTM from keras.layers import Embedding de keras.layers import Dropout de keras.layers.merge importar adicionar de keras.callbacks import ModelCheckpoint de keras.preprocessing.image import load_img, img_to_array from keras.preprocessing.text import Tokenizer de sklearn.utils import shuffle de sklearn.model_selection import train_test_split
Paso 2: – Carregamento e pré-processamento de dados
Defina nossa imagem e caminho de legenda e verifique quantas imagens no total estão presentes no conjunto de dados.
image_path = "/content / gdrive / My Drive / FLICKR8K / Flicker8k_Dataset" dir_Flickr_text = "/content / gdrive / My Drive / FLICKR8K / Flickr8k_text / Flickr8k.token.txt" jpgs = os.listdir(caminho_da_imagem) imprimir("Total de imagens no conjunto de dados = {}".formato(len(jpgs)))
Produção:
![]()
Criamos um quadro de dados para armazenar o id da imagem e as legendas para facilidade de uso.
arquivo = aberto(dir_Flickr_text,'r') text = file.read() file.close() datatxt = [] para linha em text.split('n'): col = linha.split('t') se len(col) == 1: Prosseguir w = col[0].dividir("#") datatxt.append(C + [col[1].diminuir()]) data = pd.DataFrame(datatxt,colunas =["nome do arquivo","índice","rubrica"]) data = data.reindex(colunas =['índice','nome do arquivo','rubrica']) dados = dados[data.filename != '2258277193_586949ec62.jpg.1'] uni_filenames = np.unique(data.filename.values) data.head()
Produção:
A seguir, Vamos visualizar algumas imagens e suas 5 legendas:
npic = 5 npix = 224 target_size = (npix,npix,3) contagem = 1 fig = plt.figure(figsize =(10,20)) para jpgfnm em uni_filenames[10:14]: nome de arquivo = image_path + '/' + jpgfnm legendas = lista(dados["rubrica"].Lugar, colocar[dados["nome do arquivo"]== jpgfnm].valores) image_load = load_img(nome do arquivo, target_size = target_size) ax = fig.add_subplot(npic,2,contar,xticks =[],yticks =[]) ax.imshow(carga_da_imagem) contagem += 1 ax = fig.add_subplot(npic,2,contar) plt.axis('desligado') ax.plot() ax.set_xlim(0,1) ax.set_ylim(0,len(legendas)) para eu, legenda em enumerar(legendas): ax.text(0,eu,rubrica,fontsize = 20) contagem += 1 plt.show()
Produção:

A seguir, vamos ver qual é o tamanho do nosso vocabulário atual: –
vocabulário = [] para txt em data.caption.values: vocabulário.estender(txt.split()) imprimir('Tamanho do vocabulário: %d ' % len(definir(vocabulário)))
Produção:
![]() A seguir, realizar uma limpeza de texto, como remover pontuação, caracteres individuais e valores numéricos:
A seguir, realizar uma limpeza de texto, como remover pontuação, caracteres individuais e valores numéricos:
def remove_punctuation(text_original): text_no_punctuation = text_original.translate(string.punctuation) Retorna(text_no_punctuation) def remove_single_character(texto): text_len_more_than1 = "" para palavra em texto.split(): se len(palavra) > 1: text_len_more_than1 += " " + palavra Retorna(text_len_more_than1) def remove_numeric(texto): text_no_numeric = "" para palavra em texto.split(): isalpha = palavra.isalpha() se isalpha: text_no_numeric += " " + palavra Retorna(text_no_numeric) def text_clean(text_original): texto = remove_punctuation(text_original) texto = remove_single_character(texto) texto = remove_numeric(texto) Retorna(texto) para eu, legenda em enumerar(data.caption.values): newcaption = text_clean(rubrica) dados["rubrica"].iloc[eu] = newcaption
Agora vamos olhar para o tamanho do nosso vocabulário após a limpeza.
clean_vocabulary = [] para txt em data.caption.values: clean_vocabulary.extend(txt.split()) imprimir('Limpar tamanho do vocabulário: %d ' % len(definir(limpar_vocabulário)))
Produção:
![]() A seguir, salvamos todos os títulos e caminhos das imagens em duas listas para que possamos carregar as imagens ao mesmo tempo usando o caminho estabelecido. Nós também adicionamos tags ” e ” a cada título para que o modelo entenda o início e o fim de cada título.
