Introdução
O formato PDF ou arquivo de documento portátil é um dos formatos de arquivo mais comuns hoje. É amplamente utilizado em todas as indústrias, como em escritórios do governo, cuidados médicos e até trabalho pessoal. Como consequência, Existe uma grande quantidade de dados não estruturados em formato PDF e extrair esses dados para gerar informações significativas é uma tarefa comum entre os cientistas de dados.
Existem várias bibliotecas Python dedicadas a trabalhar com documentos PDF como PYPDF2, etc. Neste tutorial, vai vestir Camelot.

Por que Camelot?
- Você está no controle: ao contrário de outras bibliotecas e ferramentas que dão bons resultados ou falham miseravelmente (sem intermediários), Camelot dá a você o poder de modificar a extração de tabelas. (Isso é essencial, pois tudo no mundo real, incluindo extração de tabelas PDF, é confuso).
- Um pouco as tabelas podem ser eliminadas com base em métricas como precisão e espaço em branco, sem ter que olhar manualmente para cada tabela.
- Cada mesa é um DataFrame do pandas, que se integra perfeitamente em Análise de dados e fluxos de trabalho ETL.
- Exportar para vários formatos, incluindo JSON, Excel, HTML e Sqlite.
Vamos começar
Antes de instalar as bibliotecas Camelot, temos que instalar script fantasma , assim que instalarmos o script fantasma, vamos instalar camelot-py.
Execute os comandos abaixo :
pip install "camelot-py[cv]"
Depois de instalar a biblioteca camelot-py, estaremos prontos para começar. Estamos tentando extrair uma tabela de receitas de GST em todo o estado deste documento pdf.
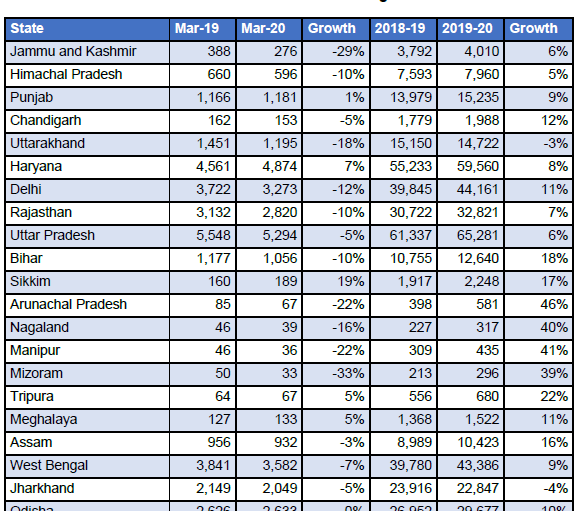
Tabela Pdf
importar camelot
Se você tem camelot, Python não imprimirá uma mensagem de erro, e se não, você verá um ImportError.
# Sintaxe da função camelot.read_pdf
camelote.read_pdf(
caminho de arquivo,
Páginas= '1',
senha= Nenhum,
sabor= 'rede',
suppress_stdout= Falso,
layout_kwargs={},
**kwargs,
)
Se você tiver que extrair uma tabela de páginas diferentes, você deve dar o número da página.
tables2 = camelot.read_pdf('gst-recipe-collection-march2020.pdf', sabor ="Stream", páginas ="0-3")
tabelas2
Isso lhe dará uma lista total da Tabela que está lá em um documento pdf. podemos escolher uma tabela que passa o índice.
tabelas2[2] # 2 é o índice
tabelas2[2].parsing_report

O código acima fornecerá detalhes como precisão e número da página. Por favor, note que existem 2 Páginas.
O código a seguir irá extrair a tabela do documento pdf.
df2 = tables2[2].df
df2
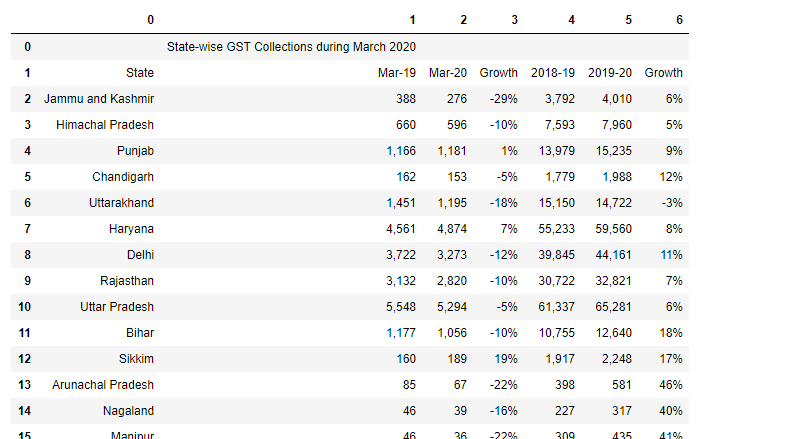
Nesta circunstância, porque a tabela é dividida em duas páginas diferentes. Então podemos fazer uma solução.
tabelas2[3]
tabelas2[3].parsing_report

