Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
Siempre que creamos un modelo de aprendizaje automático, lo alimentamos con datos iniciales para entrenar el modelo. Y luego alimentamos algunos datos desconocidos (datos de prueba) para comprender qué tan bien se desempeña el modelo y se generalizan sobre los datos invisibles. Si el modelo funciona bien en los datos invisibles, es consistente y puede predecir con buena precisión en una amplia gama de datos de entrada; entonces este modelo es estable.
¡Pero este no es siempre el caso! Los modelos de aprendizaje automático no siempre son estables y tenemos que evaluar la estabilidad del modelo de aprendizaje automático. Ahí es donde entra en juego la validación cruzada.
«En términos simples, la validación cruzada es una técnica que se utiliza para evaluar qué tan bien funcionan nuestros modelos de aprendizaje automático en datos no vistos»
Según Wikipedia, la validación cruzada es el proceso de evaluar cómo los resultados de un análisis estadístico se generalizarán a un conjunto de datos independiente.
Hay muchas formas de realizar la validación cruzada y aprenderemos sobre 4 métodos en este artículo.
¡Primero entendamos la necesidad de la validación cruzada!
¿Por qué necesitamos la validación cruzada?

Suponga que crea un modelo de aprendizaje automático para resolver un problema y ha entrenado el modelo en un conjunto de datos determinado. Cuando verifica la precisión del modelo en los datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina...., está cerca del 95%. ¿Significa esto que su modelo se ha entrenado muy bien y es el mejor modelo debido a la alta precisión?
¡No, no es! Debido a que su modelo está entrenado con los datos proporcionados, conoce bien los datos, captura incluso las variaciones mínimas (ruido) y se ha generalizado muy bien sobre los datos proporcionados. Si expone el modelo a datos completamente nuevos e invisibles, es posible que no prediga con la misma precisión y que no se generalice sobre los nuevos datos. Este problema se llama sobreajuste.
A veces, el modelo no se entrena bien en el conjunto de entrenamiento porque no puede encontrar patrones. En este caso, tampoco funcionaría bien en el equipo de prueba. Este problema se llama Ajuste insuficiente.
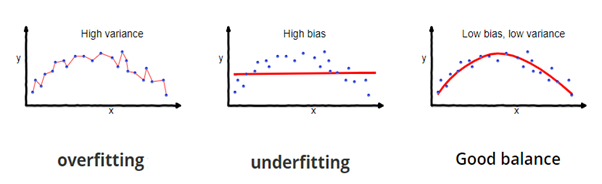
Fuente de la imagen: fireblazeaischool.in
Para superar los problemas de sobreajuste, utilizamos una técnica llamada Validación cruzada.
Validación cruzada es una técnica de remuestreo con la idea fundamental de dividir el conjunto de datos en 2 partes: datos de entrenamiento y datos de prueba. Los datos del tren se utilizan para entrenar el modelo y los datos de prueba invisibles se utilizan para la predicción. Si el modelo se desempeña bien sobre los datos de prueba y ofrece una buena precisión, significa que el modelo no ha sobreajustado los datos de entrenamiento y puede usarse para la predicción.
Profundicemos y aprendamos sobre algunas de las técnicas de evaluación de modelos.
1. Método de espera
Este es el método de evaluación más simple y se usa ampliamente en proyectos de aprendizaje automático. Aquí, el conjunto de datos completo (población) se divide en 2 conjuntos: conjunto de trenes y conjunto de pruebas. Los datos se pueden dividir en 70-30 o 60-40, 75-25 o 80-20, o incluso 50-50 según el caso de uso. Como regla general, la proporción de datos de entrenamiento debe ser mayor que los datos de prueba.
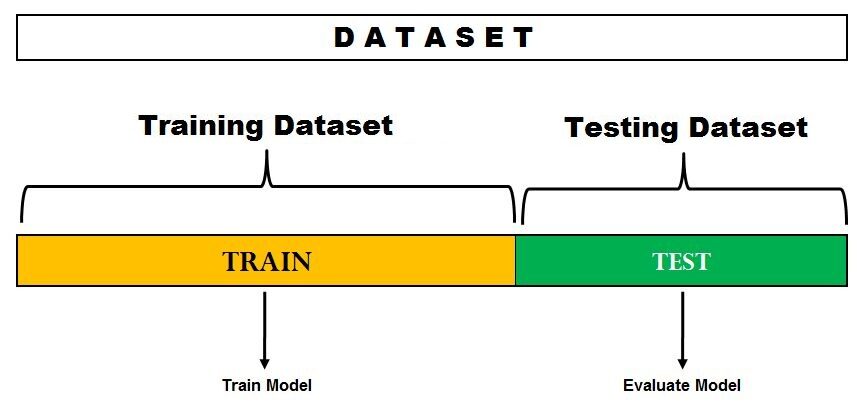
Fuente de la imagen: DataVedas
La división de datos ocurre aleatoriamente y no podemos estar seguros de qué datos terminan en el tren y en el depósito de prueba durante la división, a menos que especifiquemos random_state. Esto puede llevar a una variación extremadamente alta y cada vez que cambia la división, la precisión también cambiará.