A seguir, salvamos todos os títulos e caminhos das imagens em duas listas para que possamos carregar as imagens ao mesmo tempo usando o caminho estabelecido. Nós também adicionamos tags ” e ” a cada título para que o modelo entenda o início e o fim de cada título.
PATH = "/content / gdrive / My Drive / FLICKR8K / Flicker8k_Dataset /" all_captions = [] para legenda em dados["rubrica"].astype(str): legenda = '<começar> ' + legenda + ' <fim>' all_captions.append(rubrica) all_captions[:10]
Produção:

all_img_name_vector = [] para anotação nos dados["nome do arquivo"]: full_image_path = PATH + anotação all_img_name_vector.append(full_image_path) all_img_name_vector[:10]
Produção:
Agora você pode ver que temos 40455 caminhos e legendas de imagens.
imprimir(f"len(all_img_name_vector) : {len(all_img_name_vector)}") imprimir(f"len(all_captions) : {len(all_captions)}")
Produção:
![]()
Vamos levar sozinhos 40000 de cada um para que possamos selecionar o tamanho do lote corretamente, quer dizer, 625 lotes se tamanho do lote = 64. Para fazer isso, definimos uma função para limitar o conjunto de dados a 40000 imagens e legendas.
def data_limiter(num,total_captions,all_img_name_vector): train_captions, img_name_vector = shuffle(total_captions,all_img_name_vector,random_state = 1) train_captions = train_captions[:num] img_name_vector = img_name_vector[:num] train_captions de retorno,img_name_vector train_captions,img_name_vector = data_limiter(40000,total_captions,all_img_name_vector)
Paso 3: – Definição do modelo
Vamos definir o modelo de extração de recursos de imagem usando InceptionV3. Devemos lembrar que não precisamos classificar as imagens aqui, só precisamos extrair um vetor de imagem para nossas imagens. Portanto, removemos a camada softmax do modelo. Devemos todos pré-processar todas as imagens com o mesmo tamanho, quer dizer, 299 × 299 antes de inseri-los no modelo, e a forma de saída desta camada é 8x8x2048.
def load_image(caminho_da_imagem): img = tf.io.read_file(caminho_da_imagem) img = tf.image.decode_jpeg(img, canais = 3) img = tf.image.resize(img, (299, 299)) img = tf.keras.applications.inception_v3.preprocess_input(img) retorno img, image_path image_model = tf.keras.applications.InceptionV3(include_top=Falso, pesos ="imagenet") new_input = image_model.input hidden_layer = image_model.layers[-1].output image_features_extract_model = tf.keras.Model(new_input, hidden_layer)
A seguir, vamos atribuir o nome de cada imagem para a função de carregar a imagem. Iremos pré-processar cada imagem com InceptionV3 e armazenar em cache a saída para o disco e as características da imagem serão reformatadas para 64 × 2048.
encode_train = classificado(definir(img_name_vector)) image_dataset = tf.data.Dataset.from_tensor_slices(encode_train) image_dataset = image_dataset.map(load_image, num_parallel_calls = tf.data.experimental.AUTOTUNE).lote(64)
Extraímos as características e as armazenamos nos respectivos .npy arquivos e, em seguida, passe essas características pelo codificador.Os arquivos NPY armazenam todas as informações necessárias para reconstruir uma matriz em qualquer computador, incluindo informações de tipo e forma.
