Esta postagem foi tornada pública como parte do Data Science Blogathon
Introdução
amostragem para obter a probabilidade de um intervalo de uma quantidade desconhecida. Parece difícil! não se preocupe, vamos explorar isso em profundidade neste post
Uma breve história:
O Método de Monte Carlo foi inventado por John Neumann e Ulam Stanislaw para impulsionar a tomada de decisões em condições incertas.. É nomeado após uma conhecida cidade de cassinos de Monte Carlo chamada Mônaco, uma vez que o elemento do acaso é central para a abordagem de modelagem, pois é semelhante a um jogo de roleta.
em palavras simples, A simulação de Monte Carlo é um método de estimando o valor de um quantidade desconhecida com a ajuda de estatísticas inferenciais. Você não precisa se aprofundar em estatísticas inferenciais para obter uma compreensão sólida de como funciona a simulação de Monte Carlo.. Apesar disto, este post passará apenas pelos pontos da estatística inferencial que serão relevantes para nós na simulação de Monte Carlo.
A estatística inferencial lida com população que é o nosso conjunto de exemplos e shows, que é um subconjunto adequado da população. O ponto-chave para prestar atenção é que uma amostra aleatória tendem a apresentar o mesmo caracteristicas / propriedade como a população da qual é extraída.
Veremos um exemplo para entender como funciona a simulação de Monte Carlo.
Nosso objetivo é estimar quais são as chances de sair na frente se jogarmos uma moeda um número infinito de vezes..
1. Digamos que viramos uma vez e vamos em frente. Temos certeza de que nossa resposta é 1?
2. Agora jogamos a moeda novamente e a cara saiu novamente.. Temos certeza de que o próximo lançamento também estará à frente?
3. Nós viramos de novo e de novo, Digamos 100 vezes, e estranhamente a cabeça aparece toda vez. Agora, temos que aceitar o fato de que o próximo turno resultará em outra cabeça?
4. Vamos mudar o cenário e supor que 100 lançamentos, 52 resultou no descanso da cabeça, 48 se transformou em cruzes. É a probabilidade de que o próximo lançamento atinja a cabeça? 52/100? Dada a observação, é a nossa melhor estimativa, mas a confiança permanecerá baixa.
Por que há uma diferença no nível de confiança?
É essencial saber que nossa estimativa depende de duas coisas
1. Tamanho: O tamanho da amostra (como um exemplo, 100 vs 2 Nos casos 2 e 4 respectivamente)
2. Diferença: variância da amostra (todos os resultados como cabeça vs. 52 cabeças como no caso 3 e 4 respectivamente)
3. UMA mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... que aumenta la varianza de la observación (casos 3 e 4), há necessidade de mais observação (como nos casos 2 e 4) ter o mesmo grau de confiança.
Agora estaremos simulando um jogo de roleta (Pitão):
Roleta é um jogo em que um disco com blocos (meio vermelho e meio preto) em que uma bola pode ser contida, girar com uma bola. Precisamos adivinhar um número e se a bola cair nesse número, então é uma vitória, e ganhamos uma quantia (valor pago por um slot
) X (não. Do total de slots na máquina).
Roleta classe():
def __init__(auto):
auto.pockets = []
para eu no alcance(1,37):
self.pockets.append(eu)
self.ball = None
self.pocketOdds = len(auto.bolsos) - 1
def spin(auto):
auto.ball = aleatório.escolha(auto.bolsos)
def betPocket(auto, Bolso, Amt):
se str(Bolso) == str(auto.ball):
return amt*self.pocketOdds
else: return -amt
def __str__(auto):
return 'Fair Roulette'
def playRoulette(jogos, numSpins, Bolso, Apostar):
totPocket = 0
para eu no alcance(numSpins):
game.spin()
totPocket += jogo.betPocket(Bolso, Apostar)
se aimpresse:
imprimir (numSpins, 'giros de', jogos)
imprimir ('Apostas de retorno esperadas', Bolso, '=',
str(100*totPocket/numSpins) + '%n')
Retorna (totPocket/numSpins)
jogo = Roleta()
para numSpins em (100, 1000000):
para eu no alcance(3):
playRoulette(jogos, numSpins, 5, 1, Verdade)
100 Giros de roleta
Apostas de retorno esperadas 5 = -100.0%
100 Giros de roleta
Apostas de retorno esperadas 5 = 42.0%
100 Giros de roleta
Apostas de retorno esperadas 5 = -26.0%
1000000 Giros de roleta
Apostas de retorno esperadas 5 = -0,0546%
1000000 Giros de roleta
Apostas de retorno esperadas 5 = 0,502%
1000000 Giros de roleta
Apostas de retorno esperadas 5 = 0,7764%
Lei de grandes números
Em repetidos testes independentes com a probabilidade constante p da população de um resultado específico em cada teste, a probabilidade de que o resultado ocorrerá, Em outras palavras, obtido a partir de amostras. Difere de p converge para zero como ele o número de tentativas vai para o infinito.
Significa simplesmente que se ocorrerem desvios (variância) de comportamento esperado (probabilidade p), é provável que no futuro esses desvios sejam compensados pelo desvio oposto.