Este método tiene algunos inconvenientes:
- En el método Hold out, las tasas de error de prueba son muy variables (alta varianza) y depende totalmente de qué observaciones terminan en el conjunto de entrenamiento y el conjunto de prueba.
- Solo una parte de los datos se usa para entrenar el modelo (alto sesgo) lo cual no es una muy buena idea cuando los datos no son grandes y esto conducirá a una sobreestimación del error de prueba.
Una de las principales ventajas de este método es que es computacionalmente económico en comparación con otras técnicas de validación cruzada.
Implementación rápida del método Hold Out en Python
from sklearn.model_selection import train_test_split
X = [10,20,30,40,50,60,70,80,90,100]
train, test = train_test_split (X, test_size = 0.3, random_state = 1)
print («Tren:», X_train, «Prueba:», X_test)
Output
Train: [50, 10, 40, 20, 80, 90, 60] Test: [30, 100, 70]
Aquí, estado_aleatorio es la semilla utilizada para la reproducibilidad.
2. Deje uno fuera de la validación cruzada
En este método, dividimos los datos en conjuntos de prueba y de tren, pero con un giro. En lugar de dividir los datos en 2 subconjuntos, seleccionamos una única observación como datos de prueba, y todo lo demás se etiqueta como datos de entrenamiento y el modelo está entrenado. Ahora se selecciona la segunda observación como datos de prueba y el modelo se entrena con los datos restantes.
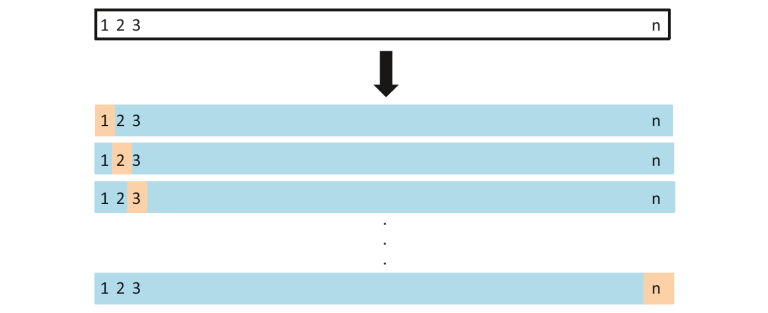
Fuente de la imagen: ISLR
Este proceso continúa ‘n’ veces y el promedio de todas estas iteraciones se calcula y estima como el error del conjunto de prueba.
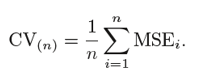
Cuando se trata de estimaciones de errores de prueba, LOOCV proporciona estimaciones no sesgadas (sesgo bajo). Pero el sesgo no es el único motivo de preocupación en los problemas de estimación. También deberíamos considerar la varianza.
LOOCV tiene un alta varianza porque estamos promediando la salida de n-modelos que se ajustan a un conjunto casi idéntico de observaciones, y sus salidas están correlacionadas muy positivamente entre sí.
Y puede ver claramente que esto es computacionalmente costoso ya que el modelo se ejecuta ‘n’ veces para probar cada observación en los datos. Nuestro próximo método abordará este problema y nos dará un buen equilibrio entre el sesgo y la varianza.
Implementación rápida de la validación cruzada de Leave One Out en Python
from sklearn.model_selection import LeaveOneOut
X = [10,20,30,40,50,60,70,80,90,100]
l = LeaveOneOut()
for train, test in l.split(X):
print("%s %s"% (train,test))
Output
[1 2 3 4 5 6 7 8 9] [0] [0 2 3 4 5 6 7 8 9] [1] [0 1 3 4 5 6 7 8 9] [2] [0 1 2 4 5 6 7 8 9] [3] [0 1 2 3 5 6 7 8 9] [4] [0 1 2 3 4 6 7 8 9] [5] [0 1 2 3 4 5 7 8 9] [6] [0 1 2 3 4 5 6 8 9] [7] [0 1 2 3 4 5 6 7 9] [8] [0 1 2 3 4 5 6 7 8] [9]
Esta salida muestra claramente cómo LOOCV mantiene una observación a un lado como datos de prueba y todas las demás observaciones van a los datos del tren.