para img, caminho em tqdm(image_dataset): batch_features = image_features_extract_model(img) batch_features = tf.reshape(batch_features, (batch_features.shape[0], -1, batch_features.shape[3])) para bf, p em zip(batch_features, caminho): path_of_feature = p.numpy().decodificar("utf-8") np.save(path_of_feature, bf.numpy())
A seguir, convertemos as legendas em tokens e criamos um vocabulário de todas as palavras únicas nos dados. Também limitaremos o tamanho do vocabulário para 5000 palavras principais para economizar memória. Substituiremos palavras que não estão no vocabulário pelo token
top_k = 5000 tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words = top_k, oov_token="<desconhecido>", filtros="!"#$%&()*+.,-/:;[e-mail protegido][]^ _`{|}~ ") tokenizer.fit_on_texts(train_captions) train_seqs = tokenizer.texts_to_sequences(train_captions) tokenizer.word_index['<almofada>'] = 0 tokenizer.index_word[0] = '<almofada>' train_seqs = tokenizer.texts_to_sequences(train_captions) cap_vector = tf.keras.preprocessing.sequence.pad_sequences(train_seqs, padding = 'post')
A seguir, criar conjuntos de treinamento e validação usando uma divisão 80-20:
img_name_train, img_name_val, cap_train, cap_val = train_test_split(img_name_vector,cap_vector, test_size = 0.2, random_state = 0)
A seguir, vamos criar um conjunto de dados tf.data para usar no treinamento de nosso modelo.
BATCH_SIZE = 64 BUFFER_SIZE = 1000 num_steps = len(img_name_train) // TAMANHO DO BATCH def map_func(img_name, boné): img_tensor = np.load(img_name.decode('utf-8')+'.npy') Retorna img_tensor, boné dataset = tf.data.Dataset.from_tensor_slices((img_name_train, cap_train)) dataset = dataset.mapa(lambda item 1, item2: tf.numpy_function(map_func, [item 1, item2], [tf.float32, tf.int32]),num_parallel_calls = tf.data.experimental.AUTOTUNE) dataset = dataset.shuffle(TAMANHO DO BUFFER).lote(TAMANHO DO BATCH) dataset = dataset.prefetch(buffer_size = tf.data.experimental.AUTOTUNE)
Paso 4: – Codificação posicional
A codificação posicional usa funções seno e cosseno de diferentes frequências. Para cada índice ímpar no vetor de entrada, crie um vetor usando a função cos, para cada índice par, criar um vetor usando a função sin. Mais tarde, adicione esses vetores às suas incorporações de entrada correspondentes, que dá à rede informações sobre a posição de cada vetor.
def get_angles(pos, eu, d_model): angle_rates = 1 / np.power(10000, (2 * (eu//2)) / por exemplo, float32(d_model)) Retorna pos * ângulos_rates def positional_encoding_1d(posição, d_model): angle_rads = get_angles(np.arange(posição)[:, por exemplo, newaxis], np.arange(d_model)[por exemplo, newaxis, :], d_model) ângulo_rads[:, 0::2] = np.sin(ângulo_rads[:, 0::2]) ângulo_rads[:, 1::2] = por exemplo cos(ângulo_rads[:, 1::2]) pos_encoding = angle_rads[por exemplo, newaxis, ...] Retorna tf.cast(pos_encoding, dtype = tf.float32) def positional_encoding_2d(fileira,col,d_model): afirmar d_model % 2 == 0 row_pos = np.repeat(np.arange(fileira),col)[:,por exemplo, newaxis] col_pos = np.repeat(np.expand_dims(np.arange(col),0),fileira,eixo =0).remodelar(-1,1) angle_rads_row = get_angles(row_pos,np.arange(d_model //2)[por exemplo, newaxis,:],d_model //2) angle_rads_col = get_angles(col_pos,np.arange(d_model //2)[por exemplo, newaxis,:],d_model //2) angle_rads_row[:, 0::2] = np.sin(angle_rads_row[:, 0::2]) angle_rads_row[:, 1::2] = por exemplo cos(angle_rads_row[:, 1::2]) angle_rads_col[:, 0::2] = np.sin(angle_rads_col[:, 0::2]) angle_rads_col[:, 1::2] = por exemplo cos(angle_rads_col[:, 1::2]) pos_encoding = np.concatenato([angle_rads_row,angle_rads_col],eixo =1)[por exemplo, newaxis, ...] Retorna tf.cast(pos_encoding, dtype = tf.float32)
Paso 5: – Cuidado multi-cabeça
Calcule os pesos de atenção. q, k, v deve ter dimensões principais correspondentes. k, v deve ter a penúltima dimensão correspondente, quer dizer: seq_len_k = seq_len_v. A máscara tem diferentes formas dependendo do seu tipo (acolchoado ou olhar para frente) mas deve ser transmissível para a adição.
