Este artigo foi publicado como parte do Data Science Blogathon
Este artigo se concentra no Apache Pig. É uma plataforma de alto nível para processar e analisar uma grande quantidade de dados.
VISÃO GLOBAL
Se olharmos para a visão geral de nível superior do Pig, Pig é uma abstração de MapReduce. Pig roda em Hadoop. Portanto, usa o sistema de arquivos distribuído Hadoop (HDFS) como o sistema de processamento Hadoop, MapReduce. Fluxo de dados executado
por um motor. Usado para analisar conjuntos de dados como fluxos de dados. Inclui uma linguagem de alto nível chamada Pig Latin para expressar esses fluxos de dados.
A entrada para Pig é Pig Latin, que se tornarão trabalhos MapReduce. Pig usa truques MapReduce para fazer todo o processamento de dados. Combina os scripts Pig Latin em uma série de um ou mais trabalhos MapReduce que são executados.
O Apache Pig foi desenvolvido pelo Yahoo porque é fácil de aprender e trabalhar.. Então, O Pig torna o Hadoop muito fácil. O Apache Pig foi desenvolvido porque a programação do MapReduce estava ficando muito difícil e muitos usuários do MapReduce não se sentem confortáveis com linguagens declarativas. Agora, Pig é um projeto de código aberto no Apache.
TABELA DE CONTEÚDO
- Características do porco
- Cerdo vs MapReduce
- Arquitetura de porco
- Opções de execução do Pig
- Comandos básicos de execução do Pig
- Tipos de dados Pig
- Operadores de pig
- Exemplo de escrita latina de porco
1. CARACTERÍSTICAS DOS PORCOS
Vejamos algumas das características do Pig.
- Tem um rico conjunto de operadores como join, pedido, etc.
- É fácil de programar, pois é semelhante ao SQL.
- As tarefas no Apache Pig foram convertidas em tarefas MapReduce automaticamente. Os programadores devem se concentrar apenas na semântica da linguagem e não no MapReduce.
- Você pode criar suas próprias funções usando Pig.
- Funções em outras linguagens de programação como Java podem ser incorporadas em scripts Pig Latin.
- Apache Pig pode lidar
todos os tipos de dados, como dados estruturados, não estruturado e semi-estruturado e
armazena o resultado em HDFS.
2. CERDO VS MAPREDUCE
Vamos ver a diferença entre Pig e MapReduce.
Pig tem várias vantagens sobre MapReduce.
Apache Pig é uma linguagem de fluxo de dados. Isso significa que permite aos usuários descrever como devem ser lidos, processar e, em seguida, armazenar os dados de uma ou mais entradas para uma ou mais saídas em paralelo. While MapReduce, por outro lado, é um estilo de programação.
Apache Pig é uma linguagem de alto nível, enquanto MapReduce é código Java compilado.
A sintaxe do Pig para realizar junções e vários arquivos é muito intuitiva e bastante simples como o SQL. Código MapReduce
fica complexo se você quiser escrever operações de junção.
A curva de aprendizado do Apache Pig é muito pequena. Experiência em bibliotecas Java e MapReduce é imprescindível
para executar o código MapReduce.
Os scripts do Apache Pig podem fazer o equivalente a várias linhas de código MapReduce e o código MapReduce precisa de mais linhas de código para executar as mesmas operações.
Apache Pig é fácil de depurar e testar, enquanto os programas MapReduce demoram muito para codificar, Experimente, etc. Pig Latin é mais barato que MapReduce.
3. ARQUITETURA PORCINA
Agora vamos dar uma olhada na arquitetura do Pig.
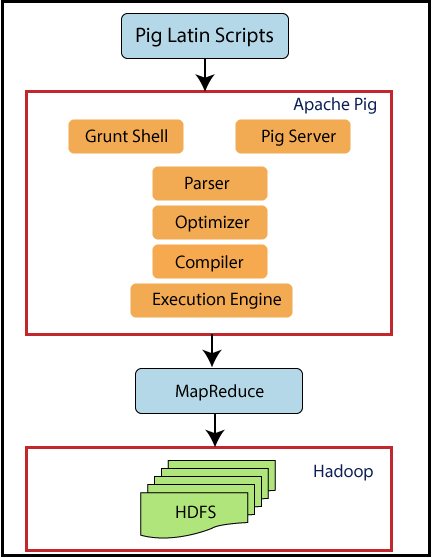
Porco sentado em cima do Hadoop. Os scripts do Pig podem ser executados no shell Grunt ou no servidor Pig. O tempo de execução do Pig the Pass otimiza e compila o script e, eventualmente, o converte em tarefas MapReduce. Usa HDFS para armazenar dados intermediários entre trabalhos MapReduce e, em seguida, grava sua saída no HDFS.
4. OPÇÕES DE EXECUÇÃO DE PORCOS
Apache Pig pode executar dois modos de execução. Ambos produzem os mesmos resultados.
4.1. Modo local
Comando nas passarelas
pig -x local
4.2. Modo Hadoop
Comando nas passarelas
porco-tipo mapreduce
O Apache Pig pode ser executado de três maneiras nos dois modos acima.
- Modo em lote / Arquivo de script: coloque os comandos do Pig em um arquivo de script e execute o script
- Programa embutido / UDF: incorporar comandos Pig em java e executar os scripts
5. COMANDOS DE SHELL DO PORK GRUNT
Grunt shells podem ser usados para escrever scripts Pig Latin. Os comandos do shell podem ser invocados usando os comandos fs e sh. Vamos ver alguns princípios básicos
Comandos de porco.
5.1. comando fs
O comando fs permite que você execute comandos HDFS do Pig
5.1.1 Para listar todos os diretórios em HDFS
grunhido> fs -ls;
Agora, todos os arquivos em HDFS serão exibidos.
