Este artículo fue publicado como parte del Blogatón de ciencia de datos
ha sido una plataforma para que los clientes den retroalimentación a las empresas en función de su satisfacción. Las reseñas publicadas por los clientes son la fuente mundialmente confiable de contenido genuino para otros usuarios. Los comentarios de los clientes sirven como una herramienta de validación de terceros para generar confianza en la marca del usuario. Para comprender estos comentarios de los clientes sobre una entidad, el análisis de sentimientos se está convirtiendo en una herramienta de aumento para cualquier organización.
El análisis de sentimientos implica examinar conversaciones en línea como tweets, publicaciones de blogs o comentarios sobre servicios o temas particulares y segregar las opiniones de los usuarios (positivas, negativas y neutrales), lo que permite a las empresas identificar el sentimiento del cliente hacia los productos. Ayuda a las empresas con un pulso profundo sobre cómo los clientes realmente se «sienten» acerca de su marca y procesan grandes cantidades de datos de una manera eficiente y rentable. Al analizar automáticamente los comentarios de los clientes, desde las respuestas a las encuestas hasta las conversaciones en las redes sociales, las marcas pueden escuchar atentamente a sus clientes y adaptar los productos y servicios para satisfacer sus necesidades.
El análisis de sentimientos se puede clasificar como detallado, detección de emociones, análisis de sentimientos basado en aspectos y análisis de intenciones. El análisis de sentimiento detallado se ocupa de la polaridad de interpretación en la revisión, mientras que la detección de emociones implica la expresión emocional del usuario sobre un producto.
El análisis de sentimiento basado en aspectos es una variedad de análisis de sentimiento que ayuda en la mejora del negocio al conocer las características de su producto que necesitan mejorar de acuerdo con los comentarios de los clientes para hacer de su producto un éxito de ventas. ABSA identifica los aspectos en la revisión dada sobre un producto y también encuentra si el aspecto mencionado en la revisión pertenece a qué clase de sentimiento.
En este artículo, realizaremos ABSA utilizando el conjunto de datos de portátiles y restaurantes de SemEval 2014, así como en conjuntos de datos multilingües como el conjunto de datos hindi sobre productos como portátiles, teléfonos, restaurantes y hoteles.
Preprocesamiento de datos
Tokenización: La tokenización es la división del párrafo de texto en trozos más pequeños, como oraciones (tokenización de oraciones) o palabras (tokenización de palabras). El principal inconveniente de la tokenización de palabras son las palabras sin vocabulario (OOV), para evitar OOV y también para extraer información de la tokenización de oraciones de texto que se utiliza en este análisis.
Eliminar palabras vacías: Después de la tokenización, las palabras vacías se identifican y eliminan de los tweets. Las palabras vacías son las palabras más comunes en un idioma que pueden no agregar mucha información a la oración o al documento. Estas palabras se filtran para minimizar el ruido y mejorar la calidad de los datos de texto para una mejor clasificación. La biblioteca NLP contiene una colección de palabras vacías para cada idioma del texto en NLTK. Las palabras del texto se comparan con esta lista de palabras vacías, las palabras coincidentes se eliminan para mejorar la calidad de los datos y también para extraer fácilmente las palabras de sentimiento de los tweets.
Eliminar la puntuación y el carácter: Después de expandir las contracciones, los caracteres especiales y las puntuaciones se eliminan mediante la función regex. La razón principal para hacerlo es porque a menudo la puntuación o los caracteres especiales no tienen mucha importancia al analizar el texto y lo utilizan para extraer características o información basada en PNL y ML.
Reemplazo de la negación con antónimos: Reemplazar las palabras negativas con antónimos disminuye la dimensionalidad del recuento de palabras de la matriz del documento, por lo que es beneficioso comprimir el vocabulario sin perder su significado para ahorrar memoria.
from nltk.corpus import wordnet
class AntonymReplacer(object):
def replace(self, word, pos=None):
antonyms = set()
for syn in wordnet.synsets(word, pos=pos):
for lemma in syn.lemmas():
for antonym in lemma.antonyms():
antonyms.add(antonym.name())
if len(antonyms) == 1:
return antonyms.pop()
else:
return None
def replace_negations(self, sent):
i, l = 0, len(sent)
words = []
while i < l:
word = sent[i]
if word == 'not' and i+1 < l:
ant = self.replace(sent[i+1])
if ant:
words.append(ant)
i += 2
continue
words.append(word)
i += 1
return words
Corrección ortográfica: Las palabras que tienen varios caracteres repetidos y ortografía incorrecta que se producen debido a errores de escritura humana deben eliminarse, ya que no tienen importancia en general. Por ejemplo, palabras como finalmenteyy, exactamenteyy, etc.son entradas incorrectas, sin embargo, deben corregirse para su uso posterior.