def create_padding_mask(seq): seq = tf.cast(tf.math.equal(seq, 0), tf.float32) Retorna seq[:, tf.newaxis, tf.newaxis, :] # (tamanho do batch, 1, 1, seq_len) def create_look_ahead_mask(Tamanho): máscara = 1 - tf.linalg.band_part(tf.ones((Tamanho, Tamanho)), -1, 0) Retorna mascarar # (seq_len, seq_len) def scaled_dot_product_attention(q, k, v, mascarar): matmul_qk = tf.matmul(q, k, transpose_b = True) # (..., seq_len_q, seq_len_k) dk = tf.cast(tf.shape(k)[-1], tf.float32) scaled_attention_logits = matmul_qk / tf.math.sqrt(dk) . E se máscara não é nenhum: scaled_attention_logits += (mascarar * -1e9) attention_weights = tf.nn.softmax(scaled_attention_logits, eixo =-1) saída = tf.matmul(atenção_pesos, v) # (..., seq_len_q, profundidade_v) Retorna saída, atenção_pesos classe MultiHeadAttention(tf.duro.camadas.Camada): def __iniciar__(auto, d_model, num_heads): super(MultiHeadAttention, auto).__iniciar__() auto.num_heads = num_heads auto.d_model = d_model afirmar d_model % auto.num_heads == 0 auto.profundidade = d_model // auto.num_heads auto.wq = tf.keras.layers.Dense(d_model) auto.wk = tf.keras.layers.Dense(d_model) auto.wv = tf.keras.layers.Dense(d_model) auto.dense = tf.keras.layers.Dense(d_model) def split_heads(auto, x, tamanho do batch): x = tf.reshape(x, (tamanho do batch, -1, auto.num_heads, auto.profundidade)) Retorna tf.transpose(x, perm =[0, 2, 1, 3]) def ligar(auto, v, k, q, mascarar= Nenhum): batch_size = tf.shape(q)[0] q = auto.wq(q) # (tamanho do batch, seq_len, d_model) k = auto.sem.(k) # (tamanho do batch, seq_len, d_model) v = auto.wv(v) # (tamanho do batch, seq_len, d_model) q = auto.split_heads(q, tamanho do batch) # (tamanho do batch, num_heads, seq_len_q, profundidade) k = auto.split_heads(k, tamanho do batch) # (tamanho do batch, num_heads, seq_len_k, profundidade) v = auto.split_heads(v, tamanho do batch) # (tamanho do batch, num_heads, seq_len_v, profundidade) scaled_attention, ention_weights = scaled_dot_product_attention(q, k, v, mascarar) scaled_attention = tf.transpose(scaled_attention, perm =[0, 2, 1, 3]) # (tamanho do batch, seq_len_q, num_heads, profundidade) concat_attention = tf.reshape(scaled_attention, (tamanho do batch, -1, auto.d_model)) # (tamanho do batch, seq_len_q, d_model) saída = auto.denso(concat_attention) # (tamanho do batch, seq_len_q, d_model) Retorna saída, atenção_pesos def point_wise_feed_forward_network(d_model, dff): Retorna tf.keras.Sequential([ tf.hard.layers.Dense(dff, ativação ='relu'), # (tamanho do batch, seq_len, dff) tf.hard.layers.Dense(d_model) # (tamanho do batch, seq_len, d_model)])
Paso 6: – Camada codificador-decodificador
classe EncoderLayer(tf.duro.camadas.Camada): def __iniciar__(auto, d_model, num_heads, dff, avaliar=0.1): super(EncoderLayer, auto).