5.1.2. Para criar um novo diretório mydir no HDFS
grunhido> fs -mkdir mydir /;
O comando acima criará um novo diretório chamado mydir no HDFS.
5.1.3. Para deletar um diretório
grunhido> fs -rmdir meudir;
O comando acima irá deletar o diretório criado mydir.
5.1.4. Para copiar um arquivo para HDFS
conceder> fs -put sales.txt sales /;
Aqui, o arquivo chamado sales.txt é o arquivo de origem que será copiado para o diretório de destino no HDFS, quer dizer, vendas.
5.1.5. Para sair do Grunt Shell
grunhido> Sair;
O comando acima irá sair do shell grunt.
5.2. comandar sh
O comando sh permite que você execute uma instrução Unix do Pig
5.2.1. Para mostrar a data atual
grunhido> encontro sh;
Este comando irá mostrar a data atual.
5.2.2. Para listar arquivos locais
grunhido> sh ls;
Este comando irá mostrar todos os arquivos no sistema local.
5.2.3. Para executar Pig Latin a partir de um shell grunhido
grunhido> execute salesreport.pig;
O comando acima irá executar um arquivo de script Pig Latin “salesreport.pig” de grunhido.
5.2.4. Para executar o Pig Latin a partir do prompt do Unix
$pig salesreport.pig;
O comando acima irá executar um arquivo de script Pig Latin “salesreport.pig” a partir do prompt do Unix.
6. P
Pig Latin consiste nos seguintes tipos de dados.
6.1. Átomo de dados
É um valor único. Pode ser uma string ou um número. Eles são de tipos escalares como int, flutuador, Duplo, etc.
Por exemplo, “João”, 9.0
6.2. Dobro
Uma tupla é semelhante a um registro com uma sequência de campos. Pode ser de qualquer tipo de dado.
Por exemplo, ('João', 'James') é uma tupla.
6.3. Bolsa de dados
Consiste em uma coleção de tuplas que é equivalente a um “Tabela” e SQL. Tuplas não são únicas e podem ter um número arbitrário de campos, cada um pode ser de qualquer tipo.
Por exemplo, {('João', 'James), (‘ Rei ',’ marca ')} é um pacote de dados equivalente à seguinte tabela em SQL.
6.4. Mapa de dados
Este tipo de dados
contém uma coleção de pares de valores-chave. Aqui, a chave deve ser um único caractere. Os valores podem ser de qualquer tipo.
Por exemplo, [nome#('João', 'James'), idade # 22] é um mapa de dados onde o nome, idade são fundamentais e ('João,’ James '), 22 são valores.
7. OPERADORES DE PORCO
Abaixo está o conteúdo do arquivo student.txt.
João,23,Hyderabad James,45,Hyderabad Sam,33,Chennai ,56,Délhi ,43,Mumbai
7.1. CARGA
Carrega dados de um determinado sistema de arquivos.
A = CARREGAR 'student.txt' AS (nome: Chararray, era: int, cidade: Chararray);
Dados do arquivo do aluno com nomes de coluna como 'nome', 'era', 'Cidade’ será carregado em uma variável A.
7.2. JOGAR FORA
O operador DUMP é usado para exibir o conteúdo de uma relação. Aqui, o conteúdo de A será exibido.
DUMP A //resultados (João,23,Hyderabad) (James,45,Hyderabad) (Sam,33,Chennai) (,56,Délhi) (,43,Mumbai)
7.3. FAZER COMPRAS
A função salvar salva os resultados no sistema de arquivos.
ARMAZENE A em 'myoutput' usando PigStorage(‘*’);
Aqui, os dados presentes em A serão armazenados em myoutput separados por '*'.
DUMP myoutput;
//results
John*23*Hyderabad
James*45*Hyderabad
Sam*33*Chennai
*56*Delhi
*43*Mumbai
7.4. FILTRO
B = FILTRO A por nome não é nulo;
O operador FILTER filtrará uma tabela com algumas condições. Aqui, o nome é a coluna em A. Os valores não vazios no nome serão armazenados na variável B.
DUMP B; //resultados (João,23,Hyderabad) (James,45,Hyderabad) (Sam,33,Chennai)
7.5. PARA CADA UM GERAR
C = FOREACH A GENERATE nome, cidade;
O operador FOREACH é usado para acessar registros individuais. Aqui, as linhas presentes no nome e na cidade serão obtidas de A e armazenadas em C.
DUMP C //resultados (João,Hyderabad) (James,Hyderabad) (Sam,Chennai) (,Délhi) (,Mumbai)
8. EXEMPLO DE SCRIPT LATIN DE PORCO
Temos um arquivo de pessoas cujos campos são a identificação do funcionário, o nome e as horas.
001,Rajiv,21 002,Sidarth,12 003,Rajesh,22
Primeiro, carregar esses dados em um funcionário variável. Filtre por horas a menos que 20 e loja a tempo parcial. Classifique o tempo parcial em ordem decrescente e salve-o em outro arquivo chamado part_time. Ver o conteúdo.
O script será
funcionário = Carregar ‘pessoas’ como (vazio, nome, horas); meio período = FILTRO funcionário POR Horas < 20; ordenado = ORDER a tempo parcial por horas DESC; STORE classificado em 'part_time'; DUMP classificado; DESCRIBE classificado; //resultados (003,Rajesh,22) (001,Rajiv,21)
NOTAS FINAIS
Estes são alguns dos princípios básicos do Apache Pig. Eu espero que você tenha gostado de ler este artigo. Comece a praticar
com o ambiente Cloudera.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.






{kind=link}