Agora vamos falar sobre um incidente interessante que ocorreu em 18 agosto 1913, em um cassino de Monte Carlo. na roleta, preto levantou um recorde vinte e seis vezes seguidas, e o pânico surgiu para apostar no vermelho (para corresponder ao desvio do comportamento esperado)
Vamos analisar essa situação matematicamente
1. Probabilidade 26 vermelho consecutivo = 1 / 67,108,865
2. Probabilidade 26 vermelho consecutivo quando o 25 rolos anteriores eram vermelhos = 1/2
Regressão à média
1. Após um evento aleatório extremo, o próximo evento aleatório provavelmente será menos extremo, para que a média seja mantida.
2. Como um exemplo, se a roleta for girada 10 vezes e os vermelhos vêm cada vez, então é um evento extremo = 1/1024 e é provável que no próximo 10 voltas temos menos de 10 vermelhos, mas o número médio é 5 só.
Então, quando olhamos para a média 20 voltas, estará mais próximo da média esperada do 50% de vermelho do que de 100% em primeiro 10 voltas.
Agora é hora de enfrentar alguma realidade.
Espaço de amostragem de resultados possíveis
1. Não é possível garantir uma precisão perfeita por amostragem, nem se pode dizer que uma estimativa não seja exatamente correta..
Estamos diante de uma questão aqui: Quantas amostras são necessárias para analisar antes que possamos ter confiança significativa em nossa resposta??
Depende da variabilidade na distribuição subjacente.
Níveis de confiança e intervalos de confiança
Assim como em uma situação da vida real, não podemos ter certeza de nenhum parâmetro desconhecido obtido de uma amostra para toda a população, então usamos níveis de confiança e intervalos de confiança.
O intervalo de confiança fornece um intervalo no qual o valor desconhecido provavelmente está contido com a confiança de que o valor desconhecido está estritamente dentro desse intervalo..
Como um exemplo, o rendimento das apostas em uma máquina caça-níqueis 1000 vezes na roleta é -3% com um margemMargem é um termo usado em uma variedade de contextos, como contabilidade, Economia e impressão. Em contabilidade, refere-se à diferença entre receitas e custos, que permite avaliar a rentabilidade de um negócio. No domínio da publicação, A margem é o espaço em branco ao redor do texto em uma página, que facilita a leitura e proporciona uma apresentação estética. Seu correto manejo é essencial.. de error de +/- 4% com um nível de confiança de 95%.
Ela pode ser decodificada ainda mais à medida que realizamos um teste infinito de 1000,
desempenho médio / média esperada seria -3%
O rendimento varia entre + 1% e -7% que além do 95% das vezes.
Função densidade de probabilidade (PDF).
A distribuição geral da forma é estabelecida através da função densidade de probabilidade (PDF). Se establece como la probabilidad de que la variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... aleatoria se encuentre entre un intervalo.
A área sob a curva entre os dois pontos PDF é a probabilidade de que a variável aleatória esteja dentro desse intervalo..
Vamos concluir nosso aprendizado com um exemplo:
Digamos que há um baralho de cartas embaralhado e precisamos encontrar a probabilidade de obter 2 reis consecutivos se eles colocarem as cartas na ordem em que são colocadas.
Método Analítico:
P (ao menos 2 reis consecutivos) = 1-P (sem reis consecutivos)
= 1- (49! X 48!) / ((49-4)! X52!) = 0.217376
Por simulação de Monte Carlo:
Passos
1. Selecione repetidamente pontos de dados aleatórios: aqui assumimos que o embaralhamento das cartas é aleatório
2. Executando cálculos determinísticos. Vários destes embaralham e encontram os resultados.
3. Combine os resultados: Explorando o resultado e terminando com nossa conclusão.
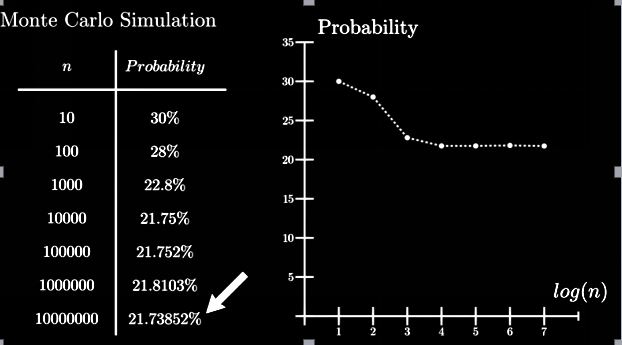
Através do método de Monte Carlo conseguimos uma solução quase exata do método analítico.
Vantagens da Simulação de Monte Carlo
- Fácil de implementar e fornece amostragem estatística para experimentos numéricos usando o computador.
- Ele nos fornece soluções aproximadas satisfatórias para problemas matemáticos computacionalmente caros..
- Pode ser usado para problemas determinísticos e estocásticos..
Desvantagens da Simulação de Monte Carlo
- Às vezes demora muito, uma vez que temos que gerar um grande número de amostras para obter o resultado satisfatório desejado.
- Os resultados obtidos com este método são apenas a aproximação da resposta verdadeira e não a resposta exata..
Sobre o autor
Soy Dinesh Junjariya, um estudante de Btech do IIT Jodhpur.
Para qualquer sugestão, Comente abaixo.
A mídia mostrada nesta postagem não é propriedade da DataPeaker e é usada a critério do autor.