__iniciar__() auto.mha = MultiHeadAttention(d_model, num_heads) auto.ffn = point_wise_feed_forward_network(d_model, dff) auto.layernorm1 = tf.hard.layers.LayerNormalization(épsilon =1e-6) auto.layernorm2 = tf.hard.layers.LayerNormalization(épsilon =1e-6) auto.dropout1 = tf.keras.layers.Dropout(avaliar) auto.dropout2 = tf.keras.layers.Dropout(avaliar) def ligar(auto, x, Treinamento, mascarar= Nenhum): attn_output, _ = auto.mha(x, x, x, mascarar) # (tamanho do batch, input_seq_len, d_model) attn_output = auto.dropout1(attn_output, treinamento = treinamento) out1 = auto.layernorm1(x + attn_output) # (tamanho do batch, input_seq_len, d_model) ffn_output = auto.ffn(out1) # (tamanho do batch, input_seq_len, d_model) ffn_output = auto.dropout2(ffn_output, treinamento = treinamento) out2 = auto.layerernorm2(out1 + ffn_output) # (tamanho do batch, input_seq_len, d_model) Retorna out2
classe DecoderLayer(tf.duro.camadas.Camada): def __iniciar__(auto, d_model, num_heads, dff, avaliar=0.1): super(DecoderLayer, auto).__iniciar__() auto.mha1 = MultiHeadAttention(d_model, num_heads) auto.mha2 = MultiHeadAttention(d_model, num_heads) auto.ffn = point_wise_feed_forward_network(d_model, dff) auto.layernorm1 = tf.hard.layers.LayerNormalization(épsilon =1e-6) auto.layernorm2 = tf.hard.layers.LayerNormalization(épsilon =1e-6) auto.layernorm3 = tf.hard.layers.LayerNormalization(épsilon =1e-6) auto.dropout1 = tf.keras.layers.Dropout(avaliar) auto.dropout2 = tf.keras.layers.Dropout(avaliar) auto.dropout3 = tf.keras.layers.Dropout(avaliar) def ligar(auto, x, enc_output, Treinamento,look_ahead_mask= Nenhum, padding_mask= Nenhum): attn1, attn_weights_block1 = auto.mha1(x, x, x, look_ahead_mask) # (tamanho do batch, target_seq_len, d_model) attn1 = auto.dropout1(attn1, treinamento = treinamento) out1 = auto.layernorm1(attn1 + x) attn2, attn_weights_block2 = auto.mha2(enc_output, enc_output, out1, padding_mask) attn2 = auto.dropout2(attn2, treinamento = treinamento) out2 = auto.layerernorm2(attn2 + out1) # (tamanho do batch, target_seq_len, d_model) ffn_output = auto.ffn(out2) # (tamanho do batch, target_seq_len, d_model) ffn_output = auto.dropout3(ffn_output, treinamento = treinamento) out3 = auto.layerernorm3(ffn_output + out2) # (tamanho do batch, target_seq_len, d_model) Retorna out3, attn_weights_block1, attn_weights_block2
classe Codificador(tf.duro.camadas.Camada): def __iniciar__(auto, num_layers, d_model, num_heads, dff, tamanho_da_linha,tamanho_col,avaliar=0.1): super(Codificador, auto).__iniciar__() auto.d_model = d_model auto.num_camadas = num_camadas auto.embedding = tf.keras.layers.Dense(auto.d_model,ativação ='relu') auto.pos_encoding = posicional_encoding_2d(tamanho_da_linha,tamanho_col,auto.d_model) auto.enc_layers = [EncoderLayer(d_model, num_heads, dff, avaliar) para _ no faixa(num_layers)] auto.dropout = tf.keras.layers.Dropout(avaliar) def ligar(auto, x, Treinamento, mascarar= Nenhum): seq_len = tf.shape(x)[1] x = auto.incorporação(x) # (tamanho do batch, input_seq_len(H * W), d_model) x += auto.pos_encoding[:, :seq_len, :] x = auto.cair fora(x, treinamento = treinamento) para eu em faixa(auto.num_layers): x = auto.enc_layers[eu](x, Treinamento, mascarar) Retorna x # (tamanho do batch, input_seq_len, d_model)