Aqui você pode notar, nós extraímos a tabela da página não 3.
df3 = tables2[3].df
df3
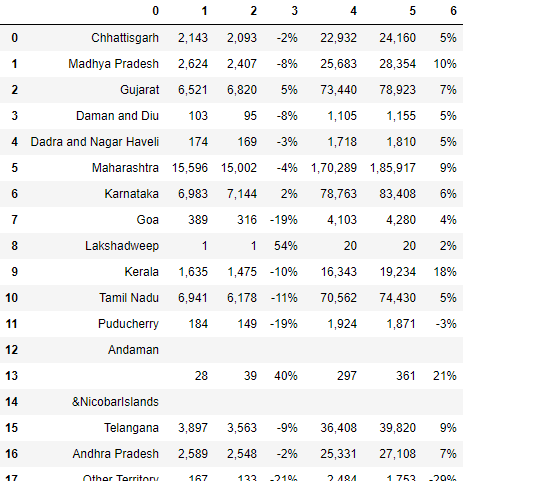
A seguir está o código para adicionar df2 e df3.
df4 = df2.append(df3)
df4
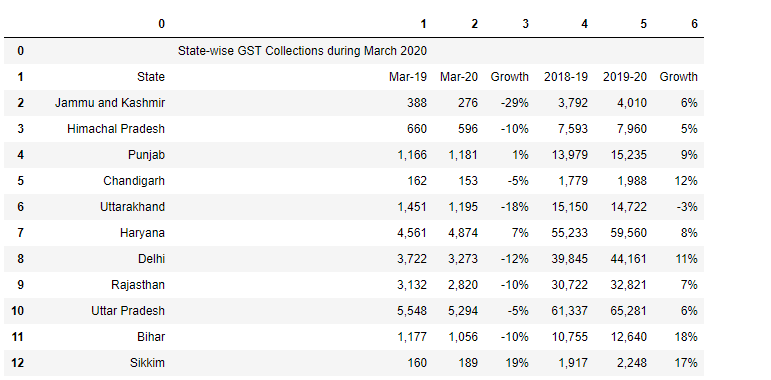
df5 = df4[1:] df5.head() new_header = df5.iloc[0]df5 = df5[1:]df5.columns = new_header
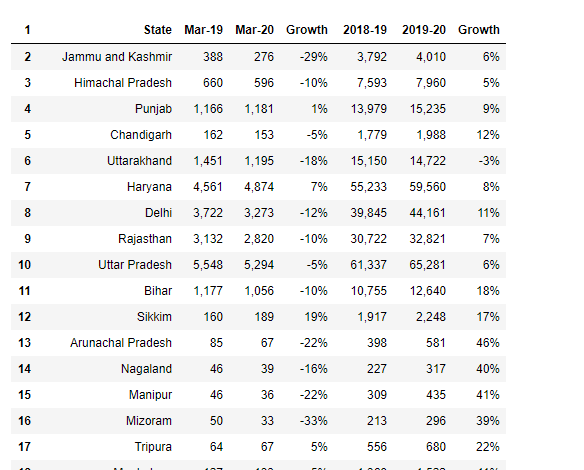
Aqui tens, nós extraímos uma tabela de pdf, agora podemos exportar esses dados em qualquer formato para o sistema local.
conclusão
Extrair dados tabulares de PDF com a ajuda da biblioteca camelot é realmente fácil. Ao mesmo tempo, sabemos que há muitos dados não estruturados em formato pdf e, depois de extrair as tabelas, podemos fazer muitas análises e visualizações com base nas necessidades do seu negócio.
Espero que este post ajude você e economize uma boa quantidade de tempo. Deixe-me saber se você tem alguma sugestão.
CÓDIGO FELIZ.
Sobre o autor

Prabhat Kumar – Analista associado
Sou um engenheiro que hoje atuo nas principais empresas multinacionais como analista associado e entusiasta da inovação., Eu adoro aprender coisas novas, Acredito que cada informação tem uma história e adoro ler as histórias.
Prabhat Pathak (Perfil do linkedIn) é analista associado.