3. Validación cruzada de K-Fold
En esta técnica de remuestreo, todos los datos se dividen en k conjuntos de tamaños casi iguales. El primer conjunto se selecciona como conjunto de prueba y el modelo se entrena en los conjuntos k-1 restantes. La tasa de error de prueba se calcula luego de ajustar el modelo a los datos de prueba.
En la segunda iteración, el segundo conjunto se selecciona como conjunto de prueba y los conjuntos k-1 restantes se utilizan para entrenar los datos y se calcula el error. Este proceso continúa para todos los k conjuntos.
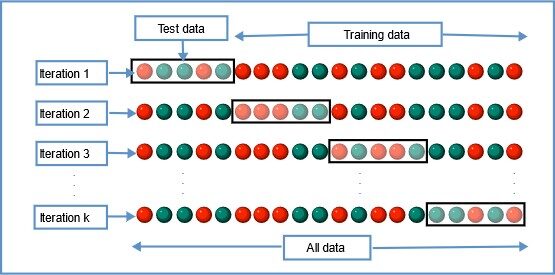
Fuente de la imagen: Wikipedia
La media de errores de todas las iteraciones se calcula como la estimación del error de prueba de CV.
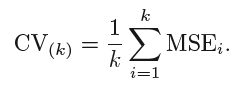
En K-Fold CV, el número de pliegues k es menor que el número de observaciones en los datos (k <n) y estamos promediando las salidas de k modelos ajustados que están algo menos correlacionados entre sí debido a la superposición entre el entrenamiento conjuntos en cada modelo es más pequeño. Esto lleva a baja varianza luego LOOCV.
La mejor parte de este método es que cada punto de datos está en el conjunto de prueba exactamente una vez y forma parte del conjunto de entrenamiento k-1 veces. A medida que aumenta el número de pliegues k, la varianza también disminuye (varianza baja). Este método conduce a sesgo intermedio porque cada conjunto de entrenamiento contiene menos observaciones (k-1) n / k que el método Leave One Out pero más que el método Hold Out.
Por lo general, la validación cruzada de K veces se realiza utilizando k = 5 o k = 10, ya que se ha demostrado empíricamente que estos valores producen estimaciones de errores de prueba que no tienen un sesgo alto ni una varianza alta.
La principal desventaja de este método es que el modelo tiene que ejecutarse desde cero k veces y es computacionalmente costoso que el método Hold Out, pero mejor que el método Leave One Out.
Implementación simple de la validación cruzada de K-Fold en Python
from sklearn.model_selection import KFold
X = ["a",'b','c','d','e','f']
kf = KFold(n_splits=3, shuffle=False, random_state=None)
for train, test in kf.split(X):
print("Train data",train,"Test data",test)
Output
Train: [2 3 4 5] Test: [0 1] Train: [0 1 4 5] Test: [2 3] Train: [0 1 2 3] Test: [4 5]
4. Validación cruzada estratificada de K-Fold
Esta es una ligera variación de K-Fold Cross Validation, que utiliza ‘muestreo estratificado’ en lugar de «muestreo aleatorio».
Entendamos rápidamente qué es el muestreo estratificado y en qué se diferencia del muestreo aleatorio.
Suponga que sus datos contienen reseñas de un producto cosmético utilizado por la población masculina y femenina. Cuando realizamos un muestreo aleatorio para dividir los datos en conjuntos de pruebas y trenes, existe la posibilidad de que la mayoría de los datos que representan a los hombres no estén representados en los datos de entrenamiento, pero podrían terminar en los datos de las pruebas. Cuando entrenamos el modelo con datos de entrenamiento de muestra que no son una representación correcta de la población real, el modelo no predecirá los datos de prueba con buena precisión.
Aquí es donde el muestreo estratificado viene al rescate. Aquí los datos se dividen de tal manera que representan todas las clases de la población.
Consideremos el ejemplo anterior, que tiene una revisión de productos cosméticos de 1000 clientes, de los cuales el 60% son mujeres y el 40% son hombres. Quiero dividir los datos en datos de prueba y de tren en proporción (80:20). El 80% de los 1000 clientes serán 800 los cuales serán elegidos de tal manera que haya 480 reseñas asociadas a la población femenina y 320 representando a la población masculina. De manera similar, el 20% de 1000 clientes serán elegidos para los datos de prueba (con la misma representación femenina y masculina).