classe Decodificador(tf.duro.camadas.Camada): def __iniciar__(auto, num_layers,d_model,num_heads,dff, target_vocab_size, maximum_position_encoding, avaliar=0.1): super(Decodificador, auto).__iniciar__() auto.d_model = d_model auto.num_camadas = num_camadas auto.embedding = tf.keras.layers.Embedding(target_vocab_size, d_model) auto.pos_encoding = positional_encoding_1d(maximum_position_encoding, d_model) auto.dec_layers = [DecoderLayer(d_model, num_heads, dff, avaliar) para _ no faixa(num_layers)] auto.dropout = tf.keras.layers.Dropout(avaliar) def ligar(auto, x, enc_output, Treinamento,look_ahead_mask=Nenhum, padding_mask=Nenhum): seq_len = tf.shape(x)[1] atenção_pesos = {} x = auto.incorporação(x) # (tamanho do batch, target_seq_len, d_model) x *= tf.math.sqrt(tf.cast(auto.d_model, tf.float32)) x += auto.pos_encoding[:, :seq_len, :] x = auto.cair fora(x, treinamento = treinamento) para eu no faixa(auto.num_layers): x, Bloco 1, bloco 2 = auto.dec_layers[eu](x, enc_output, Treinamento, look_ahead_mask, padding_mask) atenção_pesos['decoder_layer{}_Bloco 1'.formato(i +1)] = bloco1 atenção_pesos['decoder_layer{}_block2 '.formato(i +1)] = bloco2 Retorna x, atenção_pesos
Paso 7: – Transformador
classe Transformador(tf.duro.Modelo): def __iniciar__(auto, num_layers, d_model, num_heads, dff,tamanho_da_linha,tamanho_col, target_vocab_size,max_pos_encoding, avaliar=0.1): super(Transformador, auto).__iniciar__() auto.encoder = Encoder(num_layers, d_model, num_heads, dff,tamanho_da_linha,tamanho_col, avaliar) auto.decoder = decoder(num_layers, d_model, num_heads, dff, target_vocab_size,max_pos_encoding, avaliar) auto.final_layer = tf.keras.layers.Dense(target_vocab_size) def ligar(auto, inp, alcatrão, Treinamento,look_ahead_mask=Nenhum,dec_padding_mask=Nenhum,enc_padding_mask=Nenhum ): enc_output = auto.codificador(inp, Treinamento, enc_padding_mask) # (tamanho do batch, inp_seq_len, d_model ) dec_output, atenção_pesos = auto.decodificador( alcatrão, enc_output, Treinamento, look_ahead_mask, dec_padding_mask) final_output = auto.final_layer(dec_output) # (tamanho do batch, tar_seq_len, target_vocab_size) Retorna final_output, atenção_pesos
Paso 8: – Modelo de hiperparámetros
Definir parâmetros de treinamento:
num_layer = 4 d_model = 512 dff = 2048 num_heads = 8 row_size = 8 col_size = 8 target_vocab_size = top_k + 1 dropout_rate = 0.1
classe CustomSchedule(tf.duro.otimizadores.horários.LearningRateSchedule): def __iniciar__(auto, d_model, warmup_steps= 4000): super(CustomSchedule, auto).__iniciar__() auto.d_model = d_model auto.d_model = tf.cast(auto.d_model, tf.float32) auto.warmup_steps = warmup_steps def __ligar__(auto, Passo): arg1 = tf.math.rsqrt(Passo) arg2 = passo * (auto.warmup_steps ** -1.5) Retorna tf.math.rsqrt(auto.d_model) * tf.math.minimum(arg1, arg2)
learning_rate = CustomSchedule(d_model) optimizer = tf.hard.optimizers.Adam(taxa de Aprendizagem, beta_1 = 0,9, beta_2 = 0,98, epsilon=1e-9) loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits =Verdade, redução ='Nenhum') def loss_function(real, pred): mask = tf.math.logical_not(tf.math.equal(real, 0)) loss_ = loss_object(real, pred) mask = tf.cast(mascarar, dtype = loss_.dtype) perda_ * = máscara Retorna tf.reduce_sum(perda_)/tf.reduce_sum(mascarar)
train_loss = tf.keras.metrics.Mean(nome ="perda de trem") train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(nome ="train_accuracy") transformador = transformador(num_layer,d_model,num_heads,dff,tamanho_da_linha,tamanho_col,target_vocab_size, max_pos_encoding = target_vocab_size,taxa = dropout_rate)