Lematización: La lematización es la técnica de preprocesamiento de texto más común utilizada para la normalizaciónLa normalización es un proceso fundamental en diversas disciplinas, que busca establecer estándares y criterios uniformes para mejorar la calidad y la eficiencia. En contextos como la ingeniería, la educación y la administración, la normalización facilita la comparación, la interoperabilidad y la comprensión mutua. Al implementar normas, se promueve la cohesión y se optimizan recursos, lo que contribuye al desarrollo sostenible y a la mejora continua de los procesos.... de palabras. Lematizar una palabra convierte la palabra a su forma básica significativa al observar el análisis morfológico de cada palabra. La lematización también es similar a la lematización, pero la primera no tiene en cuenta el contexto de la palabra en la oración y solo elimina el sufijo en las palabras.
nltk.download('wordnet')
from nltk.stem import WordNetLemmatizer
lemmatizer=WordNetLemmatizer()
antreplacer = AntonymReplacer()
def clean_text(text):
#Lemmatizing the texts
# removing aphostrophe words
text = text.lower() if pd.notnull(text) else text
text = re.sub(r"what's", "what is ",str(text))
text = re.sub(r"'s", " ", str(text))
text = re.sub(r"'ve", " have ", str(text))
text = re.sub(r"can't", "cannot ", str(text))
text = re.sub(r'ain't', 'is not', str(text))
text = re.sub(r'won't', 'will not', str(text))
text = re.sub(r"n't", " not ", str(text))
text = re.sub(r"i'm", "i am ", str(text))
text = re.sub(r"'re", " are ", str(text))
text = re.sub(r"'d", " would ", str(text))
text = re.sub(r"'ll", " will ", str(text))
text = re.sub(r"'scuse", " excuse ", str(text))
text = re.sub('W', ' ', str(text))
text = re.sub('s+', ' ', str(text))
# Remove punctuations and numbers
text = re.sub('[^a-zA-Z]', ' ', str(text))
# Single character removal
text = re.sub(r"s+[a-zA-Z]s+", ' ', str(text))
text=lemmatizer.lemmatize(text)
# replacing negation words with antonyms
text=antreplacer.replace(text)
# Removing multiple spaces
text = re.sub(r's+', ' ', str(text))
text = text.strip(' ')
return text
Modelos de clasificador

La incrustación es el método de representar las palabras en la oración como vectores. La técnica de incrustación que usaremos será la incrustación GloVe, construyendo matrices de co-ocurrencia de palabras. Las oraciones en inglés se entrenan con incrustaciones GloVe previamente entrenadas y las incrustaciones para las oraciones en hindi se entrenan de manera personalizada con datos de corpus de hindi 13M.
def get_word2vec_embedding_matrix(model):
embedding_matrix = np.zeros((vocab_size,300))
for word, i in tokenizer.word_index.items():
try:
embedding_vector = model[word]
except KeyError:
embedding_vector = None
if embedding_vector is not None:
embedding_matrix[i]=embedding_vector
return embedding_matrix
Después de que las palabras de las oraciones se conviertan en vectores con la incrustación GloVe, los modelos bidireccionales LSTM y CNN se aplican en la capa de incrustación para entrenar y predecir los términos de aspecto y los términos de sentimiento, respectivamente. Los 1000 términos de aspecto más utilizados se identifican en el conjunto de datos y el modelo Bi-LSTM se entrena y clasifica entre estas clases de aspectos. Los términos de aspecto predichos se etiquetan como BIO. El sentimiento del término de aspecto encontrado se predice utilizando el modelo de CNN para clasificar la revisión como positiva, negativa y neutral.
embed_dim = 128 lstm_out = 196 model = Sequential() model.add(Embedding(10000, embed_dim,input_length = 28)) model.add(Bidirectional(LSTM(lstm_out,return_sequences=True))) model.add(LSTM(lstm_out, dropout=0.2, recurrent_dropout=0.2)) model.add(attention()) model.add(Flatten()) model.add(Dropout(0.3)) model.add(Dense(1000, activation='softmax')) model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=['accuracy']) model.summary()

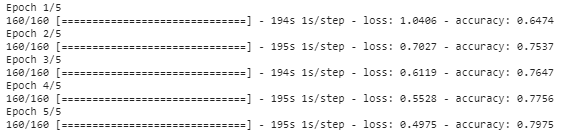
history_object = model.fit(trainX, trainY, epochs=5,batch_size=8)
Resumen
En este artículo, hemos aplicado varias técnicas de preprocesamiento a las revisiones de texto y las palabras se convierten en representaciones vectoriales utilizando la incrustación GloVe. La capa incrustada se agrega con la capa LSTM bidireccional para encontrar los términos de aspecto en la oración y se aplica la atención de Bahdanau para encontrar la asociación entre el objetivo y las palabras de contexto. Encuentre la polaridad de sentimiento para cada término de aspecto que se encuentra en el modelo anterior y se predice usando el modelo CNN para clasificar el término de aspecto como positivo, negativo o neutral. Los términos de aspecto que se predicen a partir de la oración se etiquetan con etiquetado BIO, a saber, Principio, intermedio o fuera del término de aspecto.
El código completo para este mini-proyecto está disponible aquí.
Notas finales
Espero que hayas disfrutado leyendo este artículo.
¡¡Feliz aprendizaje!!
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