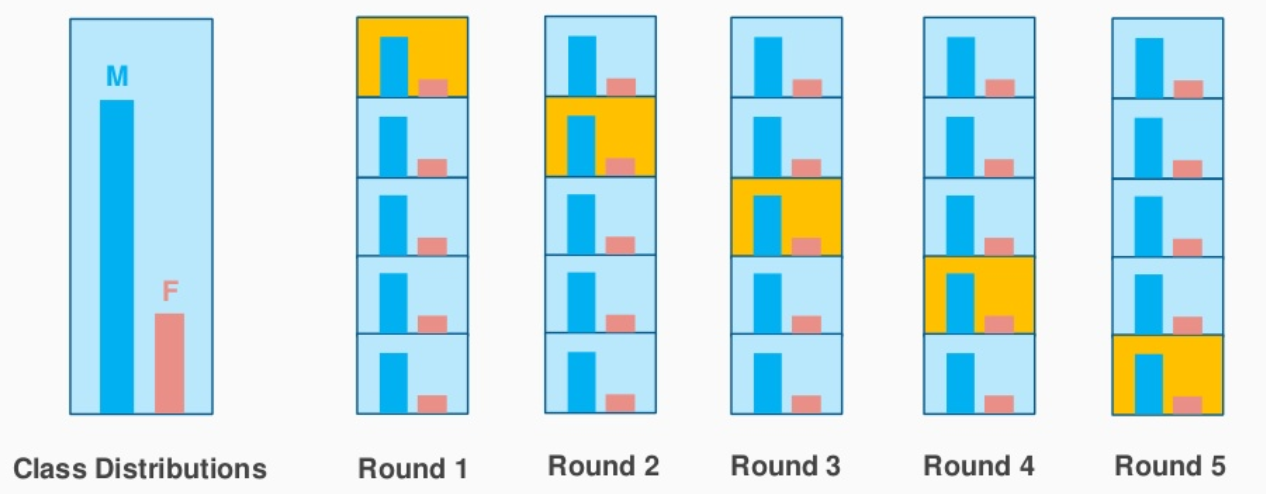
Fuente de la imagen: stackexchange.com
Esto es exactamente lo que hace el CV estratificado de K-Fold y creará K-Folds al preservar el porcentaje de muestra para cada clase. Esto resuelve el problema del muestreo aleatorio asociado con los métodos Hold out y K-Fold.
Implementación rápida de la validación cruzada estratificada de K-Fold en Python
from sklearn.model_selection import StratifiedKFold
X = np.array([[1,2],[3,4],[5,6],[7,8],[9,10],[11,12]])
y= np.array([0,0,1,0,1,1])
skf = StratifiedKFold(n_splits=3,random_state=None,shuffle=False)
for train_index,test_index in skf.split(X,y):
print("Train:",train_index,'Test:',test_index)
X_train,X_test = X[train_index], X[test_index]
y_train,y_test = y[train_index], y[test_index]
Output
Train: [1 3 4 5] Test: [0 2] Train: [0 2 3 5] Test: [1 4] Train: [0 1 2 4] Test: [3 5]
El resultado muestra claramente la división estratificada realizada en función de las clases ‘0’ y ‘1’ en ‘y’.
Sesgo – Compensación de varianza
Cuando consideramos las estimaciones de la tasa de error de la prueba, la validación cruzada de K-Fold proporciona estimaciones más precisas que la validación cruzada de dejar uno fuera. Mientras que el método Hold One Out CV generalmente conduce a sobreestimaciones de la tasa de error de prueba, porque en este enfoque, solo una parte de los datos se usa para entrenar el modelo de aprendizaje automático.
Cuando se trata de sesgo, el método Leave One Out ofrece estimaciones no sesgadas porque cada conjunto de entrenamiento contiene n-1 observaciones (que son prácticamente todos los datos). K-Fold CV conduce a un nivel intermedio de sesgo dependiendo del número de k-pliegues en comparación con LOOCV, pero es mucho menor en comparación con el método Hold Out.
Para concluir, la técnica de validación cruzada que elegimos depende en gran medida del caso de uso y del equilibrio entre sesgo y varianza.
Si ha leído este artículo hasta ahora, aquí hay un bono rápido para usted. 👏
sklearn.model_selection tiene un método cross_val_score lo que simplifica el proceso de validación cruzada. En lugar de iterar a través de los datos completos usando la función ‘dividir’, podemos usar cross_val_score y comprobar la puntuación de precisión del método de validación cruzada elegido
Puedes consultar mi Github para implementación de python de diferentes métodos de validación cruzada en el Datos de cáncer de mama de la UCI de Kaggle.
A continuación se muestran algunos de mis artículos sobre aprendizaje automático.
Inteligencia artificial Vs Aprendizaje automático Vs Aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud...: ¿Cuál es exactamente la diferencia entre estas palabras de moda?
Una guía completa para el análisis de datos usando Pandas
Si desea compartir sus pensamientos, puede conectarse conmigo en LinkedIn.
¡Feliz aprendizaje!
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