Paso 9: – Treinamento de modelo
def create_masks_decoder(alcatrão): look_ahead_mask = create_look_ahead_mask(tf.shape(alcatrão)[1]) dec_target_padding_mask = create_padding_mask(alcatrão) combinado_mask = tf.maximum(dec_target_padding_mask, look_ahead_mask) Retorna máscara_combinada
@ tf.function def train_step(img_tensor, alcatrão): tar_inp = tar[:, :-1] tar_real = tar[:, 1:] dec_mask = create_masks_decoder(tar_inp) com tf.GradientTape() Como fita: previsões, _ = transformador(img_tensor, tar_inp,Verdade, dec_mask) loss = loss_function(tar_real, previsões) gradientes = tape.gradient(perda, transformer.trainable_variables) optimizer.apply_gradients(fecho eclair(gradientes, transformer.trainable_variables)) perda de trem(perda) train_accuracy(tar_real, previsões)
para época no faixa(30): start = time.time() train_loss.reset_states() train_accuracy.reset_states() para (lote, (img_tensor, alcatrão)) no enumerar(conjunto de dados): train_step(img_tensor, alcatrão) E se lote % 50 == 0: imprimir ('Época {} Lote {} Perda {:.4f} Precisão {:.4f}'.formato( época + 1, lote, train_loss.result(), train_accuracy.result())) imprimir ('Época {} Perda {:.4f} Precisão {:.4f}'.formato(época + 1, train_loss.result(), train_accuracy.result())) imprimir ('Tempo gasto para 1 época: {} secsn '.formato(time.time() - começar))
Paso 10: – Avaliação BLEU
def Avalie(imagem): temp_input = tf.expand_dims(load_image(imagem)[0], 0) img_tensor_val = image_features_extract_model(temp_input) img_tensor_val = tf.reshape(img_tensor_val, (img_tensor_val.shape[0], -1, img_tensor_val.shape[3])) start_token = tokenizer.word_index['<começar>'] end_token = tokenizer.word_index['<fim>'] decoder_input = [start_token] output = tf.expand_dims(decoder_input, 0) #tokens resultado = [] #lista de palavras fou eu no faixa(100): dec_mask = create_masks_decoder(saída) previsões, atenção_pesos = transformador(img_tensor_val,saída,Falso,dec_mask) previsões = previsões[: ,-1:, :] # (tamanho do batch, 1, tamanho_do_ vocabulário) predicted_id = tf.cast(tf.argmax(previsões, eixo = -1), tf.int32) E se predicted_id == end_token: Retorna resultado,tf.squeeze(saída, eixo = 0), atenção_pesos result.append(tokenizer.index_word[int(predicted_id)]) output = tf.concat([saída, predicted_id], eixo = -1) Retorna resultado,tf.squeeze(saída, eixo = 0), atenção_pesos
rid = np.random.randint(0, len(img_name_val)) image = img_name_val[livrar] real_caption = ''.Junte([tokenizer.index_word[eu] para eu no cap_val[livrar] E se eu não no [0]]) rubrica,resultado,atenção_pesos = avaliar(imagem) first = real_caption.split('', 1)[1] real_caption = first.rsplit('', 1)[0] para eu no rubrica: E se i =="<desconhecido>": caption.remove(eu) para eu no real_caption: E se i =="<desconhecido>": real_caption.remove(eu) result_join = ''.Junte(rubrica) result_final = result_join.rsplit('', 1)[0] real_appn = [] real_appn.append(real_caption.split()) referência = real_appn candidato = legenda pontuação = frase_bleu(referência, candidato, pesos =(1.0,0,0,0)) imprimir(f"Pontuação BLUE-1: {pontuação * 100}") pontuação = frase_bleu(referência, candidato, pesos =(0.5,0.5,0,0)) imprimir(f"Pontuação BLUE-2: {pontuação * 100}") pontuação = frase_bleu(referência, candidato, pesos =(0.3,0.3,0.3,0)) imprimir(f"Pontuação BLUE-3: {pontuação * 100}") pontuação = frase_bleu(referência, candidato, pesos =(0.25,0.25,0.25,0.25)) imprimir(f"Pontuação BLUE-4: {pontuação * 100}") imprimir ('Real Caption:', real_caption) imprimir ('Predicted Caption:', ''.Junte(rubrica)) temp_image = np.array(Imagem.abrir(imagem)) plt.imshow(temp_image)
Produção:

rid = np.random.randint(0, len(img_name_val)) image = img_name_val[livrar] real_caption = ''.Junte([tokenizer.index_word[eu] para eu no cap_val[livrar] E se eu não no [0]]) rubrica,resultado,atenção_pesos = avaliar(imagem) first = real_caption.split('', 1)[1] real_caption = first.rsplit('', 1)[0] para eu no rubrica: E se i =="<desconhecido>": caption.remove(eu) para eu no real_caption: E se i =="<desconhecido>": real_caption.remove(eu) result_join = ''.Junte(rubrica) result_final = result_join.rsplit('', 1)[0] real_appn = [] real_appn.append(real_caption.split()) referência = real_appn candidato = legenda pontuação = frase_bleu(referência, candidato, pesos =(1.0,0,0,0)) imprimir(f"Pontuação BLUE-1: {pontuação * 100}") pontuação = frase_bleu(referência, candidato, pesos =(0.5,0.5,0,0)) imprimir(f"Pontuação BLUE-2: {pontuação * 100}") pontuação = frase_bleu(referência, candidato, pesos =(0.3,0.3,0.3,0)) imprimir(f"Pontuação BLUE-3: {pontuação * 100}") pontuação = frase_bleu(referência, candidato, pesos =(0.25,0.25,0.25,0.25)) imprimir(f"Pontuação BLUE-4: {pontuação * 100}") imprimir ('Real Caption:', real_caption) imprimir ('Predicted Caption:', ''.Junte(rubrica)) temp_image = np.array(Imagem.abrir(imagem)) plt.imshow(temp_image)
Produção:

Paso 11: – Comparação
Vamos comparar as pontuações BLEU alcançadas no artigo anterior usando a atenção de Bahdanau versus nossos transformadores.

As pontuações BLEU à esquerda usam a atenção de Bahdanau e as pontuações BLEU à direita usam Transformers. Como podemos ver, O transformador funciona muito melhor do que apenas um modelo de atendimento.


E aí está! Implementamos Transformers com sucesso usando o Tensorflow e vimos como ele pode produzir resultados de ponta..
Notas finais
Em resumo, Os transformadores são melhores do que todas as outras arquiteturas que vimos antes porque evitam totalmente a recursão, processando frases como um todo e aprendendo as relações entre as palavras graças a mecanismos de atenção com várias cabeças e embeddings posicionais. Também deve ser observado que os transformadores que usam Tensorflow só podem capturar dependências dentro do tamanho de entrada fixo usado para treiná-los.
Existem muitos transformadores novos e poderosos como o Transformer-XL, Transformador emaranhado, Transformador de memória em malha que também pode ser implementado para aplicativos como Image Captions para obter resultados ainda melhores.
Você acha útil este artigo? Compartilhe seus valiosos comentários na seção de comentários abaixo.. Sinta-se à vontade para compartilhar seus livros de código completos também, que será útil para os membros da nossa comunidade.





